 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Limits of Compressive Memory: A Study of Infini-Attention in Small-Scale Pretraining
Dec 29, 2025This study investigates small-scale pretraining for Small Language Models (SLMs) to enable efficient use of limited data and compute, improve accessibility in low-resource settings and reduce costs. To enhance long-context extrapolation in compact models, we focus on Infini-attention, which builds a compressed memory from past segments while preserving local attention. In our work, we conduct an empirical study using 300M-parameter LLaMA models pretrained with Infini-attention. The model demonstrates training stability and outperforms the baseline in long-context retrieval. We identify the balance factor as a key part of the model performance, and we found that retrieval accuracy drops with repeated memory compressions over long sequences. Even so, Infini-attention still effectively compensates for the SLM's limited parameters. Particularly, despite performance degradation at a 16,384-token context, the Infini-attention model achieves up to 31% higher accuracy than the baseline. Our findings suggest that achieving robust long-context capability in SLMs benefits from architectural memory like Infini-attention.
Improving Neural Biasing for Contextual Speech Recognition by Early Context Injection and Text Perturbation
Jul 14, 2024Existing research suggests that automatic speech recognition (ASR) models can benefit from additional contexts (e.g., contact lists, user specified vocabulary). Rare words and named entities can be better recognized with contexts. In this work, we propose two simple yet effective techniques to improve context-aware ASR models. First, we inject contexts into the encoders at an early stage instead of merely at their last layers. Second, to enforce the model to leverage the contexts during training, we perturb the reference transcription with alternative spellings so that the model learns to rely on the contexts to make correct predictions. On LibriSpeech, our techniques together reduce the rare word error rate by 60% and 25% relatively compared to no biasing and shallow fusion, making the new state-of-the-art performance. On SPGISpeech and a real-world dataset ConEC, our techniques also yield good improvements over the baselines.
TorchAudio 2.1: Advancing speech recognition, self-supervised learning, and audio processing components for PyTorch
Oct 27, 2023



TorchAudio is an open-source audio and speech processing library built for PyTorch. It aims to accelerate the research and development of audio and speech technologies by providing well-designed, easy-to-use, and performant PyTorch components. Its contributors routinely engage with users to understand their needs and fulfill them by developing impactful features. Here, we survey TorchAudio's development principles and contents and highlight key features we include in its latest version (2.1): self-supervised learning pre-trained pipelines and training recipes, high-performance CTC decoders, speech recognition models and training recipes, advanced media I/O capabilities, and tools for performing forced alignment, multi-channel speech enhancement, and reference-less speech assessment. For a selection of these features, through empirical studies, we demonstrate their efficacy and show that they achieve competitive or state-of-the-art performance.
Efficient MDI Adaptation for n-gram Language Models
Aug 05, 2020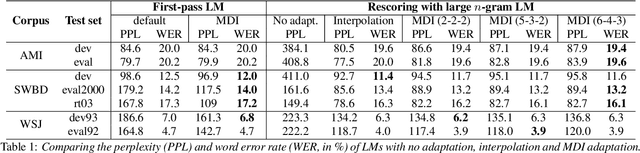
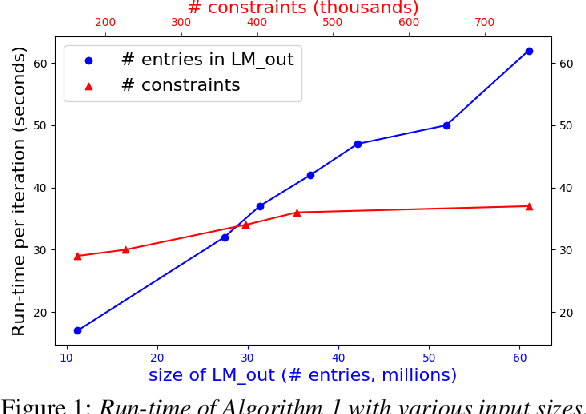
This paper presents an efficient algorithm for n-gram language model adaptation under the minimum discrimination information (MDI) principle, where an out-of-domain language model is adapted to satisfy the constraints of marginal probabilities of the in-domain data. The challenge for MDI language model adaptation is its computational complexity. By taking advantage of the backoff structure of n-gram model and the idea of hierarchical training method, originally proposed for maximum entropy (ME) language models, we show that MDI adaptation can be computed in linear-time complexity to the inputs in each iteration. The complexity remains the same as ME models, although MDI is more general than ME. This makes MDI adaptation practical for large corpus and vocabulary. Experimental results confirm the scalability of our algorithm on very large datasets, while MDI adaptation gets slightly worse perplexity but better word error rate results compared to simple linear interpolation.