 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterspeech 2025 URGENT Speech Enhancement Challenge
May 29, 2025There has been a growing effort to develop universal speech enhancement (SE) to handle inputs with various speech distortions and recording conditions. The URGENT Challenge series aims to foster such universal SE by embracing a broad range of distortion types, increasing data diversity, and incorporating extensive evaluation metrics. This work introduces the Interspeech 2025 URGENT Challenge, the second edition of the series, to explore several aspects that have received limited attention so far: language dependency, universality for more distortion types, data scalability, and the effectiveness of using noisy training data. We received 32 submissions, where the best system uses a discriminative model, while most other competitive ones are hybrid methods. Analysis reveals some key findings: (i) some generative or hybrid approaches are preferred in subjective evaluations over the top discriminative model, and (ii) purely generative SE models can exhibit language dependency.
Source Separation by Flow Matching
May 22, 2025


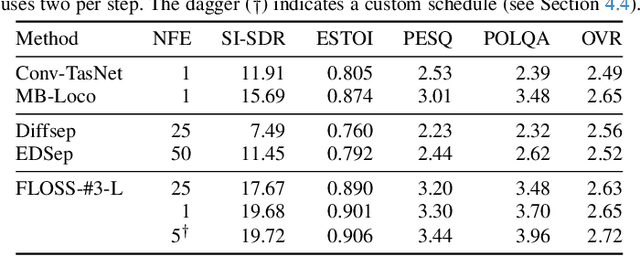
We consider the problem of single-channel audio source separation with the goal of reconstructing $K$ sources from their mixture. We address this ill-posed problem with FLOSS (FLOw matching for Source Separation), a constrained generation method based on flow matching, ensuring strict mixture consistency. Flow matching is a general methodology that, when given samples from two probability distributions defined on the same space, learns an ordinary differential equation to output a sample from one of the distributions when provided with a sample from the other. In our context, we have access to samples from the joint distribution of $K$ sources and so the corresponding samples from the lower-dimensional distribution of their mixture. To apply flow matching, we augment these mixture samples with artificial noise components to ensure the resulting "augmented" distribution matches the dimensionality of the $K$ source distribution. Additionally, as any permutation of the sources yields the same mixture, we adopt an equivariant formulation of flow matching which relies on a suitable custom-designed neural network architecture. We demonstrate the performance of the method for the separation of overlapping speech.
ReverbMiipher: Generative Speech Restoration meets Reverberation Characteristics Controllability
May 08, 2025



Reverberation encodes spatial information regarding the acoustic source environment, yet traditional Speech Restoration (SR) usually completely removes reverberation. We propose ReverbMiipher, an SR model extending parametric resynthesis framework, designed to denoise speech while preserving and enabling control over reverberation. ReverbMiipher incorporates a dedicated ReverbEncoder to extract a reverb feature vector from noisy input. This feature conditions a vocoder to reconstruct the speech signal, removing noise while retaining the original reverberation characteristics. A stochastic zero-vector replacement strategy during training ensures the feature specifically encodes reverberation, disentangling it from other speech attributes. This learned representation facilitates reverberation control via techniques such as interpolation between features, replacement with features from other utterances, or sampling from a latent space. Objective and subjective evaluations confirm ReverbMiipher effectively preserves reverberation, removes other artifacts, and outperforms the conventional two-stage SR and convolving simulated room impulse response approach. We further demonstrate its ability to generate novel reverberation effects through feature manipulation.
Miipher-2: A Universal Speech Restoration Model for Million-Hour Scale Data Restoration
May 07, 2025



Training data cleaning is a new application for generative model-based speech restoration (SR). This paper introduces Miipher-2, an SR model designed for million-hour scale data, for training data cleaning for large-scale generative models like large language models. Key challenges addressed include generalization to unseen languages, operation without explicit conditioning (e.g., text, speaker ID), and computational efficiency. Miipher-2 utilizes a frozen, pre-trained Universal Speech Model (USM), supporting over 300 languages, as a robust, conditioning-free feature extractor. To optimize efficiency and minimize memory, Miipher-2 incorporates parallel adapters for predicting clean USM features from noisy inputs and employs the WaneFit neural vocoder for waveform synthesis. These components were trained on 3,000 hours of multi-lingual, studio-quality recordings with augmented degradations, while USM parameters remained fixed. Experimental results demonstrate Miipher-2's superior or comparable performance to conventional SR models in word-error-rate, speaker similarity, and both objective and subjective sound quality scores across all tested languages. Miipher-2 operates efficiently on consumer-grade accelerators, achieving a real-time factor of 0.0078, enabling the processing of a million-hour speech dataset in approximately three days using only 100 such accelerators.
Universal Score-based Speech Enhancement with High Content Preservation
Jun 18, 2024



We propose UNIVERSE++, a universal speech enhancement method based on score-based diffusion and adversarial training. Specifically, we improve the existing UNIVERSE model that decouples clean speech feature extraction and diffusion. Our contributions are three-fold. First, we make several modifications to the network architecture, improving training stability and final performance. Second, we introduce an adversarial loss to promote learning high quality speech features. Third, we propose a low-rank adaptation scheme with a phoneme fidelity loss to improve content preservation in the enhanced speech. In the experiments, we train a universal enhancement model on a large scale dataset of speech degraded by noise, reverberation, and various distortions. The results on multiple public benchmark datasets demonstrate that UNIVERSE++ compares favorably to both discriminative and generative baselines for a wide range of qualitative and intelligibility metrics.
URGENT Challenge: Universality, Robustness, and Generalizability For Speech Enhancement
Jun 07, 2024



The last decade has witnessed significant advancements in deep learning-based speech enhancement (SE). However, most existing SE research has limitations on the coverage of SE sub-tasks, data diversity and amount, and evaluation metrics. To fill this gap and promote research toward universal SE, we establish a new SE challenge, named URGENT, to focus on the universality, robustness, and generalizability of SE. We aim to extend the SE definition to cover different sub-tasks to explore the limits of SE models, starting from denoising, dereverberation, bandwidth extension, and declipping. A novel framework is proposed to unify all these sub-tasks in a single model, allowing the use of all existing SE approaches. We collected public speech and noise data from different domains to construct diverse evaluation data. Finally, we discuss the insights gained from our preliminary baseline experiments based on both generative and discriminative SE methods with 12 curated metrics.
TorchAudio 2.1: Advancing speech recognition, self-supervised learning, and audio processing components for PyTorch
Oct 27, 2023



TorchAudio is an open-source audio and speech processing library built for PyTorch. It aims to accelerate the research and development of audio and speech technologies by providing well-designed, easy-to-use, and performant PyTorch components. Its contributors routinely engage with users to understand their needs and fulfill them by developing impactful features. Here, we survey TorchAudio's development principles and contents and highlight key features we include in its latest version (2.1): self-supervised learning pre-trained pipelines and training recipes, high-performance CTC decoders, speech recognition models and training recipes, advanced media I/O capabilities, and tools for performing forced alignment, multi-channel speech enhancement, and reference-less speech assessment. For a selection of these features, through empirical studies, we demonstrate their efficacy and show that they achieve competitive or state-of-the-art performance.
Neural Diarization with Non-autoregressive Intermediate Attractors
Mar 13, 2023End-to-end neural diarization (EEND) with encoder-decoder-based attractors (EDA) is a promising method to handle the whole speaker diarization problem simultaneously with a single neural network. While the EEND model can produce all frame-level speaker labels simultaneously, it disregards output label dependency. In this work, we propose a novel EEND model that introduces the label dependency between frames. The proposed method generates non-autoregressive intermediate attractors to produce speaker labels at the lower layers and conditions the subsequent layers with these labels. While the proposed model works in a non-autoregressive manner, the speaker labels are refined by referring to the whole sequence of intermediate labels. The experiments with the two-speaker CALLHOME dataset show that the intermediate labels with the proposed non-autoregressive intermediate attractors boost the diarization performance. The proposed method with the deeper network benefits more from the intermediate labels, resulting in better performance and training throughput than EEND-EDA.
Diffusion-based Generative Speech Source Separation
Nov 02, 2022We propose DiffSep, a new single channel source separation method based on score-matching of a stochastic differential equation (SDE). We craft a tailored continuous time diffusion-mixing process starting from the separated sources and converging to a Gaussian distribution centered on their mixture. This formulation lets us apply the machinery of score-based generative modelling. First, we train a neural network to approximate the score function of the marginal probabilities or the diffusion-mixing process. Then, we use it to solve the reverse time SDE that progressively separates the sources starting from their mixture. We propose a modified training strategy to handle model mismatch and source permutation ambiguity. Experiments on the WSJ0 2mix dataset demonstrate the potential of the method. Furthermore, the method is also suitable for speech enhancement and shows performance competitive with prior work on the VoiceBank-DEMAND dataset.
ESPnet-SE++: Speech Enhancement for Robust Speech Recognition, Translation, and Understanding
Jul 19, 2022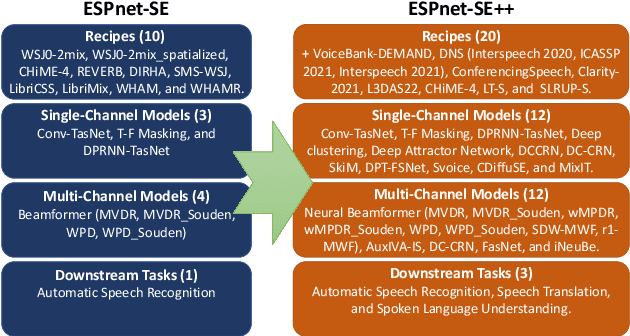
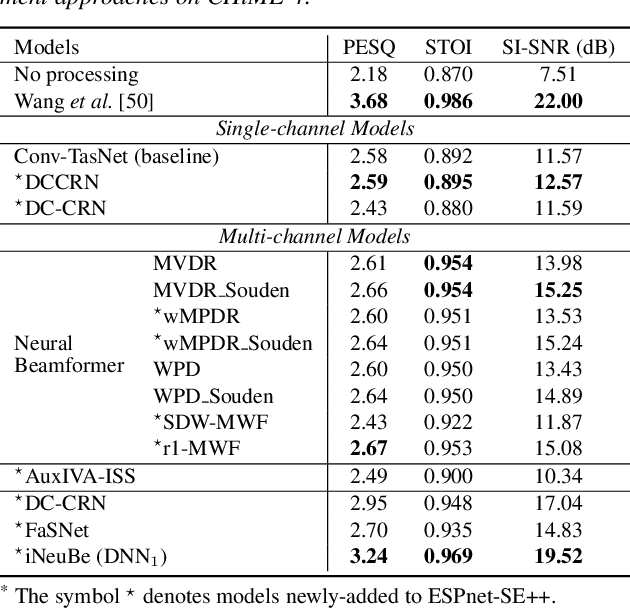
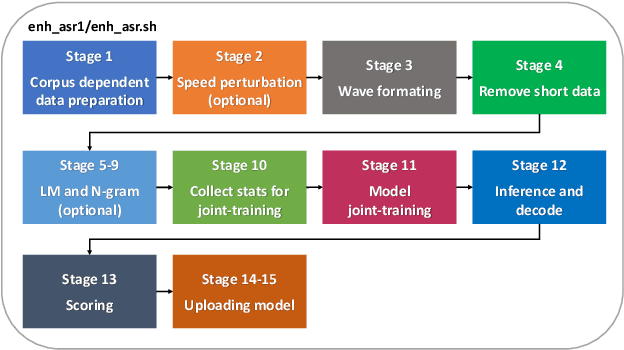
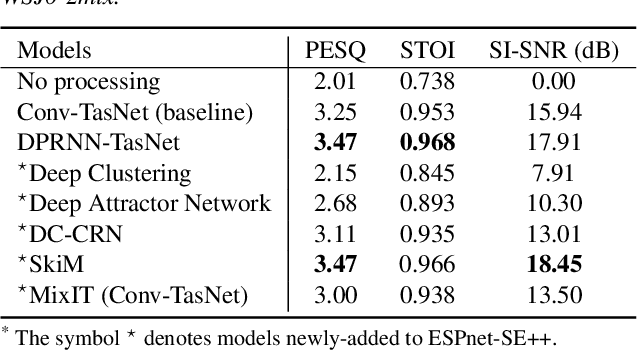
This paper presents recent progress on integrating speech separation and enhancement (SSE) into the ESPnet toolkit. Compared with the previous ESPnet-SE work, numerous features have been added, including recent state-of-the-art speech enhancement models with their respective training and evaluation recipes. Importantly, a new interface has been designed to flexibly combine speech enhancement front-ends with other tasks, including automatic speech recognition (ASR), speech translation (ST), and spoken language understanding (SLU). To showcase such integration, we performed experiments on carefully designed synthetic datasets for noisy-reverberant multi-channel ST and SLU tasks, which can be used as benchmark corpora for future research. In addition to these new tasks, we also use CHiME-4 and WSJ0-2Mix to benchmark multi- and single-channel SE approaches. Results show that the integration of SE front-ends with back-end tasks is a promising research direction even for tasks besides ASR, especially in the multi-channel scenario. The code is available online at https://github.com/ESPnet/ESPnet. The multi-channel ST and SLU datasets, which are another contribution of this work, are released on HuggingFace.