 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKisMATH: Do LLMs Have Knowledge of Implicit Structures in Mathematical Reasoning?
Jul 15, 2025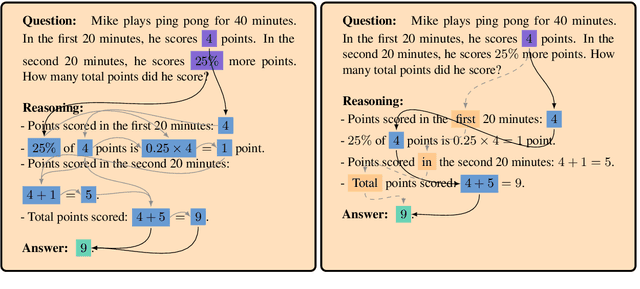
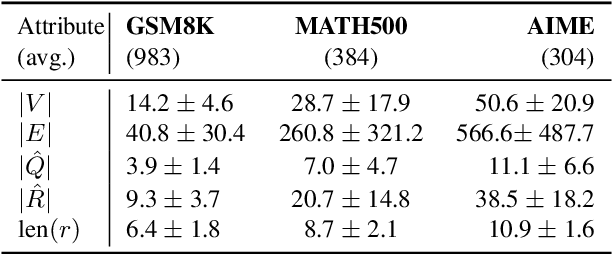
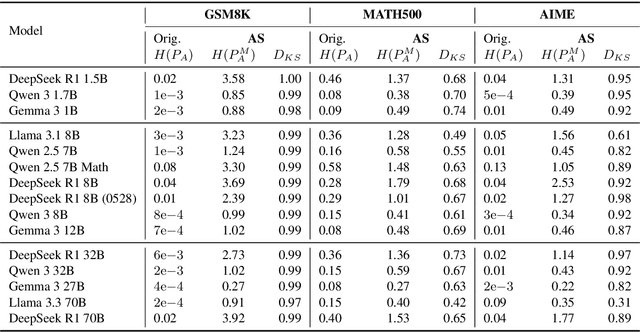
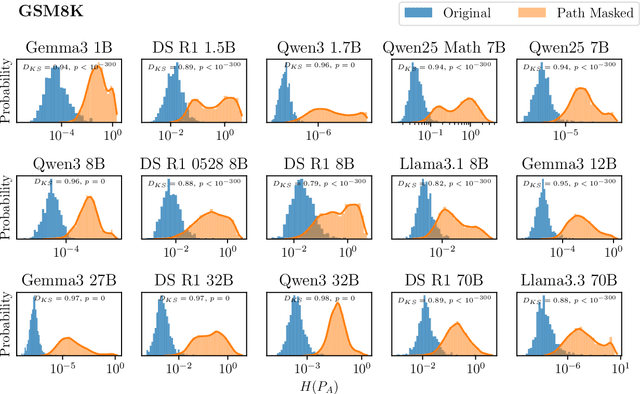
Chain-of-thought traces have been shown to improve performance of large language models in a plethora of reasoning tasks, yet there is no consensus on the mechanism through which this performance boost is achieved. To shed more light on this, we introduce Causal CoT Graphs (CCGs), which are directed acyclic graphs automatically extracted from reasoning traces that model fine-grained causal dependencies in the language model output. A collection of $1671$ mathematical reasoning problems from MATH500, GSM8K and AIME, and their associated CCGs are compiled into our dataset -- \textbf{KisMATH}. Our detailed empirical analysis with 15 open-weight LLMs shows that (i) reasoning nodes in the CCG are mediators for the final answer, a condition necessary for reasoning; and (ii) LLMs emphasise reasoning paths given by the CCG, indicating that models internally realise structures akin to our graphs. KisMATH enables controlled, graph-aligned interventions and opens up avenues for further investigation into the role of chain-of-thought in LLM reasoning.
sudoLLM : On Multi-role Alignment of Language Models
May 20, 2025



User authorization-based access privileges are a key feature in many safety-critical systems, but have thus far been absent from the large language model (LLM) realm. In this work, drawing inspiration from such access control systems, we introduce sudoLLM, a novel framework that results in multi-role aligned LLMs, i.e., LLMs that account for, and behave in accordance with, user access rights. sudoLLM injects subtle user-based biases into queries and trains an LLM to utilize this bias signal in order to produce sensitive information if and only if the user is authorized. We present empirical results demonstrating that this approach shows substantially improved alignment, generalization, and resistance to prompt-based jailbreaking attacks. The persistent tension between the language modeling objective and safety alignment, which is often exploited to jailbreak LLMs, is somewhat resolved with the aid of the injected bias signal. Our framework is meant as an additional security layer, and complements existing guardrail mechanisms for enhanced end-to-end safety with LLMs.
On Measuring Intrinsic Causal Attributions in Deep Neural Networks
May 14, 2025Quantifying the causal influence of input features within neural networks has become a topic of increasing interest. Existing approaches typically assess direct, indirect, and total causal effects. This work treats NNs as structural causal models (SCMs) and extends our focus to include intrinsic causal contributions (ICC). We propose an identifiable generative post-hoc framework for quantifying ICC. We also draw a relationship between ICC and Sobol' indices. Our experiments on synthetic and real-world datasets demonstrate that ICC generates more intuitive and reliable explanations compared to existing global explanation techniques.
Factual Inconsistency in Data-to-Text Generation Scales Exponentially with LLM Size: A Statistical Validation
Feb 17, 2025



Monitoring factual inconsistency is essential for ensuring trustworthiness in data-to-text generation (D2T). While large language models (LLMs) have demonstrated exceptional performance across various D2T tasks, previous studies on scaling laws have primarily focused on generalization error through power law scaling to LLM size (i.e., the number of model parameters). However, no research has examined the impact of LLM size on factual inconsistency in D2T. In this paper, we investigate how factual inconsistency in D2T scales with LLM size by exploring two scaling laws: power law and exponential scaling. To rigorously evaluate and compare these scaling laws, we employ a statistical validation framework consisting of three key stages: predictive performance estimation, goodness-of-fit assessment, and comparative analysis. For a comprehensive empirical study, we analyze three popular LLM families across five D2T datasets, measuring factual inconsistency inversely using four state-of-the-art consistency metrics. Our findings, based on exhaustive empirical results and validated through our framework, reveal that, contrary to the widely assumed power law scaling, factual inconsistency in D2T follows an exponential scaling with LLM size.
Deep Learning Based Recalibration of SDSS and DESI BAO Alleviates Hubble and Clustering Tensions
Dec 19, 2024Conventional calibration of Baryon Acoustic Oscillations (BAO) data relies on estimation of the sound horizon at drag epoch $r_d$ from early universe observations by assuming a cosmological model. We present a recalibration of two independent BAO datasets, SDSS and DESI, by employing deep learning techniques for model-independent estimation of $r_d$, and explore the impacts on $\Lambda$CDM cosmological parameters. Significant reductions in both Hubble ($H_0$) and clustering ($S_8$) tensions are observed for both the recalibrated datasets. Moderate shifts in some other parameters hint towards further exploration of such data-driven approaches.
An Extensive Evaluation of Factual Consistency in Large Language Models for Data-to-Text Generation
Nov 28, 2024



Large Language Models (LLMs) have shown exceptional performance across various Data-to-Text Generation (DTG) tasks. However, generating factually consistent text in DTG remains challenging for LLMs. Despite this, in-depth evaluations of LLM factual consistency for DTG remain missing in the current literature. This paper addresses this gap by providing an extensive evaluation of factual consistency in LLMs for DTG. Our evaluation covers five widely used DTG datasets (E2E, ViGGo, WikiTableText, DART, and WebNLG) and five prominent LLM families (T5, BART, OPT, BLOOM, and Llama 2). To ensure a thorough evaluation of factual consistency, we use four state-of-the-art automatic metrics and include essential human assessments. Our extensive evaluations reveals three key findings regarding factual consistency in LLMs for DTG. First, Llama 2 often excels in generating factually consistent text, although smaller models like T5 and BART can achieve strong factual consistency on larger, lexically less-diverse datasets. Second, the average rate of change (AROC) indicates that increasing model size (number of model trainable parameters) generally enhances factual consistency of LLMs in DTG. Third, we observe that source-reference divergence (i.e., when the reference text diverges semantically from the source) typically reduces the factual consistency of LLMs in DTG.
Impact of Model Size on Fine-tuned LLM Performance in Data-to-Text Generation: A State-of-the-Art Investigation
Jul 19, 2024Data-to-text (D2T) generation aims to generate human-readable text from semi-structured data, such as tables and graphs. The recent success of D2T is largely attributed to advancements in LLMs. Despite the success of LLMs, no research has been conducted to illustrate the impact of model size on the performance of fine-tuned LLMs for D2T tasks. D2T model performance is typically assessed based on three key qualities: \textit{readability} (indicates fluency and coherence), \textit{informativeness} (measures content similarity), and \textit{faithfulness} (assesses consistency of factual information). It is currently uncertain whether increasing the size of LLMs effectively improves performance in D2T tasks across these three qualities. The objective of this study is to investigate the performance of fine-tuned LLMs in D2T tasks in terms of model size. Through extensive comparative analysis, we aim to elucidate both the advantages and limitations of scaling model sizes across five widely used D2T datasets (E2E, ViGGo, WikiTableText, DART, and WebNLG) and twelve state-of-the-art LLMs with varying sizes from five different LLM families (T5, BART, OPT, BLOOM, and Llama 2). To comprehensively cover all the three essential qualities of D2T models, we incorporate six widely recognized automatic metrics -- \textsc{BLEU}, \textsc{METEOR}, \textsc{BERTScore}, \textsc{MoverScore}, \textsc{Parent}, and \textsc{BARTScore}. We also provide an in-depth analysis of LLM performance concerning model size in the presence of source-reference divergence, a critical aspect of D2T tasks. Our investigation reveals that increasing LLM size enhances \textit{readability} and \textit{informativeness} in D2T tasks, but larger (in terms of size) LLMs may sacrifice \textit{faithfulness}. Moreover, small-sized LLMs show more resilience than larger ones when source-reference divergence is present.
Language Models are Crossword Solvers
Jun 14, 2024



Crosswords are a form of word puzzle that require a solver to demonstrate a high degree of proficiency in natural language understanding, wordplay, reasoning, and world knowledge, along with adherence to character and length constraints. In this paper we tackle the challenge of solving crosswords with Large Language Models (LLMs). We demonstrate that the current generation of state-of-the art (SoTA) language models show significant competence at deciphering cryptic crossword clues, and outperform previously reported SoTA results by a factor of 2-3 in relevant benchmarks. We also develop a search algorithm that builds off this performance to tackle the problem of solving full crossword grids with LLMs for the very first time, achieving an accuracy of 93\% on New York Times crossword puzzles. Contrary to previous work in this area which concluded that LLMs lag human expert performance significantly, our research suggests this gap is a lot narrower.
LADDER: Revisiting the Cosmic Distance Ladder with Deep Learning Approaches and Exploring its Applications
Jan 30, 2024We investigate the prospect of reconstructing the ``cosmic distance ladder'' of the Universe using a novel deep learning framework called LADDER - Learning Algorithm for Deep Distance Estimation and Reconstruction. LADDER is trained on the apparent magnitude data from the Pantheon Type Ia supernovae compilation, incorporating the full covariance information among data points, to produce predictions along with corresponding errors. After employing several validation tests with a number of deep learning models, we pick LADDER as the best performing one. We then demonstrate applications of our method in the cosmological context, that include serving as a model-independent tool for consistency checks for other datasets like baryon acoustic oscillations, calibration of high-redshift datasets such as gamma ray bursts, use as a model-independent mock catalog generator for future probes, etc. Our analysis advocates for interesting yet cautious consideration of machine learning applications in these contexts.
HCDIR: End-to-end Hate Context Detection, and Intensity Reduction model for online comments
Dec 20, 2023



Warning: This paper contains examples of the language that some people may find offensive. Detecting and reducing hateful, abusive, offensive comments is a critical and challenging task on social media. Moreover, few studies aim to mitigate the intensity of hate speech. While studies have shown that context-level semantics are crucial for detecting hateful comments, most of this research focuses on English due to the ample datasets available. In contrast, low-resource languages, like Indian languages, remain under-researched because of limited datasets. Contrary to hate speech detection, hate intensity reduction remains unexplored in high-resource and low-resource languages. In this paper, we propose a novel end-to-end model, HCDIR, for Hate Context Detection, and Hate Intensity Reduction in social media posts. First, we fine-tuned several pre-trained language models to detect hateful comments to ascertain the best-performing hateful comments detection model. Then, we identified the contextual hateful words. Identification of such hateful words is justified through the state-of-the-art explainable learning model, i.e., Integrated Gradient (IG). Lastly, the Masked Language Modeling (MLM) model has been employed to capture domain-specific nuances to reduce hate intensity. We masked the 50\% hateful words of the comments identified as hateful and predicted the alternative words for these masked terms to generate convincing sentences. An optimal replacement for the original hate comments from the feasible sentences is preferred. Extensive experiments have been conducted on several recent datasets using automatic metric-based evaluation (BERTScore) and thorough human evaluation. To enhance the faithfulness in human evaluation, we arranged a group of three human annotators with varied expertise.