 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Audiovisual Speech Processing via MUTUD: Multimodal Training and Unimodal Deployment
Jan 30, 2025



Building reliable speech systems often requires combining multiple modalities, like audio and visual cues. While such multimodal solutions frequently lead to improvements in performance and may even be critical in certain cases, they come with several constraints such as increased sensory requirements, computational cost, and modality synchronization, to mention a few. These challenges constrain the direct uses of these multimodal solutions in real-world applications. In this work, we develop approaches where the learning happens with all available modalities but the deployment or inference is done with just one or reduced modalities. To do so, we propose a Multimodal Training and Unimodal Deployment (MUTUD) framework which includes a Temporally Aligned Modality feature Estimation (TAME) module that can estimate information from missing modality using modalities present during inference. This innovative approach facilitates the integration of information across different modalities, enhancing the overall inference process by leveraging the strengths of each modality to compensate for the absence of certain modalities during inference. We apply MUTUD to various audiovisual speech tasks and show that it can reduce the performance gap between the multimodal and corresponding unimodal models to a considerable extent. MUTUD can achieve this while reducing the model size and compute compared to multimodal models, in some cases by almost 80%.
Let's Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation
Jun 12, 2024



In this paper, we introduce a novel Face-to-Face spoken dialogue model. It processes audio-visual speech from user input and generates audio-visual speech as the response, marking the initial step towards creating an avatar chatbot system without relying on intermediate text. To this end, we newly introduce MultiDialog, the first large-scale multimodal (i.e., audio and visual) spoken dialogue corpus containing 340 hours of approximately 9,000 dialogues, recorded based on the open domain dialogue dataset, TopicalChat. The MultiDialog contains parallel audio-visual recordings of conversation partners acting according to the given script with emotion annotations, which we expect to open up research opportunities in multimodal synthesis. Our Face-to-Face spoken dialogue model incorporates a textually pretrained large language model and adapts it into the audio-visual spoken dialogue domain by incorporating speech-text joint pretraining. Through extensive experiments, we validate the effectiveness of our model in facilitating a face-to-face conversation. Demo and data are available at https://multidialog.github.io and https://huggingface.co/datasets/IVLLab/MultiDialog, respectively.
Intuitive Multilingual Audio-Visual Speech Recognition with a Single-Trained Model
Oct 23, 2023We present a novel approach to multilingual audio-visual speech recognition tasks by introducing a single model on a multilingual dataset. Motivated by a human cognitive system where humans can intuitively distinguish different languages without any conscious effort or guidance, we propose a model that can capture which language is given as an input speech by distinguishing the inherent similarities and differences between languages. To do so, we design a prompt fine-tuning technique into the largely pre-trained audio-visual representation model so that the network can recognize the language class as well as the speech with the corresponding language. Our work contributes to developing robust and efficient multilingual audio-visual speech recognition systems, reducing the need for language-specific models.
DiffV2S: Diffusion-based Video-to-Speech Synthesis with Vision-guided Speaker Embedding
Aug 15, 2023



Recent research has demonstrated impressive results in video-to-speech synthesis which involves reconstructing speech solely from visual input. However, previous works have struggled to accurately synthesize speech due to a lack of sufficient guidance for the model to infer the correct content with the appropriate sound. To resolve the issue, they have adopted an extra speaker embedding as a speaking style guidance from a reference auditory information. Nevertheless, it is not always possible to obtain the audio information from the corresponding video input, especially during the inference time. In this paper, we present a novel vision-guided speaker embedding extractor using a self-supervised pre-trained model and prompt tuning technique. In doing so, the rich speaker embedding information can be produced solely from input visual information, and the extra audio information is not necessary during the inference time. Using the extracted vision-guided speaker embedding representations, we further develop a diffusion-based video-to-speech synthesis model, so called DiffV2S, conditioned on those speaker embeddings and the visual representation extracted from the input video. The proposed DiffV2S not only maintains phoneme details contained in the input video frames, but also creates a highly intelligible mel-spectrogram in which the speaker identities of the multiple speakers are all preserved. Our experimental results show that DiffV2S achieves the state-of-the-art performance compared to the previous video-to-speech synthesis technique.
Watch or Listen: Robust Audio-Visual Speech Recognition with Visual Corruption Modeling and Reliability Scoring
Mar 20, 2023This paper deals with Audio-Visual Speech Recognition (AVSR) under multimodal input corruption situations where audio inputs and visual inputs are both corrupted, which is not well addressed in previous research directions. Previous studies have focused on how to complement the corrupted audio inputs with the clean visual inputs with the assumption of the availability of clean visual inputs. However, in real life, clean visual inputs are not always accessible and can even be corrupted by occluded lip regions or noises. Thus, we firstly analyze that the previous AVSR models are not indeed robust to the corruption of multimodal input streams, the audio and the visual inputs, compared to uni-modal models. Then, we design multimodal input corruption modeling to develop robust AVSR models. Lastly, we propose a novel AVSR framework, namely Audio-Visual Reliability Scoring module (AV-RelScore), that is robust to the corrupted multimodal inputs. The AV-RelScore can determine which input modal stream is reliable or not for the prediction and also can exploit the more reliable streams in prediction. The effectiveness of the proposed method is evaluated with comprehensive experiments on popular benchmark databases, LRS2 and LRS3. We also show that the reliability scores obtained by AV-RelScore well reflect the degree of corruption and make the proposed model focus on the reliable multimodal representations.
Lip-to-Speech Synthesis in the Wild with Multi-task Learning
Feb 17, 2023



Recent studies have shown impressive performance in Lip-to-speech synthesis that aims to reconstruct speech from visual information alone. However, they have been suffering from synthesizing accurate speech in the wild, due to insufficient supervision for guiding the model to infer the correct content. Distinct from the previous methods, in this paper, we develop a powerful Lip2Speech method that can reconstruct speech with correct contents from the input lip movements, even in a wild environment. To this end, we design multi-task learning that guides the model using multimodal supervision, i.e., text and audio, to complement the insufficient word representations of acoustic feature reconstruction loss. Thus, the proposed framework brings the advantage of synthesizing speech containing the right content of multiple speakers with unconstrained sentences. We verify the effectiveness of the proposed method using LRS2, LRS3, and LRW datasets.
SyncTalkFace: Talking Face Generation with Precise Lip-Syncing via Audio-Lip Memory
Nov 03, 2022



The challenge of talking face generation from speech lies in aligning two different modal information, audio and video, such that the mouth region corresponds to input audio. Previous methods either exploit audio-visual representation learning or leverage intermediate structural information such as landmarks and 3D models. However, they struggle to synthesize fine details of the lips varying at the phoneme level as they do not sufficiently provide visual information of the lips at the video synthesis step. To overcome this limitation, our work proposes Audio-Lip Memory that brings in visual information of the mouth region corresponding to input audio and enforces fine-grained audio-visual coherence. It stores lip motion features from sequential ground truth images in the value memory and aligns them with corresponding audio features so that they can be retrieved using audio input at inference time. Therefore, using the retrieved lip motion features as visual hints, it can easily correlate audio with visual dynamics in the synthesis step. By analyzing the memory, we demonstrate that unique lip features are stored in each memory slot at the phoneme level, capturing subtle lip motion based on memory addressing. In addition, we introduce visual-visual synchronization loss which can enhance lip-syncing performance when used along with audio-visual synchronization loss in our model. Extensive experiments are performed to verify that our method generates high-quality video with mouth shapes that best align with the input audio, outperforming previous state-of-the-art methods.
Visual Context-driven Audio Feature Enhancement for Robust End-to-End Audio-Visual Speech Recognition
Jul 13, 2022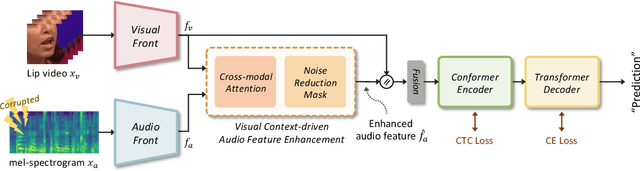
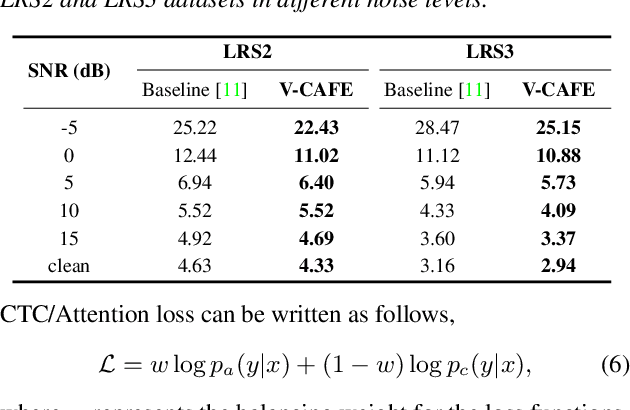
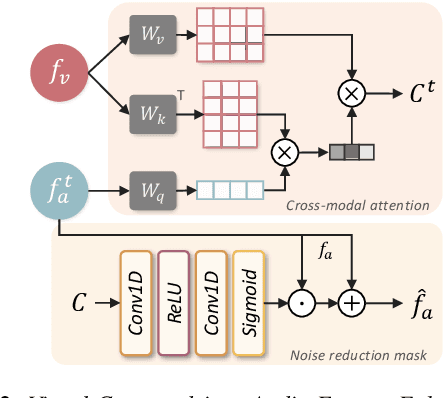
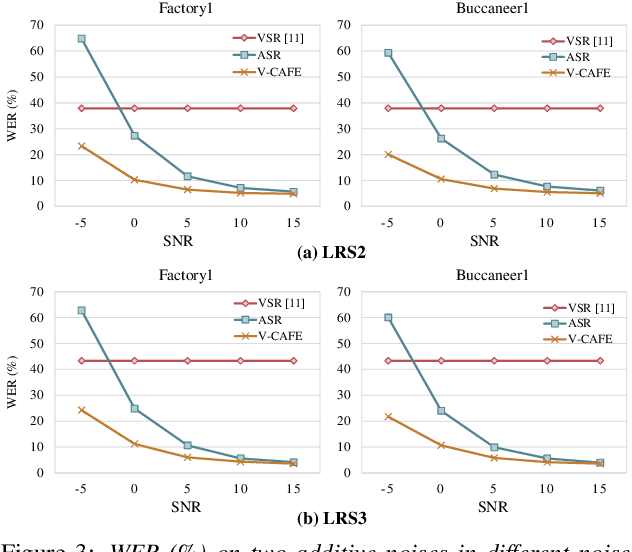
This paper focuses on designing a noise-robust end-to-end Audio-Visual Speech Recognition (AVSR) system. To this end, we propose Visual Context-driven Audio Feature Enhancement module (V-CAFE) to enhance the input noisy audio speech with a help of audio-visual correspondence. The proposed V-CAFE is designed to capture the transition of lip movements, namely visual context and to generate a noise reduction mask by considering the obtained visual context. Through context-dependent modeling, the ambiguity in viseme-to-phoneme mapping can be refined for mask generation. The noisy representations are masked out with the noise reduction mask resulting in enhanced audio features. The enhanced audio features are fused with the visual features and taken to an encoder-decoder model composed of Conformer and Transformer for speech recognition. We show the proposed end-to-end AVSR with the V-CAFE can further improve the noise-robustness of AVSR. The effectiveness of the proposed method is evaluated in noisy speech recognition and overlapped speech recognition experiments using the two largest audio-visual datasets, LRS2 and LRS3.
VisageSynTalk: Unseen Speaker Video-to-Speech Synthesis via Speech-Visage Feature Selection
Jun 15, 2022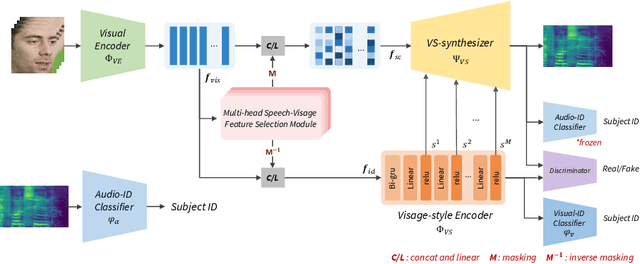
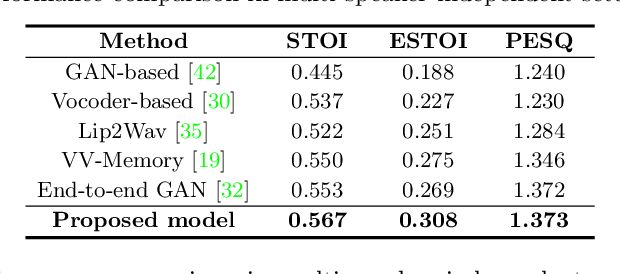
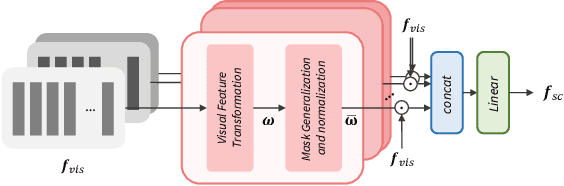
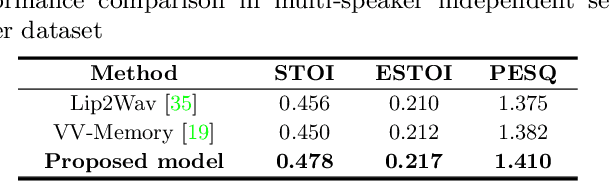
The goal of this work is to reconstruct speech from a silent talking face video. Recent studies have shown impressive performance on synthesizing speech from silent talking face videos. However, they have not explicitly considered on varying identity characteristics of different speakers, which place a challenge in the video-to-speech synthesis, and this becomes more critical in unseen-speaker settings. Distinct from the previous methods, our approach is to separate the speech content and the visage-style from a given silent talking face video. By guiding the model to independently focus on modeling the two representations, we can obtain the speech of high intelligibility from the model even when the input video of an unseen subject is given. To this end, we introduce speech-visage selection module that separates the speech content and the speaker identity from the visual features of the input video. The disentangled representations are jointly incorporated to synthesize speech through visage-style based synthesizer which generates speech by coating the visage-styles while maintaining the speech content. Thus, the proposed framework brings the advantage of synthesizing the speech containing the right content even when the silent talking face video of an unseen subject is given. We validate the effectiveness of the proposed framework on the GRID, TCD-TIMIT volunteer, and LRW datasets. The synthesized speech can be heard in supplementary materials.
Lip to Speech Synthesis with Visual Context Attentional GAN
Apr 04, 2022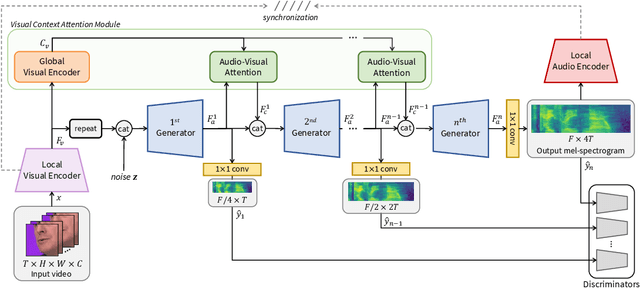

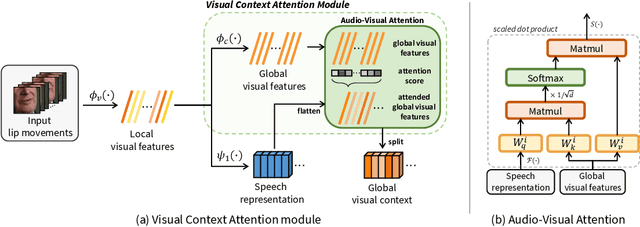
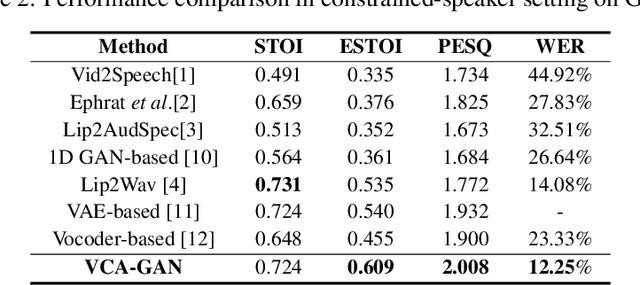
In this paper, we propose a novel lip-to-speech generative adversarial network, Visual Context Attentional GAN (VCA-GAN), which can jointly model local and global lip movements during speech synthesis. Specifically, the proposed VCA-GAN synthesizes the speech from local lip visual features by finding a mapping function of viseme-to-phoneme, while global visual context is embedded into the intermediate layers of the generator to clarify the ambiguity in the mapping induced by homophene. To achieve this, a visual context attention module is proposed where it encodes global representations from the local visual features, and provides the desired global visual context corresponding to the given coarse speech representation to the generator through audio-visual attention. In addition to the explicit modelling of local and global visual representations, synchronization learning is introduced as a form of contrastive learning that guides the generator to synthesize a speech in sync with the given input lip movements. Extensive experiments demonstrate that the proposed VCA-GAN outperforms existing state-of-the-art and is able to effectively synthesize the speech from multi-speaker that has been barely handled in the previous works.