 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Finnish Parliament ASR corpus - Analysis, benchmarks and statistics
Mar 28, 2022
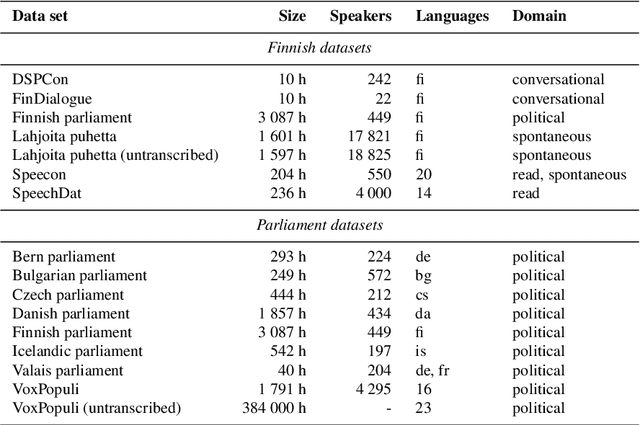
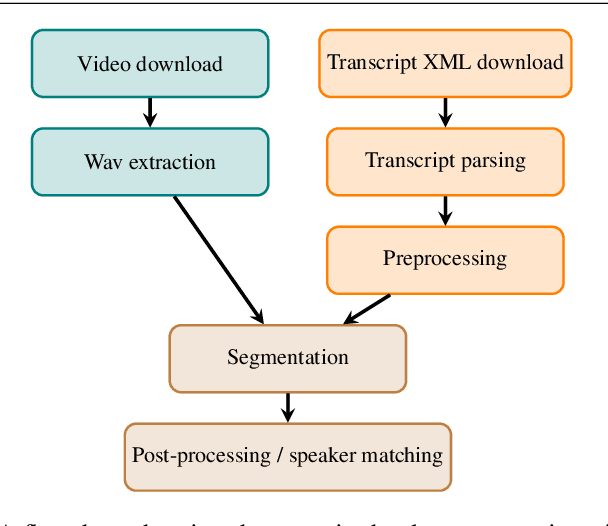

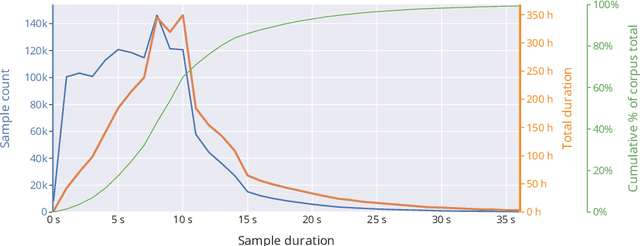
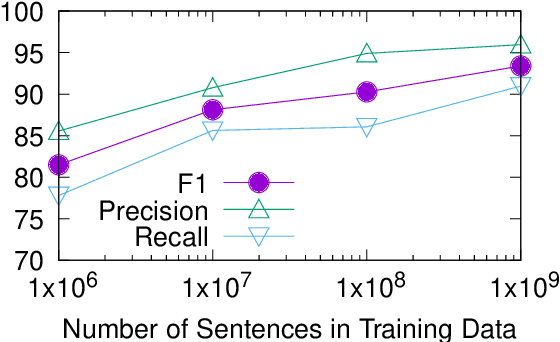
Public sources like parliament meeting recordings and transcripts provide ever-growing material for the training and evaluation of automatic speech recognition (ASR) systems. In this paper, we publish and analyse the Finnish parliament ASR corpus, the largest publicly available collection of manually transcribed speech data for Finnish with over 3000 hours of speech and 449 speakers for which it provides rich demographic metadata. This corpus builds on earlier initial work, and as a result the corpus has a natural split into two training subsets from two periods of time. Similarly, there are two official, corrected test sets covering different times, setting an ASR task with longitudinal distribution-shift characteristics. An official development set is also provided. We develop a complete Kaldi-based data preparation pipeline, and hidden Markov model (HMM), hybrid deep neural network (HMM-DNN) and attention-based encoder-decoder (AED) ASR recipes. We set benchmarks on the official test sets, as well as multiple other recently used test sets. Both temporal corpus subsets are already large, and we observe that beyond their scale, ASR performance on the official test sets plateaus, whereas other domains benefit from added data. The HMM-DNN and AED approaches are compared in a carefully matched equal data setting, with the HMM-DNN system consistently performing better. Finally, the variation of the ASR accuracy is compared between the speaker categories available in the parliament metadata to detect potential biases based on factors such as gender, age, and education.
The Volcspeech system for the ICASSP 2022 multi-channel multi-party meeting transcription challenge
Feb 10, 2022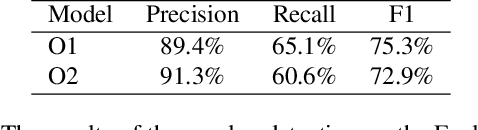
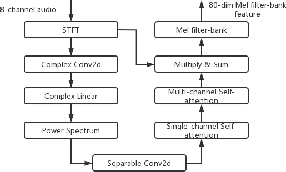
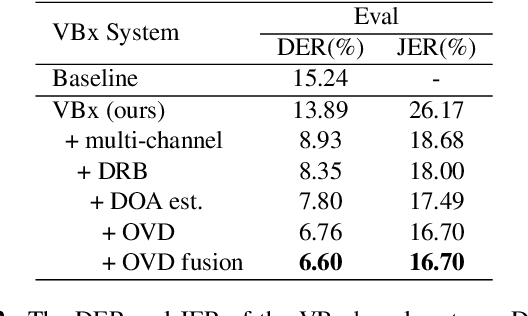
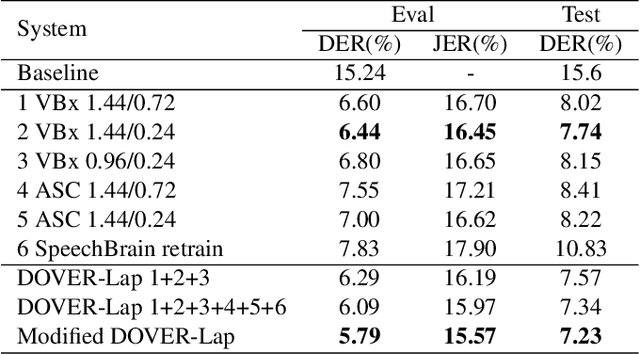
This paper describes our submission to ICASSP 2022 Multi-channel Multi-party Meeting Transcription (M2MeT) Challenge. For Track 1, we propose several approaches to empower the clustering-based speaker diarization system to handle overlapped speech. Front-end dereverberation and the direction-of-arrival (DOA) estimation are used to improve the accuracy of speaker diarization. Multi-channel combination and overlap detection are applied to reduce the missed speaker error. A modified DOVER-Lap is also proposed to fuse the results of different systems. We achieve the final DER of 5.79% on the Eval set and 7.23% on the Test set. For Track 2, we develop our system using the Conformer model in a joint CTC-attention architecture. Serialized output training is adopted to multi-speaker overlapped speech recognition. We propose a neural front-end module to model multi-channel audio and train the model end-to-end. Various data augmentation methods are utilized to mitigate over-fitting in the multi-channel multi-speaker E2E system. Transformer language model fusion is developed to achieve better performance. The final CER is 19.2% on the Eval set and 20.8% on the Test set.
Distillation-Resistant Watermarking for Model Protection in NLP
Oct 07, 2022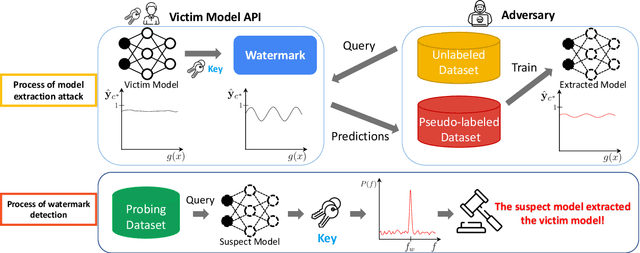
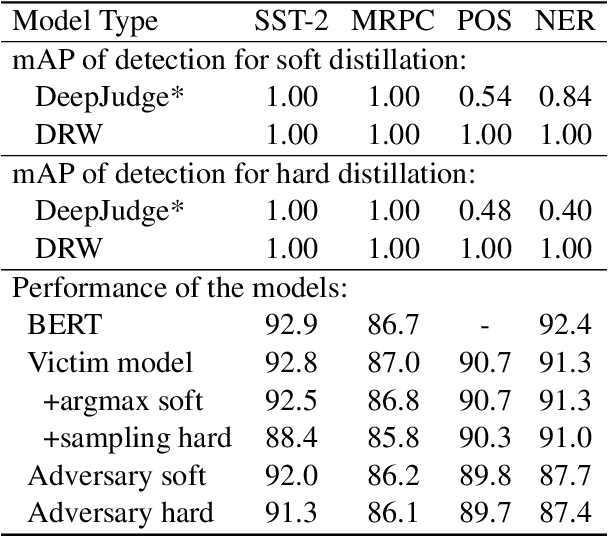
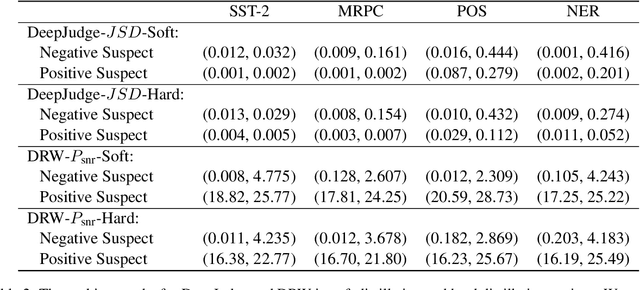
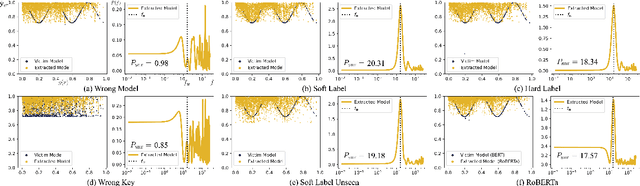
How can we protect the intellectual property of trained NLP models? Modern NLP models are prone to stealing by querying and distilling from their publicly exposed APIs. However, existing protection methods such as watermarking only work for images but are not applicable to text. We propose Distillation-Resistant Watermarking (DRW), a novel technique to protect NLP models from being stolen via distillation. DRW protects a model by injecting watermarks into the victim's prediction probability corresponding to a secret key and is able to detect such a key by probing a suspect model. We prove that a protected model still retains the original accuracy within a certain bound. We evaluate DRW on a diverse set of NLP tasks including text classification, part-of-speech tagging, and named entity recognition. Experiments show that DRW protects the original model and detects stealing suspects at 100% mean average precision for all four tasks while the prior method fails on two.
Position-Invariant Truecasing with a Word-and-Character Hierarchical Recurrent Neural Network
Sep 01, 2021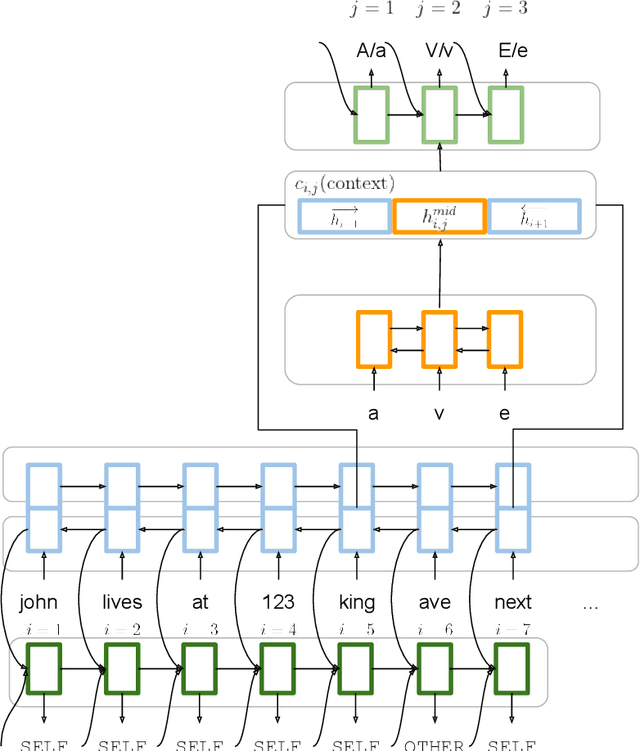
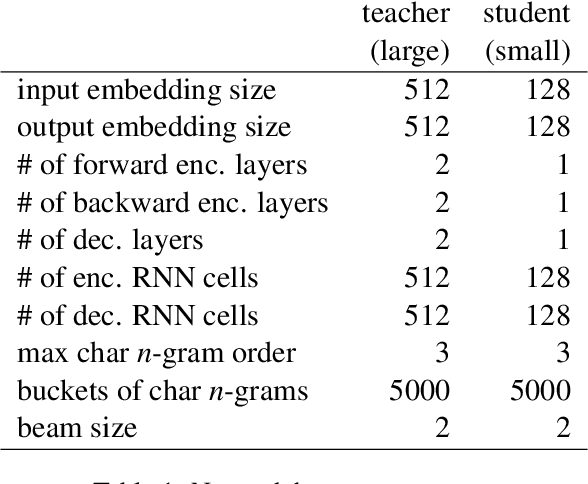

Truecasing is the task of restoring the correct case (uppercase or lowercase) of noisy text generated either by an automatic system for speech recognition or machine translation or by humans. It improves the performance of downstream NLP tasks such as named entity recognition and language modeling. We propose a fast, accurate and compact two-level hierarchical word-and-character-based recurrent neural network model, the first of its kind for this problem. Using sequence distillation, we also address the problem of truecasing while ignoring token positions in the sentence, i.e. in a position-invariant manner.
Enhancing ASR for Stuttered Speech with Limited Data Using Detect and Pass
Feb 08, 2022It is estimated that around 70 million people worldwide are affected by a speech disorder called stuttering. With recent advances in Automatic Speech Recognition (ASR), voice assistants are increasingly useful in our everyday lives. Many technologies in education, retail, telecommunication and healthcare can now be operated through voice. Unfortunately, these benefits are not accessible for People Who Stutter (PWS). We propose a simple but effective method called 'Detect and Pass' to make modern ASR systems accessible for People Who Stutter in a limited data setting. The algorithm uses a context aware classifier trained on a limited amount of data, to detect acoustic frames that contain stutter. To improve robustness on stuttered speech, this extra information is passed on to the ASR model to be utilized during inference. Our experiments show a reduction of 12.18% to 71.24% in Word Error Rate (WER) across various state of the art ASR systems. Upon varying the threshold of the associated posterior probability of stutter for each stacked frame used in determining low frame rate (LFR) acoustic features, we were able to determine an optimal setting that reduced the WER by 23.93% to 71.67% across different ASR systems.
Towards Structured Deep Neural Network for Automatic Speech Recognition
Nov 08, 2015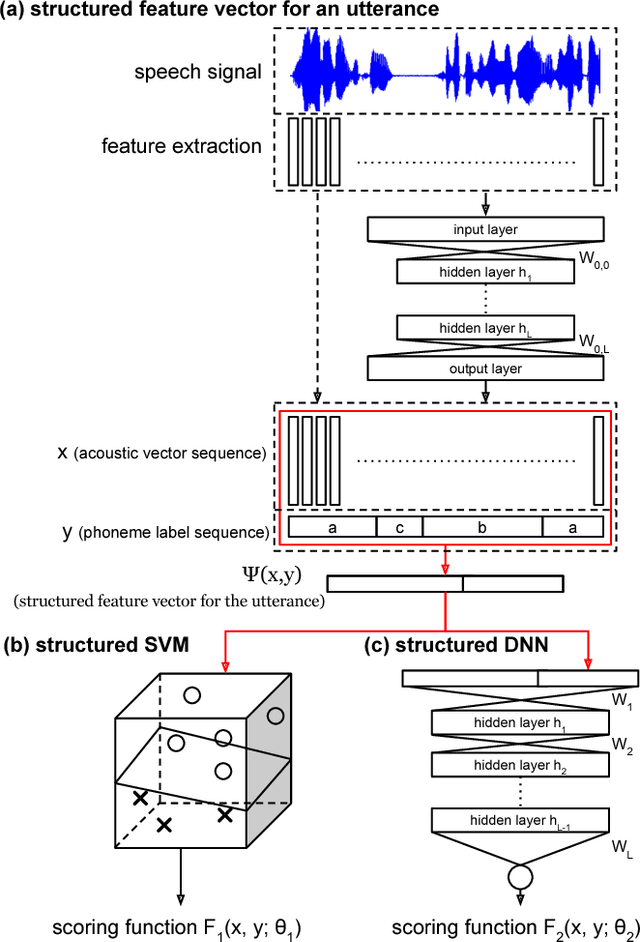

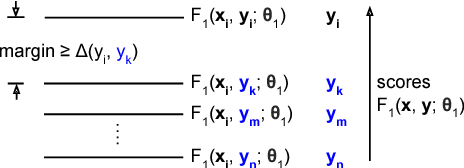
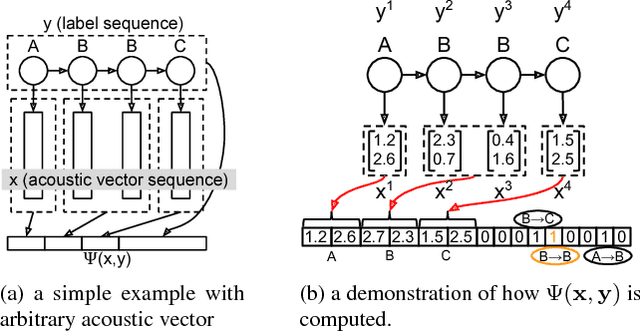
In this paper we propose the Structured Deep Neural Network (structured DNN) as a structured and deep learning framework. This approach can learn to find the best structured object (such as a label sequence) given a structured input (such as a vector sequence) by globally considering the mapping relationships between the structures rather than item by item. When automatic speech recognition is viewed as a special case of such a structured learning problem, where we have the acoustic vector sequence as the input and the phoneme label sequence as the output, it becomes possible to comprehensively learn utterance by utterance as a whole, rather than frame by frame. Structured Support Vector Machine (structured SVM) was proposed to perform ASR with structured learning previously, but limited by the linear nature of SVM. Here we propose structured DNN to use nonlinear transformations in multi-layers as a structured and deep learning approach. This approach was shown to beat structured SVM in preliminary experiments on TIMIT.
Magic dust for cross-lingual adaptation of monolingual wav2vec-2.0
Oct 07, 2021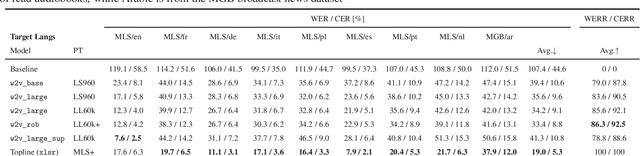
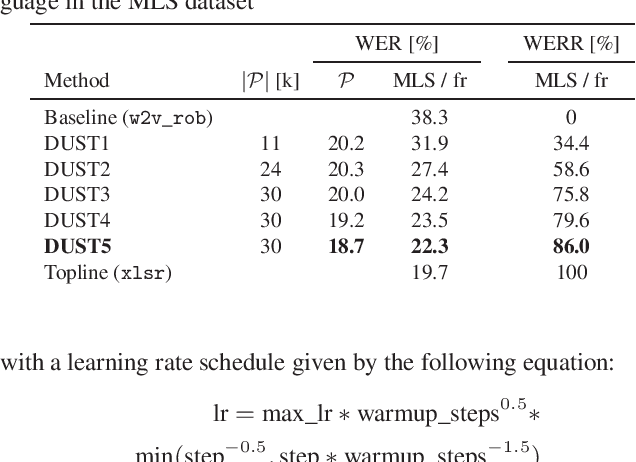
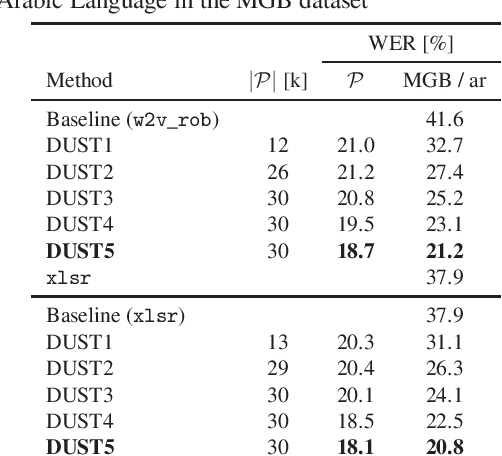
We propose a simple and effective cross-lingual transfer learning method to adapt monolingual wav2vec-2.0 models for Automatic Speech Recognition (ASR) in resource-scarce languages. We show that a monolingual wav2vec-2.0 is a good few-shot ASR learner in several languages. We improve its performance further via several iterations of Dropout Uncertainty-Driven Self-Training (DUST) by using a moderate-sized unlabeled speech dataset in the target language. A key finding of this work is that the adapted monolingual wav2vec-2.0 achieves similar performance as the topline multilingual XLSR model, which is trained on fifty-three languages, on the target language ASR task.
Feature Learning with Gaussian Restricted Boltzmann Machine for Robust Speech Recognition
Sep 23, 2013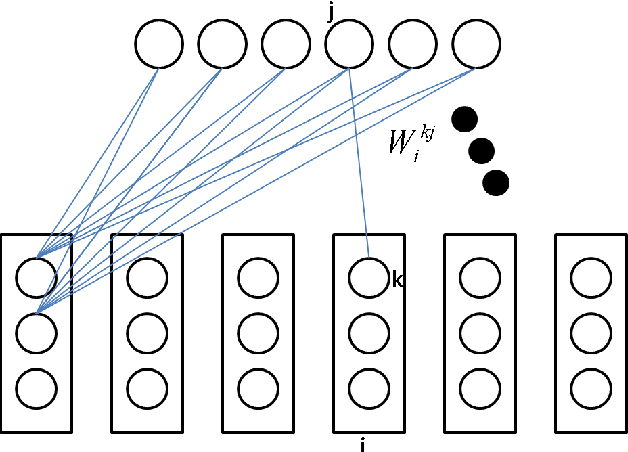
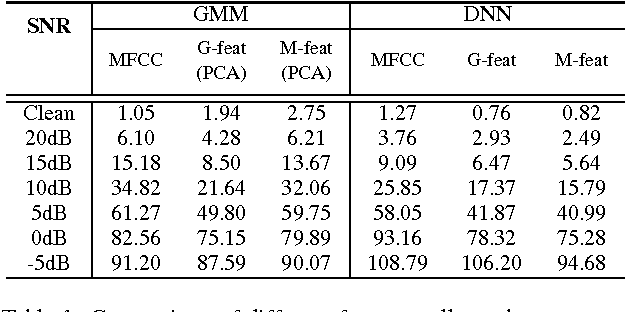
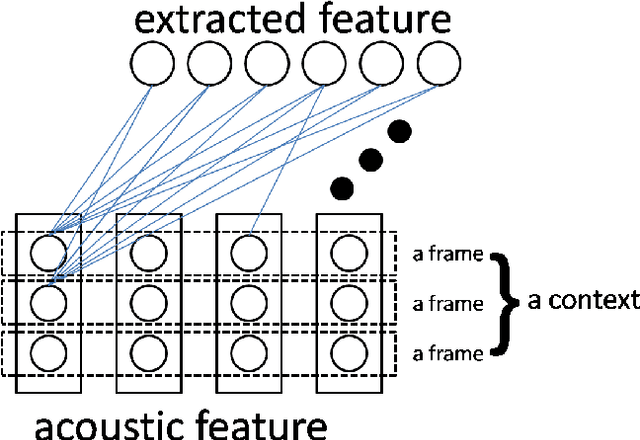
In this paper, we first present a new variant of Gaussian restricted Boltzmann machine (GRBM) called multivariate Gaussian restricted Boltzmann machine (MGRBM), with its definition and learning algorithm. Then we propose using a learned GRBM or MGRBM to extract better features for robust speech recognition. Our experiments on Aurora2 show that both GRBM-extracted and MGRBM-extracted feature performs much better than Mel-frequency cepstral coefficient (MFCC) with either HMM-GMM or hybrid HMM-deep neural network (DNN) acoustic model, and MGRBM-extracted feature is slightly better.
AISHELL-4: An Open Source Dataset for Speech Enhancement, Separation, Recognition and Speaker Diarization in Conference Scenario
Apr 08, 2021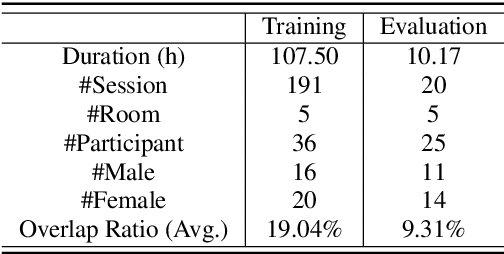
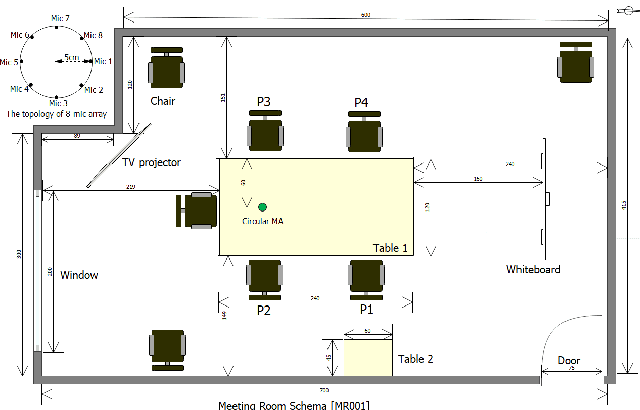

In this paper, we present AISHELL-4, a sizable real-recorded Mandarin speech dataset collected by 8-channel circular microphone array for speech processing in conference scenario. The dataset consists of 211 recorded meeting sessions, each containing 4 to 8 speakers, with a total length of 118 hours. This dataset aims to bride the advanced research on multi-speaker processing and the practical application scenario in three aspects. With real recorded meetings, AISHELL-4 provides realistic acoustics and rich natural speech characteristics in conversation such as short pause, speech overlap, quick speaker turn, noise, etc. Meanwhile, the accurate transcription and speaker voice activity are provided for each meeting in AISHELL-4. This allows the researchers to explore different aspects in meeting processing, ranging from individual tasks such as speech front-end processing, speech recognition and speaker diarization, to multi-modality modeling and joint optimization of relevant tasks. Given most open source dataset for multi-speaker tasks are in English, AISHELL-4 is the only Mandarin dataset for conversation speech, providing additional value for data diversity in speech community.
A Comparison of Techniques for Language Model Integration in Encoder-Decoder Speech Recognition
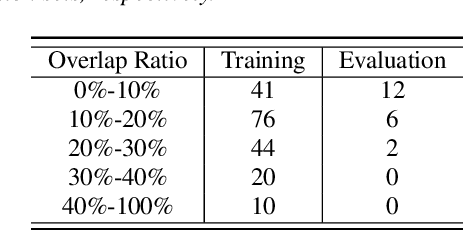
Jul 27, 2018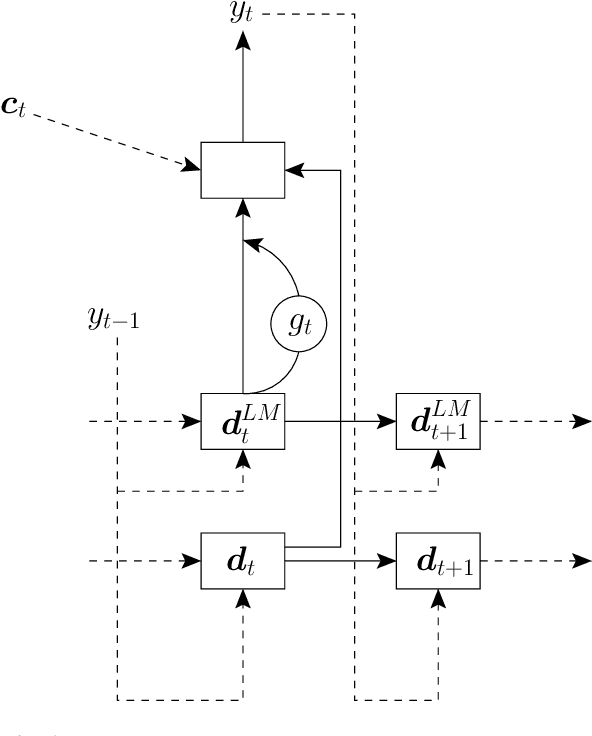
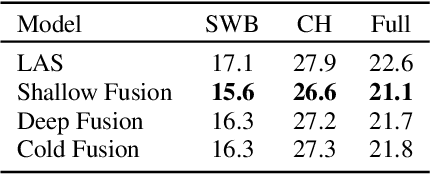
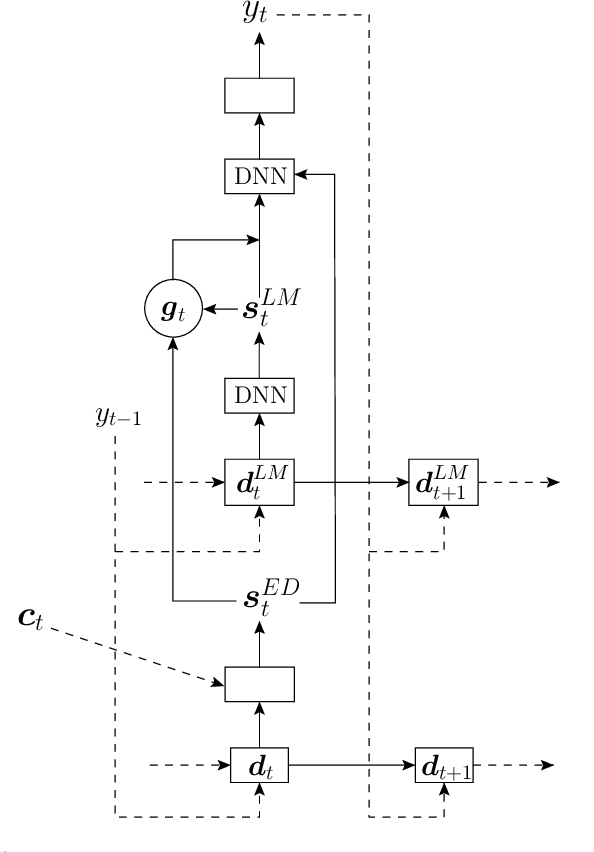

Attention-based recurrent neural encoder-decoder models present an elegant solution to the automatic speech recognition problem. This approach folds the acoustic model, pronunciation model, and language model into a single network and requires only a parallel corpus of speech and text for training. However, unlike in conventional approaches that combine separate acoustic and language models, it is not clear how to use additional (unpaired) text. While there has been previous work on methods addressing this problem, a thorough comparison among methods is still lacking. In this paper, we compare a suite of past methods and some of our own proposed methods for using unpaired text data to improve encoder-decoder models. For evaluation, we use the medium-sized Switchboard data set and the large-scale Google voice search and dictation data sets. Our results confirm the benefits of using unpaired text across a range of methods and data sets. Surprisingly, for first-pass decoding, the rather simple approach of shallow fusion performs best across data sets. However, for Google data sets we find that cold fusion has a lower oracle error rate and outperforms other approaches after second-pass rescoring on the Google voice search data set.