 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Whisper to Grade Them All
Jul 23, 2025We present an efficient end-to-end approach for holistic Automatic Speaking Assessment (ASA) of multi-part second-language tests, developed for the 2025 Speak & Improve Challenge. Our system's main novelty is the ability to process all four spoken responses with a single Whisper-small encoder, combine all information via a lightweight aggregator, and predict the final score. This architecture removes the need for transcription and per-part models, cuts inference time, and makes ASA practical for large-scale Computer-Assisted Language Learning systems. Our system achieved a Root Mean Squared Error (RMSE) of 0.384, outperforming the text-based baseline (0.44) while using at most 168M parameters (about 70% of Whisper-small). Furthermore, we propose a data sampling strategy, allowing the model to train on only 44.8% of the speakers in the corpus and still reach 0.383 RMSE, demonstrating improved performance on imbalanced classes and strong data efficiency.
Pronunciation Editing for Finnish Speech using Phonetic Posteriorgrams
Jul 02, 2025Synthesizing second-language (L2) speech is potentially highly valued for L2 language learning experience and feedback. However, due to the lack of L2 speech synthesis datasets, it is difficult to synthesize L2 speech for low-resourced languages. In this paper, we provide a practical solution for editing native speech to approximate L2 speech and present PPG2Speech, a diffusion-based multispeaker Phonetic-Posteriorgrams-to-Speech model that is capable of editing a single phoneme without text alignment. We use Matcha-TTS's flow-matching decoder as the backbone, transforming Phonetic Posteriorgrams (PPGs) to mel-spectrograms conditioned on external speaker embeddings and pitch. PPG2Speech strengthens the Matcha-TTS's flow-matching decoder with Classifier-free Guidance (CFG) and Sway Sampling. We also propose a new task-specific objective evaluation metric, the Phonetic Aligned Consistency (PAC), between the edited PPGs and the PPGs extracted from the synthetic speech for editing effects. We validate the effectiveness of our method on Finnish, a low-resourced, nearly phonetic language, using approximately 60 hours of data. We conduct objective and subjective evaluations of our approach to compare its naturalness, speaker similarity, and editing effectiveness with TTS-based editing. Our source code is published at https://github.com/aalto-speech/PPG2Speech.
Multi-Teacher Language-Aware Knowledge Distillation for Multilingual Speech Emotion Recognition
Jun 10, 2025Speech Emotion Recognition (SER) is crucial for improving human-computer interaction. Despite strides in monolingual SER, extending them to build a multilingual system remains challenging. Our goal is to train a single model capable of multilingual SER by distilling knowledge from multiple teacher models. To address this, we introduce a novel language-aware multi-teacher knowledge distillation method to advance SER in English, Finnish, and French. It leverages Wav2Vec2.0 as the foundation of monolingual teacher models and then distills their knowledge into a single multilingual student model. The student model demonstrates state-of-the-art performance, with a weighted recall of 72.9 on the English dataset and an unweighted recall of 63.4 on the Finnish dataset, surpassing fine-tuning and knowledge distillation baselines. Our method excels in improving recall for sad and neutral emotions, although it still faces challenges in recognizing anger and happiness.
Non-native Children's Automatic Speech Assessment Challenge (NOCASA)
Apr 29, 2025



This paper presents the "Non-native Children's Automatic Speech Assessment" (NOCASA) - a data competition part of the IEEE MLSP 2025 conference. NOCASA challenges participants to develop new systems that can assess single-word pronunciations of young second language (L2) learners as part of a gamified pronunciation training app. To achieve this, several issues must be addressed, most notably the limited nature of available training data and the highly unbalanced distribution among the pronunciation level categories. To expedite the development, we provide a pseudo-anonymized training data (TeflonNorL2), containing 10,334 recordings from 44 speakers attempting to pronounce 205 distinct Norwegian words, human-rated on a 1 to 5 scale (number of stars that should be given in the game). In addition to the data, two already trained systems are released as official baselines: an SVM classifier trained on the ComParE_16 acoustic feature set and a multi-task wav2vec 2.0 model. The latter achieves the best performance on the challenge test set, with an unweighted average recall (UAR) of 36.37%.
LLMs' morphological analyses of complex FST-generated Finnish words
Jul 11, 2024



Rule-based language processing systems have been overshadowed by neural systems in terms of utility, but it remains unclear whether neural NLP systems, in practice, learn the grammar rules that humans use. This work aims to shed light on the issue by evaluating state-of-the-art LLMs in a task of morphological analysis of complex Finnish noun forms. We generate the forms using an FST tool, and they are unlikely to have occurred in the training sets of the LLMs, therefore requiring morphological generalisation capacity. We find that GPT-4-turbo has some difficulties in the task while GPT-3.5-turbo struggles and smaller models Llama2-70B and Poro-34B fail nearly completely.
Out-of-distribution generalisation in spoken language understanding
Jul 10, 2024


Test data is said to be out-of-distribution (OOD) when it unexpectedly differs from the training data, a common challenge in real-world use cases of machine learning. Although OOD generalisation has gained interest in recent years, few works have focused on OOD generalisation in spoken language understanding (SLU) tasks. To facilitate research on this topic, we introduce a modified version of the popular SLU dataset SLURP, featuring data splits for testing OOD generalisation in the SLU task. We call our modified dataset SLURP For OOD generalisation, or SLURPFOOD. Utilising our OOD data splits, we find end-to-end SLU models to have limited capacity for generalisation. Furthermore, by employing model interpretability techniques, we shed light on the factors contributing to the generalisation difficulties of the models. To improve the generalisation, we experiment with two techniques, which improve the results on some, but not all the splits, emphasising the need for new techniques.
On Using Distribution-Based Compositionality Assessment to Evaluate Compositional Generalisation in Machine Translation
Nov 14, 2023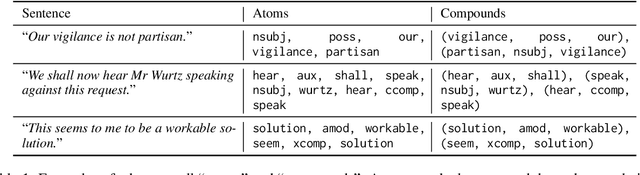
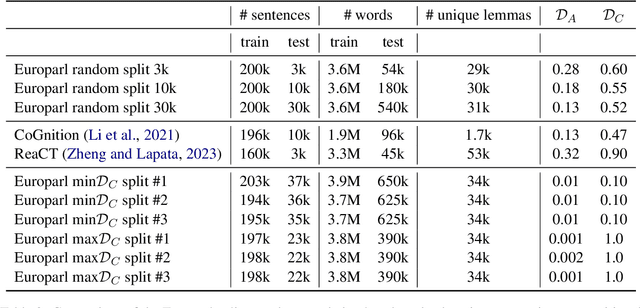
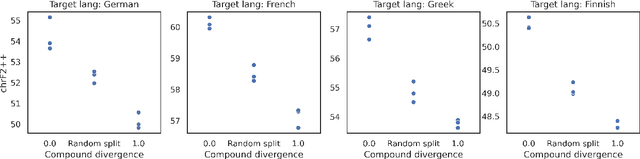
Compositional generalisation (CG), in NLP and in machine learning more generally, has been assessed mostly using artificial datasets. It is important to develop benchmarks to assess CG also in real-world natural language tasks in order to understand the abilities and limitations of systems deployed in the wild. To this end, our GenBench Collaborative Benchmarking Task submission utilises the distribution-based compositionality assessment (DBCA) framework to split the Europarl translation corpus into a training and a test set in such a way that the test set requires compositional generalisation capacity. Specifically, the training and test sets have divergent distributions of dependency relations, testing NMT systems' capability of translating dependencies that they have not been trained on. This is a fully-automated procedure to create natural language compositionality benchmarks, making it simple and inexpensive to apply it further to other datasets and languages. The code and data for the experiments is available at https://github.com/aalto-speech/dbca.
Advancing Audio Emotion and Intent Recognition with Large Pre-Trained Models and Bayesian Inference
Oct 16, 2023


Large pre-trained models are essential in paralinguistic systems, demonstrating effectiveness in tasks like emotion recognition and stuttering detection. In this paper, we employ large pre-trained models for the ACM Multimedia Computational Paralinguistics Challenge, addressing the Requests and Emotion Share tasks. We explore audio-only and hybrid solutions leveraging audio and text modalities. Our empirical results consistently show the superiority of the hybrid approaches over the audio-only models. Moreover, we introduce a Bayesian layer as an alternative to the standard linear output layer. The multimodal fusion approach achieves an 85.4% UAR on HC-Requests and 60.2% on HC-Complaints. The ensemble model for the Emotion Share task yields the best rho value of .614. The Bayesian wav2vec2 approach, explored in this study, allows us to easily build ensembles, at the cost of fine-tuning only one model. Moreover, we can have usable confidence values instead of the usual overconfident posterior probabilities.
Topic Identification For Spontaneous Speech: Enriching Audio Features With Embedded Linguistic Information
Jul 21, 2023



Traditional topic identification solutions from audio rely on an automatic speech recognition system (ASR) to produce transcripts used as input to a text-based model. These approaches work well in high-resource scenarios, where there are sufficient data to train both components of the pipeline. However, in low-resource situations, the ASR system, even if available, produces low-quality transcripts, leading to a bad text-based classifier. Moreover, spontaneous speech containing hesitations can further degrade the performance of the ASR model. In this paper, we investigate alternatives to the standard text-only solutions by comparing audio-only and hybrid techniques of jointly utilising text and audio features. The models evaluated on spontaneous Finnish speech demonstrate that purely audio-based solutions are a viable option when ASR components are not available, while the hybrid multi-modal solutions achieve the best results.
When to Laugh and How Hard? A Multimodal Approach to Detecting Humor and its Intensity
Nov 03, 2022


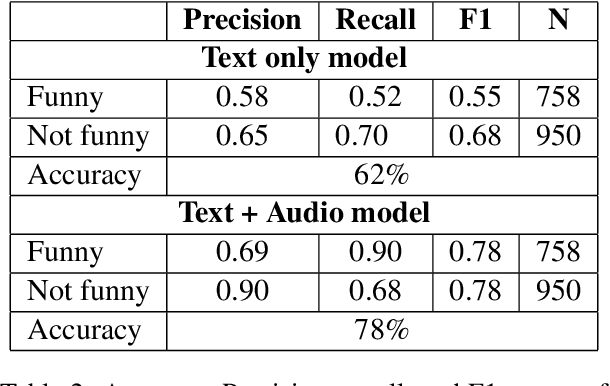
Prerecorded laughter accompanying dialog in comedy TV shows encourages the audience to laugh by clearly marking humorous moments in the show. We present an approach for automatically detecting humor in the Friends TV show using multimodal data. Our model is capable of recognizing whether an utterance is humorous or not and assess the intensity of it. We use the prerecorded laughter in the show as annotation as it marks humor and the length of the audience's laughter tells us how funny a given joke is. We evaluate the model on episodes the model has not been exposed to during the training phase. Our results show that the model is capable of correctly detecting whether an utterance is humorous 78% of the time and how long the audience's laughter reaction should last with a mean absolute error of 600 milliseconds.