 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisContSE: Single-Step Diffusion Speech Enhancement Based on Joint Discrete and Continuous Embeddings
Jan 29, 2026Diffusion speech enhancement on discrete audio codec features gain immense attention due to their improved speech component reconstruction capability. However, they usually suffer from high inference computational complexity due to multiple reverse process iterations. Furthermore, they generally achieve promising results on non-intrusive metrics but show poor performance on intrusive metrics, as they may struggle in reconstructing the correct phones. In this paper, we propose DisContSE, an efficient diffusion-based speech enhancement model on joint discrete codec tokens and continuous embeddings. Our contributions are three-fold. First, we formulate both a discrete and a continuous enhancement module operating on discrete audio codec tokens and continuous embeddings, respectively, to achieve improved fidelity and intelligibility simultaneously. Second, a semantic enhancement module is further adopted to achieve optimal phonetic accuracy. Third, we achieve a single-step efficient reverse process in inference with a novel quantization error mask initialization strategy, which, according to our knowledge, is the first successful single-step diffusion speech enhancement based on an audio codec. Trained and evaluated on URGENT 2024 Speech Enhancement Challenge data splits, the proposed DisContSE excels top-reported time- and frequency-domain diffusion baseline methods in PESQ, POLQA, UTMOS, and in a subjective ITU-T P.808 listening test, clearly achieving an overall top rank.
ICASSP 2026 URGENT Speech Enhancement Challenge
Jan 20, 2026The ICASSP 2026 URGENT Challenge advances the series by focusing on universal speech enhancement (SE) systems that handle diverse distortions, domains, and input conditions. This overview paper details the challenge's motivation, task definitions, datasets, baseline systems, evaluation protocols, and results. The challenge is divided into two complementary tracks. Track 1 focuses on universal speech enhancement, while Track 2 introduces speech quality assessment for enhanced speech. The challenge attracted over 80 team registrations, with 29 submitting valid entries, demonstrating significant community interest in robust SE technologies.
Active Confusion Expression in Large Language Models: Leveraging World Models toward Better Social Reasoning
Oct 09, 2025While large language models (LLMs) excel in mathematical and code reasoning, we observe they struggle with social reasoning tasks, exhibiting cognitive confusion, logical inconsistencies, and conflation between objective world states and subjective belief states. Through deteiled analysis of DeepSeek-R1's reasoning trajectories, we find that LLMs frequently encounter reasoning impasses and tend to output contradictory terms like "tricky" and "confused" when processing scenarios with multiple participants and timelines, leading to erroneous reasoning or infinite loops. The core issue is their inability to disentangle objective reality from agents' subjective beliefs. To address this, we propose an adaptive world model-enhanced reasoning mechanism that constructs a dynamic textual world model to track entity states and temporal sequences. It dynamically monitors reasoning trajectories for confusion indicators and promptly intervenes by providing clear world state descriptions, helping models navigate through cognitive dilemmas. The mechanism mimics how humans use implicit world models to distinguish between external events and internal beliefs. Evaluations on three social benchmarks demonstrate significant improvements in accuracy (e.g., +10% in Hi-ToM) while reducing computational costs (up to 33.8% token reduction), offering a simple yet effective solution for deploying LLMs in social contexts.
Interspeech 2025 URGENT Speech Enhancement Challenge
May 29, 2025There has been a growing effort to develop universal speech enhancement (SE) to handle inputs with various speech distortions and recording conditions. The URGENT Challenge series aims to foster such universal SE by embracing a broad range of distortion types, increasing data diversity, and incorporating extensive evaluation metrics. This work introduces the Interspeech 2025 URGENT Challenge, the second edition of the series, to explore several aspects that have received limited attention so far: language dependency, universality for more distortion types, data scalability, and the effectiveness of using noisy training data. We received 32 submissions, where the best system uses a discriminative model, while most other competitive ones are hybrid methods. Analysis reveals some key findings: (i) some generative or hybrid approaches are preferred in subjective evaluations over the top discriminative model, and (ii) purely generative SE models can exhibit language dependency.
VE-KWS: Visual Modality Enhanced End-to-End Keyword Spotting
Mar 14, 2023



The performance of the keyword spotting (KWS) system based on audio modality, commonly measured in false alarms and false rejects, degrades significantly under the far field and noisy conditions. Therefore, audio-visual keyword spotting, which leverages complementary relationships over multiple modalities, has recently gained much attention. However, current studies mainly focus on combining the exclusively learned representations of different modalities, instead of exploring the modal relationships during each respective modeling. In this paper, we propose a novel visual modality enhanced end-to-end KWS framework (VE-KWS), which fuses audio and visual modalities from two aspects. The first one is utilizing the speaker location information obtained from the lip region in videos to assist the training of multi-channel audio beamformer. By involving the beamformer as an audio enhancement module, the acoustic distortions, caused by the far field or noisy environments, could be significantly suppressed. The other one is conducting cross-attention between different modalities to capture the inter-modal relationships and help the representation learning of each modality. Experiments on the MSIP challenge corpus show that our proposed model achieves 2.79% false rejection rate and 2.95% false alarm rate on the Eval set, resulting in a new SOTA performance compared with the top-ranking systems in the ICASSP2022 MISP challenge.
spatial-dccrn: dccrn equipped with frame-level angle feature and hybrid filtering for multi-channel speech enhancement
Oct 17, 2022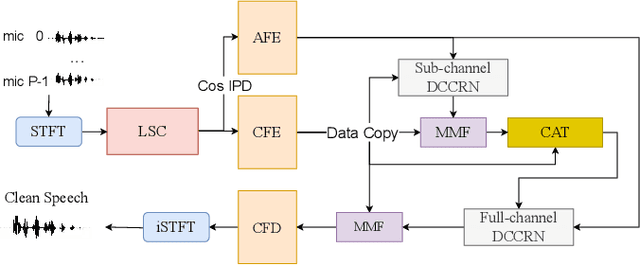
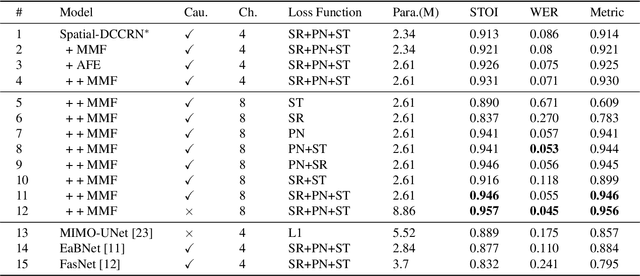
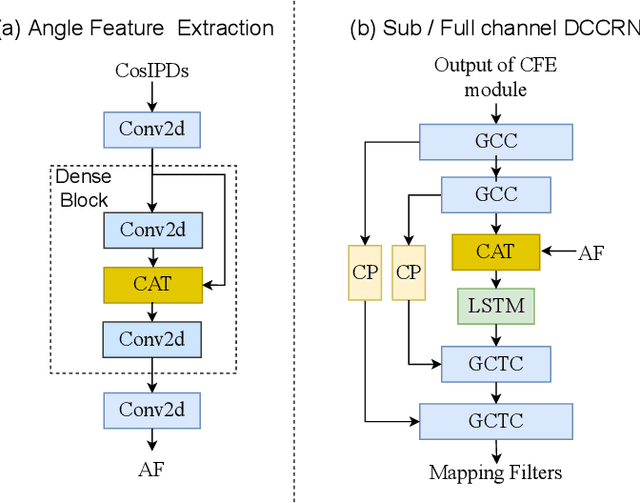
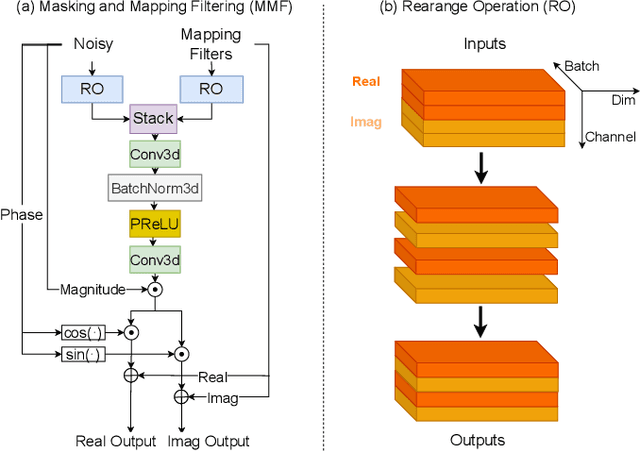
Recently, multi-channel speech enhancement has drawn much interest due to the use of spatial information to distinguish target speech from interfering signal. To make full use of spatial information and neural network based masking estimation, we propose a multi-channel denoising neural network -- Spatial DCCRN. Firstly, we extend S-DCCRN to multi-channel scenario, aiming at performing cascaded sub-channel and full-channel processing strategy, which can model different channels separately. Moreover, instead of only adopting multi-channel spectrum or concatenating first-channel's magnitude and IPD as the model's inputs, we apply an angle feature extraction module (AFE) to extract frame-level angle feature embeddings, which can help the model to apparently perceive spatial information. Finally, since the phenomenon of residual noise will be more serious when the noise and speech exist in the same time frequency (TF) bin, we particularly design a masking and mapping filtering method to substitute the traditional filter-and-sum operation, with the purpose of cascading coarsely denoising, dereverberation and residual noise suppression. The proposed model, Spatial-DCCRN, has surpassed EaBNet, FasNet as well as several competitive models on the L3DAS22 Challenge dataset. Not only the 3D scenario, Spatial-DCCRN outperforms state-of-the-art (SOTA) model MIMO-UNet by a large margin in multiple evaluation metrics on the multi-channel ConferencingSpeech2021 Challenge dataset. Ablation studies also demonstrate the effectiveness of different contributions.
Personalized Acoustic Echo Cancellation for Full-duplex Communications
May 30, 2022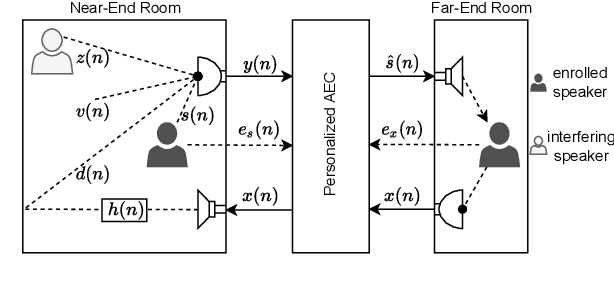

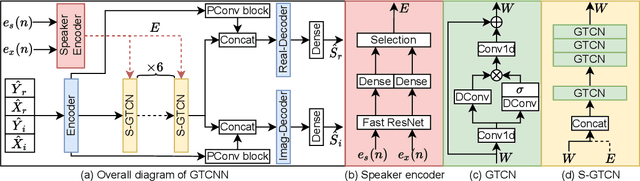
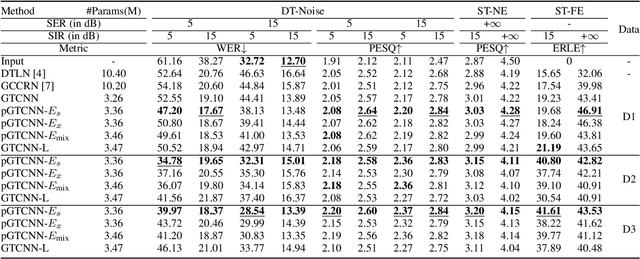
Deep neural networks (DNNs) have shown promising results for acoustic echo cancellation (AEC). But the DNN-based AEC models let through all near-end speakers including the interfering speech. In light of recent studies on personalized speech enhancement, we investigate the feasibility of personalized acoustic echo cancellation (PAEC) in this paper for full-duplex communications, where background noise and interfering speakers may coexist with acoustic echoes. Specifically, we first propose a novel backbone neural network termed as gated temporal convolutional neural network (GTCNN) that outperforms state-of-the-art AEC models in performance. Speaker embeddings like d-vectors are further adopted as auxiliary information to guide the GTCNN to focus on the target speaker. A special case in PAEC is that speech snippets of both parties on the call are enrolled. Experimental results show that auxiliary information from either the near-end speaker or the far-end speaker can improve the DNN-based AEC performance. Nevertheless, there is still much room for improvement in the utilization of the finite-dimensional speaker embeddings.
Multi-Task Deep Residual Echo Suppression with Echo-aware Loss
Feb 21, 2022

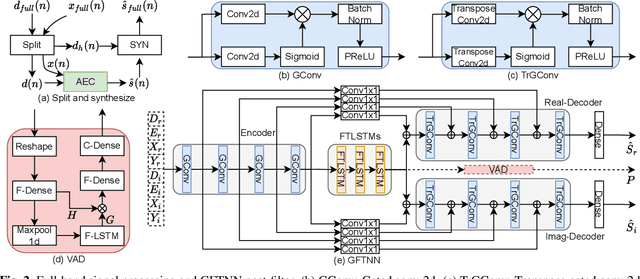
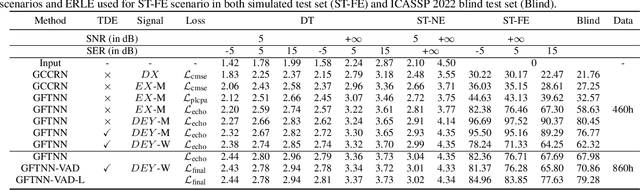
This paper introduces the NWPU Team's entry to the ICASSP 2022 AEC Challenge. We take a hybrid approach that cascades a linear AEC with a neural post-filter. The former is used to deal with the linear echo components while the latter suppresses the residual non-linear echo components. We use gated convolutional F-T-LSTM neural network (GFTNN) as the backbone and shape the post-filter by a multi-task learning (MTL) framework, where a voice activity detection (VAD) module is adopted as an auxiliary task along with echo suppression, with the aim to avoid over suppression that may cause speech distortion. Moreover, we adopt an echo-aware loss function, where the mean square error (MSE) loss can be optimized particularly for every time-frequency bin (TF-bin) according to the signal-to-echo ratio (SER), leading to further suppression on the echo. Extensive ablation study shows that the time delay estimation (TDE) module in neural post-filter leads to better perceptual quality, and an adaptive filter with better convergence will bring consistent performance gain for the post-filter. Besides, we find that using the linear echo as the input of our neural post-filter is a better choice than using the reference signal directly. In the ICASSP 2022 AEC-Challenge, our approach has ranked the 1st place on word accuracy (WAcc) (0.817) and the 3rd place on both mean opinion score (MOS) (4.502) and the final score (0.864).
Summary On The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Grand Challenge
Feb 08, 2022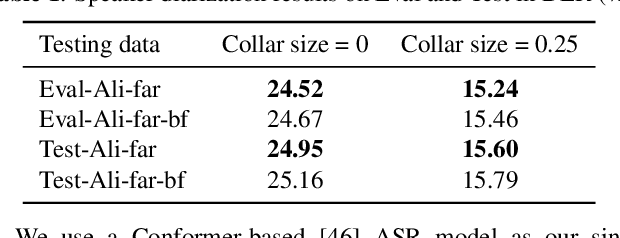
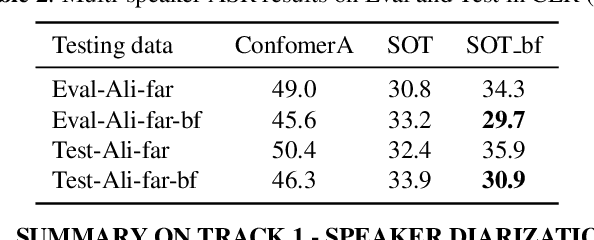
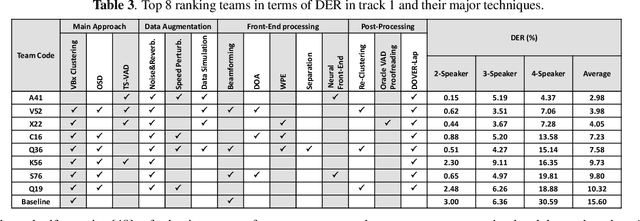
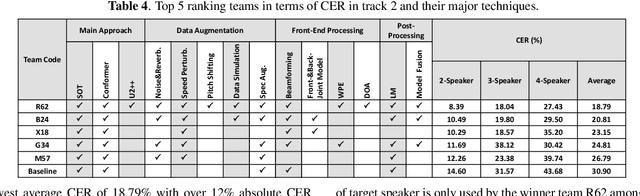
The ICASSP 2022 Multi-channel Multi-party Meeting Transcription Grand Challenge (M2MeT) focuses on one of the most valuable and the most challenging scenarios of speech technologies. The M2MeT challenge has particularly set up two tracks, speaker diarization (track 1) and multi-speaker automatic speech recognition (ASR) (track 2). Along with the challenge, we released 120 hours of real-recorded Mandarin meeting speech data with manual annotation, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. We briefly describe the released dataset, track setups, baselines and summarize the challenge results and major techniques used in the submissions.
S-DCCRN: Super Wide Band DCCRN with learnable complex feature for speech enhancement
Nov 16, 2021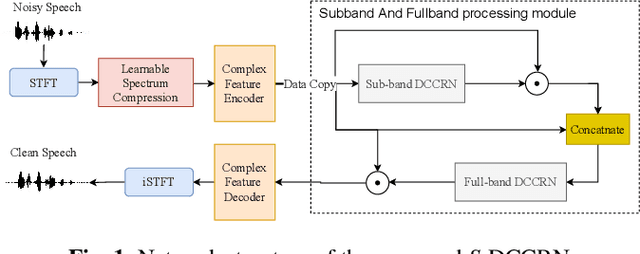
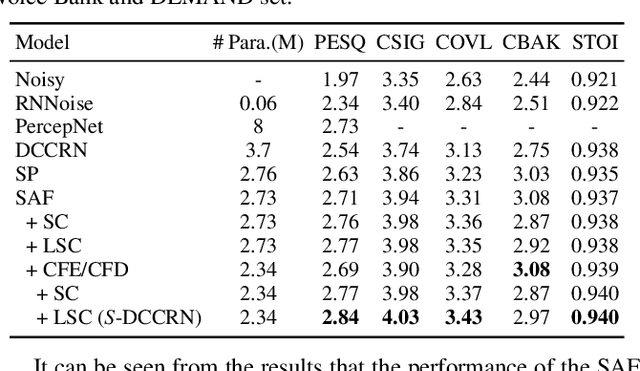
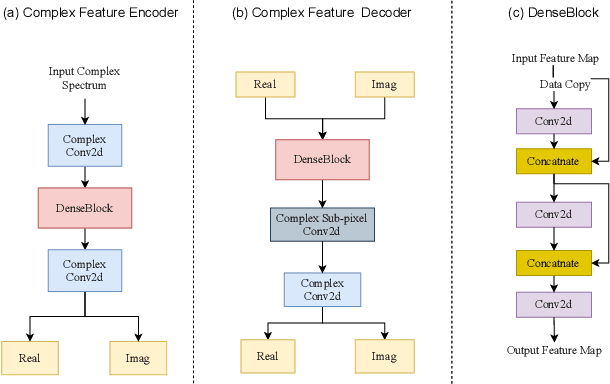
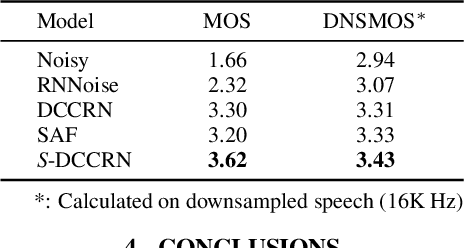
In speech enhancement, complex neural network has shown promising performance due to their effectiveness in processing complex-valued spectrum. Most of the recent speech enhancement approaches mainly focus on wide-band signal with a sampling rate of 16K Hz. However, research on super wide band (e.g., 32K Hz) or even full-band (48K) denoising is still lacked due to the difficulty of modeling more frequency bands and particularly high frequency components. In this paper, we extend our previous deep complex convolution recurrent neural network (DCCRN) substantially to a super wide band version -- S-DCCRN, to perform speech denoising on speech of 32K Hz sampling rate. We first employ a cascaded sub-band and full-band processing module, which consists of two small-footprint DCCRNs -- one operates on sub-band signal and one operates on full-band signal, aiming at benefiting from both local and global frequency information. Moreover, instead of simply adopting the STFT feature as input, we use a complex feature encoder trained in an end-to-end manner to refine the information of different frequency bands. We also use a complex feature decoder to revert the feature to time-frequency domain. Finally, a learnable spectrum compression method is adopted to adjust the energy of different frequency bands, which is beneficial for neural network learning. The proposed model, S-DCCRN, has surpassed PercepNet as well as several competitive models and achieves state-of-the-art performance in terms of speech quality and intelligibility. Ablation studies also demonstrate the effectiveness of different contributions.