 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMBTFNet: Multi-Band Temporal-Frequency Neural Network For Singing Voice Enhancement
Oct 06, 2023



A typical neural speech enhancement (SE) approach mainly handles speech and noise mixtures, which is not optimal for singing voice enhancement scenarios. Music source separation (MSS) models treat vocals and various accompaniment components equally, which may reduce performance compared to the model that only considers vocal enhancement. In this paper, we propose a novel multi-band temporal-frequency neural network (MBTFNet) for singing voice enhancement, which particularly removes background music, noise and even backing vocals from singing recordings. MBTFNet combines inter and intra-band modeling for better processing of full-band signals. Dual-path modeling are introduced to expand the receptive field of the model. We propose an implicit personalized enhancement (IPE) stage based on signal-to-noise ratio (SNR) estimation, which further improves the performance of MBTFNet. Experiments show that our proposed model significantly outperforms several state-of-the-art SE and MSS models.
DCCRN-KWS: an audio bias based model for noise robust small-footprint keyword spotting
May 23, 2023



Real-world complex acoustic environments especially the ones with a low signal-to-noise ratio (SNR) will bring tremendous challenges to a keyword spotting (KWS) system. Inspired by the recent advances of neural speech enhancement and context bias in speech recognition, we propose a robust audio context bias based DCCRN-KWS model to address this challenge. We form the whole architecture as a multi-task learning framework for both denosing and keyword spotting, where the DCCRN encoder is connected with the KWS model. Helped with the denoising task, we further introduce an audio context bias module to leverage the real keyword samples and bias the network to better iscriminate keywords in noisy conditions. Feature merge and complex context linear modules are also introduced to strength such discrimination and to effectively leverage contextual information respectively. Experiments on the internal challenging dataset and the HIMIYA public dataset show that our DCCRN-KWS system is superior in performance, while ablation study demonstrates the good design of the whole model.
Two-stage Neural Network for ICASSP 2023 Speech Signal Improvement Challenge
Mar 14, 2023

In ICASSP 2023 speech signal improvement challenge, we developed a dual-stage neural model which improves speech signal quality induced by different distortions in a stage-wise divide-and-conquer fashion. Specifically, in the first stage, the speech improvement network focuses on recovering the missing components of the spectrum, while in the second stage, our model aims to further suppress noise, reverberation, and artifacts introduced by the first-stage model. Achieving 0.446 in the final score and 0.517 in the P.835 score, our system ranks 4th in the non-real-time track.
spatial-dccrn: dccrn equipped with frame-level angle feature and hybrid filtering for multi-channel speech enhancement
Oct 17, 2022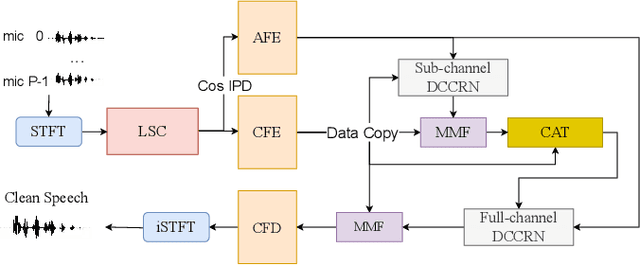
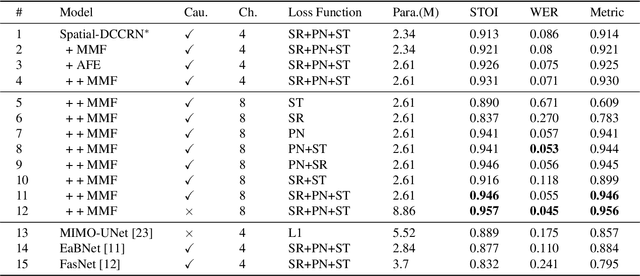
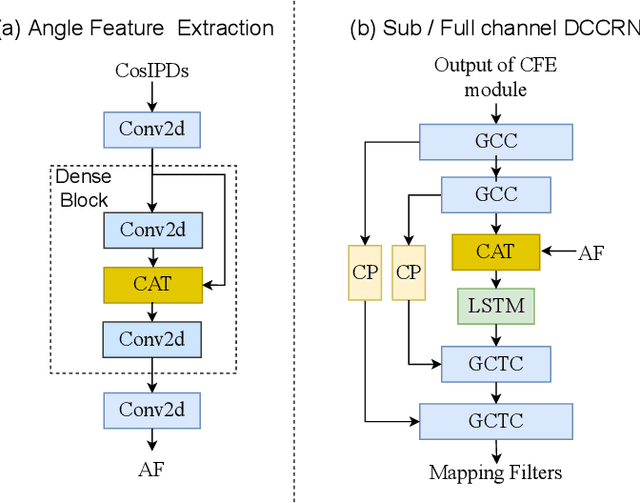
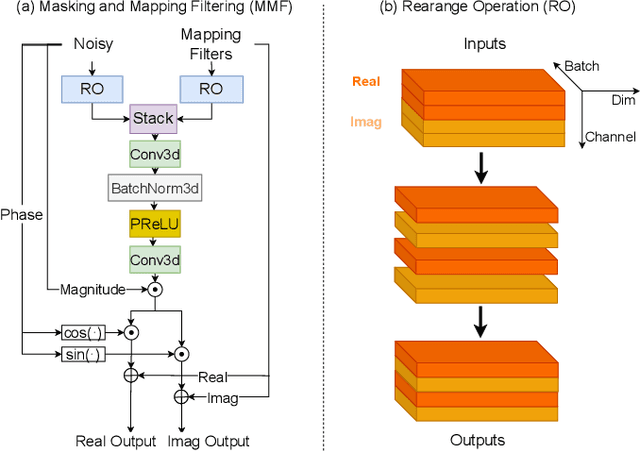
Recently, multi-channel speech enhancement has drawn much interest due to the use of spatial information to distinguish target speech from interfering signal. To make full use of spatial information and neural network based masking estimation, we propose a multi-channel denoising neural network -- Spatial DCCRN. Firstly, we extend S-DCCRN to multi-channel scenario, aiming at performing cascaded sub-channel and full-channel processing strategy, which can model different channels separately. Moreover, instead of only adopting multi-channel spectrum or concatenating first-channel's magnitude and IPD as the model's inputs, we apply an angle feature extraction module (AFE) to extract frame-level angle feature embeddings, which can help the model to apparently perceive spatial information. Finally, since the phenomenon of residual noise will be more serious when the noise and speech exist in the same time frequency (TF) bin, we particularly design a masking and mapping filtering method to substitute the traditional filter-and-sum operation, with the purpose of cascading coarsely denoising, dereverberation and residual noise suppression. The proposed model, Spatial-DCCRN, has surpassed EaBNet, FasNet as well as several competitive models on the L3DAS22 Challenge dataset. Not only the 3D scenario, Spatial-DCCRN outperforms state-of-the-art (SOTA) model MIMO-UNet by a large margin in multiple evaluation metrics on the multi-channel ConferencingSpeech2021 Challenge dataset. Ablation studies also demonstrate the effectiveness of different contributions.
S-DCCRN: Super Wide Band DCCRN with learnable complex feature for speech enhancement
Nov 16, 2021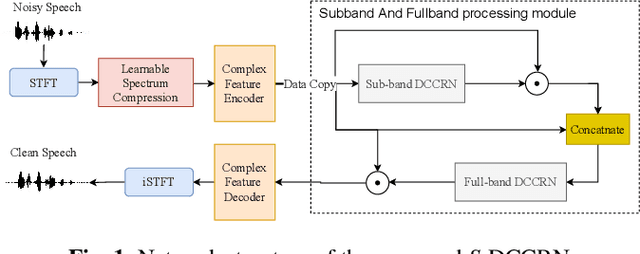
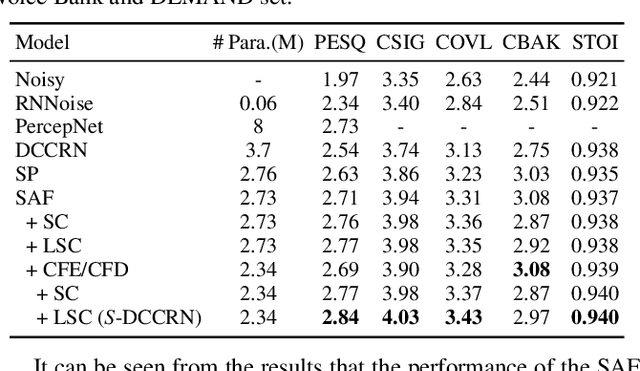
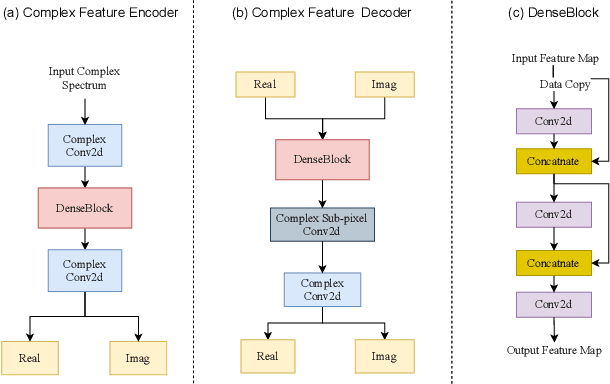
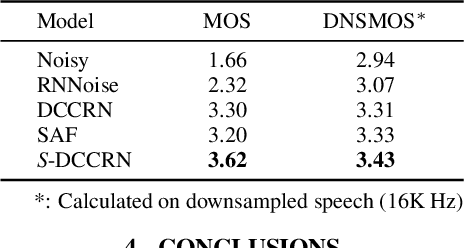
In speech enhancement, complex neural network has shown promising performance due to their effectiveness in processing complex-valued spectrum. Most of the recent speech enhancement approaches mainly focus on wide-band signal with a sampling rate of 16K Hz. However, research on super wide band (e.g., 32K Hz) or even full-band (48K) denoising is still lacked due to the difficulty of modeling more frequency bands and particularly high frequency components. In this paper, we extend our previous deep complex convolution recurrent neural network (DCCRN) substantially to a super wide band version -- S-DCCRN, to perform speech denoising on speech of 32K Hz sampling rate. We first employ a cascaded sub-band and full-band processing module, which consists of two small-footprint DCCRNs -- one operates on sub-band signal and one operates on full-band signal, aiming at benefiting from both local and global frequency information. Moreover, instead of simply adopting the STFT feature as input, we use a complex feature encoder trained in an end-to-end manner to refine the information of different frequency bands. We also use a complex feature decoder to revert the feature to time-frequency domain. Finally, a learnable spectrum compression method is adopted to adjust the energy of different frequency bands, which is beneficial for neural network learning. The proposed model, S-DCCRN, has surpassed PercepNet as well as several competitive models and achieves state-of-the-art performance in terms of speech quality and intelligibility. Ablation studies also demonstrate the effectiveness of different contributions.
Uformer: A Unet based dilated complex & real dual-path conformer network for simultaneous speech enhancement and dereverberation
Nov 11, 2021
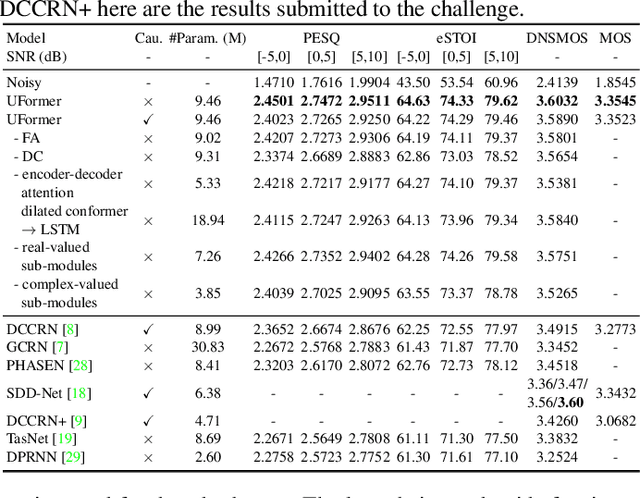
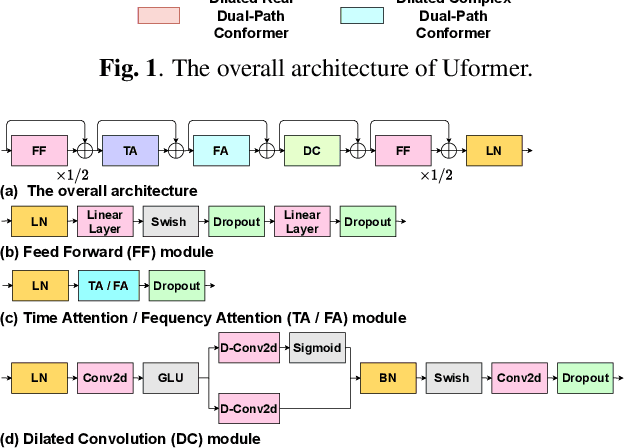
Complex spectrum and magnitude are considered as two major features of speech enhancement and dereverberation. Traditional approaches always treat these two features separately, ignoring their underlying relationship. In this paper, we proposem Uformer, a Unet based dilated complex & real dual-path conformer network in both complex and magnitude domain for simultaneous speech enhancement and dereverberation. We exploit time attention (TA) and dilated convolution (DC) to leverage local and global contextual information and frequency attention (FA) to model dimensional information. These three sub-modules contained in the proposed dilated complex & real dual-path conformer module effectively improve the speech enhancement and dereverberation performance. Furthermore, hybrid encoder and decoder are adopted to simultaneously model the complex spectrum and magnitude and promote the information interaction between two domains. Encoder decoder attention is also applied to enhance the interaction between encoder and decoder. Our experimental results outperform all SOTA time and complex domain models objectively and subjectively. Specifically, Uformer reaches 3.6032 DNSMOS on the blind test set of Interspeech 2021 DNS Challenge, which outperforms all top-performed models. We also carry out ablation experiments to tease apart all proposed sub-modules that are most important.
DCCRN+: Channel-wise Subband DCCRN with SNR Estimation for Speech Enhancement
Jun 16, 2021
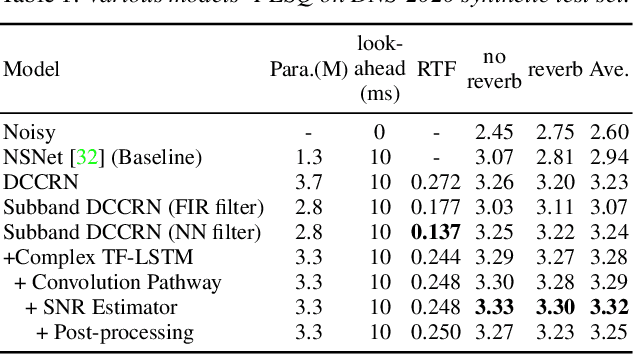
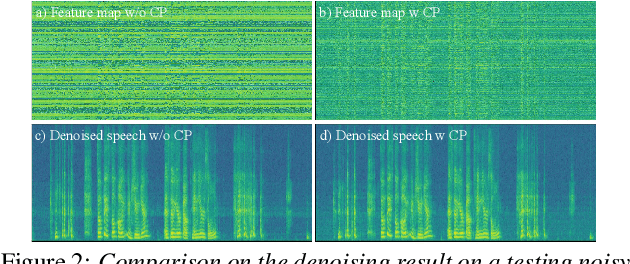

Deep complex convolution recurrent network (DCCRN), which extends CRN with complex structure, has achieved superior performance in MOS evaluation in Interspeech 2020 deep noise suppression challenge (DNS2020). This paper further extends DCCRN with the following significant revisions. We first extend the model to sub-band processing where the bands are split and merged by learnable neural network filters instead of engineered FIR filters, leading to a faster noise suppressor trained in an end-to-end manner. Then the LSTM is further substituted with a complex TF-LSTM to better model temporal dependencies along both time and frequency axes. Moreover, instead of simply concatenating the output of each encoder layer to the input of the corresponding decoder layer, we use convolution blocks to first aggregate essential information from the encoder output before feeding it to the decoder layers. We specifically formulate the decoder with an extra a priori SNR estimation module to maintain good speech quality while removing noise. Finally a post-processing module is adopted to further suppress the unnatural residual noise. The new model, named DCCRN+, has surpassed the original DCCRN as well as several competitive models in terms of PESQ and DNSMOS, and has achieved superior performance in the new Interspeech 2021 DNS challenge
F-T-LSTM based Complex Network for Joint Acoustic Echo Cancellation and Speech Enhancement
Jun 16, 2021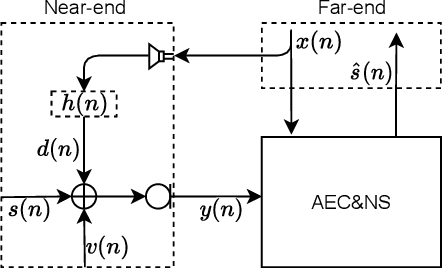
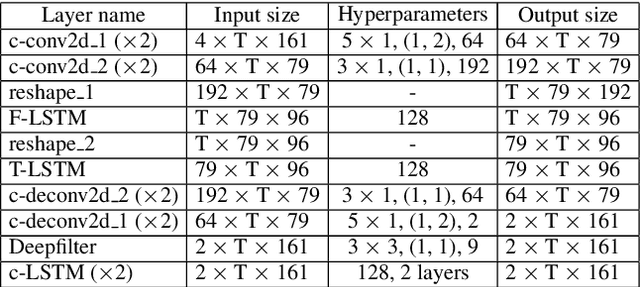
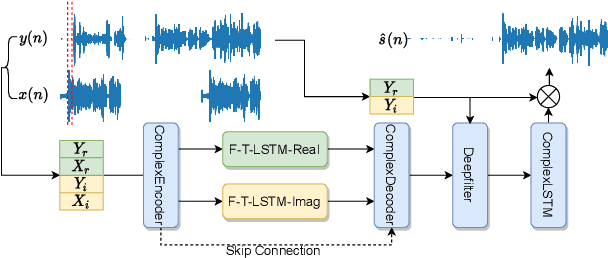
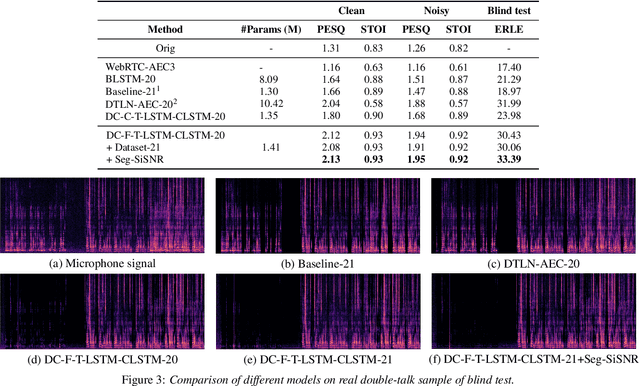
With the increasing demand for audio communication and online conference, ensuring the robustness of Acoustic Echo Cancellation (AEC) under the complicated acoustic scenario including noise, reverberation and nonlinear distortion has become a top issue. Although there have been some traditional methods that consider nonlinear distortion, they are still inefficient for echo suppression and the performance will be attenuated when noise is present. In this paper, we present a real-time AEC approach using complex neural network to better modeling the important phase information and frequency-time-LSTMs (F-T-LSTM), which scan both frequency and time axis, for better temporal modeling. Moreover, we utilize modified SI-SNR as cost function to make the model to have better echo cancellation and noise suppression (NS) performance. With only 1.4M parameters, the proposed approach outperforms the AEC-challenge baseline by 0.27 in terms of Mean Opinion Score (MOS).
AISHELL-4: An Open Source Dataset for Speech Enhancement, Separation, Recognition and Speaker Diarization in Conference Scenario
Apr 08, 2021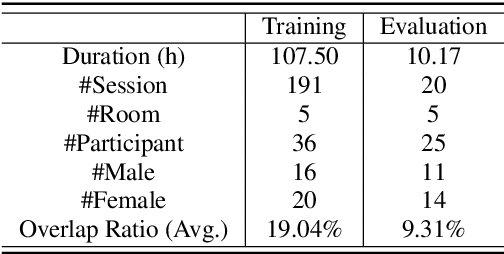
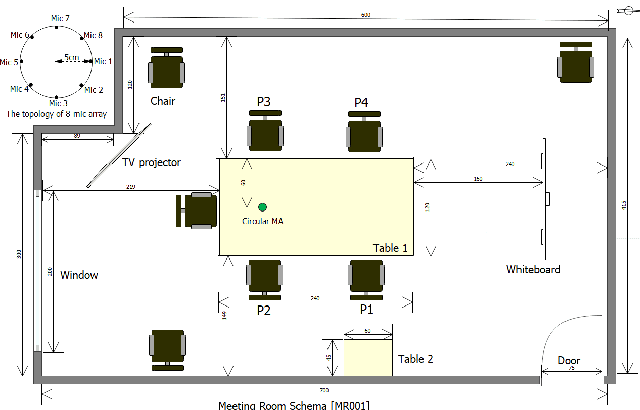
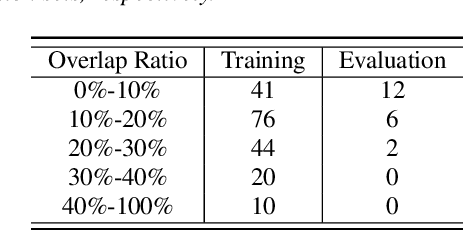

In this paper, we present AISHELL-4, a sizable real-recorded Mandarin speech dataset collected by 8-channel circular microphone array for speech processing in conference scenario. The dataset consists of 211 recorded meeting sessions, each containing 4 to 8 speakers, with a total length of 118 hours. This dataset aims to bride the advanced research on multi-speaker processing and the practical application scenario in three aspects. With real recorded meetings, AISHELL-4 provides realistic acoustics and rich natural speech characteristics in conversation such as short pause, speech overlap, quick speaker turn, noise, etc. Meanwhile, the accurate transcription and speaker voice activity are provided for each meeting in AISHELL-4. This allows the researchers to explore different aspects in meeting processing, ranging from individual tasks such as speech front-end processing, speech recognition and speaker diarization, to multi-modality modeling and joint optimization of relevant tasks. Given most open source dataset for multi-speaker tasks are in English, AISHELL-4 is the only Mandarin dataset for conversation speech, providing additional value for data diversity in speech community.