 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering LLMs for Culturally Localized Generation
Mar 24, 2026LLMs are deployed globally, yet produce responses biased towards cultures with abundant training data. Existing cultural localization approaches such as prompting or post-training alignment are black-box, hard to control, and do not reveal whether failures reflect missing knowledge or poor elicitation. In this paper, we address these gaps using mechanistic interpretability to uncover and manipulate cultural representations in LLMs. Leveraging sparse autoencoders, we identify interpretable features that encode culturally salient information and aggregate them into Cultural Embeddings (CuE). We use CuE both to analyze implicit cultural biases under underspecified prompts and to construct white-box steering interventions. Across multiple models, we show that CuE-based steering increases cultural faithfulness and elicits significantly rarer, long-tail cultural concepts than prompting alone. Notably, CuE-based steering is complementary to black-box localization methods, offering gains when applied on top of prompt-augmented inputs. This also suggests that models do benefit from better elicitation strategies, and don't necessarily lack long-tail knowledge representation, though this varies across cultures. Our results provide both diagnostic insight into cultural representations in LLMs and a controllable method to steer towards desired cultures.
Fantastic Reasoning Behaviors and Where to Find Them: Unsupervised Discovery of the Reasoning Process
Dec 30, 2025Despite the growing reasoning capabilities of recent large language models (LLMs), their internal mechanisms during the reasoning process remain underexplored. Prior approaches often rely on human-defined concepts (e.g., overthinking, reflection) at the word level to analyze reasoning in a supervised manner. However, such methods are limited, as it is infeasible to capture the full spectrum of potential reasoning behaviors, many of which are difficult to define in token space. In this work, we propose an unsupervised framework (namely, RISE: Reasoning behavior Interpretability via Sparse auto-Encoder) for discovering reasoning vectors, which we define as directions in the activation space that encode distinct reasoning behaviors. By segmenting chain-of-thought traces into sentence-level 'steps' and training sparse auto-encoders (SAEs) on step-level activations, we uncover disentangled features corresponding to interpretable behaviors such as reflection and backtracking. Visualization and clustering analyses show that these behaviors occupy separable regions in the decoder column space. Moreover, targeted interventions on SAE-derived vectors can controllably amplify or suppress specific reasoning behaviors, altering inference trajectories without retraining. Beyond behavior-specific disentanglement, SAEs capture structural properties such as response length, revealing clusters of long versus short reasoning traces. More interestingly, SAEs enable the discovery of novel behaviors beyond human supervision. We demonstrate the ability to control response confidence by identifying confidence-related vectors in the SAE decoder space. These findings underscore the potential of unsupervised latent discovery for both interpreting and controllably steering reasoning in LLMs.
The Gift of Feedback: Improving ASR Model Quality by Learning from User Corrections through Federated Learning
Sep 29, 2023Automatic speech recognition (ASR) models are typically trained on large datasets of transcribed speech. As language evolves and new terms come into use, these models can become outdated and stale. In the context of models trained on the server but deployed on edge devices, errors may result from the mismatch between server training data and actual on-device usage. In this work, we seek to continually learn from on-device user corrections through Federated Learning (FL) to address this issue. We explore techniques to target fresh terms that the model has not previously encountered, learn long-tail words, and mitigate catastrophic forgetting. In experimental evaluations, we find that the proposed techniques improve model recognition of fresh terms, while preserving quality on the overall language distribution.
Large vocabulary speech recognition for languages of Africa: multilingual modeling and self-supervised learning
Aug 05, 2022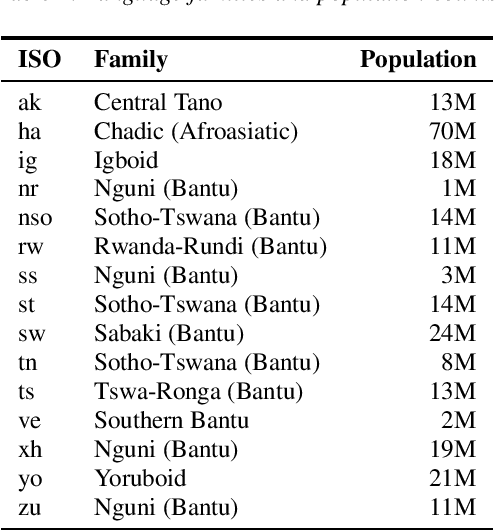
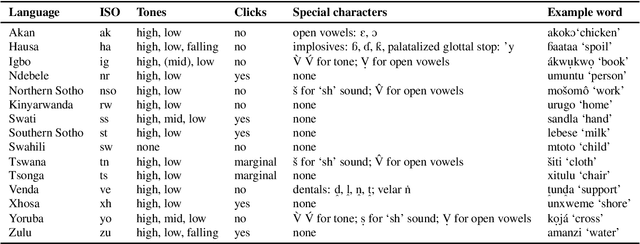
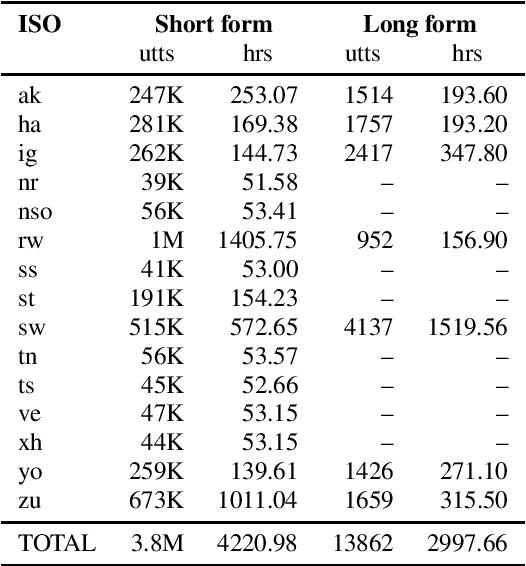
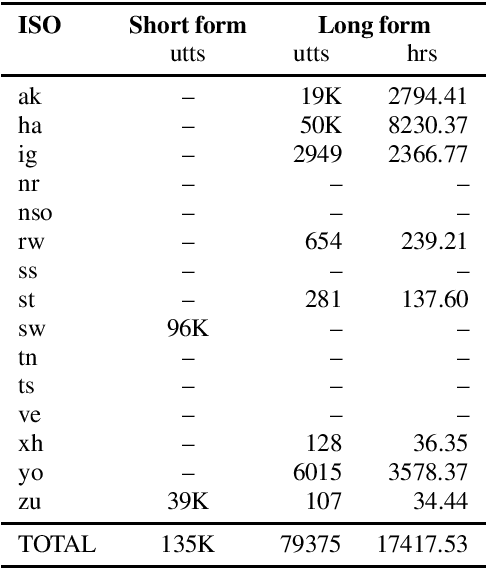
Almost none of the 2,000+ languages spoken in Africa have widely available automatic speech recognition systems, and the required data is also only available for a few languages. We have experimented with two techniques which may provide pathways to large vocabulary speech recognition for African languages: multilingual modeling and self-supervised learning. We gathered available open source data and collected data for 15 languages, and trained experimental models using these techniques. Our results show that pooling the small amounts of data available in multilingual end-to-end models, and pre-training on unsupervised data can help improve speech recognition quality for many African languages.
UserLibri: A Dataset for ASR Personalization Using Only Text
Jul 02, 2022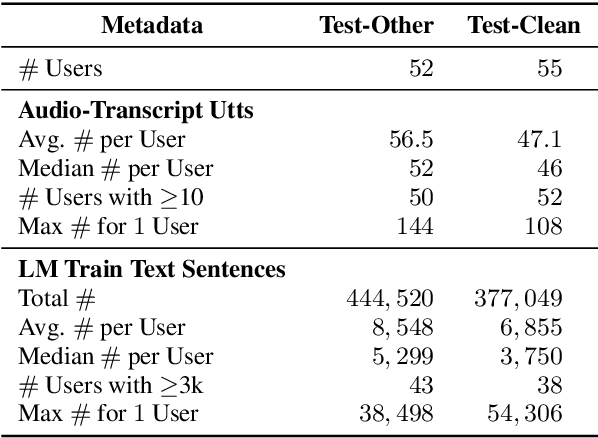
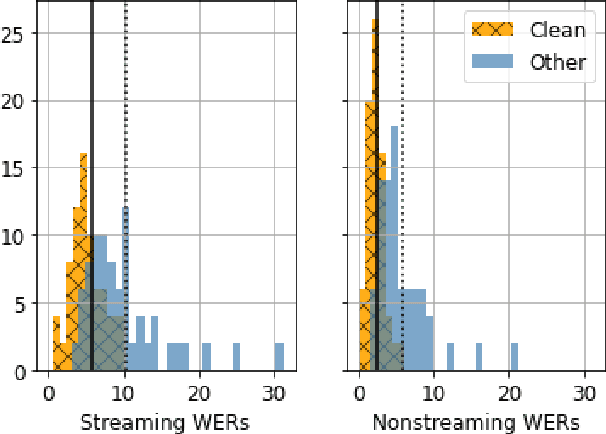
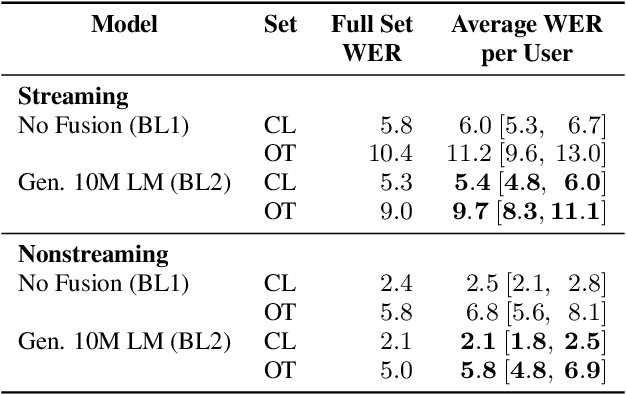
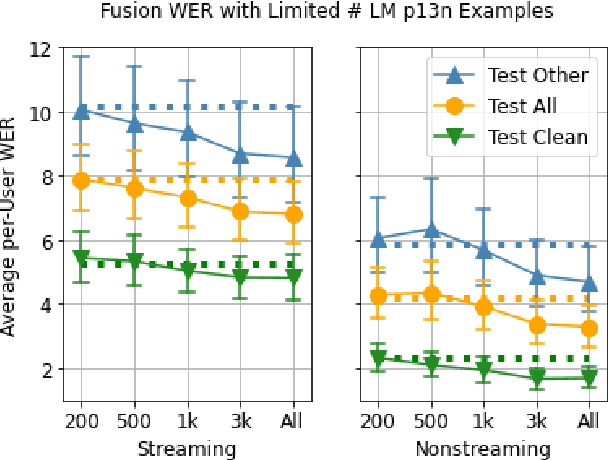
Personalization of speech models on mobile devices (on-device personalization) is an active area of research, but more often than not, mobile devices have more text-only data than paired audio-text data. We explore training a personalized language model on text-only data, used during inference to improve speech recognition performance for that user. We experiment on a user-clustered LibriSpeech corpus, supplemented with personalized text-only data for each user from Project Gutenberg. We release this User-Specific LibriSpeech (UserLibri) dataset to aid future personalization research. LibriSpeech audio-transcript pairs are grouped into 55 users from the test-clean dataset and 52 users from test-other. We are able to lower the average word error rate per user across both sets in streaming and nonstreaming models, including an improvement of 2.5 for the harder set of test-other users when streaming.
Online Model Compression for Federated Learning with Large Models
May 06, 2022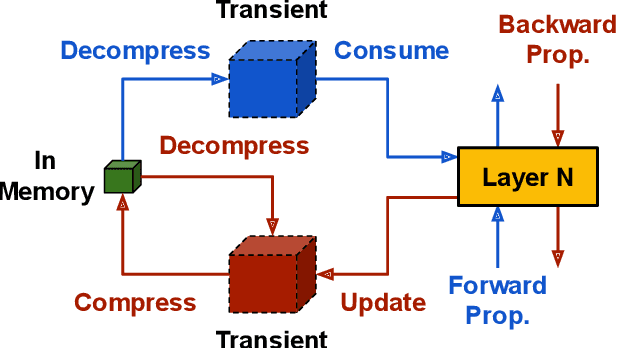
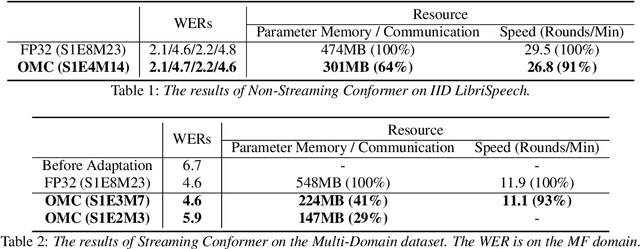
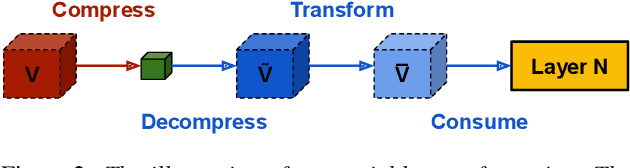
This paper addresses the challenges of training large neural network models under federated learning settings: high on-device memory usage and communication cost. The proposed Online Model Compression (OMC) provides a framework that stores model parameters in a compressed format and decompresses them only when needed. We use quantization as the compression method in this paper and propose three methods, (1) using per-variable transformation, (2) weight matrices only quantization, and (3) partial parameter quantization, to minimize the impact on model accuracy. According to our experiments on two recent neural networks for speech recognition and two different datasets, OMC can reduce memory usage and communication cost of model parameters by up to 59% while attaining comparable accuracy and training speed when compared with full-precision training.
Capitalization Normalization for Language Modeling with an Accurate and Efficient Hierarchical RNN Model
Feb 16, 2022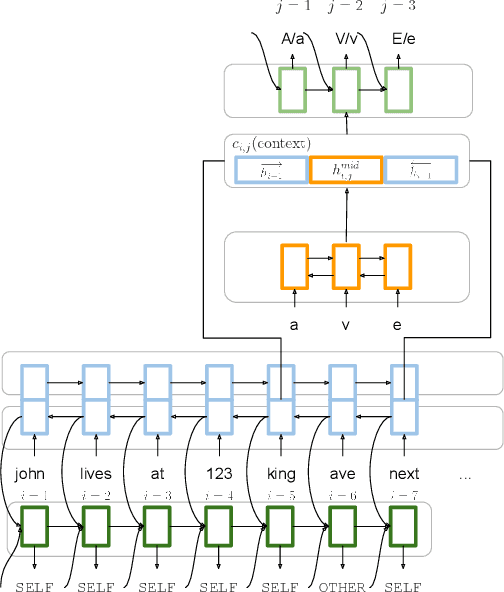
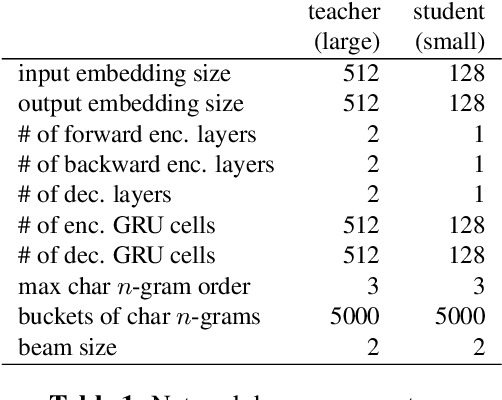
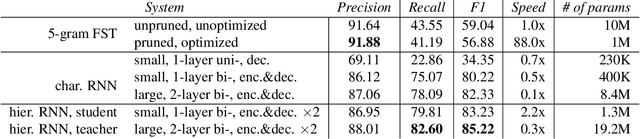

Capitalization normalization (truecasing) is the task of restoring the correct case (uppercase or lowercase) of noisy text. We propose a fast, accurate and compact two-level hierarchical word-and-character-based recurrent neural network model. We use the truecaser to normalize user-generated text in a Federated Learning framework for language modeling. A case-aware language model trained on this normalized text achieves the same perplexity as a model trained on text with gold capitalization. In a real user A/B experiment, we demonstrate that the improvement translates to reduced prediction error rates in a virtual keyboard application. Similarly, in an ASR language model fusion experiment, we show reduction in uppercase character error rate and word error rate.
Efficient and Private Federated Learning with Partially Trainable Networks
Oct 06, 2021


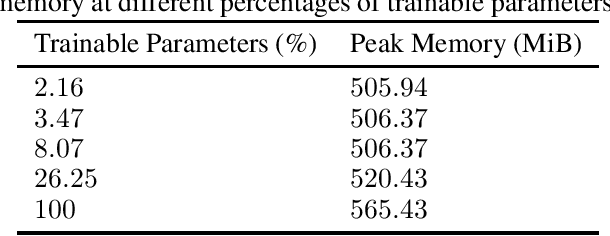
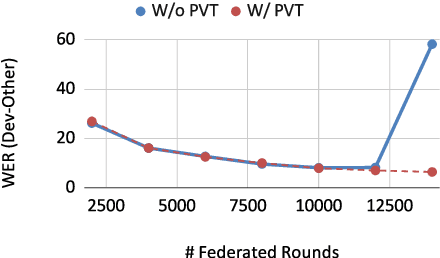
Federated learning is used for decentralized training of machine learning models on a large number (millions) of edge mobile devices. It is challenging because mobile devices often have limited communication bandwidth and local computation resources. Therefore, improving the efficiency of federated learning is critical for scalability and usability. In this paper, we propose to leverage partially trainable neural networks, which freeze a portion of the model parameters during the entire training process, to reduce the communication cost with little implications on model performance. Through extensive experiments, we empirically show that Federated learning of Partially Trainable neural networks (FedPT) can result in superior communication-accuracy trade-offs, with up to $46\times$ reduction in communication cost, at a small accuracy cost. Our approach also enables faster training, with a smaller memory footprint, and better utility for strong differential privacy guarantees. The proposed FedPT method can be particularly interesting for pushing the limitations of overparameterization in on-device learning.
Position-Invariant Truecasing with a Word-and-Character Hierarchical Recurrent Neural Network
Sep 01, 2021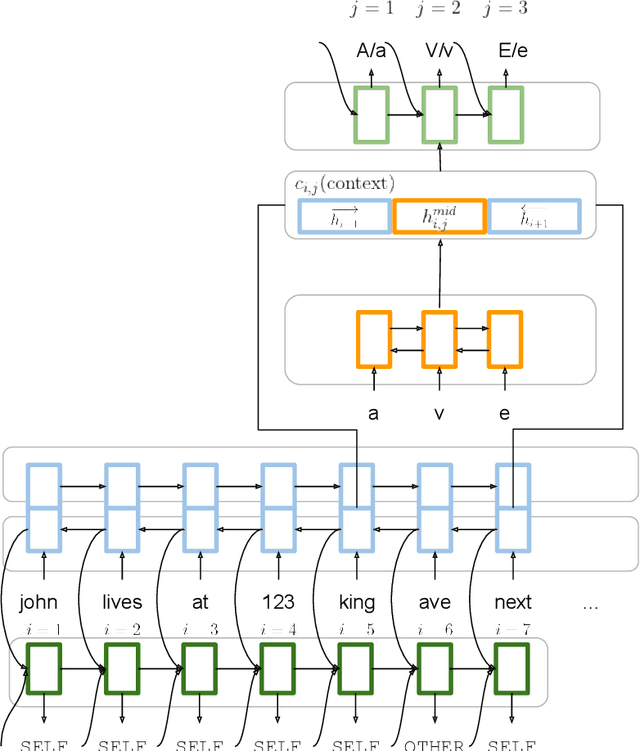
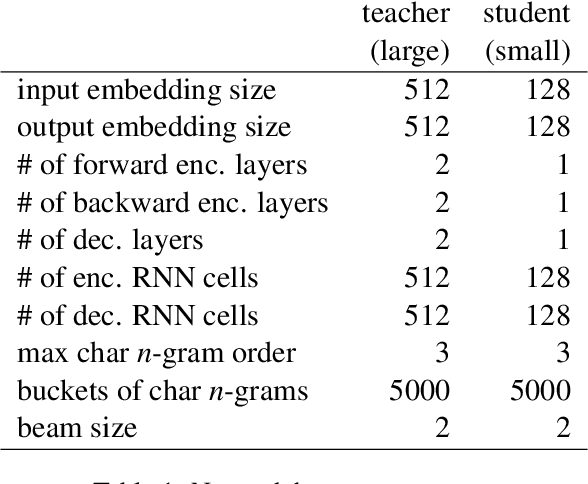

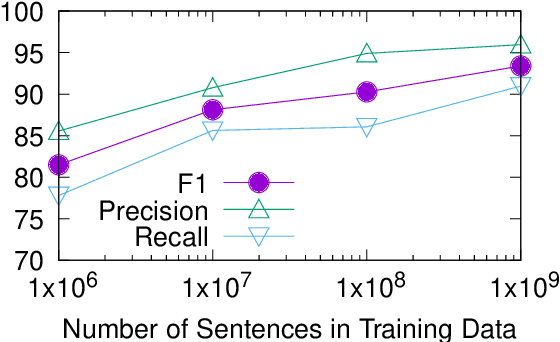
Truecasing is the task of restoring the correct case (uppercase or lowercase) of noisy text generated either by an automatic system for speech recognition or machine translation or by humans. It improves the performance of downstream NLP tasks such as named entity recognition and language modeling. We propose a fast, accurate and compact two-level hierarchical word-and-character-based recurrent neural network model, the first of its kind for this problem. Using sequence distillation, we also address the problem of truecasing while ignoring token positions in the sentence, i.e. in a position-invariant manner.
Communication-Efficient Agnostic Federated Averaging
Apr 06, 2021
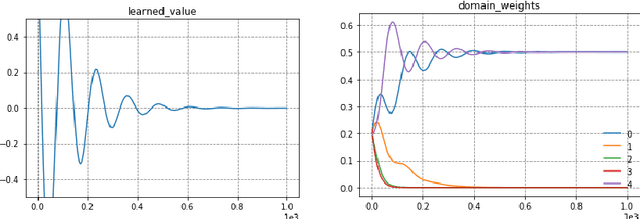
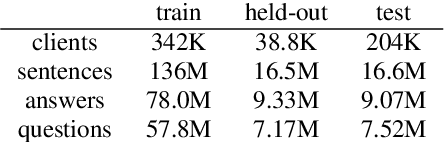
In distributed learning settings such as federated learning, the training algorithm can be potentially biased towards different clients. Mohri et al. (2019) proposed a domain-agnostic learning algorithm, where the model is optimized for any target distribution formed by a mixture of the client distributions in order to overcome this bias. They further proposed an algorithm for the cross-silo federated learning setting, where the number of clients is small. We consider this problem in the cross-device setting, where the number of clients is much larger. We propose a communication-efficient distributed algorithm called Agnostic Federated Averaging (or AgnosticFedAvg) to minimize the domain-agnostic objective proposed in Mohri et al. (2019), which is amenable to other private mechanisms such as secure aggregation. We highlight two types of naturally occurring domains in federated learning and argue that AgnosticFedAvg performs well on both. To demonstrate the practical effectiveness of AgnosticFedAvg, we report positive results for large-scale language modeling tasks in both simulation and live experiments, where the latter involves training language models for Spanish virtual keyboard for millions of user devices.