 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Device Directedness with Contextual Cues for Spoken Dialog Systems
Nov 23, 2022

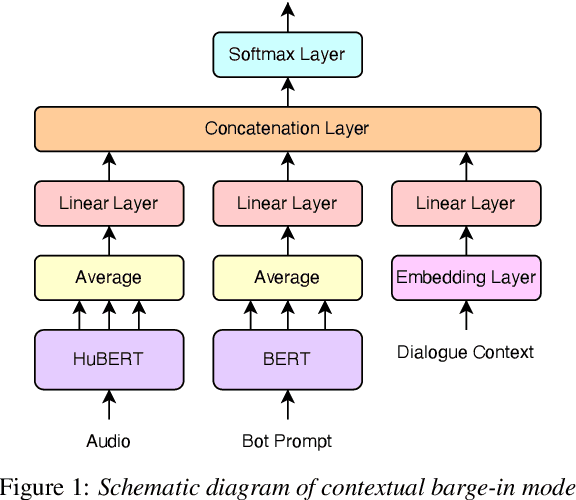
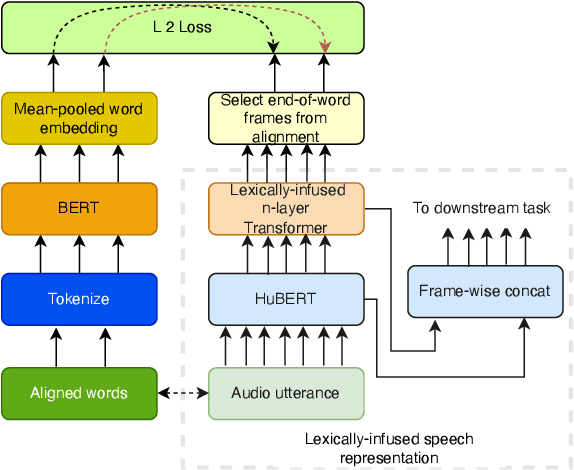
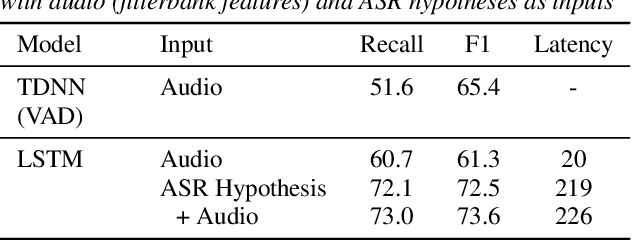
In this work, we define barge-in verification as a supervised learning task where audio-only information is used to classify user spoken dialogue into true and false barge-ins. Following the success of pre-trained models, we use low-level speech representations from a self-supervised representation learning model for our downstream classification task. Further, we propose a novel technique to infuse lexical information directly into speech representations to improve the domain-specific language information implicitly learned during pre-training. Experiments conducted on spoken dialog data show that our proposed model trained to validate barge-in entirely from speech representations is faster by 38% relative and achieves 4.5% relative F1 score improvement over a baseline LSTM model that uses both audio and Automatic Speech Recognition (ASR) 1-best hypotheses. On top of this, our best proposed model with lexically infused representations along with contextual features provides a further relative improvement of 5.7% in the F1 score but only 22% faster than the baseline.
Speaker Anonymization with Phonetic Intermediate Representations
Jul 11, 2022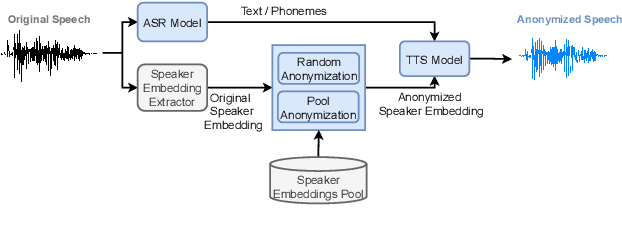
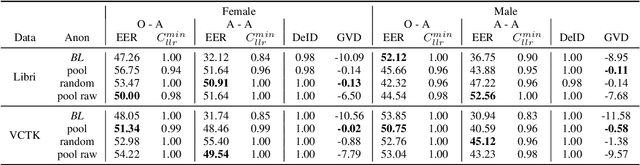

In this work, we propose a speaker anonymization pipeline that leverages high quality automatic speech recognition and synthesis systems to generate speech conditioned on phonetic transcriptions and anonymized speaker embeddings. Using phones as the intermediate representation ensures near complete elimination of speaker identity information from the input while preserving the original phonetic content as much as possible. Our experimental results on LibriSpeech and VCTK corpora reveal two key findings: 1) although automatic speech recognition produces imperfect transcriptions, our neural speech synthesis system can handle such errors, making our system feasible and robust, and 2) combining speaker embeddings from different resources is beneficial and their appropriate normalization is crucial. Overall, our final best system outperforms significantly the baselines provided in the Voice Privacy Challenge 2020 in terms of privacy robustness against a lazy-informed attacker while maintaining high intelligibility and naturalness of the anonymized speech.
Cross-sentence Neural Language Models for Conversational Speech Recognition
Jun 15, 2021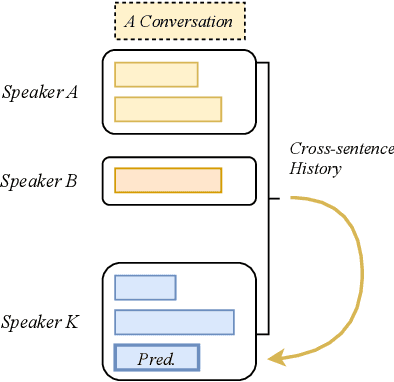
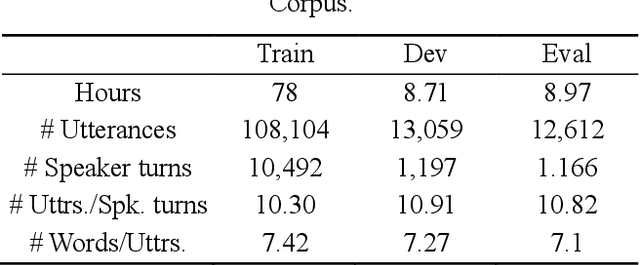
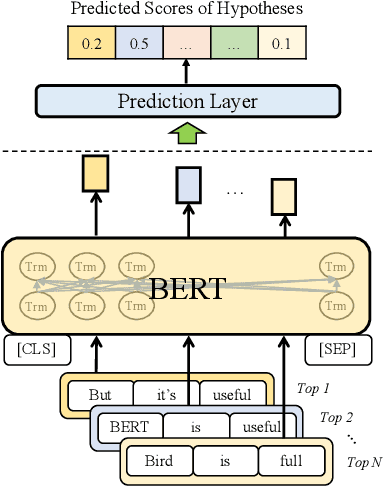
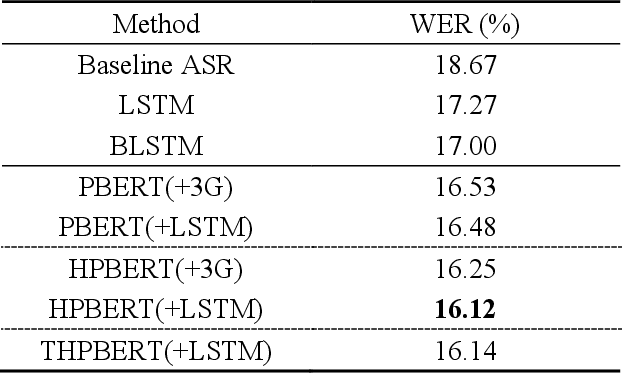
An important research direction in automatic speech recognition (ASR) has centered around the development of effective methods to rerank the output hypotheses of an ASR system with more sophisticated language models (LMs) for further gains. A current mainstream school of thoughts for ASR N-best hypothesis reranking is to employ a recurrent neural network (RNN)-based LM or its variants, with performance superiority over the conventional n-gram LMs across a range of ASR tasks. In real scenarios such as a long conversation, a sequence of consecutive sentences may jointly contain ample cues of conversation-level information such as topical coherence, lexical entrainment and adjacency pairs, which however remains to be underexplored. In view of this, we first formulate ASR N-best reranking as a prediction problem, putting forward an effective cross-sentence neural LM approach that reranks the ASR N-best hypotheses of an upcoming sentence by taking into consideration the word usage in its precedent sentences. Furthermore, we also explore to extract task-specific global topical information of the cross-sentence history in an unsupervised manner for better ASR performance. Extensive experiments conducted on the AMI conversational benchmark corpus indicate the effectiveness and feasibility of our methods in comparison to several state-of-the-art reranking methods.
Exploiting Adapters for Cross-lingual Low-resource Speech Recognition
May 18, 2021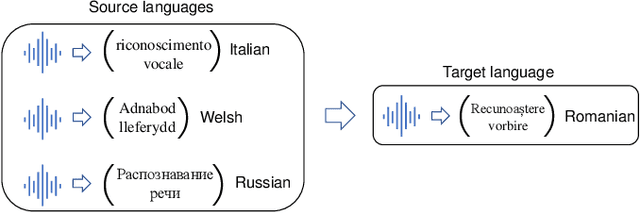
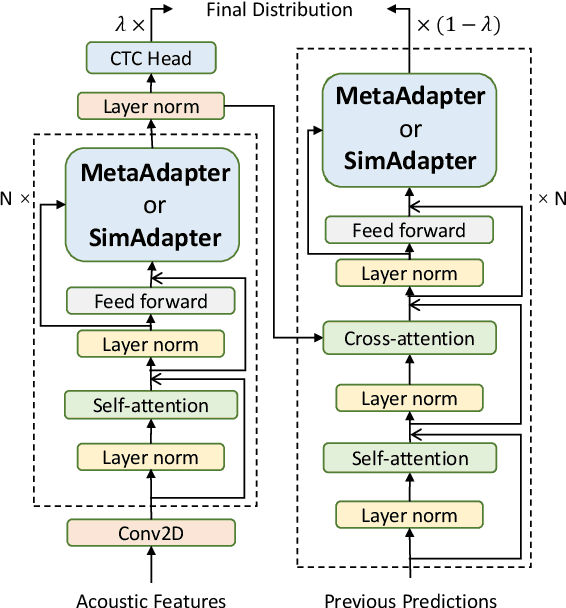
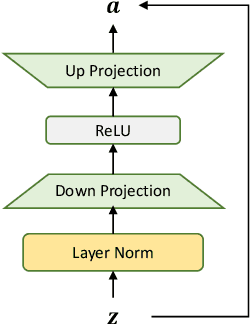
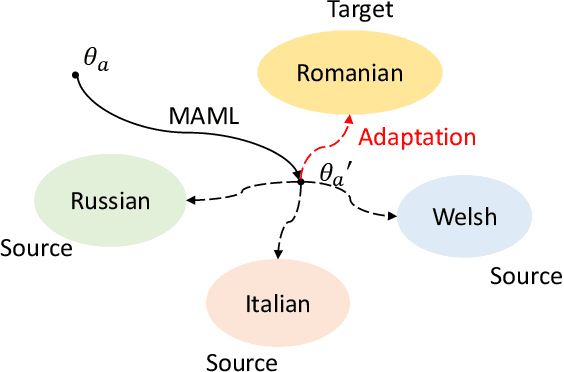
Cross-lingual speech adaptation aims to solve the problem of leveraging multiple rich-resource languages to build models for a low-resource target language. Since the low-resource language has limited training data, speech recognition models can easily overfit. In this paper, we propose to use adapters to investigate the performance of multiple adapters for parameter-efficient cross-lingual speech adaptation. Based on our previous MetaAdapter that implicitly leverages adapters, we propose a novel algorithms called SimAdapter for explicitly learning knowledge from adapters. Our algorithm leverages adapters which can be easily integrated into the Transformer structure.MetaAdapter leverages meta-learning to transfer the general knowledge from training data to the test language. SimAdapter aims to learn the similarities between the source and target languages during fine-tuning using the adapters. We conduct extensive experiments on five-low-resource languages in Common Voice dataset. Results demonstrate that our MetaAdapter and SimAdapter methods can reduce WER by 2.98% and 2.55% with only 2.5% and 15.5% of trainable parameters compared to the strong full-model fine-tuning baseline. Moreover, we also show that these two novel algorithms can be integrated for better performance with up to 3.55% relative WER reduction.
Simulating realistic speech overlaps improves multi-talker ASR
Nov 17, 2022

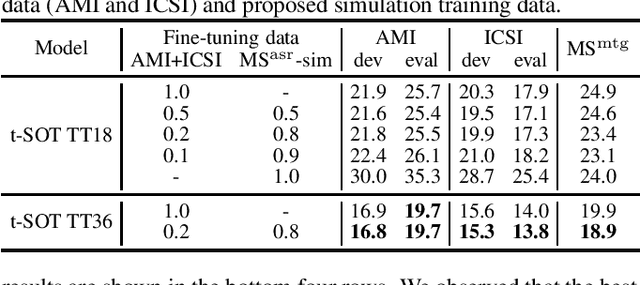
Multi-talker automatic speech recognition (ASR) has been studied to generate transcriptions of natural conversation including overlapping speech of multiple speakers. Due to the difficulty in acquiring real conversation data with high-quality human transcriptions, a na\"ive simulation of multi-talker speech by randomly mixing multiple utterances was conventionally used for model training. In this work, we propose an improved technique to simulate multi-talker overlapping speech with realistic speech overlaps, where an arbitrary pattern of speech overlaps is represented by a sequence of discrete tokens. With this representation, speech overlapping patterns can be learned from real conversations based on a statistical language model, such as N-gram, which can be then used to generate multi-talker speech for training. In our experiments, multi-talker ASR models trained with the proposed method show consistent improvement on the word error rates across multiple datasets.
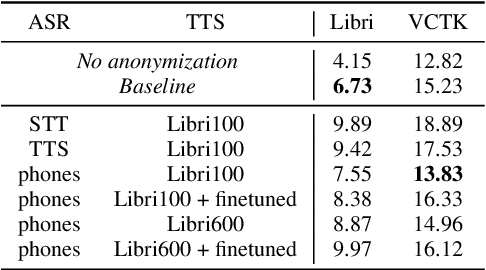
A Simple Baseline for Domain Adaptation in End to End ASR Systems Using Synthetic Data
Jun 22, 2022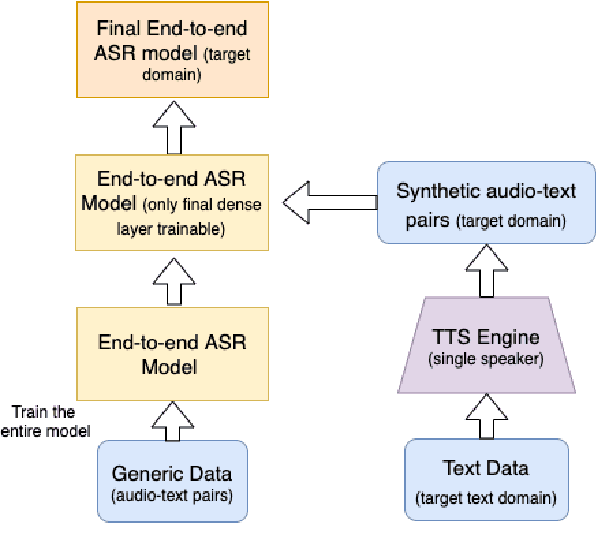
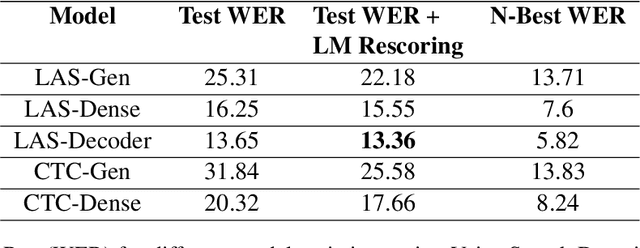
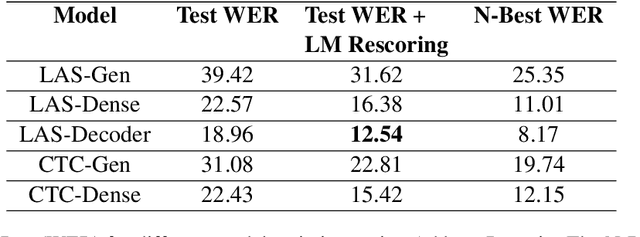
Automatic Speech Recognition(ASR) has been dominated by deep learning-based end-to-end speech recognition models. These approaches require large amounts of labeled data in the form of audio-text pairs. Moreover, these models are more susceptible to domain shift as compared to traditional models. It is common practice to train generic ASR models and then adapt them to target domains using comparatively smaller data sets. We consider a more extreme case of domain adaptation where text-only corpus is available. In this work, we propose a simple baseline technique for domain adaptation in end-to-end speech recognition models. We convert the text-only corpus to audio data using single speaker Text to Speech (TTS) engine. The parallel data in the target domain is then used to fine-tune the final dense layer of generic ASR models. We show that single speaker synthetic TTS data coupled with final dense layer only fine-tuning provides reasonable improvements in word error rates. We use text data from address and e-commerce search domains to show the effectiveness of our low-cost baseline approach on CTC and attention-based models.
Virtuoso: Massive Multilingual Speech-Text Joint Semi-Supervised Learning for Text-To-Speech
Oct 27, 2022
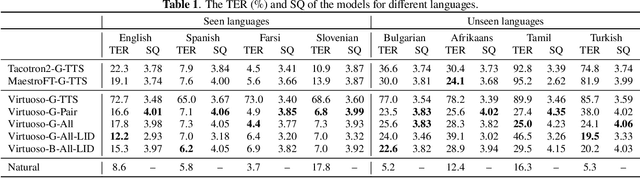
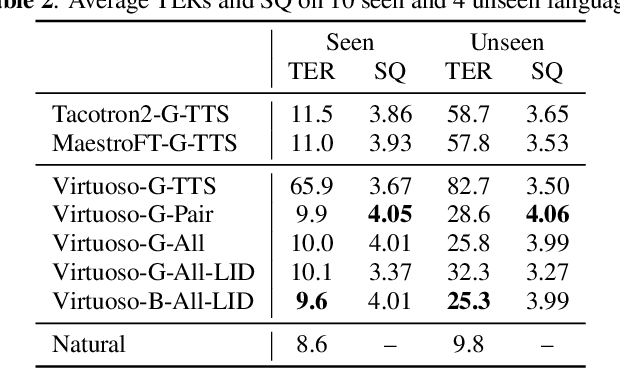
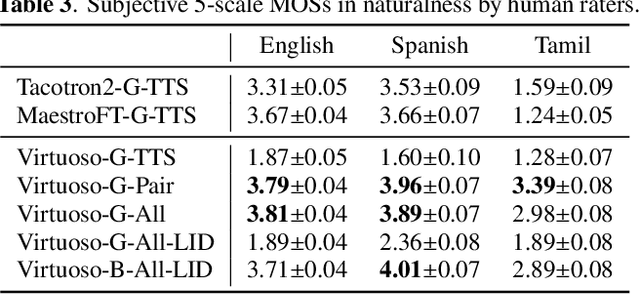
This paper proposes Virtuoso, a massively multilingual speech-text joint semi-supervised learning framework for text-to-speech synthesis (TTS) models. Existing multilingual TTS typically supports tens of languages, which are a small fraction of the thousands of languages in the world. One difficulty to scale multilingual TTS to hundreds of languages is collecting high-quality speech-text paired data in low-resource languages. This study extends Maestro, a speech-text joint pretraining framework for automatic speech recognition (ASR), to speech generation tasks. To train a TTS model from various types of speech and text data, different training schemes are designed to handle supervised (paired TTS and ASR data) and unsupervised (untranscribed speech and unspoken text) datasets. Experimental evaluation shows that 1) multilingual TTS models trained on Virtuoso can achieve significantly better naturalness and intelligibility than baseline ones in seen languages, and 2) they can synthesize reasonably intelligible and naturally sounding speech for unseen languages where no high-quality paired TTS data is available.
Fusing ASR Outputs in Joint Training for Speech Emotion Recognition
Oct 29, 2021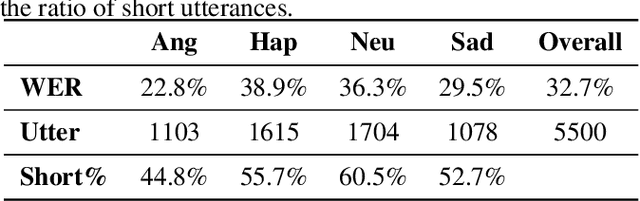
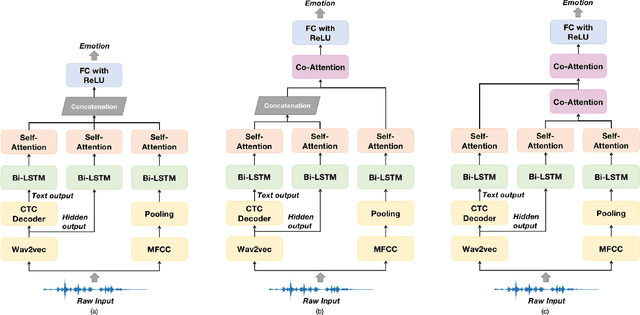
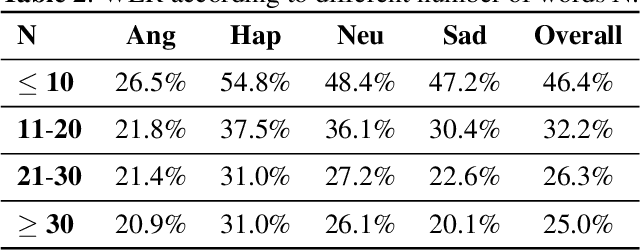

Alongside acoustic information, linguistic features based on speech transcripts have been proven useful in Speech Emotion Recognition (SER). However, due to the scarcity of emotion labelled data and the difficulty of recognizing emotional speech, it is hard to obtain reliable linguistic features and models in this research area. In this paper, we propose to fuse Automatic Speech Recognition (ASR) outputs into the pipeline for joint training SER. The relationship between ASR and SER is understudied, and it is unclear what and how ASR features benefit SER. By examining various ASR outputs and fusion methods, our experiments show that in joint ASR-SER training, incorporating both ASR hidden and text output using a hierarchical co-attention fusion approach improves the SER performance the most. On the IEMOCAP corpus, our approach achieves 63.4% weighted accuracy, which is close to the baseline results achieved by combining ground-truth transcripts. In addition, we also present novel word error rate analysis on IEMOCAP and layer-difference analysis of the Wav2vec 2.0 model to better understand the relationship between ASR and SER.
Robustness of end-to-end Automatic Speech Recognition Models -- A Case Study using Mozilla DeepSpeech
May 08, 2021

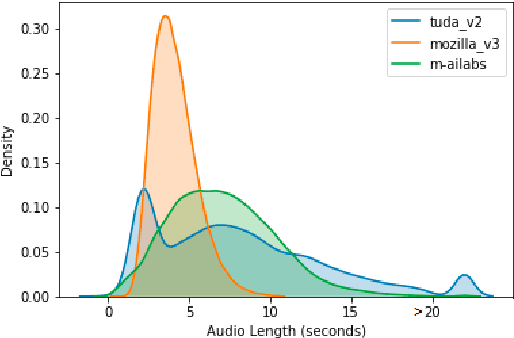
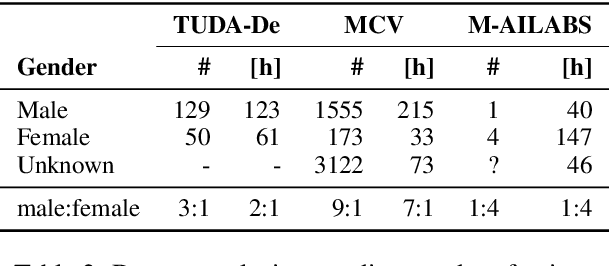
When evaluating the performance of automatic speech recognition models, usually word error rate within a certain dataset is used. Special care must be taken in understanding the dataset in order to report realistic performance numbers. We argue that many performance numbers reported probably underestimate the expected error rate. We conduct experiments controlling for selection bias, gender as well as overlap (between training and test data) in content, voices, and recording conditions. We find that content overlap has the biggest impact, but other factors like gender also play a role.
BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition
Oct 01, 2021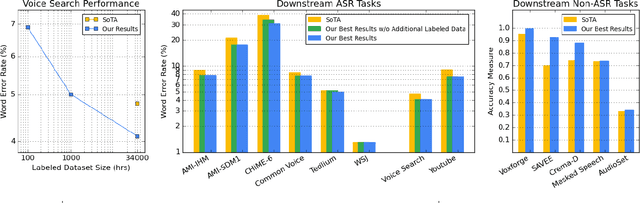
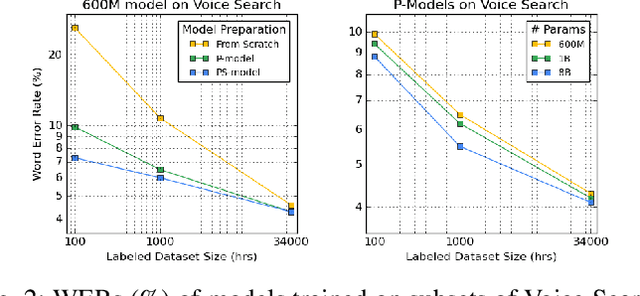
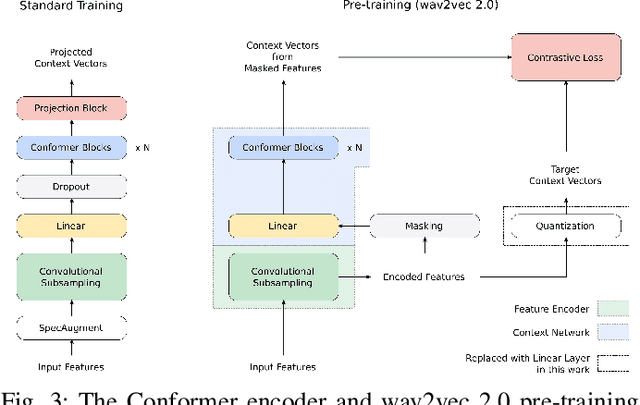
We summarize the results of a host of efforts using giant automatic speech recognition (ASR) models pre-trained using large, diverse unlabeled datasets containing approximately a million hours of audio. We find that the combination of pre-training, self-training and scaling up model size greatly increases data efficiency, even for extremely large tasks with tens of thousands of hours of labeled data. In particular, on an ASR task with 34k hours of labeled data, by fine-tuning an 8 billion parameter pre-trained Conformer model we can match state-of-the-art (SoTA) performance with only 3% of the training data and significantly improve SoTA with the full training set. We also report on the universal benefits gained from using big pre-trained and self-trained models for a large set of downstream tasks that cover a wide range of speech domains and span multiple orders of magnitudes of dataset sizes, including obtaining SoTA performance on many public benchmarks. In addition, we utilize the learned representation of pre-trained networks to achieve SoTA results on non-ASR tasks.