 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Extending Multilingual Speech Synthesis to 100+ Languages without Transcribed Data
Feb 29, 2024



Collecting high-quality studio recordings of audio is challenging, which limits the language coverage of text-to-speech (TTS) systems. This paper proposes a framework for scaling a multilingual TTS model to 100+ languages using found data without supervision. The proposed framework combines speech-text encoder pretraining with unsupervised training using untranscribed speech and unspoken text data sources, thereby leveraging massively multilingual joint speech and text representation learning. Without any transcribed speech in a new language, this TTS model can generate intelligible speech in >30 unseen languages (CER difference of <10% to ground truth). With just 15 minutes of transcribed, found data, we can reduce the intelligibility difference to 1% or less from the ground-truth, and achieve naturalness scores that match the ground-truth in several languages.
E3 TTS: Easy End-to-End Diffusion-based Text to Speech
Nov 02, 2023



We propose Easy End-to-End Diffusion-based Text to Speech, a simple and efficient end-to-end text-to-speech model based on diffusion. E3 TTS directly takes plain text as input and generates an audio waveform through an iterative refinement process. Unlike many prior work, E3 TTS does not rely on any intermediate representations like spectrogram features or alignment information. Instead, E3 TTS models the temporal structure of the waveform through the diffusion process. Without relying on additional conditioning information, E3 TTS could support flexible latent structure within the given audio. This enables E3 TTS to be easily adapted for zero-shot tasks such as editing without any additional training. Experiments show that E3 TTS can generate high-fidelity audio, approaching the performance of a state-of-the-art neural TTS system. Audio samples are available at https://e3tts.github.io.
LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus
May 30, 2023



This paper introduces a new speech dataset called ``LibriTTS-R'' designed for text-to-speech (TTS) use. It is derived by applying speech restoration to the LibriTTS corpus, which consists of 585 hours of speech data at 24 kHz sampling rate from 2,456 speakers and the corresponding texts. The constituent samples of LibriTTS-R are identical to those of LibriTTS, with only the sound quality improved. Experimental results show that the LibriTTS-R ground-truth samples showed significantly improved sound quality compared to those in LibriTTS. In addition, neural end-to-end TTS trained with LibriTTS-R achieved speech naturalness on par with that of the ground-truth samples. The corpus is freely available for download from \url{http://www.openslr.org/141/}.
Miipher: A Robust Speech Restoration Model Integrating Self-Supervised Speech and Text Representations
Mar 03, 2023



Speech restoration (SR) is a task of converting degraded speech signals into high-quality ones. In this study, we propose a robust SR model called Miipher, and apply Miipher to a new SR application: increasing the amount of high-quality training data for speech generation by converting speech samples collected from the Web to studio-quality. To make our SR model robust against various degradation, we use (i) a speech representation extracted from w2v-BERT for the input feature, and (ii) a text representation extracted from transcripts via PnG-BERT as a linguistic conditioning feature. Experiments show that Miipher (i) is robust against various audio degradation and (ii) enable us to train a high-quality text-to-speech (TTS) model from restored speech samples collected from the Web. Audio samples are available at our demo page: google.github.io/df-conformer/miipher/
Residual Adapters for Few-Shot Text-to-Speech Speaker Adaptation
Oct 28, 2022



Adapting a neural text-to-speech (TTS) model to a target speaker typically involves fine-tuning most if not all of the parameters of a pretrained multi-speaker backbone model. However, serving hundreds of fine-tuned neural TTS models is expensive as each of them requires significant footprint and separate computational resources (e.g., accelerators, memory). To scale speaker adapted neural TTS voices to hundreds of speakers while preserving the naturalness and speaker similarity, this paper proposes a parameter-efficient few-shot speaker adaptation, where the backbone model is augmented with trainable lightweight modules called residual adapters. This architecture allows the backbone model to be shared across different target speakers. Experimental results show that the proposed approach can achieve competitive naturalness and speaker similarity compared to the full fine-tuning approaches, while requiring only $\sim$0.1% of the backbone model parameters for each speaker.
Virtuoso: Massive Multilingual Speech-Text Joint Semi-Supervised Learning for Text-To-Speech
Oct 27, 2022



This paper proposes Virtuoso, a massively multilingual speech-text joint semi-supervised learning framework for text-to-speech synthesis (TTS) models. Existing multilingual TTS typically supports tens of languages, which are a small fraction of the thousands of languages in the world. One difficulty to scale multilingual TTS to hundreds of languages is collecting high-quality speech-text paired data in low-resource languages. This study extends Maestro, a speech-text joint pretraining framework for automatic speech recognition (ASR), to speech generation tasks. To train a TTS model from various types of speech and text data, different training schemes are designed to handle supervised (paired TTS and ASR data) and unsupervised (untranscribed speech and unspoken text) datasets. Experimental evaluation shows that 1) multilingual TTS models trained on Virtuoso can achieve significantly better naturalness and intelligibility than baseline ones in seen languages, and 2) they can synthesize reasonably intelligible and naturally sounding speech for unseen languages where no high-quality paired TTS data is available.
Leveraging unsupervised and weakly-supervised data to improve direct speech-to-speech translation
Mar 24, 2022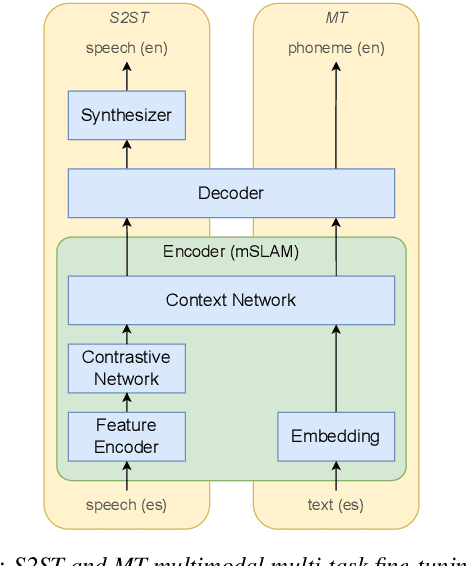
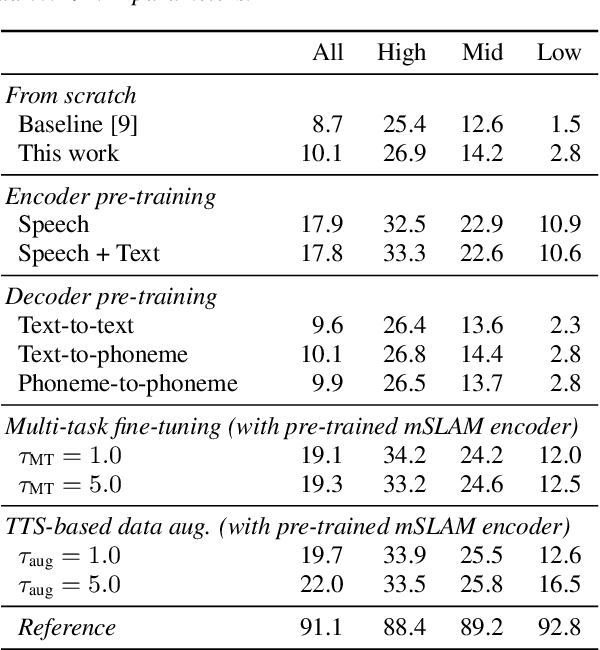
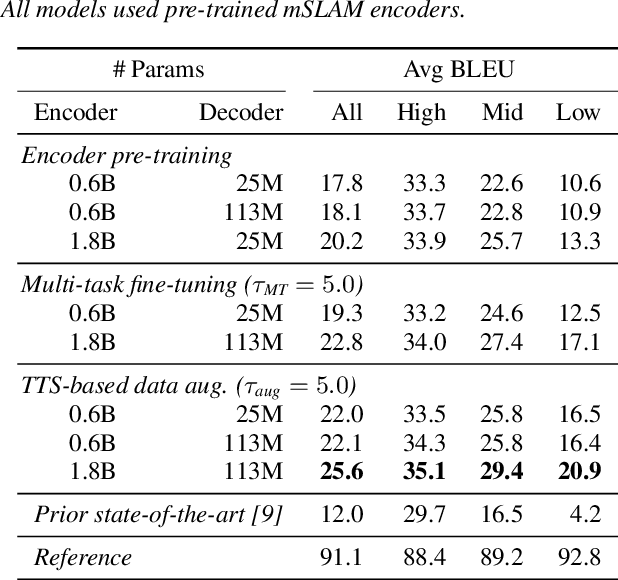
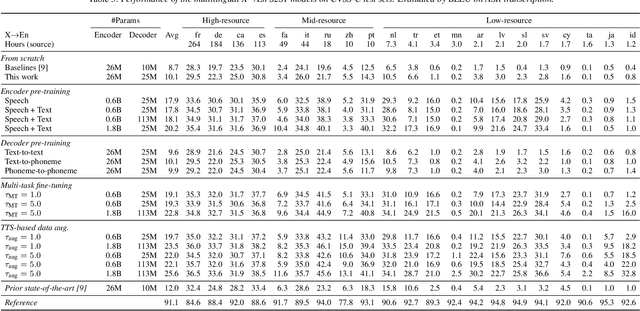
End-to-end speech-to-speech translation (S2ST) without relying on intermediate text representations is a rapidly emerging frontier of research. Recent works have demonstrated that the performance of such direct S2ST systems is approaching that of conventional cascade S2ST when trained on comparable datasets. However, in practice, the performance of direct S2ST is bounded by the availability of paired S2ST training data. In this work, we explore multiple approaches for leveraging much more widely available unsupervised and weakly-supervised speech and text data to improve the performance of direct S2ST based on Translatotron 2. With our most effective approaches, the average translation quality of direct S2ST on 21 language pairs on the CVSS-C corpus is improved by +13.6 BLEU (or +113% relatively), as compared to the previous state-of-the-art trained without additional data. The improvements on low-resource language are even more significant (+398% relatively on average). Our comparative studies suggest future research directions for S2ST and speech representation learning.