 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYODAS: Youtube-Oriented Dataset for Audio and Speech
Jun 02, 2024



In this study, we introduce YODAS (YouTube-Oriented Dataset for Audio and Speech), a large-scale, multilingual dataset comprising currently over 500k hours of speech data in more than 100 languages, sourced from both labeled and unlabeled YouTube speech datasets. The labeled subsets, including manual or automatic subtitles, facilitate supervised model training. Conversely, the unlabeled subsets are apt for self-supervised learning applications. YODAS is distinctive as the first publicly available dataset of its scale, and it is distributed under a Creative Commons license. We introduce the collection methodology utilized for YODAS, which contributes to the large-scale speech dataset construction. Subsequently, we provide a comprehensive analysis of speech, text contained within the dataset. Finally, we describe the speech recognition baselines over the top-15 languages.
Extending Multilingual Speech Synthesis to 100+ Languages without Transcribed Data
Feb 29, 2024



Collecting high-quality studio recordings of audio is challenging, which limits the language coverage of text-to-speech (TTS) systems. This paper proposes a framework for scaling a multilingual TTS model to 100+ languages using found data without supervision. The proposed framework combines speech-text encoder pretraining with unsupervised training using untranscribed speech and unspoken text data sources, thereby leveraging massively multilingual joint speech and text representation learning. Without any transcribed speech in a new language, this TTS model can generate intelligible speech in >30 unseen languages (CER difference of <10% to ground truth). With just 15 minutes of transcribed, found data, we can reduce the intelligibility difference to 1% or less from the ground-truth, and achieve naturalness scores that match the ground-truth in several languages.
SpeechBERTScore: Reference-Aware Automatic Evaluation of Speech Generation Leveraging NLP Evaluation Metrics
Jan 30, 2024While subjective assessments have been the gold standard for evaluating speech generation, there is a growing need for objective metrics that are highly correlated with human subjective judgments due to their cost efficiency. This paper proposes reference-aware automatic evaluation methods for speech generation inspired by evaluation metrics in natural language processing. The proposed SpeechBERTScore computes the BERTScore for self-supervised dense speech features of the generated and reference speech, which can have different sequential lengths. We also propose SpeechBLEU and SpeechTokenDistance, which are computed on speech discrete tokens. The evaluations on synthesized speech show that our method correlates better with human subjective ratings than mel cepstral distortion and a recent mean opinion score prediction model. Also, they are effective in noisy speech evaluation and have cross-lingual applicability.
Diversity-based core-set selection for text-to-speech with linguistic and acoustic features
Sep 15, 2023



This paper proposes a method for extracting a lightweight subset from a text-to-speech (TTS) corpus ensuring synthetic speech quality. In recent years, methods have been proposed for constructing large-scale TTS corpora by collecting diverse data from massive sources such as audiobooks and YouTube. Although these methods have gained significant attention for enhancing the expressive capabilities of TTS systems, they often prioritize collecting vast amounts of data without considering practical constraints like storage capacity and computation time in training, which limits the available data quantity. Consequently, the need arises to efficiently collect data within these volume constraints. To address this, we propose a method for selecting the core subset~(known as \textit{core-set}) from a TTS corpus on the basis of a \textit{diversity metric}, which measures the degree to which a subset encompasses a wide range. Experimental results demonstrate that our proposed method performs significantly better than the baseline phoneme-balanced data selection across language and corpus size.
Duration-aware pause insertion using pre-trained language model for multi-speaker text-to-speech
Feb 27, 2023



Pause insertion, also known as phrase break prediction and phrasing, is an essential part of TTS systems because proper pauses with natural duration significantly enhance the rhythm and intelligibility of synthetic speech. However, conventional phrasing models ignore various speakers' different styles of inserting silent pauses, which can degrade the performance of the model trained on a multi-speaker speech corpus. To this end, we propose more powerful pause insertion frameworks based on a pre-trained language model. Our approach uses bidirectional encoder representations from transformers (BERT) pre-trained on a large-scale text corpus, injecting speaker embedding to capture various speaker characteristics. We also leverage duration-aware pause insertion for more natural multi-speaker TTS. We develop and evaluate two types of models. The first improves conventional phrasing models on the position prediction of respiratory pauses (RPs), i.e., silent pauses at word transitions without punctuation. It performs speaker-conditioned RP prediction considering contextual information and is used to demonstrate the effect of speaker information on the prediction. The second model is further designed for phoneme-based TTS models and performs duration-aware pause insertion, predicting both RPs and punctuation-indicated pauses (PIPs) that are categorized by duration. The evaluation results show that our models improve the precision and recall of pause insertion and the rhythm of synthetic speech.
Learning to Speak from Text: Zero-Shot Multilingual Text-to-Speech with Unsupervised Text Pretraining
Feb 05, 2023



While neural text-to-speech (TTS) has achieved human-like natural synthetic speech, multilingual TTS systems are limited to resource-rich languages due to the need for paired text and studio-quality audio data. This paper proposes a method for zero-shot multilingual TTS using text-only data for the target language. The use of text-only data allows the development of TTS systems for low-resource languages for which only textual resources are available, making TTS accessible to thousands of languages. Inspired by the strong cross-lingual transferability of multilingual language models, our framework first performs masked language model pretraining with multilingual text-only data. Then we train this model with a paired data in a supervised manner, while freezing a language-aware embedding layer. This allows inference even for languages not included in the paired data but present in the text-only data. Evaluation results demonstrate highly intelligible zero-shot TTS with a character error rate of less than 12% for an unseen language. All experiments were conducted using public datasets and the implementation will be made available for reproducibility.
SpeechLMScore: Evaluating speech generation using speech language model
Dec 08, 2022While human evaluation is the most reliable metric for evaluating speech generation systems, it is generally costly and time-consuming. Previous studies on automatic speech quality assessment address the problem by predicting human evaluation scores with machine learning models. However, they rely on supervised learning and thus suffer from high annotation costs and domain-shift problems. We propose SpeechLMScore, an unsupervised metric to evaluate generated speech using a speech-language model. SpeechLMScore computes the average log-probability of a speech signal by mapping it into discrete tokens and measures the average probability of generating the sequence of tokens. Therefore, it does not require human annotation and is a highly scalable framework. Evaluation results demonstrate that the proposed metric shows a promising correlation with human evaluation scores on different speech generation tasks including voice conversion, text-to-speech, and speech enhancement.
Virtuoso: Massive Multilingual Speech-Text Joint Semi-Supervised Learning for Text-To-Speech
Oct 27, 2022



This paper proposes Virtuoso, a massively multilingual speech-text joint semi-supervised learning framework for text-to-speech synthesis (TTS) models. Existing multilingual TTS typically supports tens of languages, which are a small fraction of the thousands of languages in the world. One difficulty to scale multilingual TTS to hundreds of languages is collecting high-quality speech-text paired data in low-resource languages. This study extends Maestro, a speech-text joint pretraining framework for automatic speech recognition (ASR), to speech generation tasks. To train a TTS model from various types of speech and text data, different training schemes are designed to handle supervised (paired TTS and ASR data) and unsupervised (untranscribed speech and unspoken text) datasets. Experimental evaluation shows that 1) multilingual TTS models trained on Virtuoso can achieve significantly better naturalness and intelligibility than baseline ones in seen languages, and 2) they can synthesize reasonably intelligible and naturally sounding speech for unseen languages where no high-quality paired TTS data is available.
Text-to-speech synthesis from dark data with evaluation-in-the-loop data selection
Oct 26, 2022This paper proposes a method for selecting training data for text-to-speech (TTS) synthesis from dark data. TTS models are typically trained on high-quality speech corpora that cost much time and money for data collection, which makes it very challenging to increase speaker variation. In contrast, there is a large amount of data whose availability is unknown (a.k.a, "dark data"), such as YouTube videos. To utilize data other than TTS corpora, previous studies have selected speech data from the corpora on the basis of acoustic quality. However, considering that TTS models robust to data noise have been proposed, we should select data on the basis of its importance as training data to the given TTS model, not the quality of speech itself. Our method with a loop of training and evaluation selects training data on the basis of the automatically predicted quality of synthetic speech of a given TTS model. Results of evaluations using YouTube data reveal that our method outperforms the conventional acoustic-quality-based method.
Spontaneous speech synthesis with linguistic-speech consistency training using pseudo-filled pauses
Oct 18, 2022

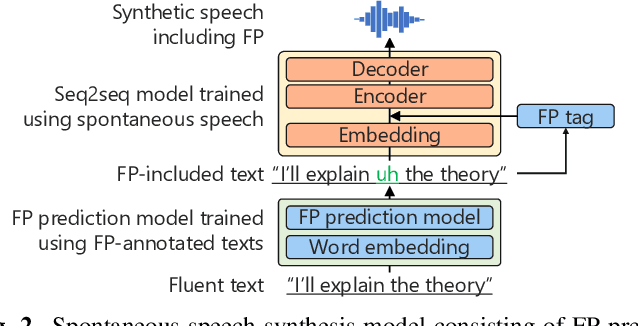

We propose a training method for spontaneous speech synthesis models that guarantees the consistency of linguistic parts of synthesized speech. Personalized spontaneous speech synthesis aims to reproduce the individuality of disfluency, such as filled pauses. Our prior model includes a filled-pause prediction model and synthesizes filled-pause-included speech from text without filled pauses. However, inserting the filled pauses degrades the quality of the linguistic parts of the synthesized speech. This might be because filled-pause insertion tendencies differ between training and inference, and the synthesis model cannot represent connections between filled pauses and surrounding phonemes in inference. We, therefore, developed a linguistic-speech consistency training that guarantees the consistency of linguistic parts of synthetic speech with and without filled pauses. The proposed consistency training utilizes not only ground-truth-filled pauses but also pseudo ones. Our experiments demonstrate that this method improves the naturalness of the synthetic linguistic speech and the entire predicted-filled-pause-included synthetic speech.