 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
EmoGen: Eliminating Subjective Bias in Emotional Music Generation
Jul 03, 2023
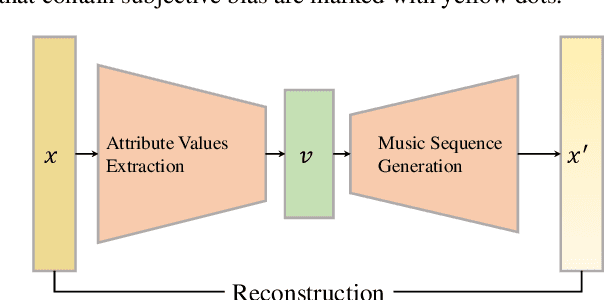

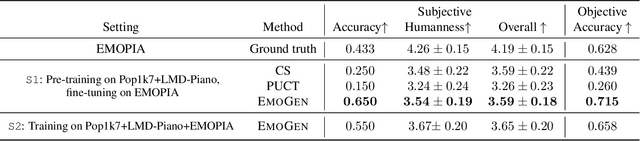
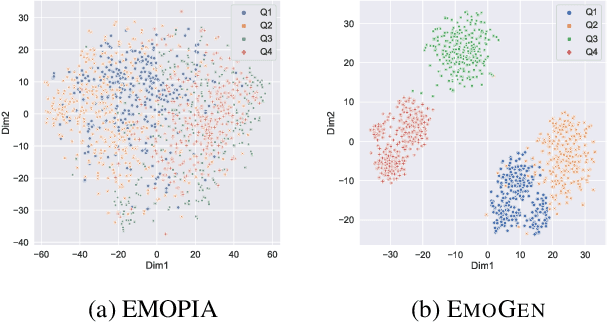
Music is used to convey emotions, and thus generating emotional music is important in automatic music generation. Previous work on emotional music generation directly uses annotated emotion labels as control signals, which suffers from subjective bias: different people may annotate different emotions on the same music, and one person may feel different emotions under different situations. Therefore, directly mapping emotion labels to music sequences in an end-to-end way would confuse the learning process and hinder the model from generating music with general emotions. In this paper, we propose EmoGen, an emotional music generation system that leverages a set of emotion-related music attributes as the bridge between emotion and music, and divides the generation into two stages: emotion-to-attribute mapping with supervised clustering, and attribute-to-music generation with self-supervised learning. Both stages are beneficial: in the first stage, the attribute values around the clustering center represent the general emotions of these samples, which help eliminate the impacts of the subjective bias of emotion labels; in the second stage, the generation is completely disentangled from emotion labels and thus free from the subjective bias. Both subjective and objective evaluations show that EmoGen outperforms previous methods on emotion control accuracy and music quality respectively, which demonstrate our superiority in generating emotional music. Music samples generated by EmoGen are available via this link:https://ai-muzic.github.io/emogen/, and the code is available at this link:https://github.com/microsoft/muzic/.
BigWavGAN: A Wave-To-Wave Generative Adversarial Network for Music Super-Resolution
Aug 12, 2023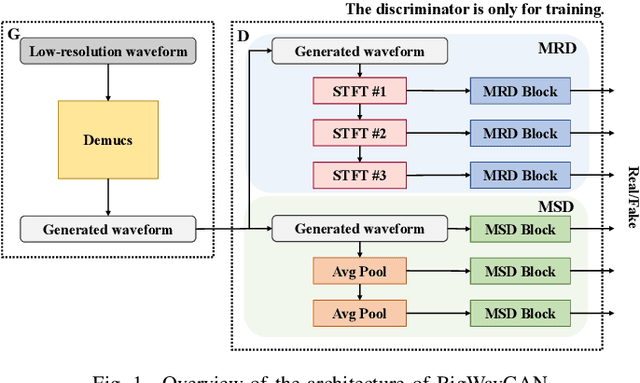
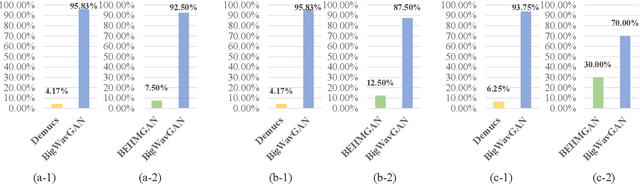
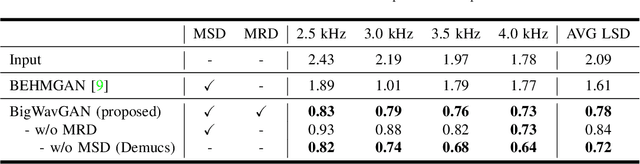
Generally, Deep Neural Networks (DNNs) are expected to have high performance when their model size is large. However, large models failed to produce high-quality results commensurate with their scale in music Super-Resolution (SR). We attribute this to that DNNs cannot learn information commensurate with their size from standard mean square error losses. To unleash the potential of large DNN models in music SR, we propose BigWavGAN, which incorporates Demucs, a large-scale wave-to-wave model, with State-Of-The-Art (SOTA) discriminators and adversarial training strategies. Our discriminator consists of Multi-Scale Discriminator (MSD) and Multi-Resolution Discriminator (MRD). During inference, since only the generator is utilized, there are no additional parameters or computational resources required compared to the baseline model Demucs. Objective evaluation affirms the effectiveness of BigWavGAN in music SR. Subjective evaluations indicate that BigWavGAN can generate music with significantly high perceptual quality over the baseline model. Notably, BigWavGAN surpasses the SOTA music SR model in both simulated and real-world scenarios. Moreover, BigWavGAN represents its superior generalization ability to address out-of-distribution data. The conducted ablation study reveals the importance of our discriminators and training strategies. Samples are available on the demo page.
Local Periodicity-Based Beat Tracking for Expressive Classical Piano Music
Aug 20, 2023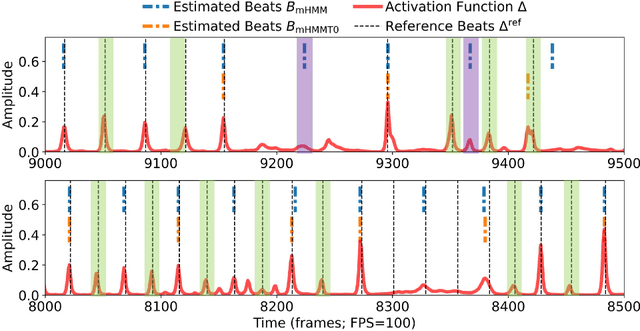
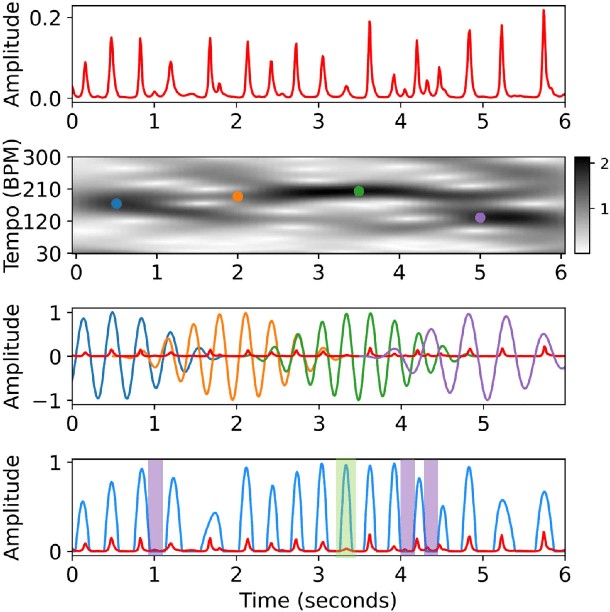
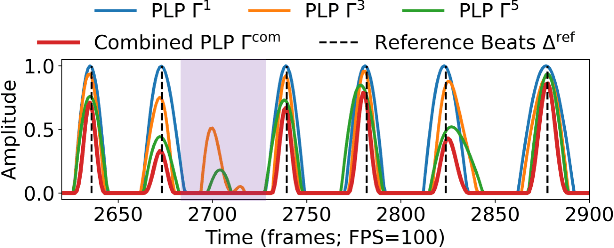
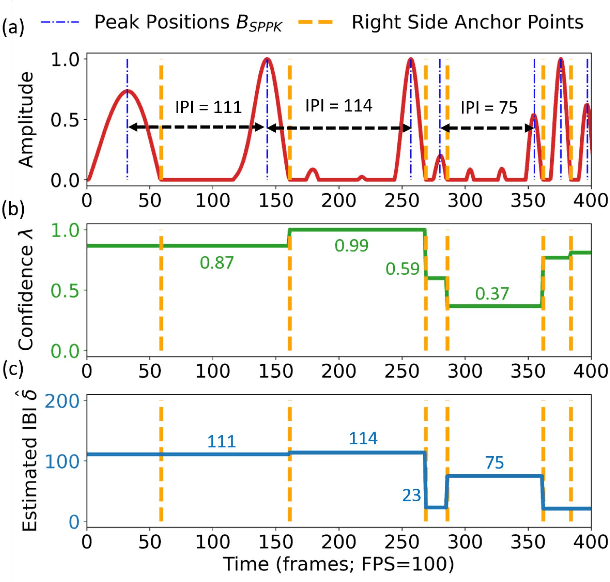
To model the periodicity of beats, state-of-the-art beat tracking systems use "post-processing trackers" (PPTs) that rely on several empirically determined global assumptions for tempo transition, which work well for music with a steady tempo. For expressive classical music, however, these assumptions can be too rigid. With two large datasets of Western classical piano music, namely the Aligned Scores and Performances (ASAP) dataset and a dataset of Chopin's Mazurkas (Maz-5), we report on experiments showing the failure of existing PPTs to cope with local tempo changes, thus calling for new methods. In this paper, we propose a new local periodicity-based PPT, called predominant local pulse-based dynamic programming (PLPDP) tracking, that allows for more flexible tempo transitions. Specifically, the new PPT incorporates a method called "predominant local pulses" (PLP) in combination with a dynamic programming (DP) component to jointly consider the locally detected periodicity and beat activation strength at each time instant. Accordingly, PLPDP accounts for the local periodicity, rather than relying on a global tempo assumption. Compared to existing PPTs, PLPDP particularly enhances the recall values at the cost of a lower precision, resulting in an overall improvement of F1-score for beat tracking in ASAP (from 0.473 to 0.493) and Maz-5 (from 0.595 to 0.838).
ChoralSynth: Synthetic Dataset of Choral Singing
Nov 21, 2023Choral singing, a widely practiced form of ensemble singing, lacks comprehensive datasets in the realm of Music Information Retrieval (MIR) research, due to challenges arising from the requirement to curate multitrack recordings. To address this, we devised a novel methodology, leveraging state-of-the-art synthesizers to create and curate quality renditions. The scores were sourced from Choral Public Domain Library(CPDL). This work is done in collaboration with a diverse team of musicians, software engineers and researchers. The resulting dataset, complete with its associated metadata, and methodology is released as part of this work, opening up new avenues for exploration and advancement in the field of singing voice research.
MARBLE: Music Audio Representation Benchmark for Universal Evaluation
Jul 12, 2023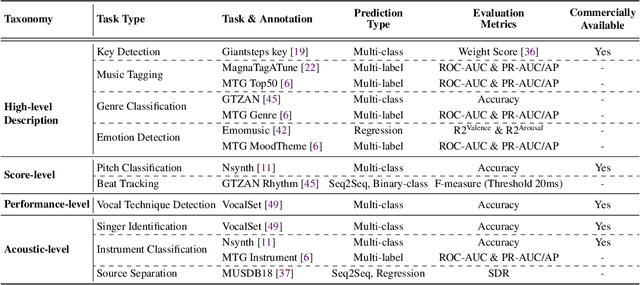
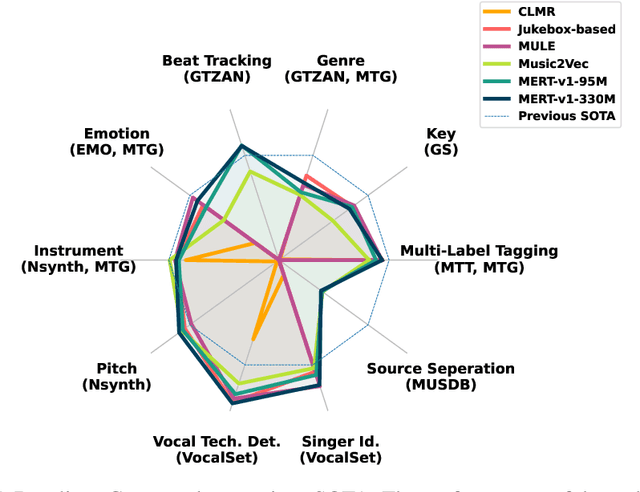
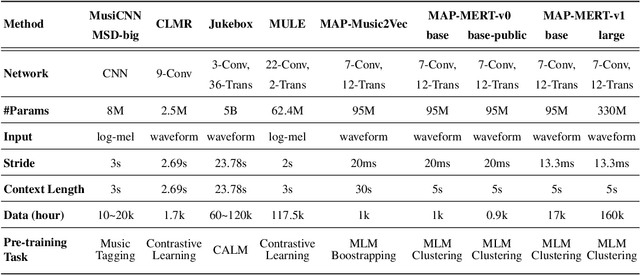
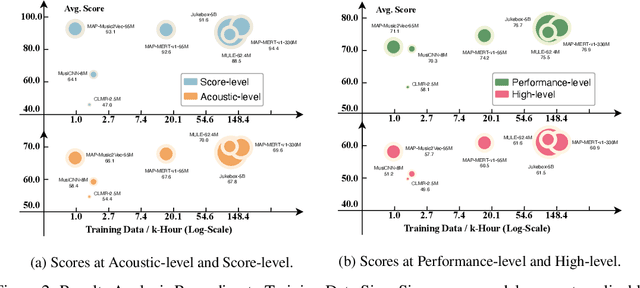
In the era of extensive intersection between art and Artificial Intelligence (AI), such as image generation and fiction co-creation, AI for music remains relatively nascent, particularly in music understanding. This is evident in the limited work on deep music representations, the scarcity of large-scale datasets, and the absence of a universal and community-driven benchmark. To address this issue, we introduce the Music Audio Representation Benchmark for universaL Evaluation, termed MARBLE. It aims to provide a benchmark for various Music Information Retrieval (MIR) tasks by defining a comprehensive taxonomy with four hierarchy levels, including acoustic, performance, score, and high-level description. We then establish a unified protocol based on 14 tasks on 8 public-available datasets, providing a fair and standard assessment of representations of all open-sourced pre-trained models developed on music recordings as baselines. Besides, MARBLE offers an easy-to-use, extendable, and reproducible suite for the community, with a clear statement on copyright issues on datasets. Results suggest recently proposed large-scale pre-trained musical language models perform the best in most tasks, with room for further improvement. The leaderboard and toolkit repository are published at https://marble-bm.shef.ac.uk to promote future music AI research.
MUSIC Algorithm for IRS-Assisted AOA Estimation
Sep 06, 2023Based on the signals received across its antennas, a multi-antenna base station (BS) can apply the classic multiple signal classification (MUSIC) algorithm for estimating the angle of arrivals (AOAs) of its incident signals. This method can be leveraged to localize the users if their line-of-sight (LOS) paths to the BS are available. In this paper, we consider a more challenging AOA estimation setup in the intelligent reflecting surface (IRS) assisted integrated sensing and communication (ISAC) system, where LOS paths do not exist between the BS and the users, while the users' signals can be transmitted to the BS merely via their LOS paths to the IRS as well as the LOS path from the IRS to the BS. Specifically, we treat the IRS as the anchor and are interested in estimating the AOAs of the incident signals from the users to the IRS. Note that we have to achieve the above goal based on the signals received by the BS, because the passive IRS cannot process its received signals. However, the signals received across different antennas of the BS only contain AOA information of its incident signals via the LOS path from the IRS to the BS. To tackle this challenge arising from the spatial-domain received signals, we propose an innovative approach to create temporal-domain multi-dimension received signals for estimating the AOAs of the paths from the users to the IRS. Specifically, via a proper design of the user message pattern and the IRS reflecting pattern, we manage to show that our designed temporal-domain multi-dimension signals can be surprisingly expressed as a function of the virtual steering vectors of the IRS towards the users. This amazing result implies that the classic MUSIC algorithm can be applied to our designed temporal-domain multi-dimension signals for accurately estimating the AOAs of the signals from the users to the IRS.
Knowledge-based Multimodal Music Similarity
Jun 21, 2023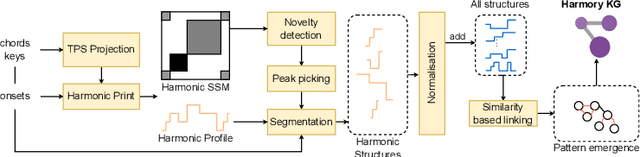
Music similarity is an essential aspect of music retrieval, recommendation systems, and music analysis. Moreover, similarity is of vital interest for music experts, as it allows studying analogies and influences among composers and historical periods. Current approaches to musical similarity rely mainly on symbolic content, which can be expensive to produce and is not always readily available. Conversely, approaches using audio signals typically fail to provide any insight about the reasons behind the observed similarity. This research addresses the limitations of current approaches by focusing on the study of musical similarity using both symbolic and audio content. The aim of this research is to develop a fully explainable and interpretable system that can provide end-users with more control and understanding of music similarity and classification systems.
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
Nov 27, 2023We introduce MMMU: a new benchmark designed to evaluate multimodal models on massive multi-discipline tasks demanding college-level subject knowledge and deliberate reasoning. MMMU includes 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering. These questions span 30 subjects and 183 subfields, comprising 30 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. Unlike existing benchmarks, MMMU focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. Our evaluation of 14 open-source LMMs and the proprietary GPT-4V(ision) highlights the substantial challenges posed by MMMU. Even the advanced GPT-4V only achieves a 56% accuracy, indicating significant room for improvement. We believe MMMU will stimulate the community to build next-generation multimodal foundation models towards expert artificial general intelligence.
VampNet: Music Generation via Masked Acoustic Token Modeling
Jul 12, 2023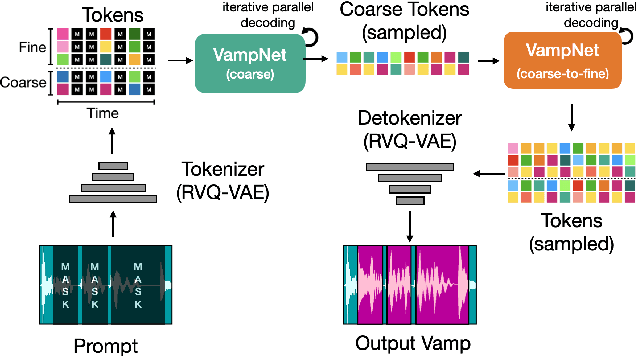
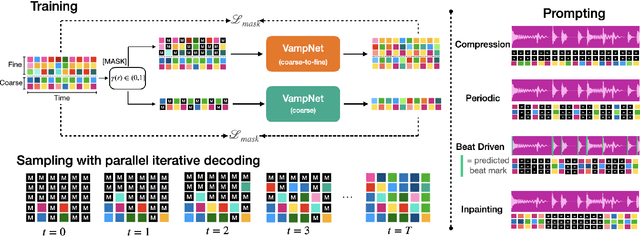
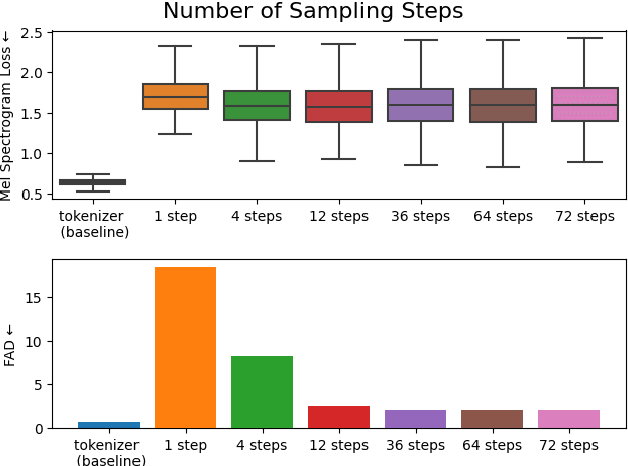

We introduce VampNet, a masked acoustic token modeling approach to music synthesis, compression, inpainting, and variation. We use a variable masking schedule during training which allows us to sample coherent music from the model by applying a variety of masking approaches (called prompts) during inference. VampNet is non-autoregressive, leveraging a bidirectional transformer architecture that attends to all tokens in a forward pass. With just 36 sampling passes, VampNet can generate coherent high-fidelity musical waveforms. We show that by prompting VampNet in various ways, we can apply it to tasks like music compression, inpainting, outpainting, continuation, and looping with variation (vamping). Appropriately prompted, VampNet is capable of maintaining style, genre, instrumentation, and other high-level aspects of the music. This flexible prompting capability makes VampNet a powerful music co-creation tool. Code and audio samples are available online.
Emotion4MIDI: a Lyrics-based Emotion-Labeled Symbolic Music Dataset
Jul 27, 2023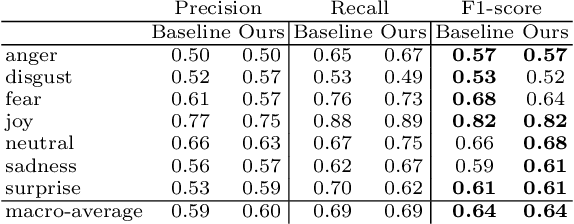
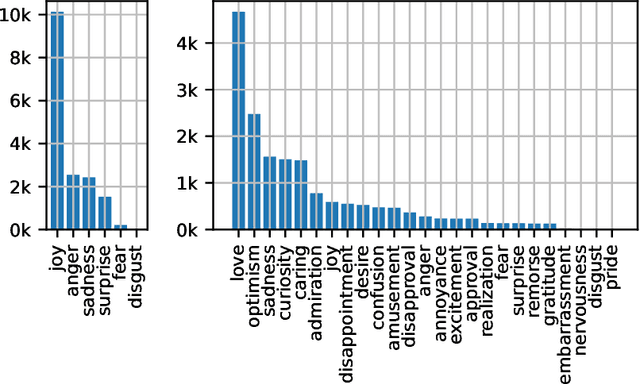
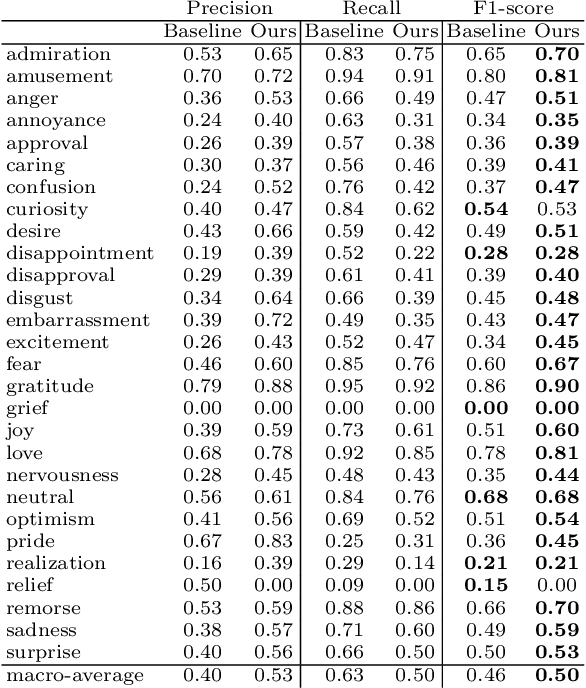
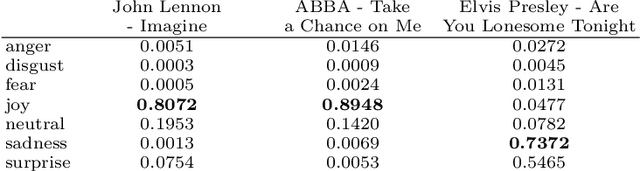
We present a new large-scale emotion-labeled symbolic music dataset consisting of 12k MIDI songs. To create this dataset, we first trained emotion classification models on the GoEmotions dataset, achieving state-of-the-art results with a model half the size of the baseline. We then applied these models to lyrics from two large-scale MIDI datasets. Our dataset covers a wide range of fine-grained emotions, providing a valuable resource to explore the connection between music and emotions and, especially, to develop models that can generate music based on specific emotions. Our code for inference, trained models, and datasets are available online.