 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the limits and opportunities of AI reviewers: Reviewing the reviews of Nature-family papers with 45 expert scientists
May 20, 2026With the advancement of AI capabilities, AI reviewers are beginning to be deployed in scientific peer review, yet their capability and credibility remain in question: many scientists simply view them as probabilistic systems without the expertise to evaluate research, while other researchers are more optimistic about their readiness without concrete evidence. Understanding what AI reviewers do well, where they fall short, and what challenges remain is essential. However, existing evaluations of AI reviewers have focused on whether their verdicts match human verdicts (e.g., score alignment, acceptance prediction), which is insufficient to characterize their capabilities and limits. In this paper, we close this gap through a large-scale expert annotation study, in which 45 domain scientists in Physical, Biological, and Health Sciences spent 469 hours rating 2,960 individual criticisms (each targeting one specific aspect of a paper) from human-written and AI-generated reviews of 82 Nature-family papers on correctness, significance, and sufficiency of evidence. On a composite of all three dimensions, a reviewing agent powered by GPT-5.2 scores above each paper's top-rated human reviewer (60.0% vs. 48.2%, p = 0.009), while all three AI reviewers (including Gemini 3.0 Pro and Claude Opus 4.5) exceed the lowest-rated human across every dimension. AI reviewers' accurate criticisms are also more often rated significant and well-evidenced, and surface a distinct 26% of issues no human raises. However, AI reviewers overlap far more than humans do (21% vs. 3% for cross-reviewer pairs), and exhibit 16 recurring weaknesses humans do not share, such as limited subfield knowledge, lack of long context management over multiple files, and overly critical stance on minor issues. Overall, our results position current AI reviewers as complements to, not substitutes for, human reviewers.
PhysicianBench: Evaluating LLM Agents in Real-World EHR Environments
May 04, 2026We introduce PhysicianBench, a benchmark for evaluating LLM agents on physician tasks grounded in real clinical setting within electronic health record (EHR) environments. Existing medical agent benchmarks primarily focus on static knowledge recall, single-step atomic actions, or action intent without verifiable execution against the environment. As a result, they fail to capture the long-horizon, composite workflows that characterize real clinical systems. PhysicianBench comprises 100 long-horizon tasks adapted from real consultation cases between primary care and subspecialty physicians, with each task independently reviewed by a separate panel of physicians. Tasks are instantiated in an EHR environment with real patient records and accessed through the same standard APIs used by commercial EHR vendors. Tasks span 21 specialties (e.g., cardiology, endocrinology, oncology, psychiatry) and diverse workflow types (e.g., diagnosis interpretation, medication prescribing, treatment planning), requiring an average of 27 tool calls per task. Solving each task requires retrieving data across encounters, reasoning over heterogeneous clinical information, executing consequential clinical actions, and producing clinical documentation. Each task is decomposed into structured checkpoints (670 in total across the benchmark) capturing distinct stages of completion graded by task-specific scripts with execution-grounded verification. Across 13 proprietary and open-source LLM agents, the best-performing model achieves only 46% success rate (pass@1), while open-source models reach at most 19%, revealing a substantial gap between current agent capabilities and the demands of real-world clinical workflows. PhysicianBench provides a realistic and execution-grounded benchmark for measuring progress toward autonomous clinical agents.
ClinicalTrialsHub: Bridging Registries and Literature for Comprehensive Clinical Trial Access
Dec 09, 2025



We present ClinicalTrialsHub, an interactive search-focused platform that consolidates all data from ClinicalTrials.gov and augments it by automatically extracting and structuring trial-relevant information from PubMed research articles. Our system effectively increases access to structured clinical trial data by 83.8% compared to relying on ClinicalTrials.gov alone, with potential to make access easier for patients, clinicians, researchers, and policymakers, advancing evidence-based medicine. ClinicalTrialsHub uses large language models such as GPT-5.1 and Gemini-3-Pro to enhance accessibility. The platform automatically parses full-text research articles to extract structured trial information, translates user queries into structured database searches, and provides an attributed question-answering system that generates evidence-grounded answers linked to specific source sentences. We demonstrate its utility through a user study involving clinicians, clinical researchers, and PhD students of pharmaceutical sciences and nursing, and a systematic automatic evaluation of its information extraction and question answering capabilities.
A Deep Subgrouping Framework for Precision Drug Repurposing via Emulating Clinical Trials on Real-world Patient Data
Dec 29, 2024Drug repurposing identifies new therapeutic uses for existing drugs, reducing the time and costs compared to traditional de novo drug discovery. Most existing drug repurposing studies using real-world patient data often treat the entire population as homogeneous, ignoring the heterogeneity of treatment responses across patient subgroups. This approach may overlook promising drugs that benefit specific subgroups but lack notable treatment effects across the entire population, potentially limiting the number of repurposable candidates identified. To address this, we introduce STEDR, a novel drug repurposing framework that integrates subgroup analysis with treatment effect estimation. Our approach first identifies repurposing candidates by emulating multiple clinical trials on real-world patient data and then characterizes patient subgroups by learning subgroup-specific treatment effects. We deploy \model to Alzheimer's Disease (AD), a condition with few approved drugs and known heterogeneity in treatment responses. We emulate trials for over one thousand medications on a large-scale real-world database covering over 8 million patients, identifying 14 drug candidates with beneficial effects to AD in characterized subgroups. Experiments demonstrate STEDR's superior capability in identifying repurposing candidates compared to existing approaches. Additionally, our method can characterize clinically relevant patient subgroups associated with important AD-related risk factors, paving the way for precision drug repurposing.
Teach Multimodal LLMs to Comprehend Electrocardiographic Images
Oct 21, 2024



The electrocardiogram (ECG) is an essential non-invasive diagnostic tool for assessing cardiac conditions. Existing automatic interpretation methods suffer from limited generalizability, focusing on a narrow range of cardiac conditions, and typically depend on raw physiological signals, which may not be readily available in resource-limited settings where only printed or digital ECG images are accessible. Recent advancements in multimodal large language models (MLLMs) present promising opportunities for addressing these challenges. However, the application of MLLMs to ECG image interpretation remains challenging due to the lack of instruction tuning datasets and well-established ECG image benchmarks for quantitative evaluation. To address these challenges, we introduce ECGInstruct, a comprehensive ECG image instruction tuning dataset of over one million samples, covering a wide range of ECG-related tasks from diverse data sources. Using ECGInstruct, we develop PULSE, an MLLM tailored for ECG image comprehension. In addition, we curate ECGBench, a new evaluation benchmark covering four key ECG image interpretation tasks across nine different datasets. Our experiments show that PULSE sets a new state-of-the-art, outperforming general MLLMs with an average accuracy improvement of 15% to 30%. This work highlights the potential of PULSE to enhance ECG interpretation in clinical practice.
KG-TREAT: Pre-training for Treatment Effect Estimation by Synergizing Patient Data with Knowledge Graphs
Mar 06, 2024



Treatment effect estimation (TEE) is the task of determining the impact of various treatments on patient outcomes. Current TEE methods fall short due to reliance on limited labeled data and challenges posed by sparse and high-dimensional observational patient data. To address the challenges, we introduce a novel pre-training and fine-tuning framework, KG-TREAT, which synergizes large-scale observational patient data with biomedical knowledge graphs (KGs) to enhance TEE. Unlike previous approaches, KG-TREAT constructs dual-focus KGs and integrates a deep bi-level attention synergy method for in-depth information fusion, enabling distinct encoding of treatment-covariate and outcome-covariate relationships. KG-TREAT also incorporates two pre-training tasks to ensure a thorough grounding and contextualization of patient data and KGs. Evaluation on four downstream TEE tasks shows KG-TREAT's superiority over existing methods, with an average improvement of 7% in Area under the ROC Curve (AUC) and 9% in Influence Function-based Precision of Estimating Heterogeneous Effects (IF-PEHE). The effectiveness of our estimated treatment effects is further affirmed by alignment with established randomized clinical trial findings.
Heterogeneous treatment effect estimation with subpopulation identification for personalized medicine in opioid use disorder
Jan 30, 2024



Deep learning models have demonstrated promising results in estimating treatment effects (TEE). However, most of them overlook the variations in treatment outcomes among subgroups with distinct characteristics. This limitation hinders their ability to provide accurate estimations and treatment recommendations for specific subgroups. In this study, we introduce a novel neural network-based framework, named SubgroupTE, which incorporates subgroup identification and treatment effect estimation. SubgroupTE identifies diverse subgroups and simultaneously estimates treatment effects for each subgroup, improving the treatment effect estimation by considering the heterogeneity of treatment responses. Comparative experiments on synthetic data show that SubgroupTE outperforms existing models in treatment effect estimation. Furthermore, experiments on a real-world dataset related to opioid use disorder (OUD) demonstrate the potential of our approach to enhance personalized treatment recommendations for OUD patients.
SubgroupTE: Advancing Treatment Effect Estimation with Subgroup Identification
Jan 22, 2024



Precise estimation of treatment effects is crucial for evaluating intervention effectiveness. While deep learning models have exhibited promising performance in learning counterfactual representations for treatment effect estimation (TEE), a major limitation in most of these models is that they treat the entire population as a homogeneous group, overlooking the diversity of treatment effects across potential subgroups that have varying treatment effects. This limitation restricts the ability to precisely estimate treatment effects and provide subgroup-specific treatment recommendations. In this paper, we propose a novel treatment effect estimation model, named SubgroupTE, which incorporates subgroup identification in TEE. SubgroupTE identifies heterogeneous subgroups with different treatment responses and more precisely estimates treatment effects by considering subgroup-specific causal effects. In addition, SubgroupTE iteratively optimizes subgrouping and treatment effect estimation networks to enhance both estimation and subgroup identification. Comprehensive experiments on the synthetic and semi-synthetic datasets exhibit the outstanding performance of SubgroupTE compared with the state-of-the-art models on treatment effect estimation. Additionally, a real-world study demonstrates the capabilities of SubgroupTE in enhancing personalized treatment recommendations for patients with opioid use disorder (OUD) by advancing treatment effect estimation with subgroup identification.
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
Nov 27, 2023



We introduce MMMU: a new benchmark designed to evaluate multimodal models on massive multi-discipline tasks demanding college-level subject knowledge and deliberate reasoning. MMMU includes 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering. These questions span 30 subjects and 183 subfields, comprising 30 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. Unlike existing benchmarks, MMMU focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. Our evaluation of 14 open-source LMMs and the proprietary GPT-4V(ision) highlights the substantial challenges posed by MMMU. Even the advanced GPT-4V only achieves a 56% accuracy, indicating significant room for improvement. We believe MMMU will stimulate the community to build next-generation multimodal foundation models towards expert artificial general intelligence.
Deconfounding Actor-Critic Network with Policy Adaptation for Dynamic Treatment Regimes
May 31, 2022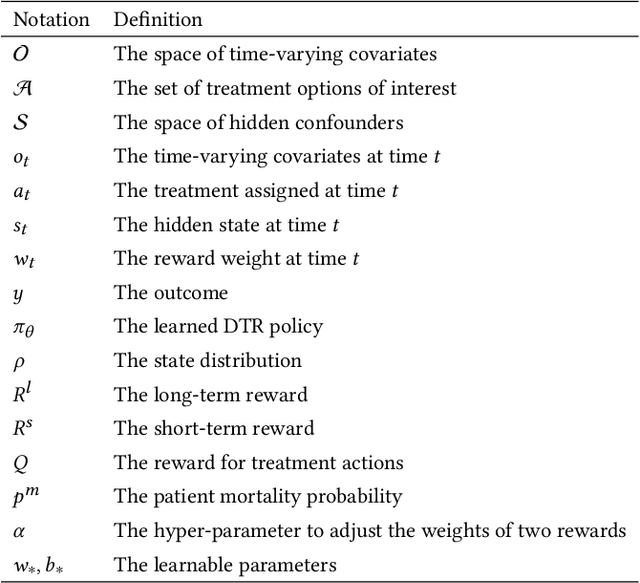
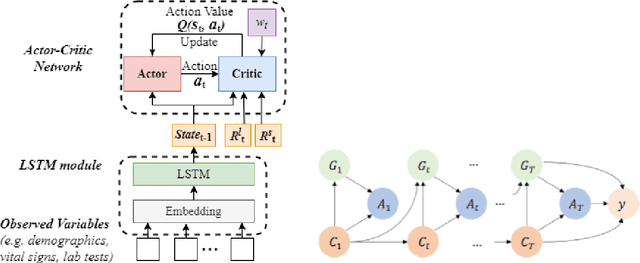
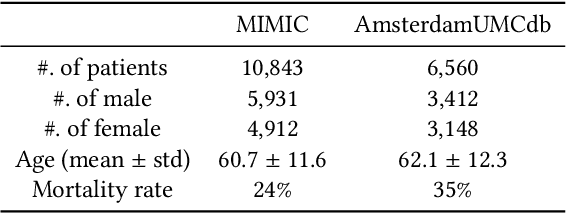

Despite intense efforts in basic and clinical research, an individualized ventilation strategy for critically ill patients remains a major challenge. Recently, dynamic treatment regime (DTR) with reinforcement learning (RL) on electronic health records (EHR) has attracted interest from both the healthcare industry and machine learning research community. However, most learned DTR policies might be biased due to the existence of confounders. Although some treatment actions non-survivors received may be helpful, if confounders cause the mortality, the training of RL models guided by long-term outcomes (e.g., 90-day mortality) would punish those treatment actions causing the learned DTR policies to be suboptimal. In this study, we develop a new deconfounding actor-critic network (DAC) to learn optimal DTR policies for patients. To alleviate confounding issues, we incorporate a patient resampling module and a confounding balance module into our actor-critic framework. To avoid punishing the effective treatment actions non-survivors received, we design a short-term reward to capture patients' immediate health state changes. Combining short-term with long-term rewards could further improve the model performance. Moreover, we introduce a policy adaptation method to successfully transfer the learned model to new-source small-scale datasets. The experimental results on one semi-synthetic and two different real-world datasets show the proposed model outperforms the state-of-the-art models. The proposed model provides individualized treatment decisions for mechanical ventilation that could improve patient outcomes.