 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Joint Language-Audio Embeddings Encode Perceptual Timbre Semantics?
Oct 16, 2025Understanding and modeling the relationship between language and sound is critical for applications such as music information retrieval,text-guided music generation, and audio captioning. Central to these tasks is the use of joint language-audio embedding spaces, which map textual descriptions and auditory content into a shared embedding space. While multimodal embedding models such as MS-CLAP, LAION-CLAP, and MuQ-MuLan have shown strong performance in aligning language and audio, their correspondence to human perception of timbre, a multifaceted attribute encompassing qualities such as brightness, roughness, and warmth, remains underexplored. In this paper, we evaluate the above three joint language-audio embedding models on their ability to capture perceptual dimensions of timbre. Our findings show that LAION-CLAP consistently provides the most reliable alignment with human-perceived timbre semantics across both instrumental sounds and audio effects.
The Rhythm In Anything: Audio-Prompted Drums Generation with Masked Language Modeling
Sep 19, 2025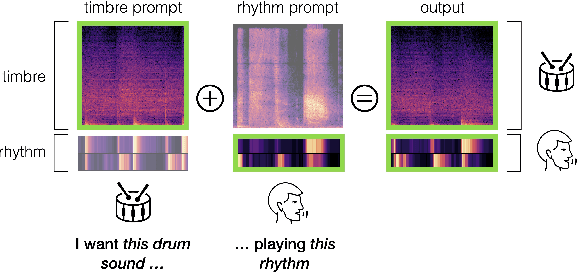
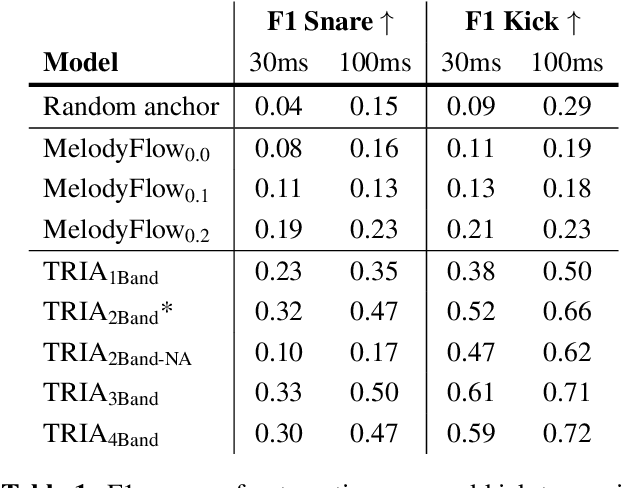
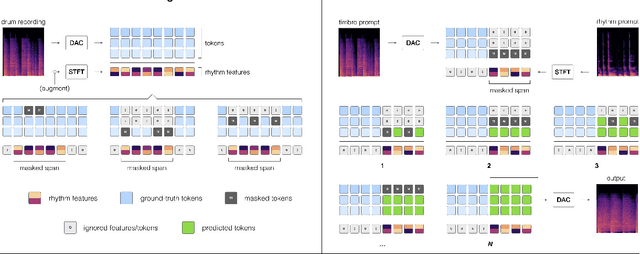
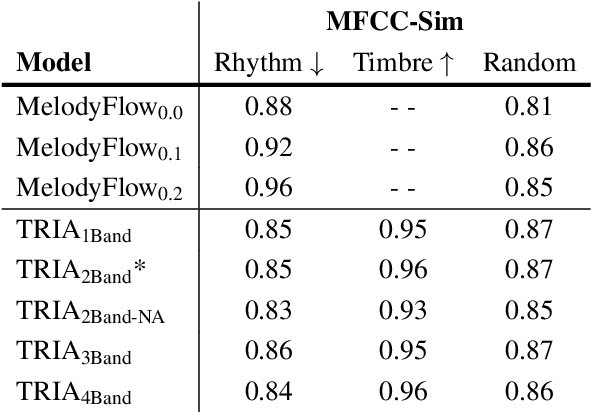
Musicians and nonmusicians alike use rhythmic sound gestures, such as tapping and beatboxing, to express drum patterns. While these gestures effectively communicate musical ideas, realizing these ideas as fully-produced drum recordings can be time-consuming, potentially disrupting many creative workflows. To bridge this gap, we present TRIA (The Rhythm In Anything), a masked transformer model for mapping rhythmic sound gestures to high-fidelity drum recordings. Given an audio prompt of the desired rhythmic pattern and a second prompt to represent drumkit timbre, TRIA produces audio of a drumkit playing the desired rhythm (with appropriate elaborations) in the desired timbre. Subjective and objective evaluations show that a TRIA model trained on less than 10 hours of publicly-available drum data can generate high-quality, faithful realizations of sound gestures across a wide range of timbres in a zero-shot manner.
Deep Audio Watermarks are Shallow: Limitations of Post-Hoc Watermarking Techniques for Speech
Apr 15, 2025In the audio modality, state-of-the-art watermarking methods leverage deep neural networks to allow the embedding of human-imperceptible signatures in generated audio. The ideal is to embed signatures that can be detected with high accuracy when the watermarked audio is altered via compression, filtering, or other transformations. Existing audio watermarking techniques operate in a post-hoc manner, manipulating "low-level" features of audio recordings after generation (e.g. through the addition of a low-magnitude watermark signal). We show that this post-hoc formulation makes existing audio watermarks vulnerable to transformation-based removal attacks. Focusing on speech audio, we (1) unify and extend existing evaluations of the effect of audio transformations on watermark detectability, and (2) demonstrate that state-of-the-art post-hoc audio watermarks can be removed with no knowledge of the watermarking scheme and minimal degradation in audio quality.
HARP 2.0: Expanding Hosted, Asynchronous, Remote Processing for Deep Learning in the DAW
Mar 04, 2025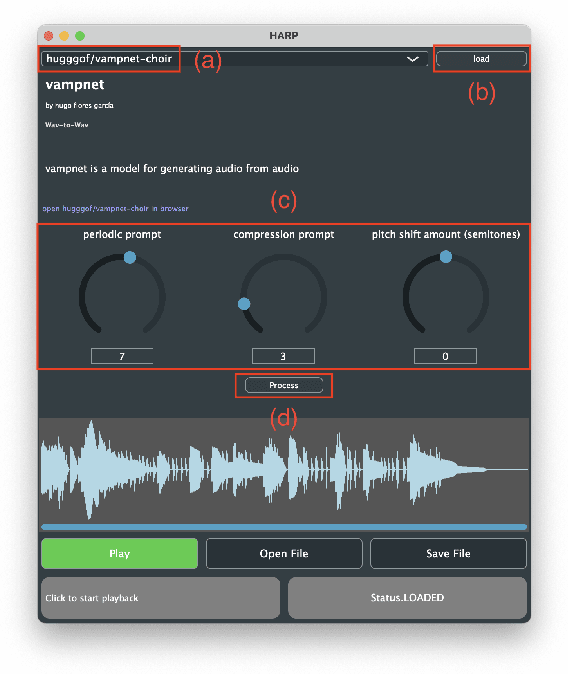
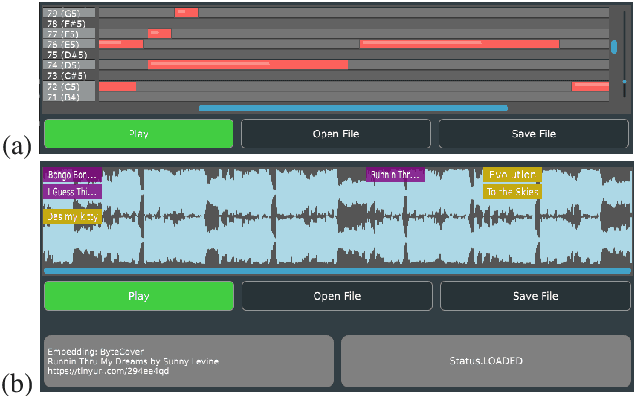
HARP 2.0 brings deep learning models to digital audio workstation (DAW) software through hosted, asynchronous, remote processing, allowing users to route audio from a plug-in interface through any compatible Gradio endpoint to perform arbitrary transformations. HARP renders endpoint-defined controls and processed audio in-plugin, meaning users can explore a variety of cutting-edge deep learning models without ever leaving the DAW. In the 2.0 release we introduce support for MIDI-based models and audio/MIDI labeling models, provide a streamlined pyharp Python API for model developers, and implement numerous interface and stability improvements. Through this work, we hope to bridge the gap between model developers and creatives, improving access to deep learning models by seamlessly integrating them into DAW workflows.
Sketch2Sound: Controllable Audio Generation via Time-Varying Signals and Sonic Imitations
Dec 11, 2024


We present Sketch2Sound, a generative audio model capable of creating high-quality sounds from a set of interpretable time-varying control signals: loudness, brightness, and pitch, as well as text prompts. Sketch2Sound can synthesize arbitrary sounds from sonic imitations (i.e.,~a vocal imitation or a reference sound-shape). Sketch2Sound can be implemented on top of any text-to-audio latent diffusion transformer (DiT), and requires only 40k steps of fine-tuning and a single linear layer per control, making it more lightweight than existing methods like ControlNet. To synthesize from sketchlike sonic imitations, we propose applying random median filters to the control signals during training, allowing Sketch2Sound to be prompted using controls with flexible levels of temporal specificity. We show that Sketch2Sound can synthesize sounds that follow the gist of input controls from a vocal imitation while retaining the adherence to an input text prompt and audio quality compared to a text-only baseline. Sketch2Sound allows sound artists to create sounds with the semantic flexibility of text prompts and the expressivity and precision of a sonic gesture or vocal imitation. Sound examples are available at https://hugofloresgarcia.art/sketch2sound/.
Code Drift: Towards Idempotent Neural Audio Codecs
Oct 14, 2024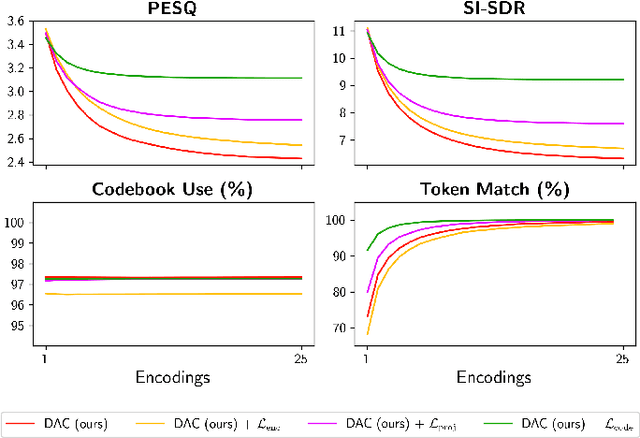
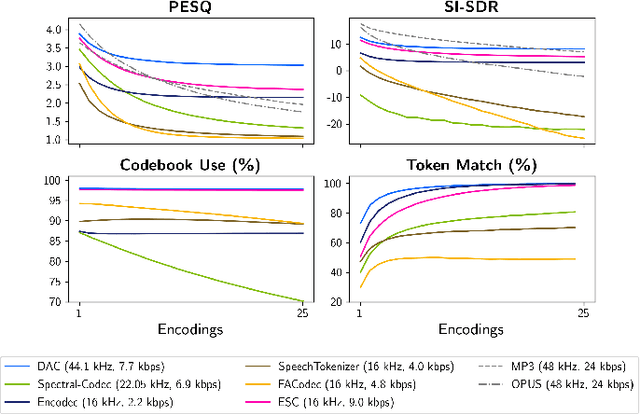
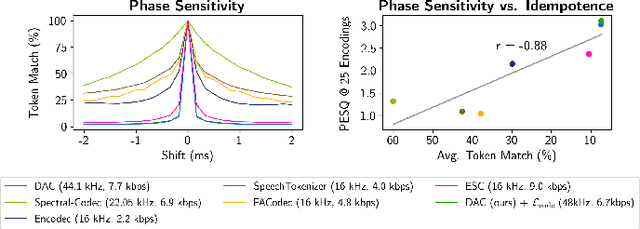
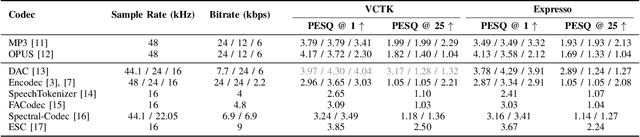
Neural codecs have demonstrated strong performance in high-fidelity compression of audio signals at low bitrates. The token-based representations produced by these codecs have proven particularly useful for generative modeling. While much research has focused on improvements in compression ratio and perceptual transparency, recent works have largely overlooked another desirable codec property -- idempotence, the stability of compressed outputs under multiple rounds of encoding. We find that state-of-the-art neural codecs exhibit varied degrees of idempotence, with some degrading audio outputs significantly after as few as three encodings. We investigate possible causes of low idempotence and devise a method for improving idempotence through fine-tuning a codec model. We then examine the effect of idempotence on a simple conditional generative modeling task, and find that increased idempotence can be achieved without negatively impacting downstream modeling performance -- potentially extending the usefulness of neural codecs for practical file compression and iterative generative modeling workflows.
Text2FX: Harnessing CLAP Embeddings for Text-Guided Audio Effects
Sep 27, 2024



This work introduces Text2FX, a method that leverages CLAP embeddings and differentiable digital signal processing to control audio effects, such as equalization and reverberation, using open-vocabulary natural language prompts (e.g., "make this sound in-your-face and bold"). Text2FX operates without retraining any models, relying instead on single-instance optimization within the existing embedding space. We show that CLAP encodes valuable information for controlling audio effects and propose two optimization approaches using CLAP to map text to audio effect parameters. While we demonstrate with CLAP, this approach is applicable to any shared text-audio embedding space. Similarly, while we demonstrate with equalization and reverberation, any differentiable audio effect may be controlled. We conduct a listener study with diverse text prompts and source audio to evaluate the quality and alignment of these methods with human perception.
Fine-Grained and Interpretable Neural Speech Editing
Jul 07, 2024

Fine-grained editing of speech attributes$\unicode{x2014}$such as prosody (i.e., the pitch, loudness, and phoneme durations), pronunciation, speaker identity, and formants$\unicode{x2014}$is useful for fine-tuning and fixing imperfections in human and AI-generated speech recordings for creation of podcasts, film dialogue, and video game dialogue. Existing speech synthesis systems use representations that entangle two or more of these attributes, prohibiting their use in fine-grained, disentangled editing. In this paper, we demonstrate the first disentangled and interpretable representation of speech with comparable subjective and objective vocoding reconstruction accuracy to Mel spectrograms. Our interpretable representation, combined with our proposed data augmentation method, enables training an existing neural vocoder to perform fast, accurate, and high-quality editing of pitch, duration, volume, timbral correlates of volume, pronunciation, speaker identity, and spectral balance.
High-Fidelity Neural Phonetic Posteriorgrams
Feb 27, 2024



A phonetic posteriorgram (PPG) is a time-varying categorical distribution over acoustic units of speech (e.g., phonemes). PPGs are a popular representation in speech generation due to their ability to disentangle pronunciation features from speaker identity, allowing accurate reconstruction of pronunciation (e.g., voice conversion) and coarse-grained pronunciation editing (e.g., foreign accent conversion). In this paper, we demonstrably improve the quality of PPGs to produce a state-of-the-art interpretable PPG representation. We train an off-the-shelf speech synthesizer using our PPG representation and show that high-quality PPGs yield independent control over pitch and pronunciation. We further demonstrate novel uses of PPGs, such as an acoustic pronunciation distance and fine-grained pronunciation control.
Exploring Musical Roots: Applying Audio Embeddings to Empower Influence Attribution for a Generative Music Model
Jan 25, 2024



Every artist has a creative process that draws inspiration from previous artists and their works. Today, "inspiration" has been automated by generative music models. The black box nature of these models obscures the identity of the works that influence their creative output. As a result, users may inadvertently appropriate, misuse, or copy existing artists' works. We establish a replicable methodology to systematically identify similar pieces of music audio in a manner that is useful for understanding training data attribution. A key aspect of our approach is to harness an effective music audio similarity measure. We compare the effect of applying CLMR and CLAP embeddings to similarity measurement in a set of 5 million audio clips used to train VampNet, a recent open source generative music model. We validate this approach with a human listening study. We also explore the effect that modifications of an audio example (e.g., pitch shifting, time stretching, background noise) have on similarity measurements. This work is foundational to incorporating automated influence attribution into generative modeling, which promises to let model creators and users move from ignorant appropriation to informed creation. Audio samples that accompany this paper are available at https://tinyurl.com/exploring-musical-roots.