 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptSep: Generative Audio Separation via Multimodal Prompting
Nov 06, 2025Recent breakthroughs in language-queried audio source separation (LASS) have shown that generative models can achieve higher separation audio quality than traditional masking-based approaches. However, two key limitations restrict their practical use: (1) users often require operations beyond separation, such as sound removal; and (2) relying solely on text prompts can be unintuitive for specifying sound sources. In this paper, we propose PromptSep to extend LASS into a broader framework for general-purpose sound separation. PromptSep leverages a conditional diffusion model enhanced with elaborated data simulation to enable both audio extraction and sound removal. To move beyond text-only queries, we incorporate vocal imitation as an additional and more intuitive conditioning modality for our model, by incorporating Sketch2Sound as a data augmentation strategy. Both objective and subjective evaluations on multiple benchmarks demonstrate that PromptSep achieves state-of-the-art performance in sound removal and vocal-imitation-guided source separation, while maintaining competitive results on language-queried source separation.
DiTSE: High-Fidelity Generative Speech Enhancement via Latent Diffusion Transformers
Apr 13, 2025Real-world speech recordings suffer from degradations such as background noise and reverberation. Speech enhancement aims to mitigate these issues by generating clean high-fidelity signals. While recent generative approaches for speech enhancement have shown promising results, they still face two major challenges: (1) content hallucination, where plausible phonemes generated differ from the original utterance; and (2) inconsistency, failing to preserve speaker's identity and paralinguistic features from the input speech. In this work, we introduce DiTSE (Diffusion Transformer for Speech Enhancement), which addresses quality issues of degraded speech in full bandwidth. Our approach employs a latent diffusion transformer model together with robust conditioning features, effectively addressing these challenges while remaining computationally efficient. Experimental results from both subjective and objective evaluations demonstrate that DiTSE achieves state-of-the-art audio quality that, for the first time, matches real studio-quality audio from the DAPS dataset. Furthermore, DiTSE significantly improves the preservation of speaker identity and content fidelity, reducing hallucinations across datasets compared to state-of-the-art enhancers. Audio samples are available at: http://hguimaraes.me/DiTSE
SpeakEasy: Enhancing Text-to-Speech Interactions for Expressive Content Creation
Apr 07, 2025



Novice content creators often invest significant time recording expressive speech for social media videos. While recent advancements in text-to-speech (TTS) technology can generate highly realistic speech in various languages and accents, many struggle with unintuitive or overly granular TTS interfaces. We propose simplifying TTS generation by allowing users to specify high-level context alongside their script. Our Wizard-of-Oz system, SpeakEasy, leverages user-provided context to inform and influence TTS output, enabling iterative refinement with high-level feedback. This approach was informed by two 8-subject formative studies: one examining content creators' experiences with TTS, and the other drawing on effective strategies from voice actors. Our evaluation shows that participants using SpeakEasy were more successful in generating performances matching their personal standards, without requiring significantly more effort than leading industry interfaces.
DMDSpeech: Distilled Diffusion Model Surpassing The Teacher in Zero-shot Speech Synthesis via Direct Metric Optimization
Oct 14, 2024



Diffusion models have demonstrated significant potential in speech synthesis tasks, including text-to-speech (TTS) and voice cloning. However, their iterative denoising processes are inefficient and hinder the application of end-to-end optimization with perceptual metrics. In this paper, we propose a novel method of distilling TTS diffusion models with direct end-to-end evaluation metric optimization, achieving state-of-the-art performance. By incorporating Connectionist Temporal Classification (CTC) loss and Speaker Verification (SV) loss, our approach optimizes perceptual evaluation metrics, leading to notable improvements in word error rate and speaker similarity. Our experiments show that DMDSpeech consistently surpasses prior state-of-the-art models in both naturalness and speaker similarity while being significantly faster. Moreover, our synthetic speech has a higher level of voice similarity to the prompt than the ground truth in both human evaluation and objective speaker similarity metric. This work highlights the potential of direct metric optimization in speech synthesis, allowing models to better align with human auditory preferences. The audio samples are available at https://dmdspeech.github.io/.
VampNet: Music Generation via Masked Acoustic Token Modeling
Jul 12, 2023



We introduce VampNet, a masked acoustic token modeling approach to music synthesis, compression, inpainting, and variation. We use a variable masking schedule during training which allows us to sample coherent music from the model by applying a variety of masking approaches (called prompts) during inference. VampNet is non-autoregressive, leveraging a bidirectional transformer architecture that attends to all tokens in a forward pass. With just 36 sampling passes, VampNet can generate coherent high-fidelity musical waveforms. We show that by prompting VampNet in various ways, we can apply it to tasks like music compression, inpainting, outpainting, continuation, and looping with variation (vamping). Appropriately prompted, VampNet is capable of maintaining style, genre, instrumentation, and other high-level aspects of the music. This flexible prompting capability makes VampNet a powerful music co-creation tool. Code and audio samples are available online.
High-Fidelity Audio Compression with Improved RVQGAN
Jun 11, 2023



Language models have been successfully used to model natural signals, such as images, speech, and music. A key component of these models is a high quality neural compression model that can compress high-dimensional natural signals into lower dimensional discrete tokens. To that end, we introduce a high-fidelity universal neural audio compression algorithm that achieves ~90x compression of 44.1 KHz audio into tokens at just 8kbps bandwidth. We achieve this by combining advances in high-fidelity audio generation with better vector quantization techniques from the image domain, along with improved adversarial and reconstruction losses. We compress all domains (speech, environment, music, etc.) with a single universal model, making it widely applicable to generative modeling of all audio. We compare with competing audio compression algorithms, and find our method outperforms them significantly. We provide thorough ablations for every design choice, as well as open-source code and trained model weights. We hope our work can lay the foundation for the next generation of high-fidelity audio modeling.
Chunked Autoregressive GAN for Conditional Waveform Synthesis
Oct 19, 2021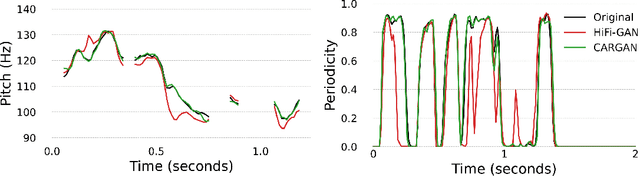

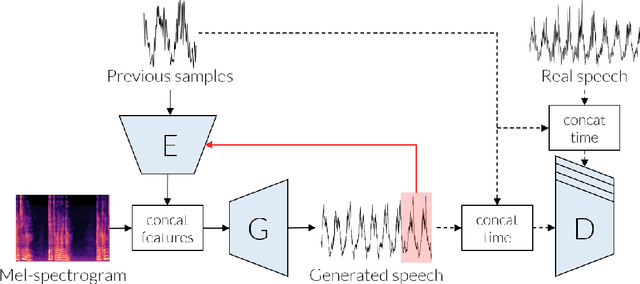
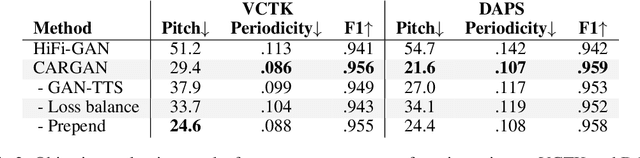
Conditional waveform synthesis models learn a distribution of audio waveforms given conditioning such as text, mel-spectrograms, or MIDI. These systems employ deep generative models that model the waveform via either sequential (autoregressive) or parallel (non-autoregressive) sampling. Generative adversarial networks (GANs) have become a common choice for non-autoregressive waveform synthesis. However, state-of-the-art GAN-based models produce artifacts when performing mel-spectrogram inversion. In this paper, we demonstrate that these artifacts correspond with an inability for the generator to learn accurate pitch and periodicity. We show that simple pitch and periodicity conditioning is insufficient for reducing this error relative to using autoregression. We discuss the inductive bias that autoregression provides for learning the relationship between instantaneous frequency and phase, and show that this inductive bias holds even when autoregressively sampling large chunks of the waveform during each forward pass. Relative to prior state-of- the-art GAN-based models, our proposed model, Chunked Autoregressive GAN (CARGAN) reduces pitch error by 40-60%, reduces training time by 58%, maintains a fast generation speed suitable for real-time or interactive applications, and maintains or improves subjective quality.
NU-GAN: High resolution neural upsampling with GAN
Oct 22, 2020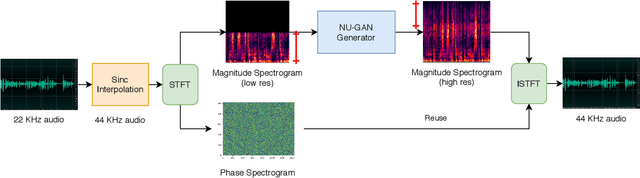
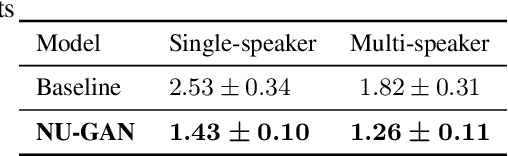
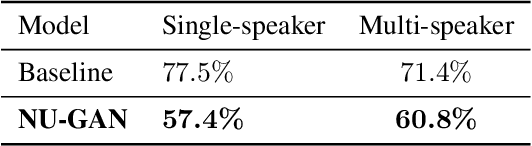
In this paper, we propose NU-GAN, a new method for resampling audio from lower to higher sampling rates (upsampling). Audio upsampling is an important problem since productionizing generative speech technology requires operating at high sampling rates. Such applications use audio at a resolution of 44.1 kHz or 48 kHz, whereas current speech synthesis methods are equipped to handle a maximum of 24 kHz resolution. NU-GAN takes a leap towards solving audio upsampling as a separate component in the text-to-speech (TTS) pipeline by leveraging techniques for audio generation using GANs. ABX preference tests indicate that our NU-GAN resampler is capable of resampling 22 kHz to 44.1 kHz audio that is distinguishable from original audio only 7.4% higher than random chance for single speaker dataset, and 10.8% higher than chance for multi-speaker dataset.
MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
Oct 28, 2019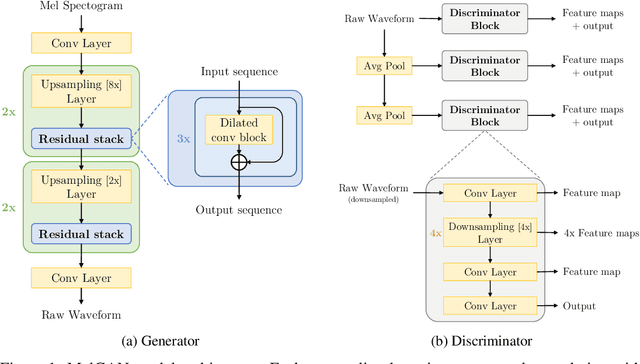


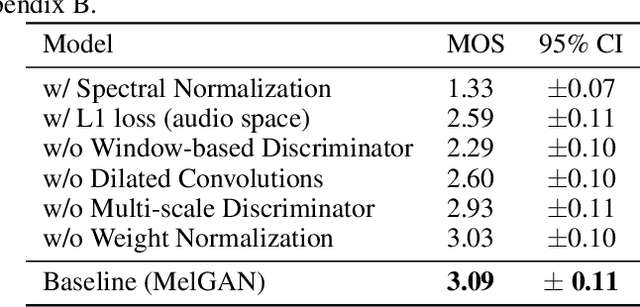
Previous works (Donahue et al., 2018a; Engel et al., 2019a) have found that generating coherent raw audio waveforms with GANs is challenging. In this paper, we show that it is possible to train GANs reliably to generate high quality coherent waveforms by introducing a set of architectural changes and simple training techniques. Subjective evaluation metric (Mean Opinion Score, or MOS) shows the effectiveness of the proposed approach for high quality mel-spectrogram inversion. To establish the generality of the proposed techniques, we show qualitative results of our model in speech synthesis, music domain translation and unconditional music synthesis. We evaluate the various components of the model through ablation studies and suggest a set of guidelines to design general purpose discriminators and generators for conditional sequence synthesis tasks. Our model is non-autoregressive, fully convolutional, with significantly fewer parameters than competing models and generalizes to unseen speakers for mel-spectrogram inversion. Our pytorch implementation runs at more than 100x faster than realtime on GTX 1080Ti GPU and more than 2x faster than real-time on CPU, without any hardware specific optimization tricks.
Maximum Entropy Generators for Energy-Based Models
Jan 24, 2019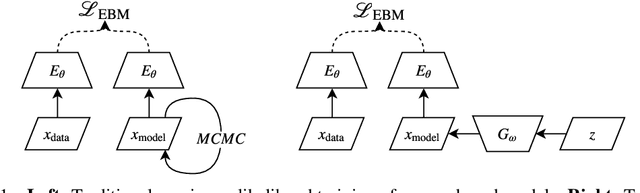
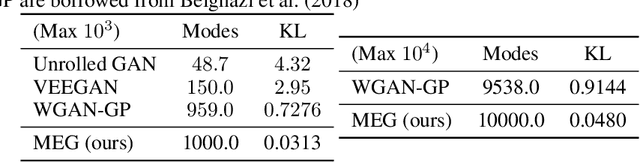
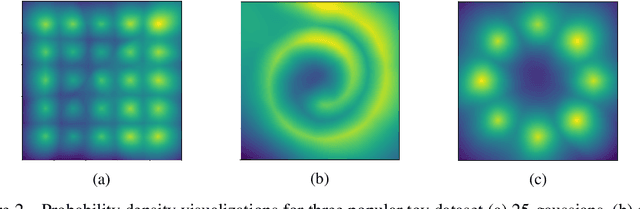
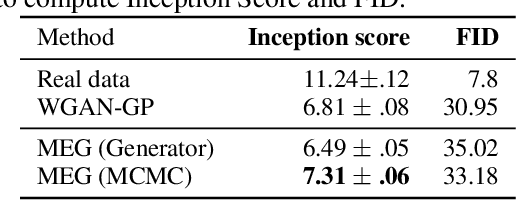
Unsupervised learning is about capturing dependencies between variables and is driven by the contrast between the probable vs. improbable configurations of these variables, often either via a generative model that only samples probable ones or with an energy function (unnormalized log-density) that is low for probable ones and high for improbable ones. Here, we consider learning both an energy function and an efficient approximate sampling mechanism. Whereas the discriminator in generative adversarial networks (GANs) learns to separate data and generator samples, introducing an entropy maximization regularizer on the generator can turn the interpretation of the critic into an energy function, which separates the training distribution from everything else, and thus can be used for tasks like anomaly or novelty detection. Then, we show how Markov Chain Monte Carlo can be done in the generator latent space whose samples can be mapped to data space, producing better samples. These samples are used for the negative phase gradient required to estimate the log-likelihood gradient of the data space energy function. To maximize entropy at the output of the generator, we take advantage of recently introduced neural estimators of mutual information. We find that in addition to producing a useful scoring function for anomaly detection, the resulting approach produces sharp samples while covering the modes well, leading to high Inception and Frechet scores.