 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generalizable Memory-driven Transformer for Multivariate Long Sequence Time-series Forecasting
Jul 16, 2022
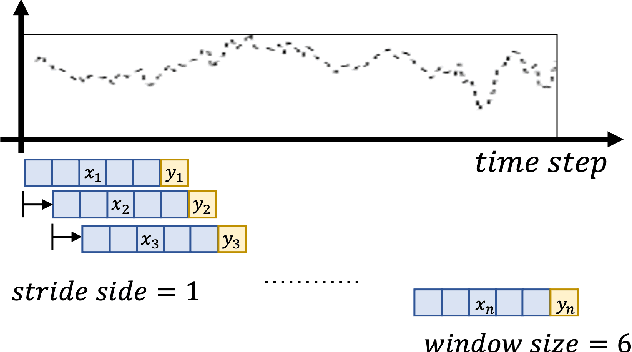
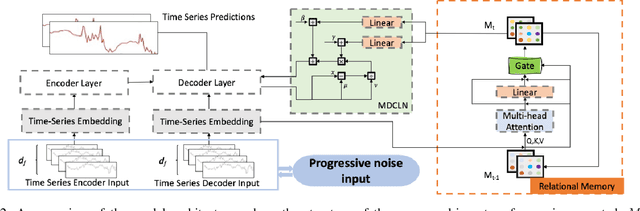
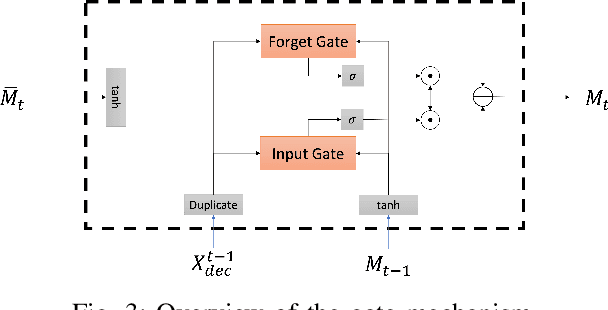
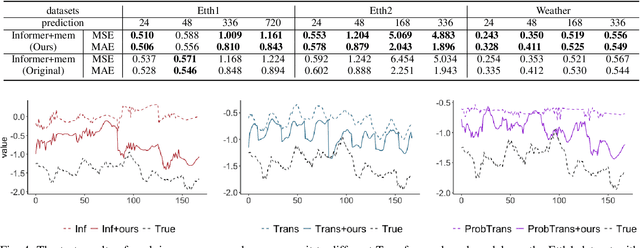
Multivariate long sequence time-series forecasting (M-LSTF) is a practical but challenging problem. Unlike traditional timer-series forecasting tasks, M-LSTF tasks are more challenging from two aspects: 1) M-LSTF models need to learn time-series patterns both within and between multiple time features; 2) Under the rolling forecasting setting, the similarity between two consecutive training samples increases with the increasing prediction length, which makes models more prone to overfitting. In this paper, we propose a generalizable memory-driven Transformer to target M-LSTF problems. Specifically, we first propose a global-level memory component to drive the forecasting procedure by integrating multiple time-series features. In addition, we adopt a progressive fashion to train our model to increase its generalizability, in which we gradually introduce Bernoulli noises to training samples. Extensive experiments have been performed on five different datasets across multiple fields. Experimental results demonstrate that our approach can be seamlessly plugged into varying Transformer-based models to improve their performances up to roughly 30%. Particularly, this is the first work to specifically focus on the M-LSTF tasks to the best of our knowledge.
ADAPT: Action-aware Driving Caption Transformer
Feb 01, 2023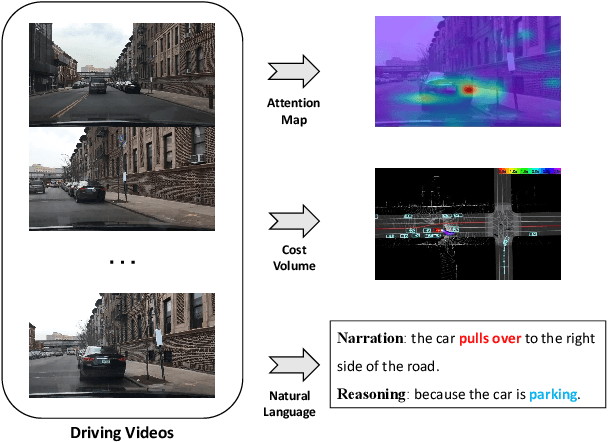
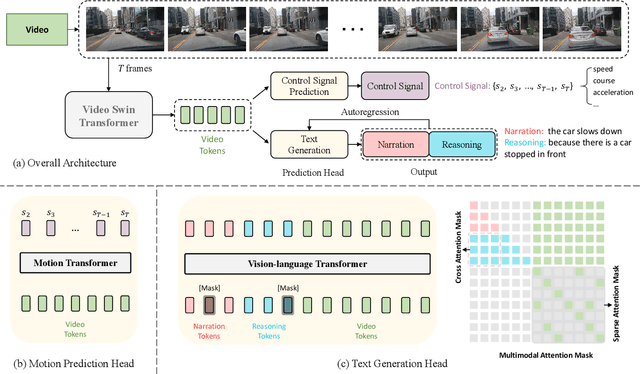
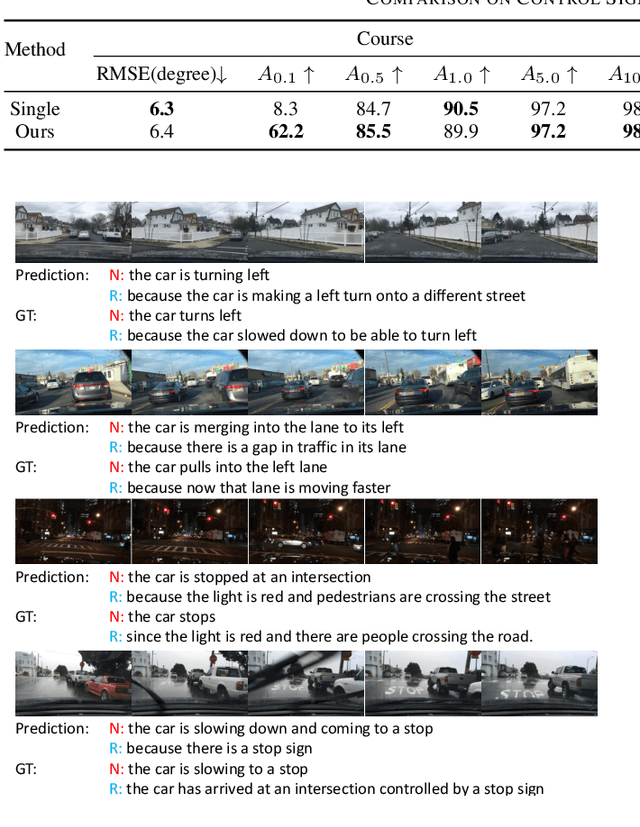
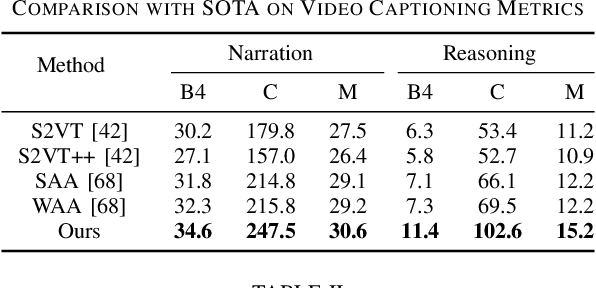
End-to-end autonomous driving has great potential in the transportation industry. However, the lack of transparency and interpretability of the automatic decision-making process hinders its industrial adoption in practice. There have been some early attempts to use attention maps or cost volume for better model explainability which is difficult for ordinary passengers to understand. To bridge the gap, we propose an end-to-end transformer-based architecture, ADAPT (Action-aware Driving cAPtion Transformer), which provides user-friendly natural language narrations and reasoning for each decision making step of autonomous vehicular control and action. ADAPT jointly trains both the driving caption task and the vehicular control prediction task, through a shared video representation. Experiments on BDD-X (Berkeley DeepDrive eXplanation) dataset demonstrate state-of-the-art performance of the ADAPT framework on both automatic metrics and human evaluation. To illustrate the feasibility of the proposed framework in real-world applications, we build a novel deployable system that takes raw car videos as input and outputs the action narrations and reasoning in real time. The code, models and data are available at https://github.com/jxbbb/ADAPT.
Learning, Fast and Slow: A Goal-Directed Memory-Based Approach for Dynamic Environments
Feb 01, 2023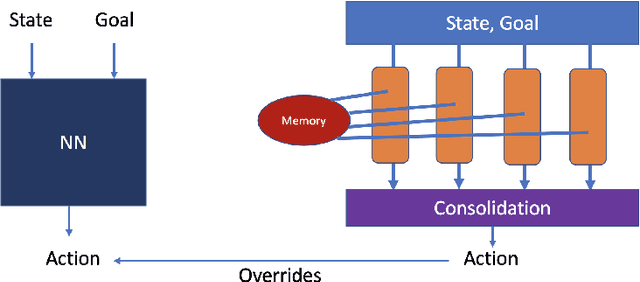
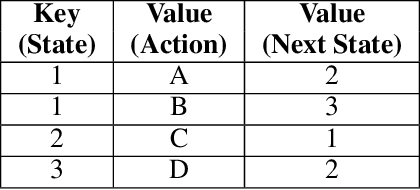
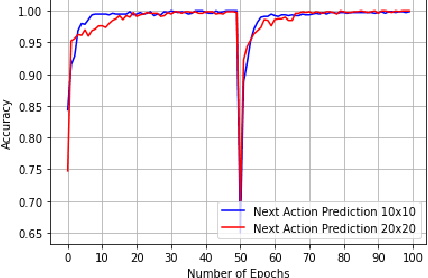
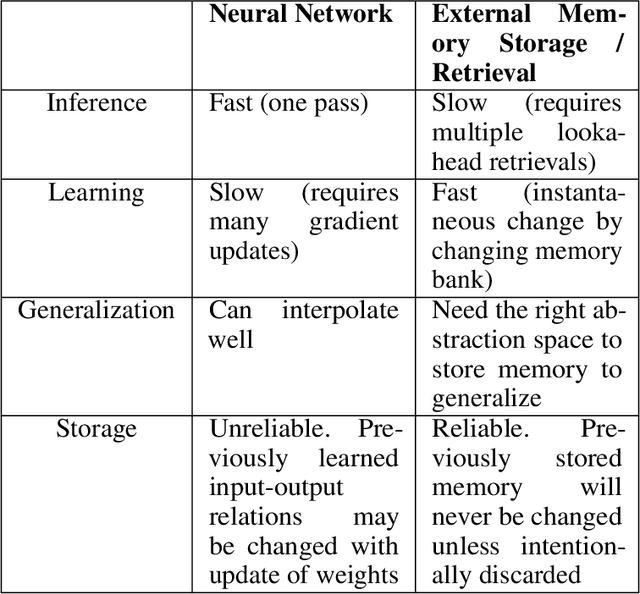
Model-based next state prediction and state value prediction are slow to converge. To address these challenges, we do the following: i) Instead of a neural network, we do model-based planning using a parallel memory retrieval system (which we term the slow mechanism); ii) Instead of learning state values, we guide the agent's actions using goal-directed exploration, by using a neural network to choose the next action given the current state and the goal state (which we term the fast mechanism). The goal-directed exploration is trained online using hippocampal replay of visited states and future imagined states every single time step, leading to fast and efficient training. Empirical studies show that our proposed method has a 92% solve rate across 100 episodes in a dynamically changing grid world, significantly outperforming state-of-the-art actor critic mechanisms such as PPO (54%), TRPO (50%) and A2C (24%). Ablation studies demonstrate that both mechanisms are crucial. We posit that the future of Reinforcement Learning (RL) will be to model goals and sub-goals for various tasks, and plan it out in a goal-directed memory-based approach.
Federated Survival Forests
Feb 06, 2023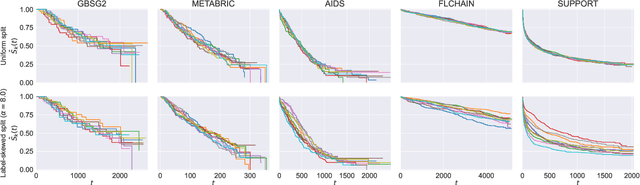
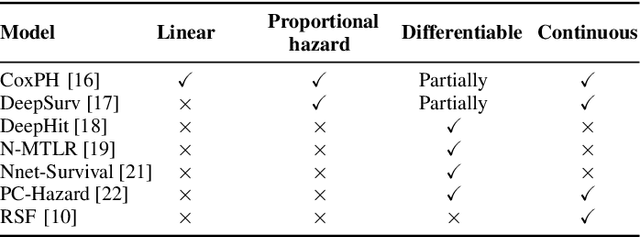
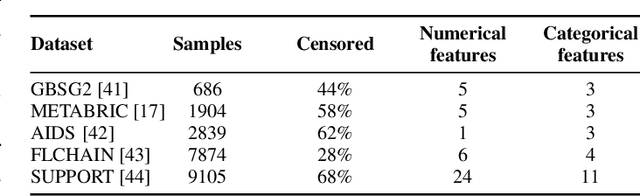
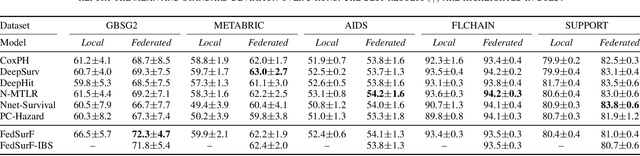
Survival analysis is a subfield of statistics concerned with modeling the occurrence time of a particular event of interest for a population. Survival analysis found widespread applications in healthcare, engineering, and social sciences. However, real-world applications involve survival datasets that are distributed, incomplete, censored, and confidential. In this context, federated learning can tremendously improve the performance of survival analysis applications. Federated learning provides a set of privacy-preserving techniques to jointly train machine learning models on multiple datasets without compromising user privacy, leading to a better generalization performance. Despite the widespread development of federated learning in recent AI research, only a few studies focus on federated survival analysis. In this work, we present a novel federated algorithm for survival analysis based on one of the most successful survival models, the random survival forest. We call the proposed method Federated Survival Forest (FedSurF). With a single communication round, FedSurF obtains a discriminative power comparable to deep-learning-based federated models trained over hundreds of federated iterations. Moreover, FedSurF retains all the advantages of random forests, namely low computational cost and natural handling of missing values and incomplete datasets. These advantages are especially desirable in real-world federated environments with multiple small datasets stored on devices with low computational capabilities. Numerical experiments compare FedSurF with state-of-the-art survival models in federated networks, showing how FedSurF outperforms deep-learning-based federated algorithms in realistic environments with non-identically distributed data.
Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models
Jan 30, 2023
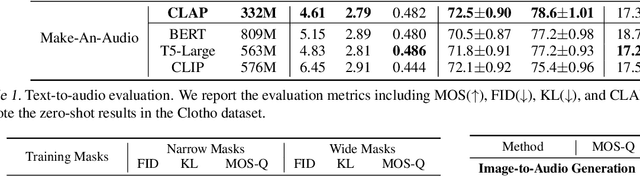
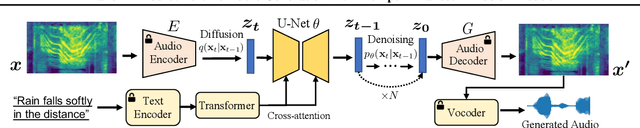
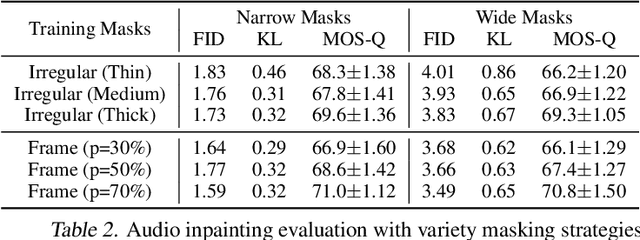
Large-scale multimodal generative modeling has created milestones in text-to-image and text-to-video generation. Its application to audio still lags behind for two main reasons: the lack of large-scale datasets with high-quality text-audio pairs, and the complexity of modeling long continuous audio data. In this work, we propose Make-An-Audio with a prompt-enhanced diffusion model that addresses these gaps by 1) introducing pseudo prompt enhancement with a distill-then-reprogram approach, it alleviates data scarcity with orders of magnitude concept compositions by using language-free audios; 2) leveraging spectrogram autoencoder to predict the self-supervised audio representation instead of waveforms. Together with robust contrastive language-audio pretraining (CLAP) representations, Make-An-Audio achieves state-of-the-art results in both objective and subjective benchmark evaluation. Moreover, we present its controllability and generalization for X-to-Audio with "No Modality Left Behind", for the first time unlocking the ability to generate high-definition, high-fidelity audios given a user-defined modality input. Audio samples are available at https://Text-to-Audio.github.io
MILO: Model-Agnostic Subset Selection Framework for Efficient Model Training and Tuning
Jan 30, 2023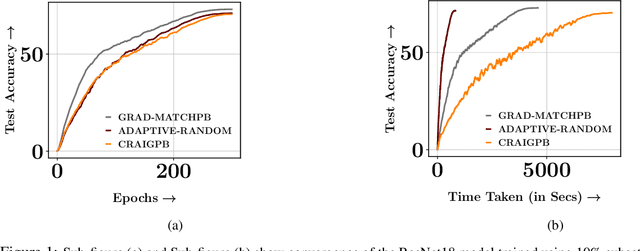
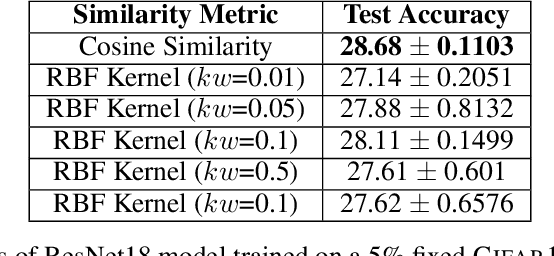
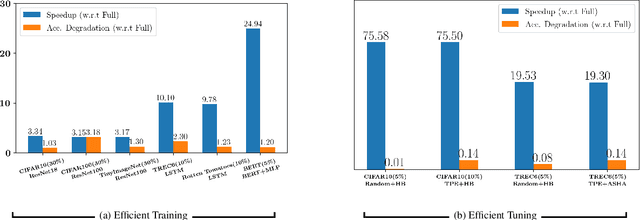
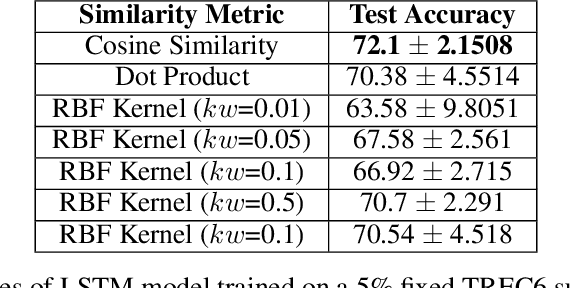
Training deep networks and tuning hyperparameters on large datasets is computationally intensive. One of the primary research directions for efficient training is to reduce training costs by selecting well-generalizable subsets of training data. Compared to simple adaptive random subset selection baselines, existing intelligent subset selection approaches are not competitive due to the time-consuming subset selection step, which involves computing model-dependent gradients and feature embeddings and applies greedy maximization of submodular objectives. Our key insight is that removing the reliance on downstream model parameters enables subset selection as a pre-processing step and enables one to train multiple models at no additional cost. In this work, we propose MILO, a model-agnostic subset selection framework that decouples the subset selection from model training while enabling superior model convergence and performance by using an easy-to-hard curriculum. Our empirical results indicate that MILO can train models $3\times - 10 \times$ faster and tune hyperparameters $20\times - 75 \times$ faster than full-dataset training or tuning without compromising performance.
Two Different Experiments with the Rope-Attached Sphere by Using Arduino
Jan 30, 2023Arduino microcontrollers are electronic devices that can be used in physics experiments, and they are both affordable and readily available in comparison to other experimental sets. Students in high school and college can acquire valuable skills through the usage of Arduino in STEM education applications. In this study, two different physics experiments were conducted with a single, easy to develop, experimental setup by using Arduino, a force sensor and a rope-attached metallic sphere. First experiment, involved several analyses such as period, rope tension, and energy conservation during simple harmonic motion. In the second experiment, the metal ball was released from the rope's connecting point, and the impulse acting on it between the times it was released and when it returned to equilibrium was measured. Analyzes performed are in very precise force and time intervals and the results of all analyzes are consistent with the theoretical values. Educational activities in this direction can both create maximum gains for students in STEM fields in limited education periods and contribute to equality of opportunity in education due to its economic nature.
Online Loss Function Learning
Jan 30, 2023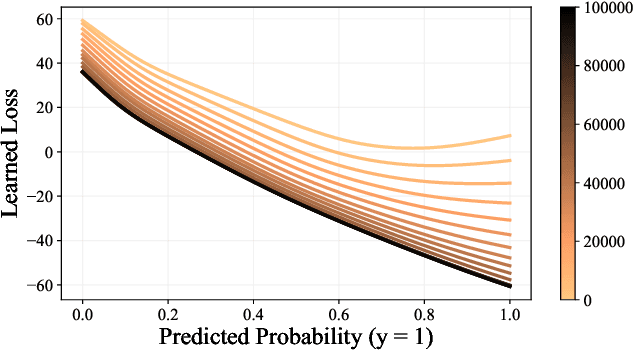
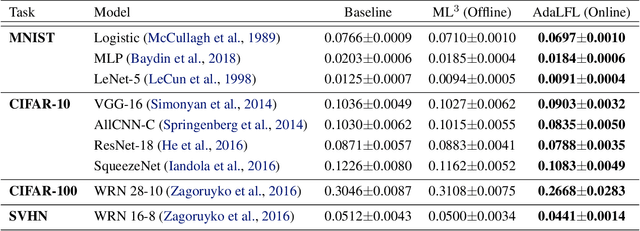
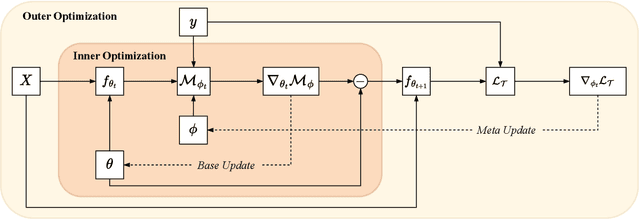

Loss function learning is a new meta-learning paradigm that aims to automate the essential task of designing a loss function for a machine learning model. Existing techniques for loss function learning have shown promising results, often improving a model's training dynamics and final inference performance. However, a significant limitation of these techniques is that the loss functions are meta-learned in an offline fashion, where the meta-objective only considers the very first few steps of training, which is a significantly shorter time horizon than the one typically used for training deep neural networks. This causes significant bias towards loss functions that perform well at the very start of training but perform poorly at the end of training. To address this issue we propose a new loss function learning technique for adaptively updating the loss function online after each update to the base model parameters. The experimental results show that our proposed method consistently outperforms the cross-entropy loss and offline loss function learning techniques on a diverse range of neural network architectures and datasets.
Data-driven soiling detection in PV modules
Jan 30, 2023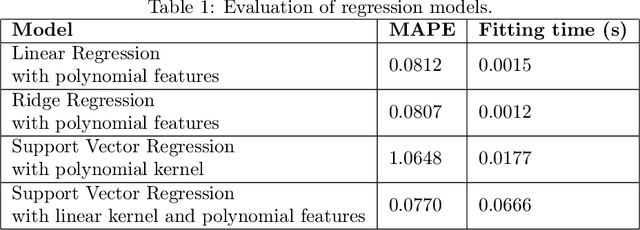
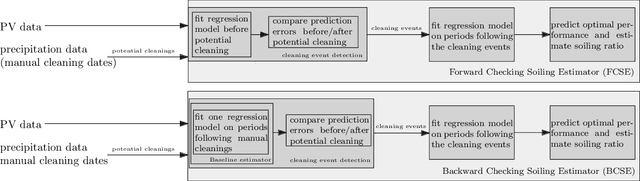
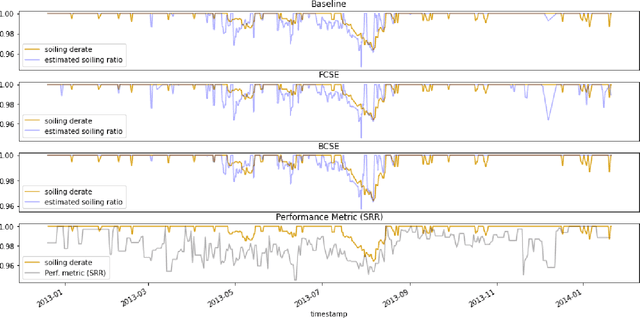
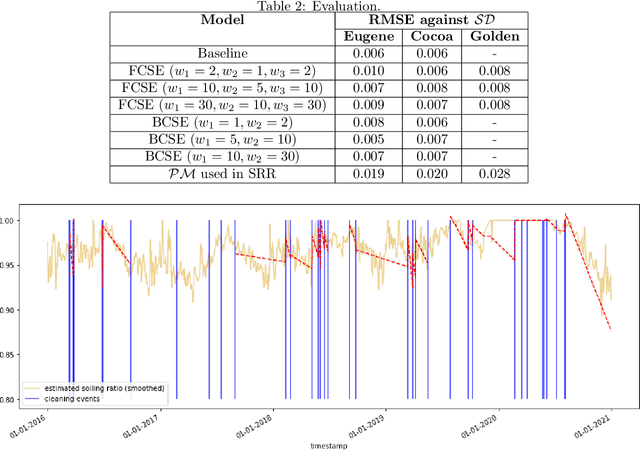
Soiling is the accumulation of dirt in solar panels which leads to a decreasing trend in solar energy yield and may be the cause of vast revenue losses. The effect of soiling can be reduced by washing the panels, which is, however, a procedure of non-negligible cost. Moreover, soiling monitoring systems are often unreliable or very costly. We study the problem of estimating the soiling ratio in photo-voltaic (PV) modules, i.e., the ratio of the real power output to the power output that would be produced if solar panels were clean. A key advantage of our algorithms is that they estimate soiling, without needing to train on labelled data, i.e., periods of explicitly monitoring the soiling in each park, and without relying on generic analytical formulas which do not take into account the peculiarities of each installation. We consider as input a time series comprising a minimum set of measurements, that are available to most PV park operators. Our experimental evaluation shows that we significantly outperform current state-of-the-art methods for estimating soiling ratio.
Learning Control from Raw Position Measurements
Jan 30, 2023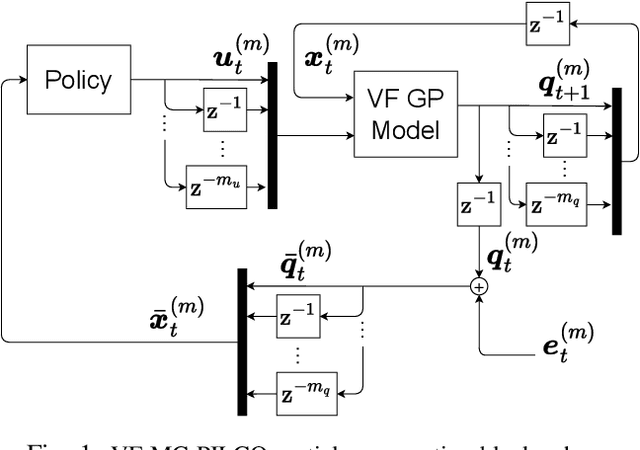
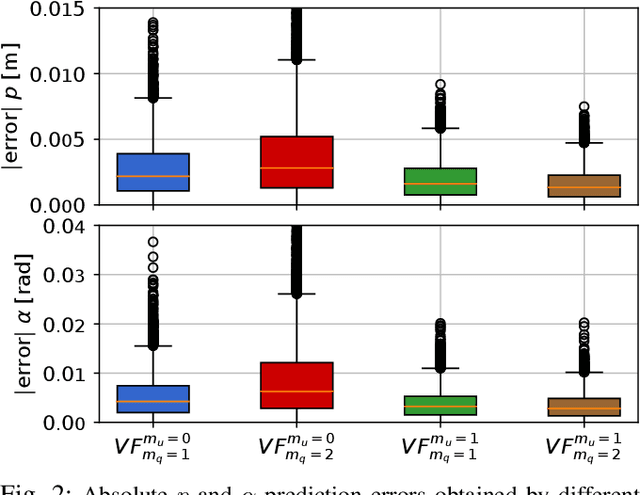
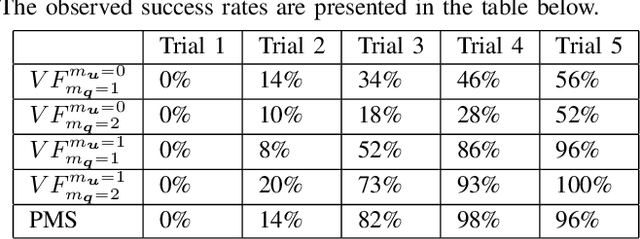
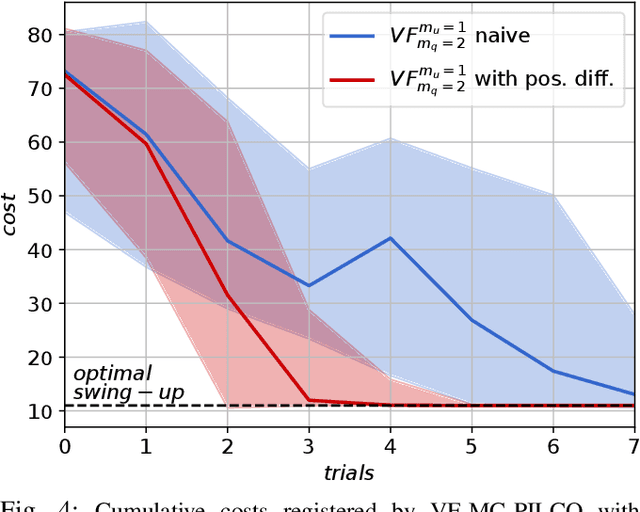
We propose a Model-Based Reinforcement Learning (MBRL) algorithm named VF-MC-PILCO, specifically designed for application to mechanical systems where velocities cannot be directly measured. This circumstance, if not adequately considered, can compromise the success of MBRL approaches. To cope with this problem, we define a velocity-free state formulation which consists of the collection of past positions and inputs. Then, VF-MC-PILCO uses Gaussian Process Regression to model the dynamics of the velocity-free state and optimizes the control policy through a particle-based policy gradient approach. We compare VF-MC-PILCO with our previous MBRL algorithm, MC-PILCO4PMS, which handles the lack of direct velocity measurements by modeling the presence of velocity estimators. Results on both simulated (cart-pole and UR5 robot) and real mechanical systems (Furuta pendulum and a ball-and-plate rig) show that the two algorithms achieve similar results. Conveniently, VF-MC-PILCO does not require the design and implementation of state estimators, which can be a challenging and time-consuming activity to be performed by an expert user.