 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On Reducing Undesirable Behavior in Deep Reinforcement Learning Models
Sep 11, 2023
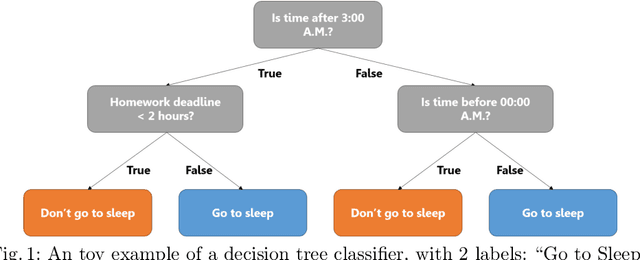
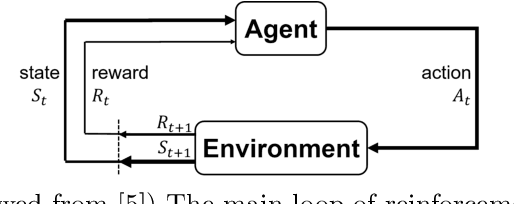
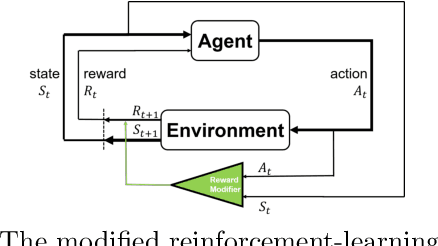
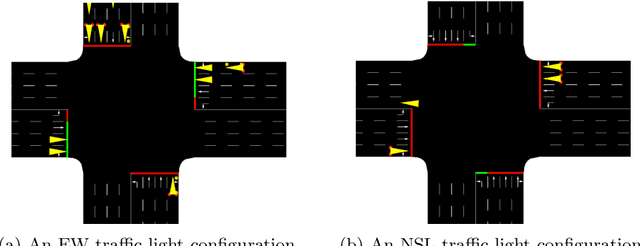
Deep reinforcement learning (DRL) has proven extremely useful in a large variety of application domains. However, even successful DRL-based software can exhibit highly undesirable behavior. This is due to DRL training being based on maximizing a reward function, which typically captures general trends but cannot precisely capture, or rule out, certain behaviors of the system. In this paper, we propose a novel framework aimed at drastically reducing the undesirable behavior of DRL-based software, while maintaining its excellent performance. In addition, our framework can assist in providing engineers with a comprehensible characterization of such undesirable behavior. Under the hood, our approach is based on extracting decision tree classifiers from erroneous state-action pairs, and then integrating these trees into the DRL training loop, penalizing the system whenever it performs an error. We provide a proof-of-concept implementation of our approach, and use it to evaluate the technique on three significant case studies. We find that our approach can extend existing frameworks in a straightforward manner, and incurs only a slight overhead in training time. Further, it incurs only a very slight hit to performance, or even in some cases - improves it, while significantly reducing the frequency of undesirable behavior.
EANet: Expert Attention Network for Online Trajectory Prediction
Sep 11, 2023


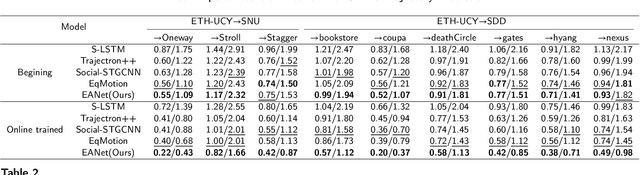
Trajectory prediction plays a crucial role in autonomous driving. Existing mainstream research and continuoual learning-based methods all require training on complete datasets, leading to poor prediction accuracy when sudden changes in scenarios occur and failing to promptly respond and update the model. Whether these methods can make a prediction in real-time and use data instances to update the model immediately(i.e., online learning settings) remains a question. The problem of gradient explosion or vanishing caused by data instance streams also needs to be addressed. Inspired by Hedge Propagation algorithm, we propose Expert Attention Network, a complete online learning framework for trajectory prediction. We introduce expert attention, which adjusts the weights of different depths of network layers, avoiding the model updated slowly due to gradient problem and enabling fast learning of new scenario's knowledge to restore prediction accuracy. Furthermore, we propose a short-term motion trend kernel function which is sensitive to scenario change, allowing the model to respond quickly. To the best of our knowledge, this work is the first attempt to address the online learning problem in trajectory prediction. The experimental results indicate that traditional methods suffer from gradient problems and that our method can quickly reduce prediction errors and reach the state-of-the-art prediction accuracy.
Efficient Defense Against Model Stealing Attacks on Convolutional Neural Networks
Sep 11, 2023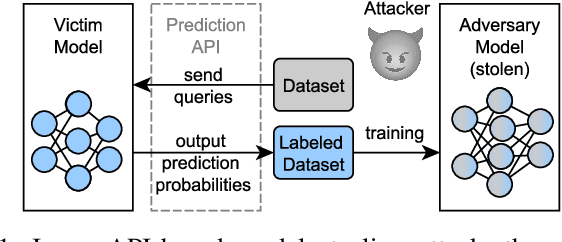
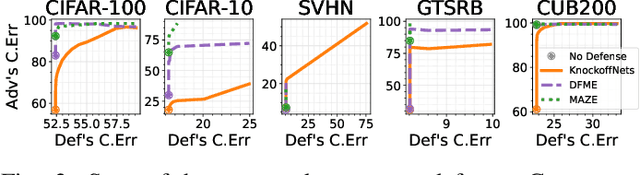
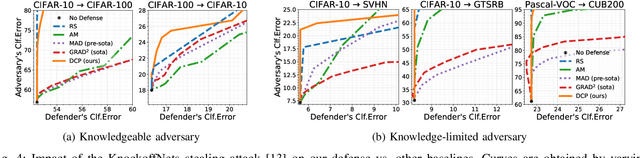
Model stealing attacks have become a serious concern for deep learning models, where an attacker can steal a trained model by querying its black-box API. This can lead to intellectual property theft and other security and privacy risks. The current state-of-the-art defenses against model stealing attacks suggest adding perturbations to the prediction probabilities. However, they suffer from heavy computations and make impracticable assumptions about the adversary. They often require the training of auxiliary models. This can be time-consuming and resource-intensive which hinders the deployment of these defenses in real-world applications. In this paper, we propose a simple yet effective and efficient defense alternative. We introduce a heuristic approach to perturb the output probabilities. The proposed defense can be easily integrated into models without additional training. We show that our defense is effective in defending against three state-of-the-art stealing attacks. We evaluate our approach on large and quantized (i.e., compressed) Convolutional Neural Networks (CNNs) trained on several vision datasets. Our technique outperforms the state-of-the-art defenses with a $\times37$ faster inference latency without requiring any additional model and with a low impact on the model's performance. We validate that our defense is also effective for quantized CNNs targeting edge devices.
Uncertainty-Driven Multi-Scale Feature Fusion Network for Real-time Image Deraining
Jul 19, 2023
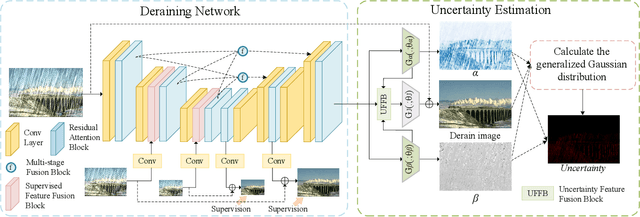
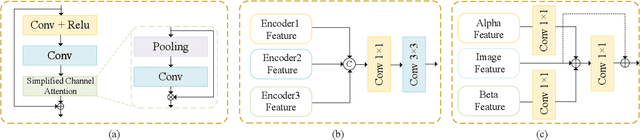
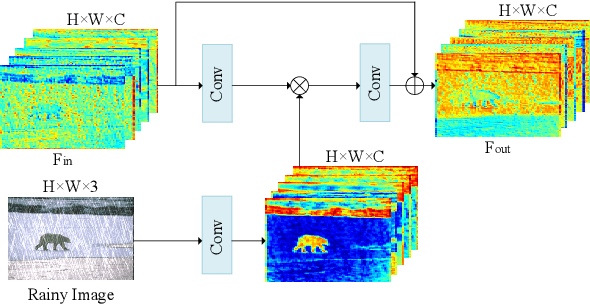
Visual-based measurement systems are frequently affected by rainy weather due to the degradation caused by rain streaks in captured images, and existing imaging devices struggle to address this issue in real-time. While most efforts leverage deep networks for image deraining and have made progress, their large parameter sizes hinder deployment on resource-constrained devices. Additionally, these data-driven models often produce deterministic results, without considering their inherent epistemic uncertainty, which can lead to undesired reconstruction errors. Well-calibrated uncertainty can help alleviate prediction errors and assist measurement devices in mitigating risks and improving usability. Therefore, we propose an Uncertainty-Driven Multi-Scale Feature Fusion Network (UMFFNet) that learns the probability mapping distribution between paired images to estimate uncertainty. Specifically, we introduce an uncertainty feature fusion block (UFFB) that utilizes uncertainty information to dynamically enhance acquired features and focus on blurry regions obscured by rain streaks, reducing prediction errors. In addition, to further boost the performance of UMFFNet, we fused feature information from multiple scales to guide the network for efficient collaborative rain removal. Extensive experiments demonstrate that UMFFNet achieves significant performance improvements with few parameters, surpassing state-of-the-art image deraining methods.
Linking Symptom Inventories using Semantic Textual Similarity
Sep 08, 2023
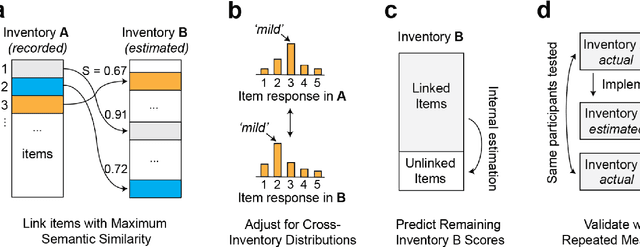
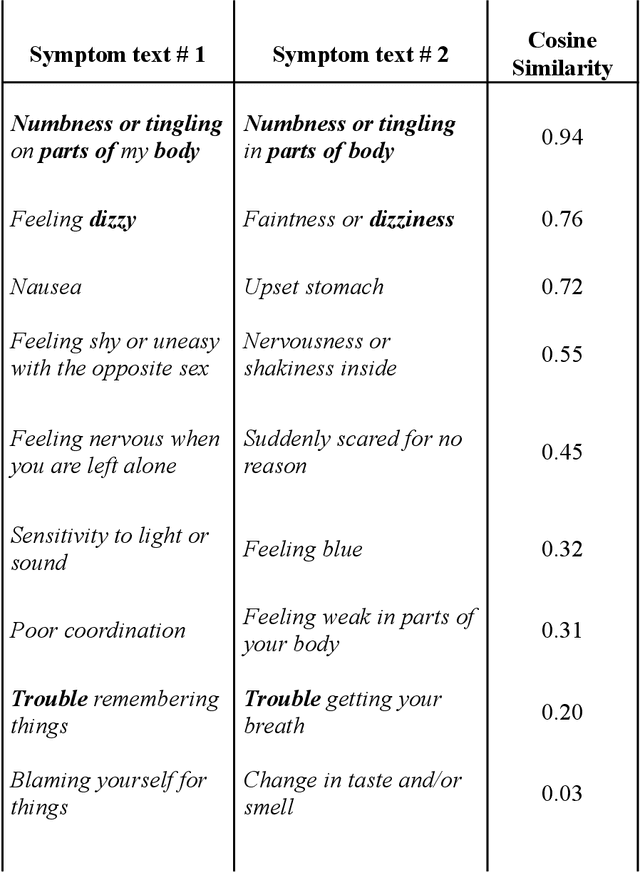
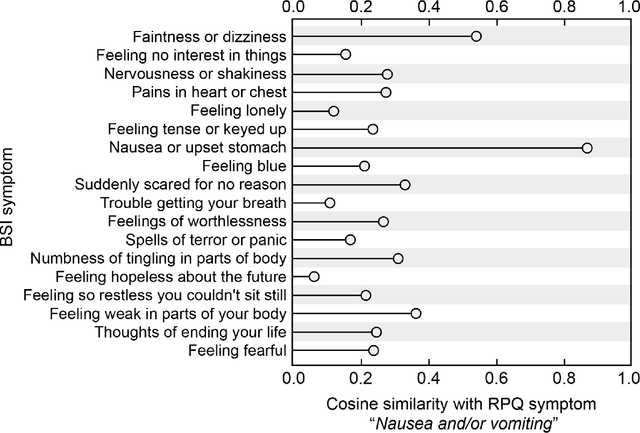
An extensive library of symptom inventories has been developed over time to measure clinical symptoms, but this variety has led to several long standing issues. Most notably, results drawn from different settings and studies are not comparable, which limits reproducibility. Here, we present an artificial intelligence (AI) approach using semantic textual similarity (STS) to link symptoms and scores across previously incongruous symptom inventories. We tested the ability of four pre-trained STS models to screen thousands of symptom description pairs for related content - a challenging task typically requiring expert panels. Models were tasked to predict symptom severity across four different inventories for 6,607 participants drawn from 16 international data sources. The STS approach achieved 74.8% accuracy across five tasks, outperforming other models tested. This work suggests that incorporating contextual, semantic information can assist expert decision-making processes, yielding gains for both general and disease-specific clinical assessment.
AdBooster: Personalized Ad Creative Generation using Stable Diffusion Outpainting
Sep 08, 2023

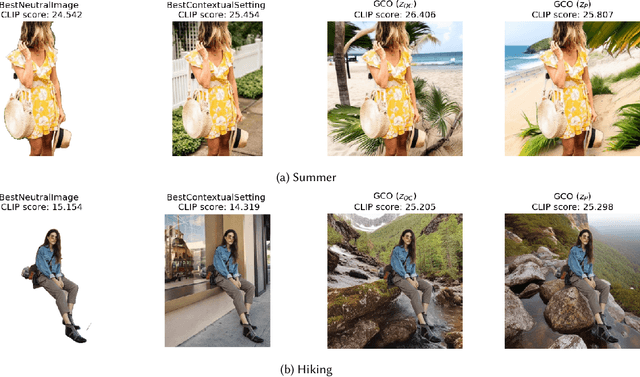
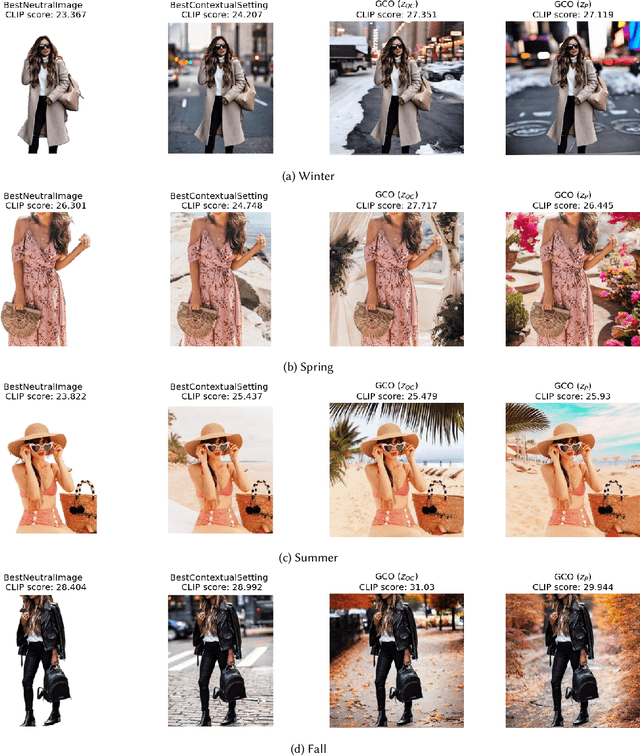
In digital advertising, the selection of the optimal item (recommendation) and its best creative presentation (creative optimization) have traditionally been considered separate disciplines. However, both contribute significantly to user satisfaction, underpinning our assumption that it relies on both an item's relevance and its presentation, particularly in the case of visual creatives. In response, we introduce the task of {\itshape Generative Creative Optimization (GCO)}, which proposes the use of generative models for creative generation that incorporate user interests, and {\itshape AdBooster}, a model for personalized ad creatives based on the Stable Diffusion outpainting architecture. This model uniquely incorporates user interests both during fine-tuning and at generation time. To further improve AdBooster's performance, we also introduce an automated data augmentation pipeline. Through our experiments on simulated data, we validate AdBooster's effectiveness in generating more relevant creatives than default product images, showing its potential of enhancing user engagement.
Advancing Intra-operative Precision: Dynamic Data-Driven Non-Rigid Registration for Enhanced Brain Tumor Resection in Image-Guided Neurosurgery
Aug 31, 2023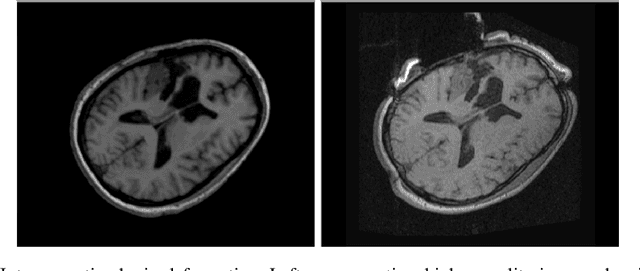

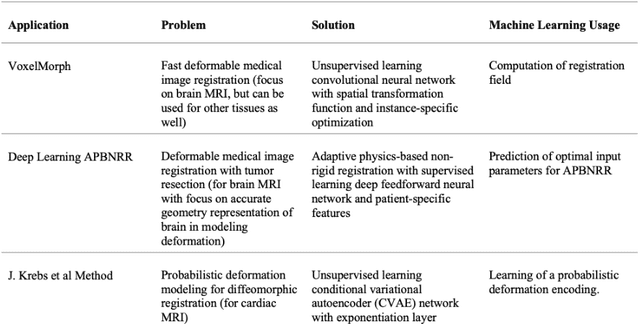
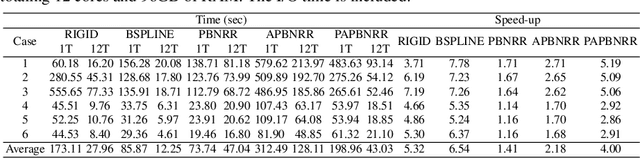
During neurosurgery, medical images of the brain are used to locate tumors and critical structures, but brain tissue shifts make pre-operative images unreliable for accurate removal of tumors. Intra-operative imaging can track these deformations but is not a substitute for pre-operative data. To address this, we use Dynamic Data-Driven Non-Rigid Registration (NRR), a complex and time-consuming image processing operation that adjusts the pre-operative image data to account for intra-operative brain shift. Our review explores a specific NRR method for registering brain MRI during image-guided neurosurgery and examines various strategies for improving the accuracy and speed of the NRR method. We demonstrate that our implementation enables NRR results to be delivered within clinical time constraints while leveraging Distributed Computing and Machine Learning to enhance registration accuracy by identifying optimal parameters for the NRR method. Additionally, we highlight challenges associated with its use in the operating room.
On the Safety of Connected Cruise Control: Analysis and Synthesis with Control Barrier Functions
Aug 31, 2023
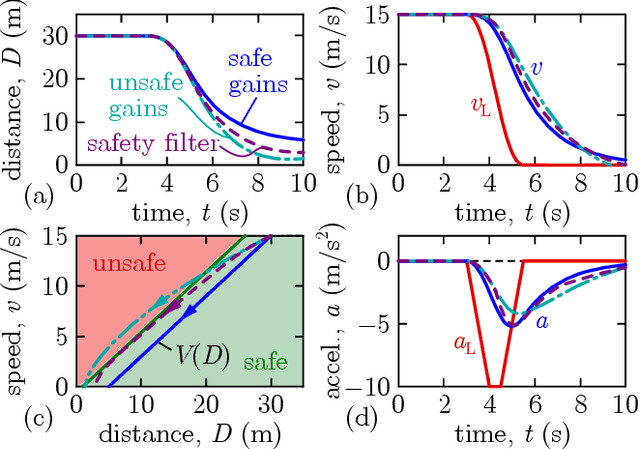
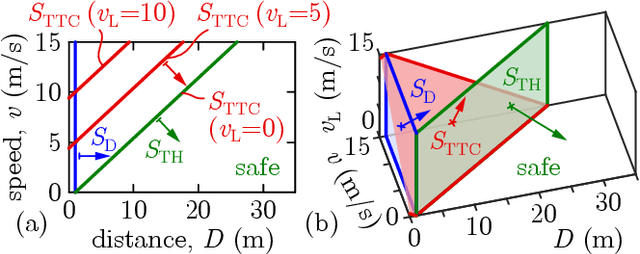
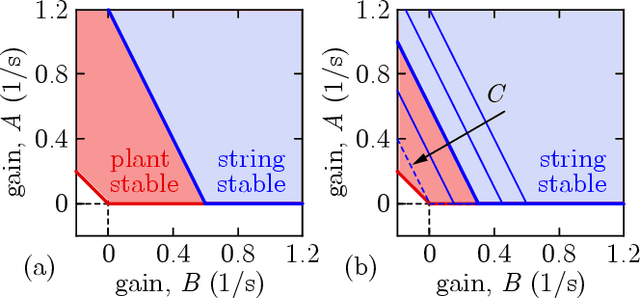
Connected automated vehicles have shown great potential to improve the efficiency of transportation systems in terms of passenger comfort, fuel economy, stability of driving behavior and mitigation of traffic congestions. Yet, to deploy these vehicles and leverage their benefits, the underlying algorithms must ensure their safe operation. In this paper, we address the safety of connected cruise control strategies for longitudinal car following using control barrier function (CBF) theory. In particular, we consider various safety measures such as minimum distance, time headway and time to conflict, and provide a formal analysis of these measures through the lens of CBFs. Additionally, motivated by how stability charts facilitate stable controller design, we derive safety charts for existing connected cruise controllers to identify safe choices of controller parameters. Finally, we combine the analysis of safety measures and the corresponding stability charts to synthesize safety-critical connected cruise controllers using CBFs. We verify our theoretical results by numerical simulations.
RoLA: A Real-Time Online Lightweight Anomaly Detection System for Multivariate Time Series
May 25, 2023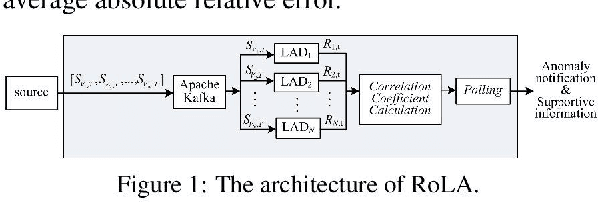


A multivariate time series refers to observations of two or more variables taken from a device or a system simultaneously over time. There is an increasing need to monitor multivariate time series and detect anomalies in real time to ensure proper system operation and good service quality. It is also highly desirable to have a lightweight anomaly detection system that considers correlations between different variables, adapts to changes in the pattern of the multivariate time series, offers immediate responses, and provides supportive information regarding detection results based on unsupervised learning and online model training. In the past decade, many multivariate time series anomaly detection approaches have been introduced. However, they are unable to offer all the above-mentioned features. In this paper, we propose RoLA, a real-time online lightweight anomaly detection system for multivariate time series based on a divide-and-conquer strategy, parallel processing, and the majority rule. RoLA employs multiple lightweight anomaly detectors to monitor multivariate time series in parallel, determine the correlations between variables dynamically on the fly, and then jointly detect anomalies based on the majority rule in real time. To demonstrate the performance of RoLA, we conducted an experiment based on a public dataset provided by the FerryBox of the One Ocean Expedition. The results show that RoLA provides satisfactory detection accuracy and lightweight performance.
The Rise and Potential of Large Language Model Based Agents: A Survey
Sep 14, 2023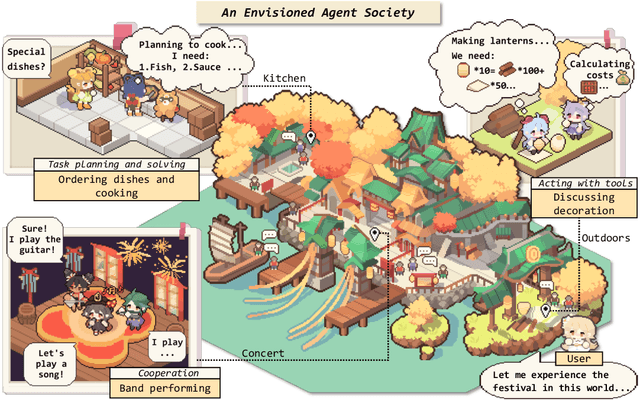
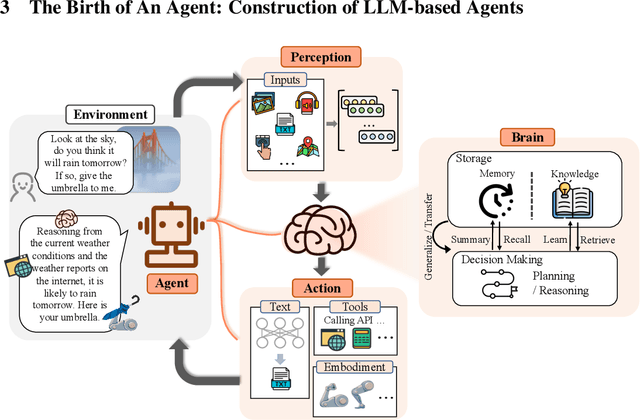
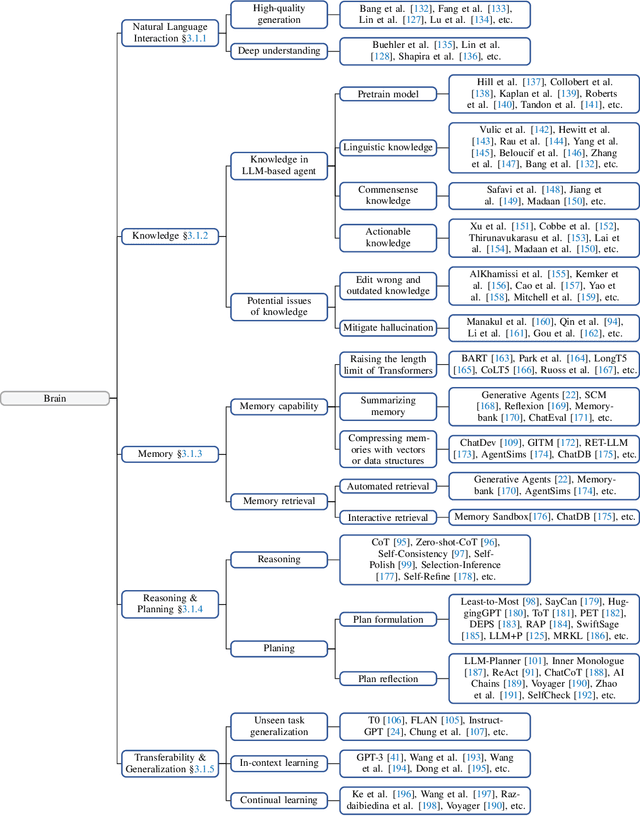
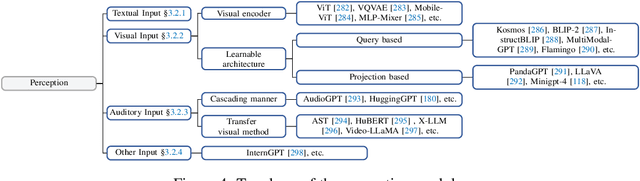
For a long time, humanity has pursued artificial intelligence (AI) equivalent to or surpassing the human level, with AI agents considered a promising vehicle for this pursuit. AI agents are artificial entities that sense their environment, make decisions, and take actions. Many efforts have been made to develop intelligent AI agents since the mid-20th century. However, these efforts have mainly focused on advancement in algorithms or training strategies to enhance specific capabilities or performance on particular tasks. Actually, what the community lacks is a sufficiently general and powerful model to serve as a starting point for designing AI agents that can adapt to diverse scenarios. Due to the versatile and remarkable capabilities they demonstrate, large language models (LLMs) are regarded as potential sparks for Artificial General Intelligence (AGI), offering hope for building general AI agents. Many research efforts have leveraged LLMs as the foundation to build AI agents and have achieved significant progress. We start by tracing the concept of agents from its philosophical origins to its development in AI, and explain why LLMs are suitable foundations for AI agents. Building upon this, we present a conceptual framework for LLM-based agents, comprising three main components: brain, perception, and action, and the framework can be tailored to suit different applications. Subsequently, we explore the extensive applications of LLM-based agents in three aspects: single-agent scenarios, multi-agent scenarios, and human-agent cooperation. Following this, we delve into agent societies, exploring the behavior and personality of LLM-based agents, the social phenomena that emerge when they form societies, and the insights they offer for human society. Finally, we discuss a range of key topics and open problems within the field.