 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivQAT: Enhancing Robustness of Quantized Convolutional Neural Networks against Model Extraction Attacks
Dec 30, 2025Convolutional Neural Networks (CNNs) and their quantized counterparts are vulnerable to extraction attacks, posing a significant threat of IP theft. Yet, the robustness of quantized models against these attacks is little studied compared to large models. Previous defenses propose to inject calculated noise into the prediction probabilities. However, these defenses are limited since they are not incorporated during the model design and are only added as an afterthought after training. Additionally, most defense techniques are computationally expensive and often have unrealistic assumptions about the victim model that are not feasible in edge device implementations and do not apply to quantized models. In this paper, we propose DivQAT, a novel algorithm to train quantized CNNs based on Quantization Aware Training (QAT) aiming to enhance their robustness against extraction attacks. To the best of our knowledge, our technique is the first to modify the quantization process to integrate a model extraction defense into the training process. Through empirical validation on benchmark vision datasets, we demonstrate the efficacy of our technique in defending against model extraction attacks without compromising model accuracy. Furthermore, combining our quantization technique with other defense mechanisms improves their effectiveness compared to traditional QAT.
Efficient Defense Against Model Stealing Attacks on Convolutional Neural Networks
Sep 11, 2023Model stealing attacks have become a serious concern for deep learning models, where an attacker can steal a trained model by querying its black-box API. This can lead to intellectual property theft and other security and privacy risks. The current state-of-the-art defenses against model stealing attacks suggest adding perturbations to the prediction probabilities. However, they suffer from heavy computations and make impracticable assumptions about the adversary. They often require the training of auxiliary models. This can be time-consuming and resource-intensive which hinders the deployment of these defenses in real-world applications. In this paper, we propose a simple yet effective and efficient defense alternative. We introduce a heuristic approach to perturb the output probabilities. The proposed defense can be easily integrated into models without additional training. We show that our defense is effective in defending against three state-of-the-art stealing attacks. We evaluate our approach on large and quantized (i.e., compressed) Convolutional Neural Networks (CNNs) trained on several vision datasets. Our technique outperforms the state-of-the-art defenses with a $\times37$ faster inference latency without requiring any additional model and with a low impact on the model's performance. We validate that our defense is also effective for quantized CNNs targeting edge devices.
Careful What You Wish For: on the Extraction of Adversarially Trained Models
Jul 21, 2022
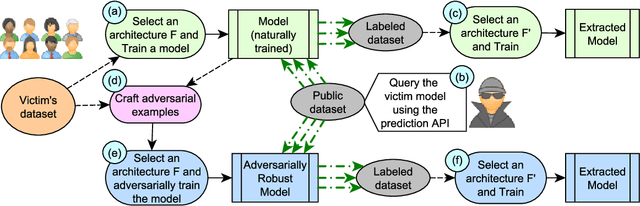

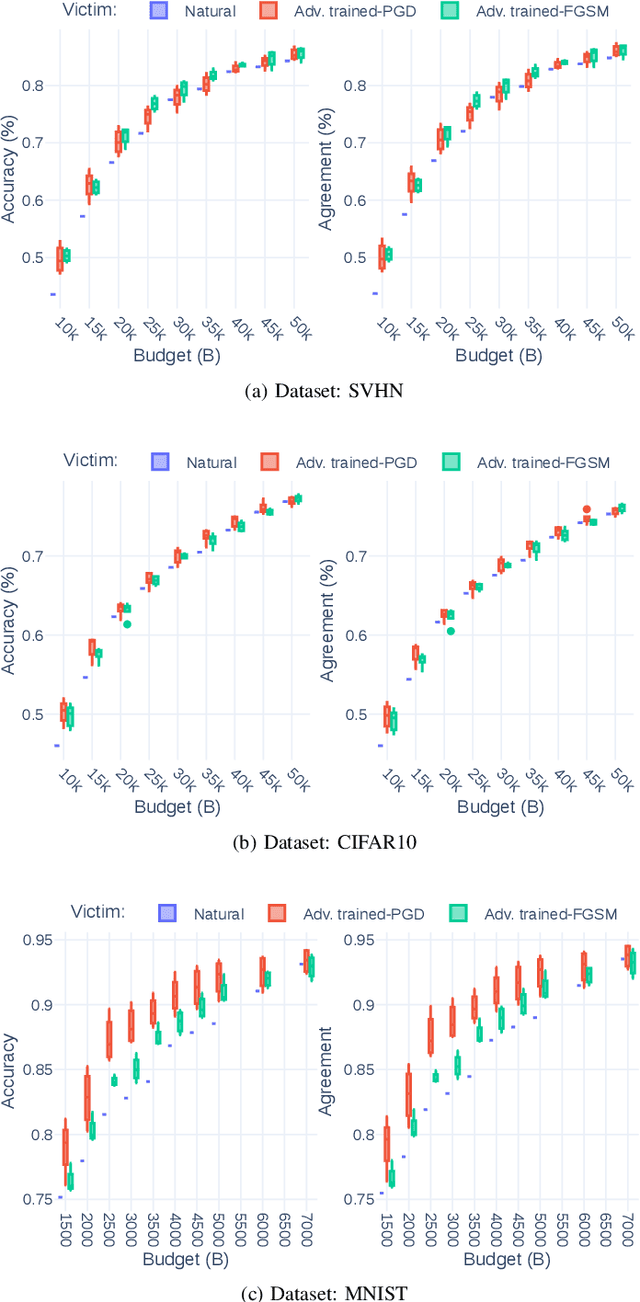
Recent attacks on Machine Learning (ML) models such as evasion attacks with adversarial examples and models stealing through extraction attacks pose several security and privacy threats. Prior work proposes to use adversarial training to secure models from adversarial examples that can evade the classification of a model and deteriorate its performance. However, this protection technique affects the model's decision boundary and its prediction probabilities, hence it might raise model privacy risks. In fact, a malicious user using only a query access to the prediction output of a model can extract it and obtain a high-accuracy and high-fidelity surrogate model. To have a greater extraction, these attacks leverage the prediction probabilities of the victim model. Indeed, all previous work on extraction attacks do not take into consideration the changes in the training process for security purposes. In this paper, we propose a framework to assess extraction attacks on adversarially trained models with vision datasets. To the best of our knowledge, our work is the first to perform such evaluation. Through an extensive empirical study, we demonstrate that adversarially trained models are more vulnerable to extraction attacks than models obtained under natural training circumstances. They can achieve up to $\times1.2$ higher accuracy and agreement with a fraction lower than $\times0.75$ of the queries. We additionally find that the adversarial robustness capability is transferable through extraction attacks, i.e., extracted Deep Neural Networks (DNNs) from robust models show an enhanced accuracy to adversarial examples compared to extracted DNNs from naturally trained (i.e. standard) models.