 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Prompt Optimisation with Random Sampling
Nov 16, 2023
Using the generative nature of a language model to generate task-relevant separators has shown competitive results compared to human-curated prompts like "TL;DR". We demonstrate that even randomly chosen tokens from the vocabulary as separators can achieve near-state-of-the-art performance. We analyse this phenomenon in detail using three different random generation strategies, establishing that the language space is rich with potential good separators, regardless of the underlying language model size. These observations challenge the common assumption that an effective prompt should be human-readable or task-relevant. Experimental results show that using random separators leads to an average 16% relative improvement across nine text classification tasks on seven language models, compared to human-curated separators, and is on par with automatic prompt searching methods.
Fuse to Forget: Bias Reduction and Selective Memorization through Model Fusion
Nov 13, 2023Model fusion research aims to aggregate the knowledge of multiple models to enhance performance by combining their weights. In this work, we study the inverse, investigating whether and how can model fusion interfere and reduce unwanted knowledge. We delve into the effects of model fusion on the evolution of learned shortcuts, social biases, and memorization capabilities in fine-tuned language models. Through several experiments covering text classification and generation tasks, our analysis highlights that shared knowledge among models is usually enhanced during model fusion, while unshared knowledge is usually lost or forgotten. Based on this observation, we demonstrate the potential of model fusion as a debiasing tool and showcase its efficacy in addressing privacy concerns associated with language models.
Taiyi: A Bilingual Fine-Tuned Large Language Model for Diverse Biomedical Tasks
Nov 20, 2023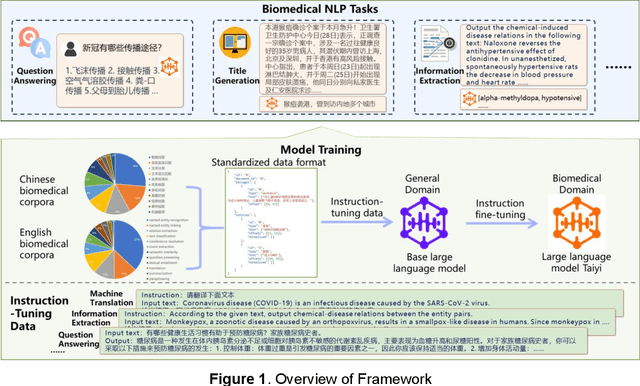
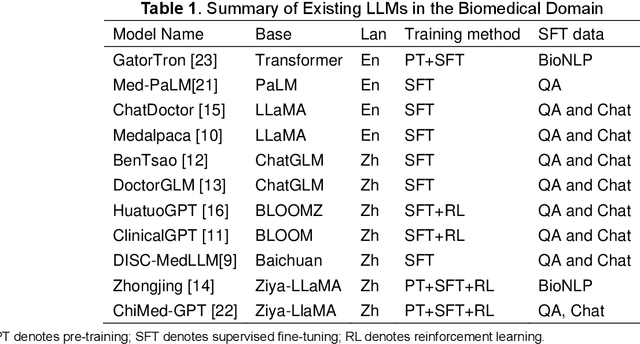
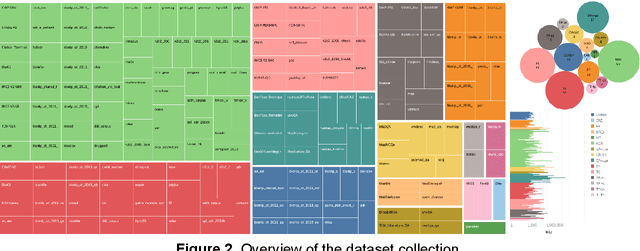
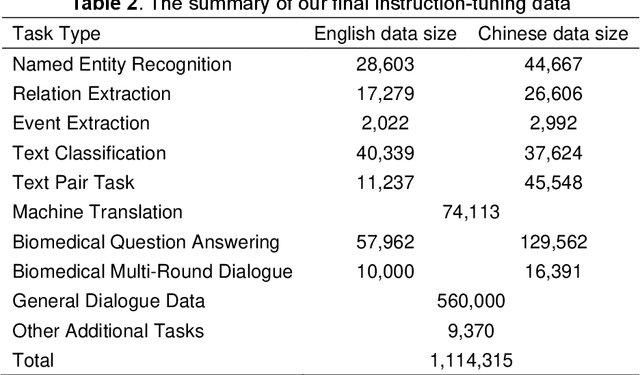
Recent advancements in large language models (LLMs) have shown promising results across a variety of natural language processing (NLP) tasks. The application of LLMs to specific domains, such as biomedicine, has achieved increased attention. However, most biomedical LLMs focus on enhancing performance in monolingual biomedical question answering and conversation tasks. To further investigate the effectiveness of the LLMs on diverse biomedical NLP tasks in different languages, we present Taiyi, a bilingual (English and Chinese) fine-tuned LLM for diverse biomedical tasks. In this work, we first curated a comprehensive collection of 140 existing biomedical text mining datasets across over 10 task types. Subsequently, a two-stage strategy is proposed for supervised fine-tuning to optimize the model performance across varied tasks. Experimental results on 13 test sets covering named entity recognition, relation extraction, text classification, question answering tasks demonstrate Taiyi achieves superior performance compared to general LLMs. The case study involving additional biomedical NLP tasks further shows Taiyi's considerable potential for bilingual biomedical multi-tasking. The source code, datasets, and model for Taiyi are freely available at https://github.com/DUTIR-BioNLP/Taiyi-LLM.
Semantic Text Compression for Classification
Sep 19, 2023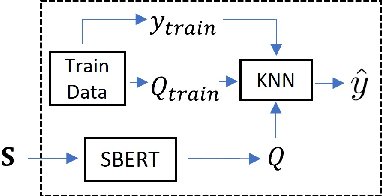
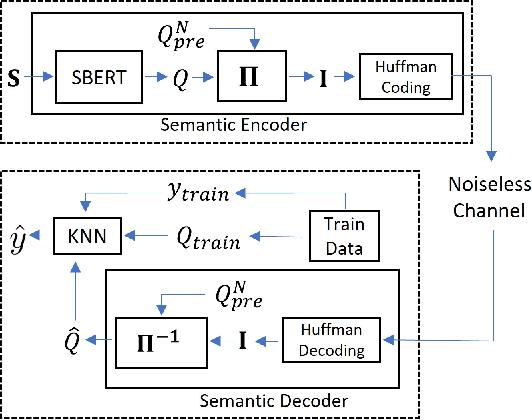
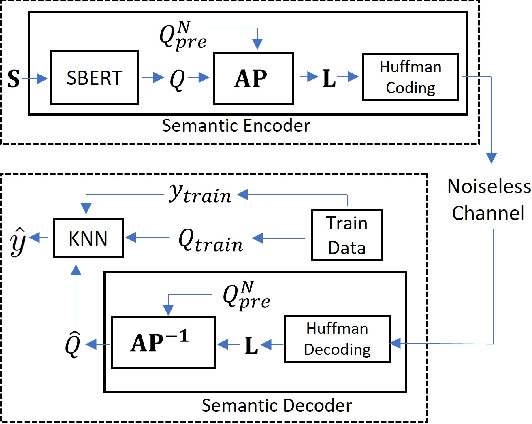
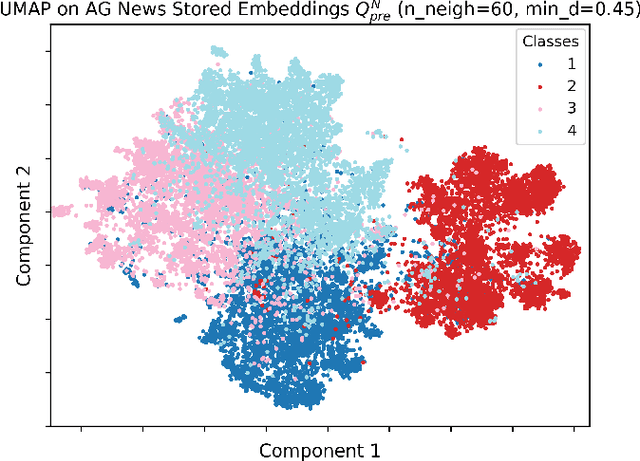
We study semantic compression for text where meanings contained in the text are conveyed to a source decoder, e.g., for classification. The main motivator to move to such an approach of recovering the meaning without requiring exact reconstruction is the potential resource savings, both in storage and in conveying the information to another node. Towards this end, we propose semantic quantization and compression approaches for text where we utilize sentence embeddings and the semantic distortion metric to preserve the meaning. Our results demonstrate that the proposed semantic approaches result in substantial (orders of magnitude) savings in the required number of bits for message representation at the expense of very modest accuracy loss compared to the semantic agnostic baseline. We compare the results of proposed approaches and observe that resource savings enabled by semantic quantization can be further amplified by semantic clustering. Importantly, we observe the generalizability of the proposed methodology which produces excellent results on many benchmark text classification datasets with a diverse array of contexts.
Few-Shot Learning from Augmented Label-Uncertain Queries in Bongard-HOI
Dec 17, 2023Detecting human-object interactions (HOI) in a few-shot setting remains a challenge. Existing meta-learning methods struggle to extract representative features for classification due to the limited data, while existing few-shot HOI models rely on HOI text labels for classification. Moreover, some query images may display visual similarity to those outside their class, such as similar backgrounds between different HOI classes. This makes learning more challenging, especially with limited samples. Bongard-HOI (Jiang et al. 2022) epitomizes this HOI few-shot problem, making it the benchmark we focus on in this paper. In our proposed method, we introduce novel label-uncertain query augmentation techniques to enhance the diversity of the query inputs, aiming to distinguish the positive HOI class from the negative ones. As these augmented inputs may or may not have the same class label as the original inputs, their class label is unknown. Those belonging to a different class become hard samples due to their visual similarity to the original ones. Additionally, we introduce a novel pseudo-label generation technique that enables a mean teacher model to learn from the augmented label-uncertain inputs. We propose to augment the negative support set for the student model to enrich the semantic information, fostering diversity that challenges and enhances the student's learning. Experimental results demonstrate that our method sets a new state-of-the-art (SOTA) performance by achieving 68.74% accuracy on the Bongard-HOI benchmark, a significant improvement over the existing SOTA of 66.59%. In our evaluation on HICO-FS, a more general few-shot recognition dataset, our method achieves 73.27% accuracy, outperforming the previous SOTA of 71.20% in the 5-way 5-shot task.
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Dec 21, 2023The exponential growth of large language models (LLMs) has opened up numerous possibilities for multi-modal AGI systems. However, the progress in vision and vision-language foundation models, which are also critical elements of multi-modal AGI, has not kept pace with LLMs. In this work, we design a large-scale vision-language foundation model (InternVL), which scales up the vision foundation model to 6 billion parameters and progressively aligns it with the large language model, using web-scale image-text data from various sources. This model can be broadly applied to and achieve state-of-the-art performance on visual perception tasks such as image-level or pixel-level recognition, vision-language tasks such as zero-shot image/video classification, zero-shot image/video-text retrieval, and link with LLMs to create multi-modal dialogue systems. We hope that our research could contribute to the development of multi-modal large models. Code and models are available at https://github.com/OpenGVLab/InternVL.
Breaking the Bank with ChatGPT: Few-Shot Text Classification for Finance
Aug 28, 2023
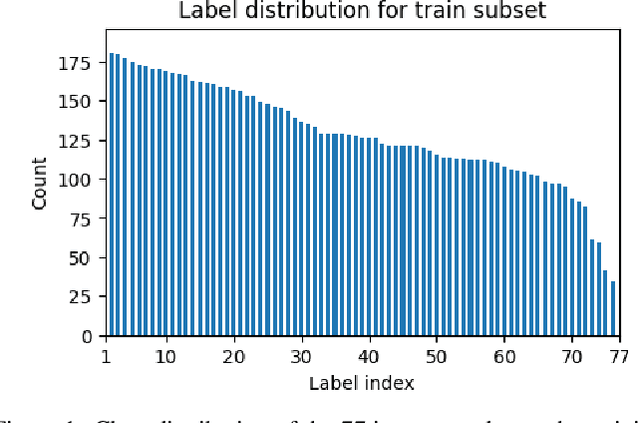
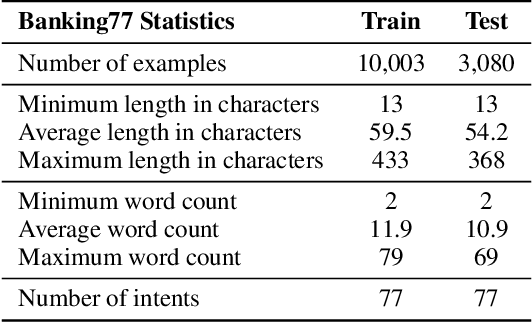

We propose the use of conversational GPT models for easy and quick few-shot text classification in the financial domain using the Banking77 dataset. Our approach involves in-context learning with GPT-3.5 and GPT-4, which minimizes the technical expertise required and eliminates the need for expensive GPU computing while yielding quick and accurate results. Additionally, we fine-tune other pre-trained, masked language models with SetFit, a recent contrastive learning technique, to achieve state-of-the-art results both in full-data and few-shot settings. Our findings show that querying GPT-3.5 and GPT-4 can outperform fine-tuned, non-generative models even with fewer examples. However, subscription fees associated with these solutions may be considered costly for small organizations. Lastly, we find that generative models perform better on the given task when shown representative samples selected by a human expert rather than when shown random ones. We conclude that a) our proposed methods offer a practical solution for few-shot tasks in datasets with limited label availability, and b) our state-of-the-art results can inspire future work in the area.
Exploiting Contextual Target Attributes for Target Sentiment Classification
Dec 21, 2023Existing PTLM-based models for TSC can be categorized into two groups: 1) fine-tuning-based models that adopt PTLM as the context encoder; 2) prompting-based models that transfer the classification task to the text/word generation task. In this paper, we present a new perspective of leveraging PTLM for TSC: simultaneously leveraging the merits of both language modeling and explicit target-context interactions via contextual target attributes. Specifically, we design the domain- and target-constrained cloze test, which can leverage the PTLMs' strong language modeling ability to generate the given target's attributes pertaining to the review context. The attributes contain the background and property information of the target, which can help to enrich the semantics of the review context and the target. To exploit the attributes for tackling TSC, we first construct a heterogeneous information graph by treating the attributes as nodes and combining them with (1) the syntax graph automatically produced by the off-the-shelf dependency parser and (2) the semantics graph of the review context, which is derived from the self-attention mechanism. Then we propose a heterogeneous information gated graph convolutional network to model the interactions among the attribute information, the syntactic information, and the contextual information. The experimental results on three benchmark datasets demonstrate the superiority of our model, which achieves new state-of-the-art performance.
TagAlign: Improving Vision-Language Alignment with Multi-Tag Classification
Dec 21, 2023The crux of learning vision-language models is to extract semantically aligned information from visual and linguistic data. Existing attempts usually face the problem of coarse alignment, \textit{e.g.}, the vision encoder struggles in localizing an attribute-specified object. In this work, we propose an embarrassingly simple approach to better align image and text features with no need of additional data formats other than image-text pairs. Concretely, given an image and its paired text, we manage to parse objects (\textit{e.g.}, cat) and attributes (\textit{e.g.}, black) from the description, which are highly likely to exist in the image. It is noteworthy that the parsing pipeline is fully automatic and thus enjoys good scalability. With these parsed semantics as supervision signals, we can complement the commonly used image-text contrastive loss with the multi-tag classification loss. Extensive experimental results on a broad suite of semantic segmentation datasets substantiate the average 3.65\% improvement of our framework over existing alternatives. Furthermore, the visualization results indicate that attribute supervision makes vision-language models accurately localize attribute-specified objects. Project page can be found at https://qinying-liu.github.io/Tag-Align/
SkyScript: A Large and Semantically Diverse Vision-Language Dataset for Remote Sensing
Dec 20, 2023Remote sensing imagery, despite its broad applications in helping achieve Sustainable Development Goals and tackle climate change, has not yet benefited from the recent advancements of versatile, task-agnostic vision language models (VLMs). A key reason is that the large-scale, semantically diverse image-text dataset required for developing VLMs is still absent for remote sensing images. Unlike natural images, remote sensing images and their associated text descriptions cannot be efficiently collected from the public Internet at scale. In this work, we bridge this gap by using geo-coordinates to automatically connect open, unlabeled remote sensing images with rich semantics covered in OpenStreetMap, and thus construct SkyScript, a comprehensive vision-language dataset for remote sensing images, comprising 2.6 million image-text pairs covering 29K distinct semantic tags. With continual pre-training on this dataset, we obtain a VLM that surpasses baseline models with a 6.2% average accuracy gain in zero-shot scene classification across seven benchmark datasets. It also demonstrates the ability of zero-shot transfer for fine-grained object attribute classification and cross-modal retrieval. We hope this dataset can support the advancement of VLMs for various multi-modal tasks in remote sensing, such as open-vocabulary classification, retrieval, captioning, and text-to-image synthesis.