 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGR-NLP-TOOLKIT: An Open-Source NLP Toolkit for Modern Greek
Dec 11, 2024



We present GR-NLP-TOOLKIT, an open-source natural language processing (NLP) toolkit developed specifically for modern Greek. The toolkit provides state-of-the-art performance in five core NLP tasks, namely part-of-speech tagging, morphological tagging, dependency parsing, named entity recognition, and Greeklishto-Greek transliteration. The toolkit is based on pre-trained Transformers, it is freely available, and can be easily installed in Python (pip install gr-nlp-toolkit). It is also accessible through a demonstration platform on HuggingFace, along with a publicly available API for non-commercial use. We discuss the functionality provided for each task, the underlying methods, experiments against comparable open-source toolkits, and future possible enhancements. The toolkit is available at: https://github.com/nlpaueb/gr-nlp-toolkit
Making LLMs Worth Every Penny: Resource-Limited Text Classification in Banking
Nov 10, 2023



Standard Full-Data classifiers in NLP demand thousands of labeled examples, which is impractical in data-limited domains. Few-shot methods offer an alternative, utilizing contrastive learning techniques that can be effective with as little as 20 examples per class. Similarly, Large Language Models (LLMs) like GPT-4 can perform effectively with just 1-5 examples per class. However, the performance-cost trade-offs of these methods remain underexplored, a critical concern for budget-limited organizations. Our work addresses this gap by studying the aforementioned approaches over the Banking77 financial intent detection dataset, including the evaluation of cutting-edge LLMs by OpenAI, Cohere, and Anthropic in a comprehensive set of few-shot scenarios. We complete the picture with two additional methods: first, a cost-effective querying method for LLMs based on retrieval-augmented generation (RAG), able to reduce operational costs multiple times compared to classic few-shot approaches, and second, a data augmentation method using GPT-4, able to improve performance in data-limited scenarios. Finally, to inspire future research, we provide a human expert's curated subset of Banking77, along with extensive error analysis.
Breaking the Bank with ChatGPT: Few-Shot Text Classification for Finance
Aug 28, 2023



We propose the use of conversational GPT models for easy and quick few-shot text classification in the financial domain using the Banking77 dataset. Our approach involves in-context learning with GPT-3.5 and GPT-4, which minimizes the technical expertise required and eliminates the need for expensive GPU computing while yielding quick and accurate results. Additionally, we fine-tune other pre-trained, masked language models with SetFit, a recent contrastive learning technique, to achieve state-of-the-art results both in full-data and few-shot settings. Our findings show that querying GPT-3.5 and GPT-4 can outperform fine-tuned, non-generative models even with fewer examples. However, subscription fees associated with these solutions may be considered costly for small organizations. Lastly, we find that generative models perform better on the given task when shown representative samples selected by a human expert rather than when shown random ones. We conclude that a) our proposed methods offer a practical solution for few-shot tasks in datasets with limited label availability, and b) our state-of-the-art results can inspire future work in the area.
Financial misstatement detection: a realistic evaluation
May 27, 2023



In this work, we examine the evaluation process for the task of detecting financial reports with a high risk of containing a misstatement. This task is often referred to, in the literature, as ``misstatement detection in financial reports''. We provide an extensive review of the related literature. We propose a new, realistic evaluation framework for the task which, unlike a large part of the previous work: (a) focuses on the misstatement class and its rarity, (b) considers the dimension of time when splitting data into training and test and (c) considers the fact that misstatements can take a long time to detect. Most importantly, we show that the evaluation process significantly affects system performance, and we analyze the performance of different models and feature types in the new realistic framework.
* 9 pages, ICAIF2021
FiNER: Financial Numeric Entity Recognition for XBRL Tagging
Mar 12, 2022
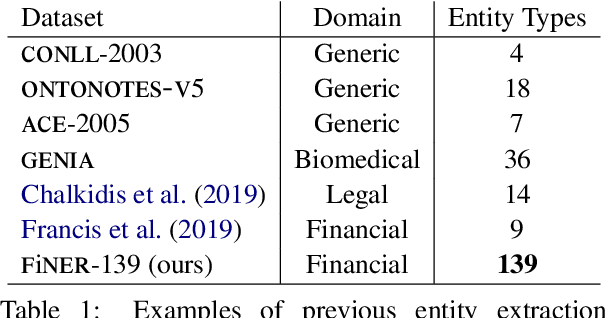
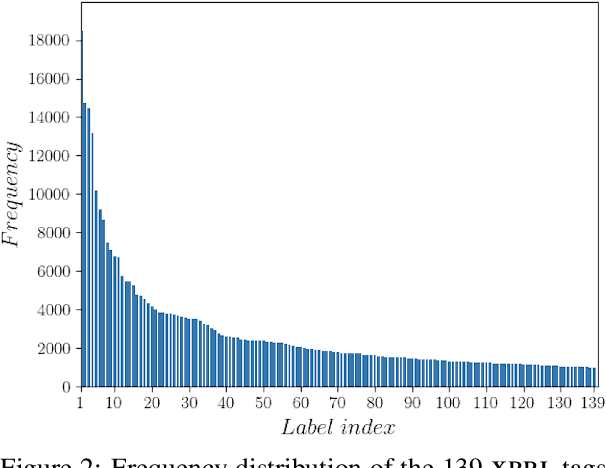
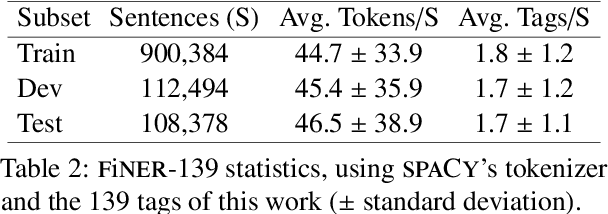
Publicly traded companies are required to submit periodic reports with eXtensive Business Reporting Language (XBRL) word-level tags. Manually tagging the reports is tedious and costly. We, therefore, introduce XBRL tagging as a new entity extraction task for the financial domain and release FiNER-139, a dataset of 1.1M sentences with gold XBRL tags. Unlike typical entity extraction datasets, FiNER-139 uses a much larger label set of 139 entity types. Most annotated tokens are numeric, with the correct tag per token depending mostly on context, rather than the token itself. We show that subword fragmentation of numeric expressions harms BERT's performance, allowing word-level BILSTMs to perform better. To improve BERT's performance, we propose two simple and effective solutions that replace numeric expressions with pseudo-tokens reflecting original token shapes and numeric magnitudes. We also experiment with FIN-BERT, an existing BERT model for the financial domain, and release our own BERT (SEC-BERT), pre-trained on financial filings, which performs best. Through data and error analysis, we finally identify possible limitations to inspire future work on XBRL tagging.
EDGAR-CORPUS: Billions of Tokens Make The World Go Round
Oct 01, 2021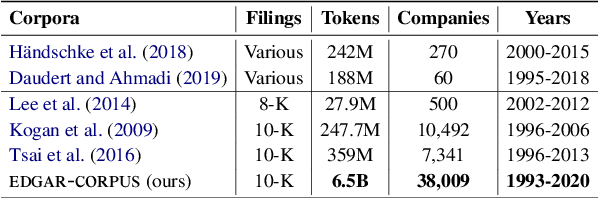



We release EDGAR-CORPUS, a novel corpus comprising annual reports from all the publicly traded companies in the US spanning a period of more than 25 years. To the best of our knowledge, EDGAR-CORPUS is the largest financial NLP corpus available to date. All the reports are downloaded, split into their corresponding items (sections), and provided in a clean, easy-to-use JSON format. We use EDGAR-CORPUS to train and release EDGAR-W2V, which are WORD2VEC embeddings for the financial domain. We employ these embeddings in a battery of financial NLP tasks and showcase their superiority over generic GloVe embeddings and other existing financial word embeddings. We also open-source EDGAR-CRAWLER, a toolkit that facilitates downloading and extracting future annual reports.
DICoE@FinSim-3: Financial Hypernym Detection using Augmented Terms and Distance-based Features
Sep 30, 2021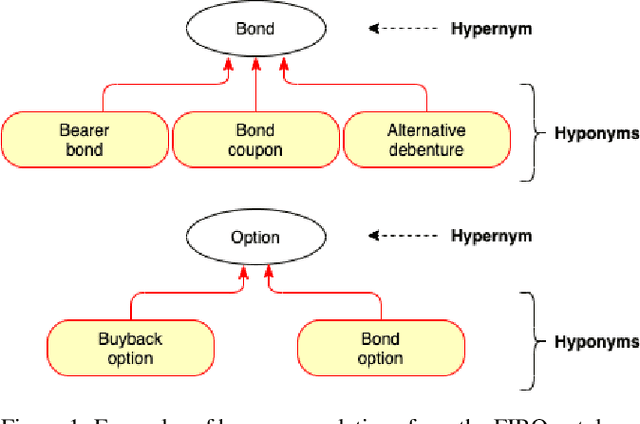
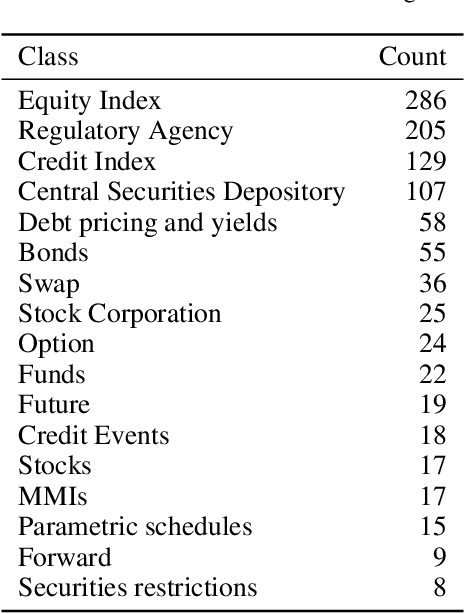
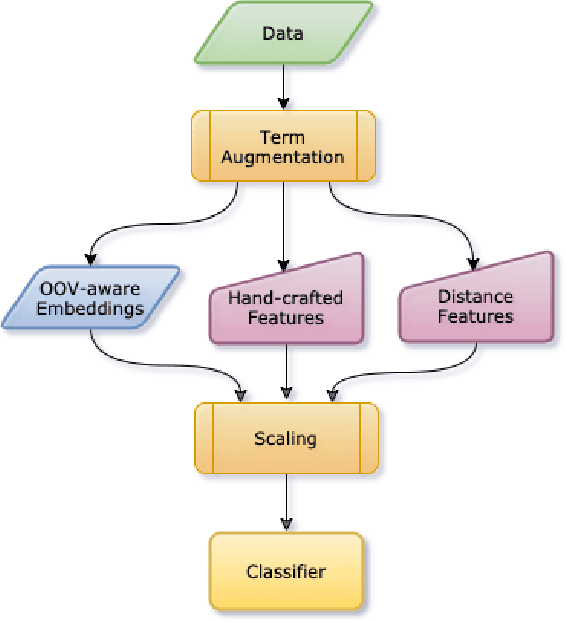
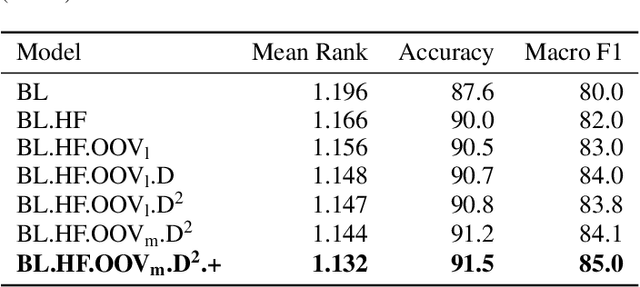
We present the submission of team DICoE for FinSim-3, the 3rd Shared Task on Learning Semantic Similarities for the Financial Domain. The task provides a set of terms in the financial domain and requires to classify them into the most relevant hypernym from a financial ontology. After augmenting the terms with their Investopedia definitions, our system employs a Logistic Regression classifier over financial word embeddings and a mix of hand-crafted and distance-based features. Also, for the first time in this task, we employ different replacement methods for out-of-vocabulary terms, leading to improved performance. Finally, we have also experimented with word representations generated from various financial corpora. Our best-performing submission ranked 4th on the task's leaderboard.