 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliability-Prioritized Fine-Grained Generation in Multimodal Large
Jun 28, 2026Multimodal large language models (MLLMs) are increasingly expected to generate fine-grained descriptions of visual content. However, we observe and theoretically show that generating fine-grained responses poses a reliability challenge, \textit{i.e.}, fine-grained generation is more error-prone than coarse-grained generation. This phenomenon suggests that models should generate the finest description that remains reliable rather than simply produce more specific outputs. To investigate this problem, we develop \textsc{GranFact}, a granularity-aware benchmark consisting of expert-verified multi-object images with coarse-to-fine category annotations. Then, we design a hierarchy-aware evaluation algorithm, which assesses both whether model predictions are visually correct and how specific the correct predictions are. We also propose a reliability-prioritized preference optimization method based on Direct Preference Optimization, which penalizes unreliable fine-grained claims while rewarding reliable specificity. Experiments on \textsc{GranFact} show that our method improves fine-grained generation while preserving reliability. Code and data are available \href{https://github.com/WeiWu2025/GranFact}{here}.
Disco: Densely-overlapping Cell Instance Segmentation via Adjacency-aware Collaborative Coloring
Feb 05, 2026Accurate cell instance segmentation is foundational for digital pathology analysis. Existing methods based on contour detection and distance mapping still face significant challenges in processing complex and dense cellular regions. Graph coloring-based methods provide a new paradigm for this task, yet the effectiveness of this paradigm in real-world scenarios with dense overlaps and complex topologies has not been verified. Addressing this issue, we release a large-scale dataset GBC-FS 2025, which contains highly complex and dense sub-cellular nuclear arrangements. We conduct the first systematic analysis of the chromatic properties of cell adjacency graphs across four diverse datasets and reveal an important discovery: most real-world cell graphs are non-bipartite, with a high prevalence of odd-length cycles (predominantly triangles). This makes simple 2-coloring theory insufficient for handling complex tissues, while higher-chromaticity models would cause representational redundancy and optimization difficulties. Building on this observation of complex real-world contexts, we propose Disco (Densely-overlapping Cell Instance Segmentation via Adjacency-aware COllaborative Coloring), an adjacency-aware framework based on the "divide and conquer" principle. It uniquely combines a data-driven topological labeling strategy with a constrained deep learning system to resolve complex adjacency conflicts. First, "Explicit Marking" strategy transforms the topological challenge into a learnable classification task by recursively decomposing the cell graph and isolating a "conflict set." Second, "Implicit Disambiguation" mechanism resolves ambiguities in conflict regions by enforcing feature dissimilarity between different instances, enabling the model to learn separable feature representations.
Modality Alignment across Trees on Heterogeneous Hyperbolic Manifolds
Oct 31, 2025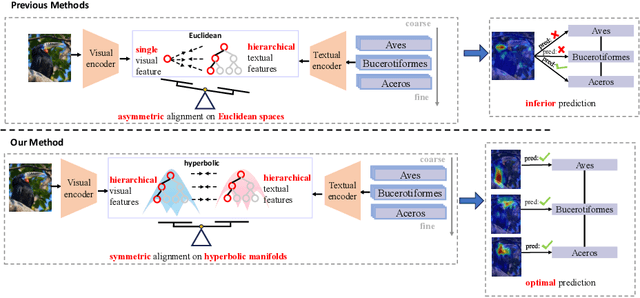
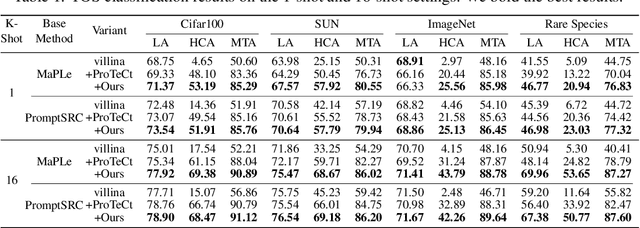
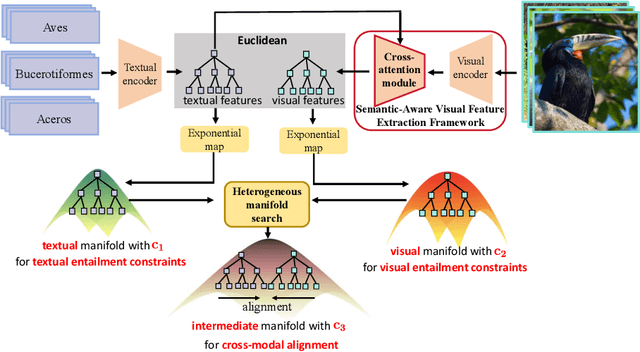

Modality alignment is critical for vision-language models (VLMs) to effectively integrate information across modalities. However, existing methods extract hierarchical features from text while representing each image with a single feature, leading to asymmetric and suboptimal alignment. To address this, we propose Alignment across Trees, a method that constructs and aligns tree-like hierarchical features for both image and text modalities. Specifically, we introduce a semantic-aware visual feature extraction framework that applies a cross-attention mechanism to visual class tokens from intermediate Transformer layers, guided by textual cues to extract visual features with coarse-to-fine semantics. We then embed the feature trees of the two modalities into hyperbolic manifolds with distinct curvatures to effectively model their hierarchical structures. To align across the heterogeneous hyperbolic manifolds with different curvatures, we formulate a KL distance measure between distributions on heterogeneous manifolds, and learn an intermediate manifold for manifold alignment by minimizing the distance. We prove the existence and uniqueness of the optimal intermediate manifold. Experiments on taxonomic open-set classification tasks across multiple image datasets demonstrate that our method consistently outperforms strong baselines under few-shot and cross-domain settings.
EffLoc: Lightweight Vision Transformer for Efficient 6-DOF Camera Relocalization
Feb 21, 2024



Camera relocalization is pivotal in computer vision, with applications in AR, drones, robotics, and autonomous driving. It estimates 3D camera position and orientation (6-DoF) from images. Unlike traditional methods like SLAM, recent strides use deep learning for direct end-to-end pose estimation. We propose EffLoc, a novel efficient Vision Transformer for single-image camera relocalization. EffLoc's hierarchical layout, memory-bound self-attention, and feed-forward layers boost memory efficiency and inter-channel communication. Our introduced sequential group attention (SGA) module enhances computational efficiency by diversifying input features, reducing redundancy, and expanding model capacity. EffLoc excels in efficiency and accuracy, outperforming prior methods, such as AtLoc and MapNet. It thrives on large-scale outdoor car-driving scenario, ensuring simplicity, end-to-end trainability, and eliminating handcrafted loss functions.
CI-Net: Contextual Information for Joint Semantic Segmentation and Depth Estimation
Jul 29, 2021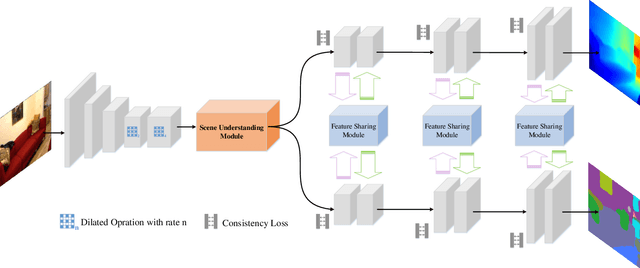
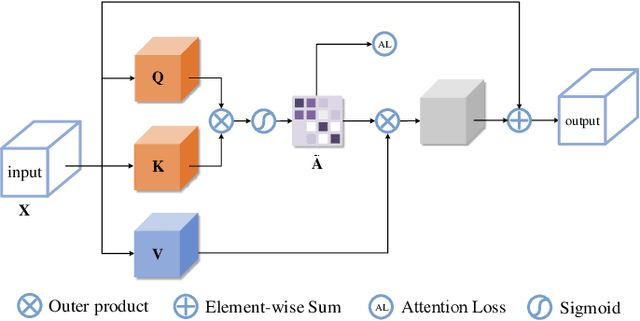
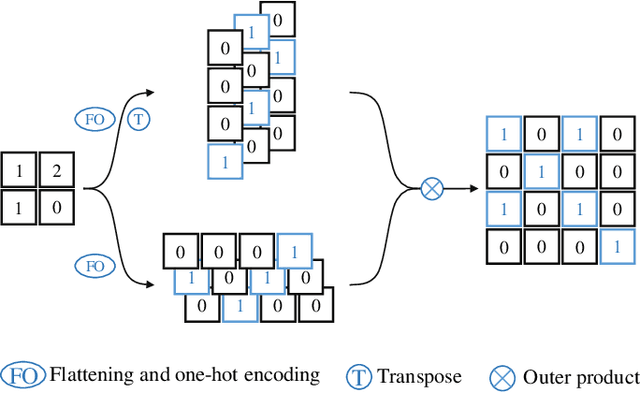
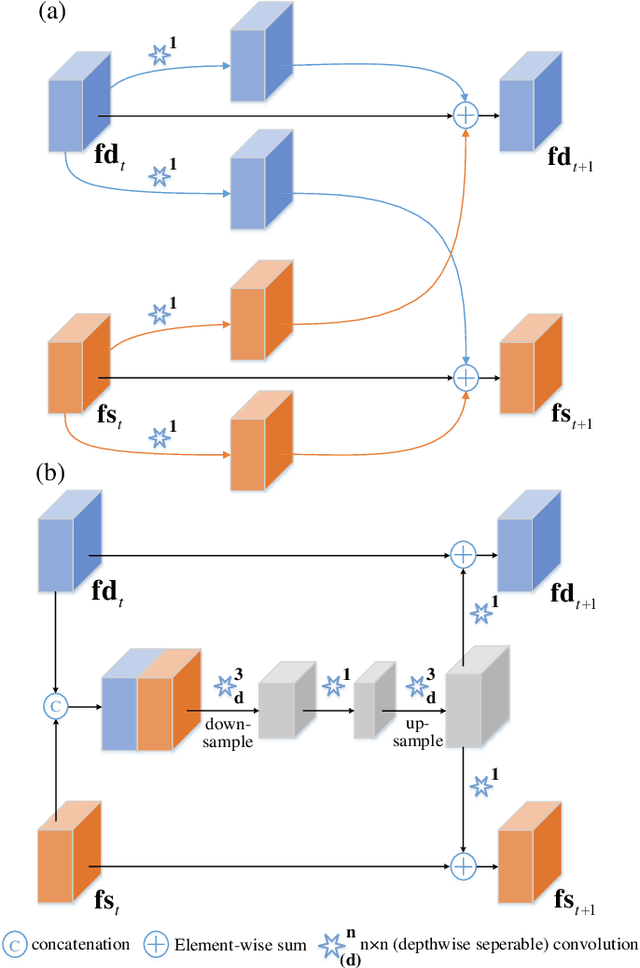
Monocular depth estimation and semantic segmentation are two fundamental goals of scene understanding. Due to the advantages of task interaction, many works study the joint task learning algorithm. However, most existing methods fail to fully leverage the semantic labels, ignoring the provided context structures and only using them to supervise the prediction of segmentation split. In this paper, we propose a network injected with contextual information (CI-Net) to solve the problem. Specifically, we introduce self-attention block in the encoder to generate attention map. With supervision from the ground truth created by semantic labels, the network is embedded with contextual information so that it could understand the scene better, utilizing dependent features to make accurate prediction. Besides, a feature sharing module is constructed to make the task-specific features deeply fused and a consistency loss is devised to make the features mutually guided. We evaluate the proposed CI-Net on the NYU-Depth-v2 and SUN-RGBD datasets. The experimental results validate that our proposed CI-Net is competitive with the state-of-the-arts.
Video Affective Effects Prediction with Multi-modal Fusion and Shot-Long Temporal Context
Sep 01, 2019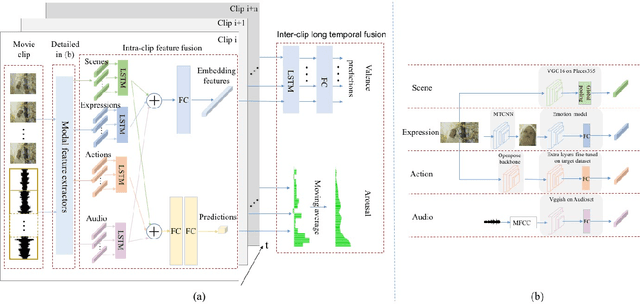
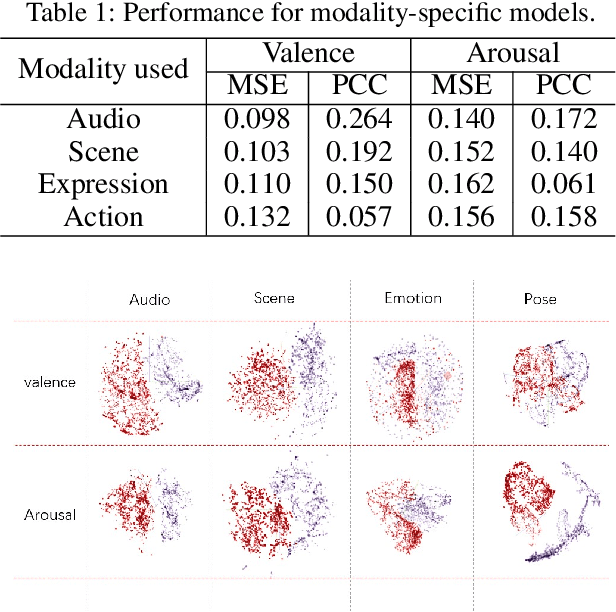
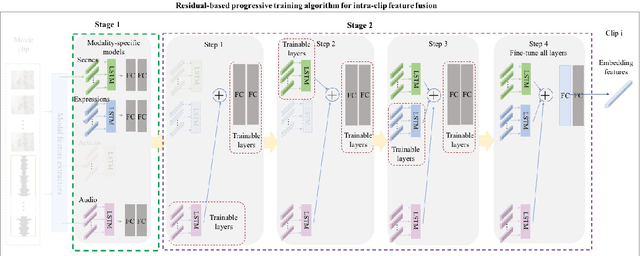
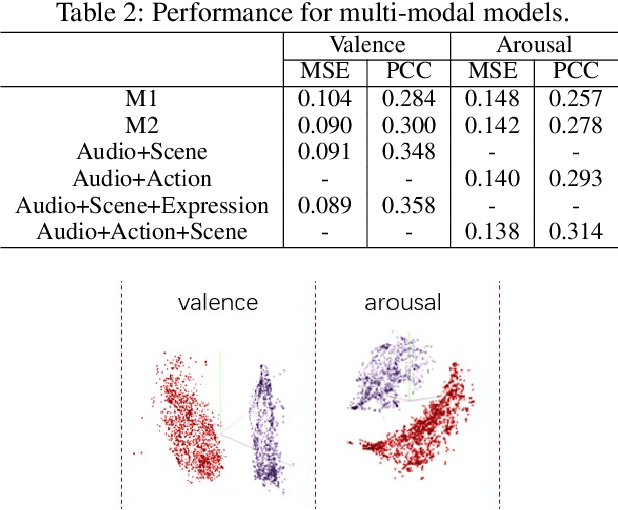
Predicting the emotional impact of videos using machine learning is a challenging task considering the varieties of modalities, the complicated temporal contex of the video as well as the time dependency of the emotional states. Feature extraction, multi-modal fusion and temporal context fusion are crucial stages for predicting valence and arousal values in the emotional impact, but have not been successfully exploited. In this paper, we propose a comprehensive framework with novel designs of modal structure and multi-modal fusion strategy. We select the most suitable modalities for valence and arousal tasks respectively and each modal feature is extracted using the modality-specific pre-trained deep model on large generic dataset. Two-time-scale structures, one for the intra-clip and the other for the inter-clip, are proposed to capture the temporal dependency of video content and emotion states. To combine the complementary information from multiple modalities, an effective and efficient residual-based progressive training strategy is proposed. Each modality is step-wisely combined into the multi-modal model, responsible for completing the missing parts of features. With all those improvements above, our proposed prediction framework achieves better performance on the LIRIS-ACCEDE dataset with a large margin compared to the state-of-the-art.