 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtility Pole Fire Risk Inspection from 2D Street-Side Images
Jun 19, 2024In recent years, California's electrical grid has confronted mounting challenges stemming from aging infrastructure and a landscape increasingly susceptible to wildfires. This paper presents a comprehensive framework utilizing computer vision techniques to address wildfire risk within the state's electrical grid, with a particular focus on vulnerable utility poles. These poles are susceptible to fire outbreaks or structural failure during extreme weather events. The proposed pipeline harnesses readily available Google Street View imagery to identify utility poles and assess their proximity to surrounding vegetation, as well as to determine any inclination angles. The early detection of potential risks associated with utility poles is pivotal for forestalling wildfire ignitions and informing strategic investments, such as undergrounding vulnerable poles and powerlines. Moreover, this study underscores the significance of data-driven decision-making in bolstering grid resilience, particularly concerning Public Safety Power Shutoffs. By fostering collaboration among utilities, policymakers, and researchers, this pipeline aims to solidify the electric grid's resilience and safeguard communities against the escalating threat of wildfires.
SkyScript: A Large and Semantically Diverse Vision-Language Dataset for Remote Sensing
Dec 20, 2023



Remote sensing imagery, despite its broad applications in helping achieve Sustainable Development Goals and tackle climate change, has not yet benefited from the recent advancements of versatile, task-agnostic vision language models (VLMs). A key reason is that the large-scale, semantically diverse image-text dataset required for developing VLMs is still absent for remote sensing images. Unlike natural images, remote sensing images and their associated text descriptions cannot be efficiently collected from the public Internet at scale. In this work, we bridge this gap by using geo-coordinates to automatically connect open, unlabeled remote sensing images with rich semantics covered in OpenStreetMap, and thus construct SkyScript, a comprehensive vision-language dataset for remote sensing images, comprising 2.6 million image-text pairs covering 29K distinct semantic tags. With continual pre-training on this dataset, we obtain a VLM that surpasses baseline models with a 6.2% average accuracy gain in zero-shot scene classification across seven benchmark datasets. It also demonstrates the ability of zero-shot transfer for fine-grained object attribute classification and cross-modal retrieval. We hope this dataset can support the advancement of VLMs for various multi-modal tasks in remote sensing, such as open-vocabulary classification, retrieval, captioning, and text-to-image synthesis.
Ice Monitoring in Swiss Lakes from Optical Satellites and Webcams using Machine Learning
Oct 27, 2020
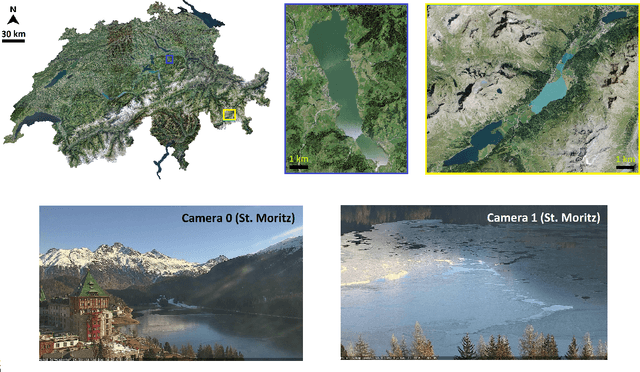

Continuous observation of climate indicators, such as trends in lake freezing, is important to understand the dynamics of the local and global climate system. Consequently, lake ice has been included among the Essential Climate Variables (ECVs) of the Global Climate Observing System (GCOS), and there is a need to set up operational monitoring capabilities. Multi-temporal satellite images and publicly available webcam streams are among the viable data sources to monitor lake ice. In this work we investigate machine learning-based image analysis as a tool to determine the spatio-temporal extent of ice on Swiss Alpine lakes as well as the ice-on and ice-off dates, from both multispectral optical satellite images (VIIRS and MODIS) and RGB webcam images. We model lake ice monitoring as a pixel-wise semantic segmentation problem, i.e., each pixel on the lake surface is classified to obtain a spatially explicit map of ice cover. We show experimentally that the proposed system produces consistently good results when tested on data from multiple winters and lakes. Our satellite-based method obtains mean Intersection-over-Union (mIoU) scores >93%, for both sensors. It also generalises well across lakes and winters with mIoU scores >78% and >80% respectively. On average, our webcam approach achieves mIoU values of 87% (approx.) and generalisation scores of 71% (approx.) and 69% (approx.) across different cameras and winters respectively. Additionally, we put forward a new benchmark dataset of webcam images (Photi-LakeIce) which includes data from two winters and three cameras.
Lake Ice Monitoring with Webcams and Crowd-Sourced Images
Feb 18, 2020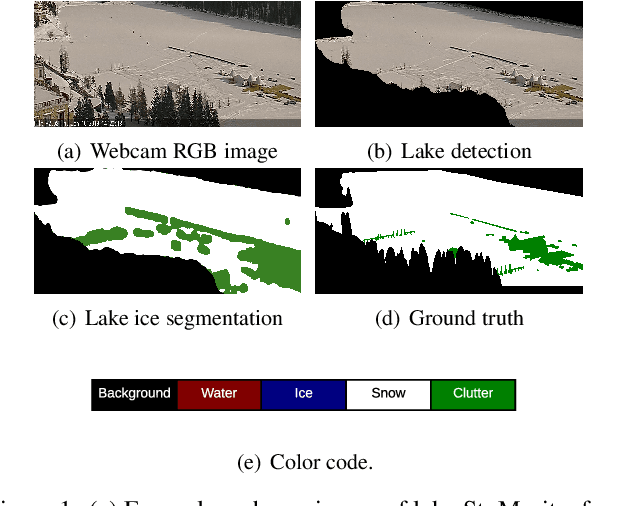
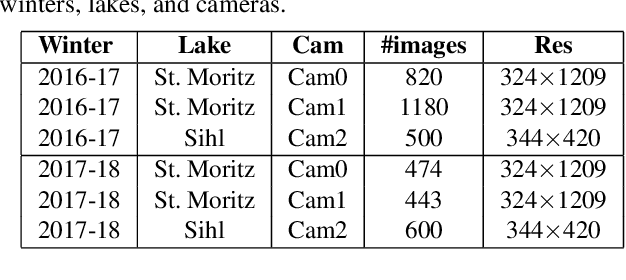

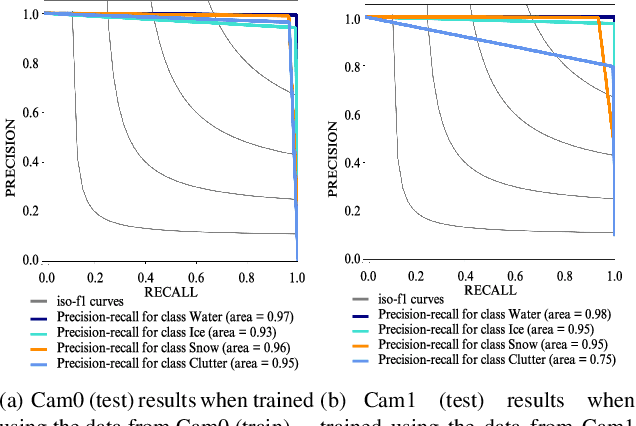
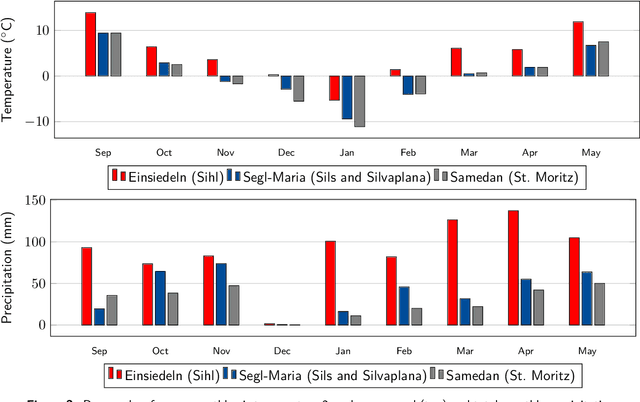
Lake ice is a strong climate indicator and has been recognised as part of the Essential Climate Variables (ECV) by the Global Climate Observing System (GCOS). The dynamics of freezing and thawing, and possible shifts of freezing patterns over time, can help in understanding the local and global climate systems. One way to acquire the spatio-temporal information about lake ice formation, independent of clouds, is to analyse webcam images. This paper intends to move towards a universal model for monitoring lake ice with freely available webcam data. We demonstrate good performance, including the ability to generalise across different winters and different lakes, with a state-of-the-art Convolutional Neural Network (CNN) model for semantic image segmentation, Deeplab v3+. Moreover, we design a variant of that model, termed Deep-U-Lab, which predicts sharper, more correct segmentation boundaries. We have tested the model's ability to generalise with data from multiple camera views and two different winters. On average, it achieves intersection-over-union (IoU) values of ~71% across different cameras and ~69% across different winters, greatly outperforming prior work. Going even further, we show that the model even achieves 60% IoU on arbitrary images scraped from photo-sharing web sites. As part of the work, we introduce a new benchmark dataset of webcam images, Photi-LakeIce, from multiple cameras and two different winters, along with pixel-wise ground truth annotations.