 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Reasoning and Action: Hybrid LLM-RL Framework for Efficient Cross-Domain Task-Oriented Dialogue
Apr 25, 2026Cross-domain task-oriented dialogue requires reasoning over implicit and explicit feasibility constraints while planning long-horizon, multi-turn actions. Large language models (LLMs) can infer such constraints but are unreliable over long horizons, while Reinforcement learning (RL) optimizes long-horizon behavior yet cannot recover constraints from raw dialogue. Naively coupling LLMs with RL is therefore brittle: unverified or unstructured LLM outputs can corrupt state representations and misguide policy learning. Motivated by this, we propose Verified LLM-Knowledge empowered RL (VLK-RL), a hybrid framework that makes LLM-derived constraint reasoning usable for RL. VLK-RL first elicits candidate constraints with an LLM and then verifies them via a dual-role cross-examination procedure to suppress hallucinations and cross-turn inconsistencies. The verified constraints are mapped into ontology-aligned slot-value representations, yielding a structured, constraint-aware state for RL policy optimization. Experiments across multiple benchmarks demonstrate that VLK-RL significantly improves generalization and robustness, outperforming strong single-model baselines on long-horizon tasks.
Less Languages, Less Tokens: An Efficient Unified Logic Cross-lingual Chain-of-Thought Reasoning Framework
Apr 22, 2026Cross-lingual chain-of-thought (XCoT) with self-consistency markedly enhances multilingual reasoning, yet existing methods remain costly due to extensive sampling of full trajectories across languages. Moreover, multilingual LLM representations vary strongly by language, hindering direct feature comparisons and effective pruning. Motivated by this, we introduce UL-XCoT, the first efficient unified logic cross-lingual reasoning framework that minimizes redundancy in token usage and latency, yielding the greatest efficiency under limited sampling budgets during inference. Specifically, UL-XCoT (1) achieves less languages by selecting, per query, a small candidate language set in a language-invariant unified logic space, (2) enables less tokens by monitoring logic-space trajectory dynamics during decoding to prune low-quality reasoning paths, and (3) aggregates the remaining high-quality trajectories via voting. Experiments on PolyMath across 18 languages and MMLU-ProX-Lite across 29 languages with DeepSeek-R1-DistillQwen-7B demonstrate that UL-XCoT achieves competitive accuracy while sharply cutting over 50% decoding token cost versus prior sampling baselines. UL-XCoT also delivers more stable gains on low-resource languages, underscoring consistently superior robustness where standard XCoT self-consistency method fails.
MaIL: Improving Imitation Learning with Mamba
Jun 12, 2024



This work introduces Mamba Imitation Learning (MaIL), a novel imitation learning (IL) architecture that offers a computationally efficient alternative to state-of-the-art (SoTA) Transformer policies. Transformer-based policies have achieved remarkable results due to their ability in handling human-recorded data with inherently non-Markovian behavior. However, their high performance comes with the drawback of large models that complicate effective training. While state space models (SSMs) have been known for their efficiency, they were not able to match the performance of Transformers. Mamba significantly improves the performance of SSMs and rivals against Transformers, positioning it as an appealing alternative for IL policies. MaIL leverages Mamba as a backbone and introduces a formalism that allows using Mamba in the encoder-decoder structure. This formalism makes it a versatile architecture that can be used as a standalone policy or as part of a more advanced architecture, such as a diffuser in the diffusion process. Extensive evaluations on the LIBERO IL benchmark and three real robot experiments show that MaIL: i) outperforms Transformers in all LIBERO tasks, ii) achieves good performance even with small datasets, iii) is able to effectively process multi-modal sensory inputs, iv) is more robust to input noise compared to Transformers.
HC$^2$L: Hybrid and Cooperative Contrastive Learning for Cross-lingual Spoken Language Understanding
May 10, 2024State-of-the-art model for zero-shot cross-lingual spoken language understanding performs cross-lingual unsupervised contrastive learning to achieve the label-agnostic semantic alignment between each utterance and its code-switched data. However, it ignores the precious intent/slot labels, whose label information is promising to help capture the label-aware semantics structure and then leverage supervised contrastive learning to improve both source and target languages' semantics. In this paper, we propose Hybrid and Cooperative Contrastive Learning to address this problem. Apart from cross-lingual unsupervised contrastive learning, we design a holistic approach that exploits source language supervised contrastive learning, cross-lingual supervised contrastive learning and multilingual supervised contrastive learning to perform label-aware semantics alignments in a comprehensive manner. Each kind of supervised contrastive learning mechanism includes both single-task and joint-task scenarios. In our model, one contrastive learning mechanism's input is enhanced by others. Thus the total four contrastive learning mechanisms are cooperative to learn more consistent and discriminative representations in the virtuous cycle during the training process. Experiments show that our model obtains consistent improvements over 9 languages, achieving new state-of-the-art performance.
Exploiting Contextual Target Attributes for Target Sentiment Classification
Dec 21, 2023



Existing PTLM-based models for TSC can be categorized into two groups: 1) fine-tuning-based models that adopt PTLM as the context encoder; 2) prompting-based models that transfer the classification task to the text/word generation task. In this paper, we present a new perspective of leveraging PTLM for TSC: simultaneously leveraging the merits of both language modeling and explicit target-context interactions via contextual target attributes. Specifically, we design the domain- and target-constrained cloze test, which can leverage the PTLMs' strong language modeling ability to generate the given target's attributes pertaining to the review context. The attributes contain the background and property information of the target, which can help to enrich the semantics of the review context and the target. To exploit the attributes for tackling TSC, we first construct a heterogeneous information graph by treating the attributes as nodes and combining them with (1) the syntax graph automatically produced by the off-the-shelf dependency parser and (2) the semantics graph of the review context, which is derived from the self-attention mechanism. Then we propose a heterogeneous information gated graph convolutional network to model the interactions among the attribute information, the syntactic information, and the contextual information. The experimental results on three benchmark datasets demonstrate the superiority of our model, which achieves new state-of-the-art performance.
Co-guiding for Multi-intent Spoken Language Understanding
Nov 22, 2023Recent graph-based models for multi-intent SLU have obtained promising results through modeling the guidance from the prediction of intents to the decoding of slot filling. However, existing methods (1) only model the unidirectional guidance from intent to slot, while there are bidirectional inter-correlations between intent and slot; (2) adopt homogeneous graphs to model the interactions between the slot semantics nodes and intent label nodes, which limit the performance. In this paper, we propose a novel model termed Co-guiding Net, which implements a two-stage framework achieving the mutual guidances between the two tasks. In the first stage, the initial estimated labels of both tasks are produced, and then they are leveraged in the second stage to model the mutual guidances. Specifically, we propose two heterogeneous graph attention networks working on the proposed two heterogeneous semantics label graphs, which effectively represent the relations among the semantics nodes and label nodes. Besides, we further propose Co-guiding-SCL Net, which exploits the single-task and dual-task semantics contrastive relations. For the first stage, we propose single-task supervised contrastive learning, and for the second stage, we propose co-guiding supervised contrastive learning, which considers the two tasks' mutual guidances in the contrastive learning procedure. Experiment results on multi-intent SLU show that our model outperforms existing models by a large margin, obtaining a relative improvement of 21.3% over the previous best model on MixATIS dataset in overall accuracy. We also evaluate our model on the zero-shot cross-lingual scenario and the results show that our model can relatively improve the state-of-the-art model by 33.5% on average in terms of overall accuracy for the total 9 languages.
Relational Temporal Graph Reasoning for Dual-task Dialogue Language Understanding
Jun 15, 2023



Dual-task dialog language understanding aims to tackle two correlative dialog language understanding tasks simultaneously via leveraging their inherent correlations. In this paper, we put forward a new framework, whose core is relational temporal graph reasoning.We propose a speaker-aware temporal graph (SATG) and a dual-task relational temporal graph (DRTG) to facilitate relational temporal modeling in dialog understanding and dual-task reasoning. Besides, different from previous works that only achieve implicit semantics-level interactions, we propose to model the explicit dependencies via integrating prediction-level interactions. To implement our framework, we first propose a novel model Dual-tAsk temporal Relational rEcurrent Reasoning network (DARER), which first generates the context-, speaker- and temporal-sensitive utterance representations through relational temporal modeling of SATG, then conducts recurrent dual-task relational temporal graph reasoning on DRTG, in which process the estimated label distributions act as key clues in prediction-level interactions. And the relational temporal modeling in DARER is achieved by relational convolutional networks (RGCNs). Then we further propose Relational Temporal Transformer (ReTeFormer), which achieves fine-grained relational temporal modeling via Relation- and Structure-aware Disentangled Multi-head Attention. Accordingly, we propose DARER with ReTeFormer (DARER2), which adopts two variants of ReTeFormer to achieve the relational temporal modeling of SATG and DTRG, respectively. The extensive experiments on different scenarios verify that our models outperform state-of-the-art models by a large margin. Remarkably, on the dialog sentiment classification task in the Mastodon dataset, DARER and DARER2 gain relative improvements of about 28% and 34% over the previous best model in terms of F1.
Co-evolving Graph Reasoning Network for Emotion-Cause Pair Extraction
Jun 07, 2023



Emotion-Cause Pair Extraction (ECPE) aims to extract all emotion clauses and their corresponding cause clauses from a document. Existing approaches tackle this task through multi-task learning (MTL) framework in which the two subtasks provide indicative clues for ECPE. However, the previous MTL framework considers only one round of multi-task reasoning and ignores the reverse feedbacks from ECPE to the subtasks. Besides, its multi-task reasoning only relies on semantics-level interactions, which cannot capture the explicit dependencies, and both the encoder sharing and multi-task hidden states concatenations can hardly capture the causalities. To solve these issues, we first put forward a new MTL framework based on Co-evolving Reasoning. It (1) models the bidirectional feedbacks between ECPE and its subtasks; (2) allows the three tasks to evolve together and prompt each other recurrently; (3) integrates prediction-level interactions to capture explicit dependencies. Then we propose a novel multi-task relational graph (MRG) to sufficiently exploit the causal relations. Finally, we propose a Co-evolving Graph Reasoning Network (CGR-Net) that implements our MTL framework and conducts Co-evolving Reasoning on MRG. Experimental results show that our model achieves new state-of-the-art performance, and further analysis confirms the advantages of our method.
Co-guiding Net: Achieving Mutual Guidances between Multiple Intent Detection and Slot Filling via Heterogeneous Semantics-Label Graphs
Oct 19, 2022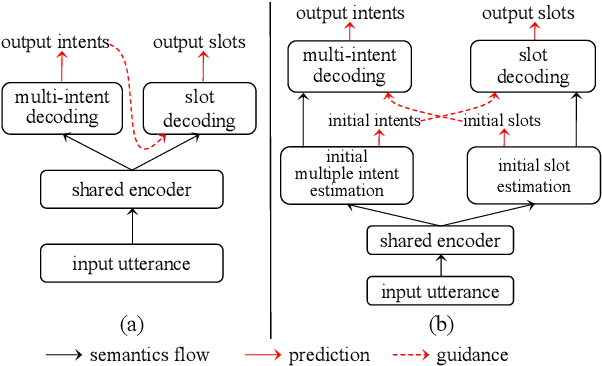
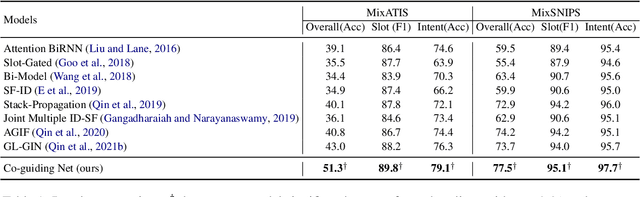
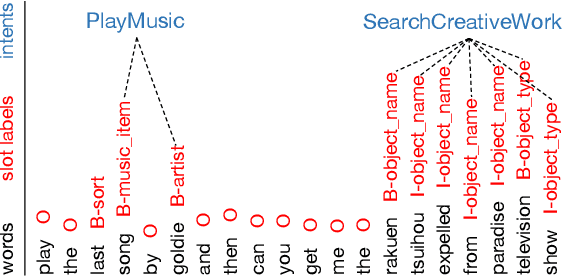
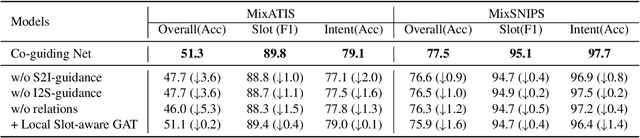
Recent graph-based models for joint multiple intent detection and slot filling have obtained promising results through modeling the guidance from the prediction of intents to the decoding of slot filling. However, existing methods (1) only model the \textit{unidirectional guidance} from intent to slot; (2) adopt \textit{homogeneous graphs} to model the interactions between the slot semantics nodes and intent label nodes, which limit the performance. In this paper, we propose a novel model termed Co-guiding Net, which implements a two-stage framework achieving the \textit{mutual guidances} between the two tasks. In the first stage, the initial estimated labels of both tasks are produced, and then they are leveraged in the second stage to model the mutual guidances. Specifically, we propose two \textit{heterogeneous graph attention networks} working on the proposed two \textit{heterogeneous semantics-label graphs}, which effectively represent the relations among the semantics nodes and label nodes. Experiment results show that our model outperforms existing models by a large margin, obtaining a relative improvement of 19.3\% over the previous best model on MixATIS dataset in overall accuracy.
Group is better than individual: Exploiting Label Topologies and Label Relations for Joint Multiple Intent Detection and Slot Filling
Oct 19, 2022
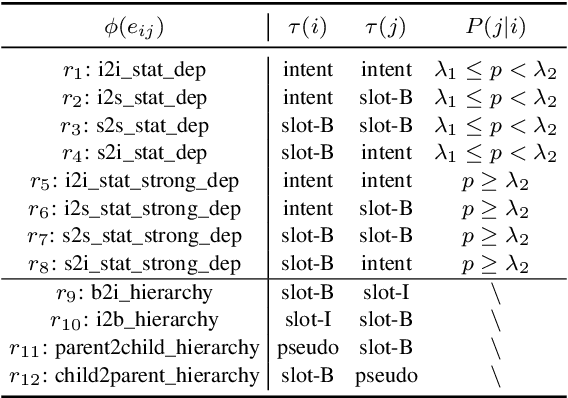
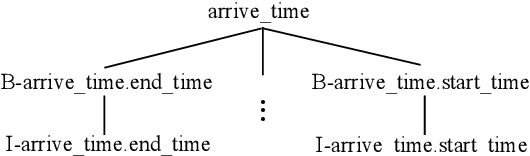
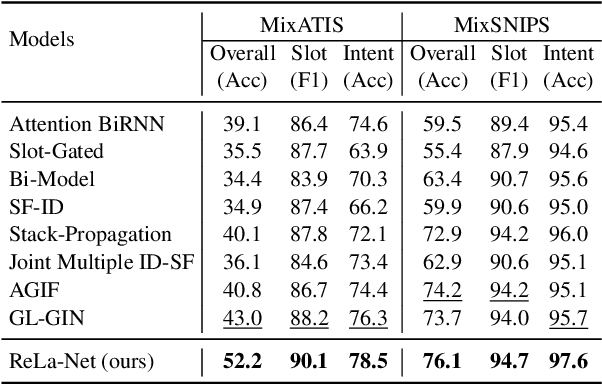
Recent joint multiple intent detection and slot filling models employ label embeddings to achieve the semantics-label interactions. However, they treat all labels and label embeddings as uncorrelated individuals, ignoring the dependencies among them. Besides, they conduct the decoding for the two tasks independently, without leveraging the correlations between them. Therefore, in this paper, we first construct a Heterogeneous Label Graph (HLG) containing two kinds of topologies: (1) statistical dependencies based on labels' co-occurrence patterns and hierarchies in slot labels; (2) rich relations among the label nodes. Then we propose a novel model termed ReLa-Net. It can capture beneficial correlations among the labels from HLG. The label correlations are leveraged to enhance semantic-label interactions. Moreover, we also propose the label-aware inter-dependent decoding mechanism to further exploit the label correlations for decoding. Experiment results show that our ReLa-Net significantly outperforms previous models. Remarkably, ReLa-Net surpasses the previous best model by over 20\% in terms of overall accuracy on MixATIS dataset.