 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Recommendation": models, code, and papers
Sequential Recommendation on Temporal Proximities with Contrastive Learning and Self-Attention
Feb 18, 2024
Sequential recommender systems identify user preferences from their past interactions to predict subsequent items optimally. Although traditional deep-learning-based models and modern transformer-based models in previous studies capture unidirectional and bidirectional patterns within user-item interactions, the importance of temporal contexts, such as individual behavioral and societal trend patterns, remains underexplored. Notably, recent models often neglect similarities in users' actions that occur implicitly among users during analogous timeframes-a concept we term vertical temporal proximity. These models primarily adapt the self-attention mechanisms of the transformer to consider the temporal context in individual user actions. Meanwhile, this adaptation still remains limited in considering the horizontal temporal proximity within item interactions, like distinguishing between subsequent item purchases within a week versus a month. To address these gaps, we propose a sequential recommendation model called TemProxRec, which includes contrastive learning and self-attention methods to consider temporal proximities both across and within user-item interactions. The proposed contrastive learning method learns representations of items selected in close temporal periods across different users to be close. Simultaneously, the proposed self-attention mechanism encodes temporal and positional contexts in a user sequence using both absolute and relative embeddings. This way, our TemProxRec accurately predicts the relevant items based on the user-item interactions within a specific timeframe. We validate this work through comprehensive experiments on TemProxRec, consistently outperforming existing models on benchmark datasets as well as showing the significance of considering the vertical and horizontal temporal proximities into sequential recommendation.
Pre-Trained Model Recommendation for Downstream Fine-tuning
Mar 11, 2024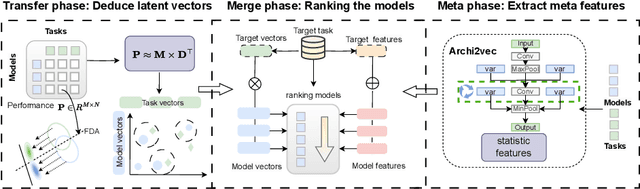
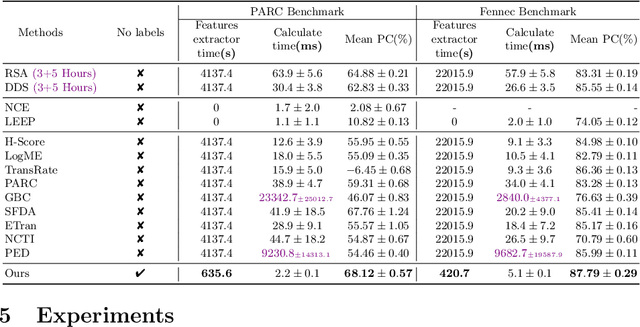
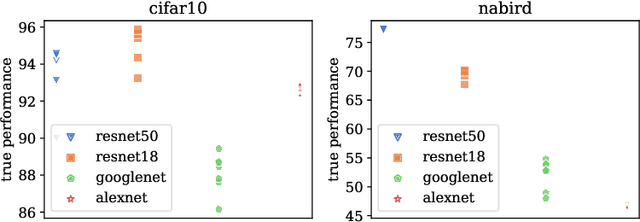
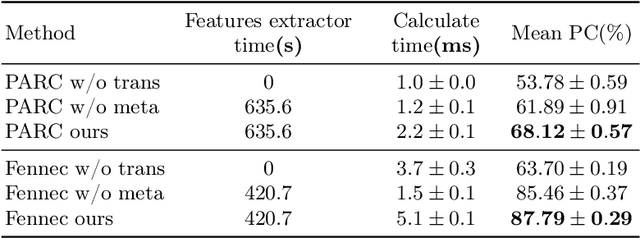
As a fundamental problem in transfer learning, model selection aims to rank off-the-shelf pre-trained models and select the most suitable one for the new target task. Existing model selection techniques are often constrained in their scope and tend to overlook the nuanced relationships between models and tasks. In this paper, we present a pragmatic framework \textbf{Fennec}, delving into a diverse, large-scale model repository while meticulously considering the intricate connections between tasks and models. The key insight is to map all models and historical tasks into a transfer-related subspace, where the distance between model vectors and task vectors represents the magnitude of transferability. A large vision model, as a proxy, infers a new task's representation in the transfer space, thereby circumventing the computational burden of extensive forward passes. We also investigate the impact of the inherent inductive bias of models on transfer results and propose a novel method called \textbf{archi2vec} to encode the intricate structures of models. The transfer score is computed through straightforward vector arithmetic with a time complexity of $\mathcal{O}(1)$. Finally, we make a substantial contribution to the field by releasing a comprehensive benchmark. We validate the effectiveness of our framework through rigorous testing on two benchmarks. The benchmark and the code will be publicly available in the near future.
Diffusion Cross-domain Recommendation
Feb 03, 2024It is always a challenge for recommender systems to give high-quality outcomes to cold-start users. One potential solution to alleviate the data sparsity problem for cold-start users in the target domain is to add data from the auxiliary domain. Finding a proper way to extract knowledge from an auxiliary domain and transfer it into a target domain is one of the main objectives for cross-domain recommendation (CDR) research. Among the existing methods, mapping approach is a popular one to implement cross-domain recommendation models (CDRs). For models of this type, a mapping module plays the role of transforming data from one domain to another. It primarily determines the performance of mapping approach CDRs. Recently, diffusion probability models (DPMs) have achieved impressive success for image synthesis related tasks. They involve recovering images from noise-added samples, which can be viewed as a data transformation process with outstanding performance. To further enhance the performance of CDRs, we first reveal the potential connection between DPMs and mapping modules of CDRs, and then propose a novel CDR model named Diffusion Cross-domain Recommendation (DiffCDR). More specifically, we first adopt the theory of DPM and design a Diffusion Module (DIM), which generates user's embedding in target domain. To reduce the negative impact of randomness introduced in DIM and improve the stability, we employ an Alignment Module to produce the aligned user embeddings. In addition, we consider the label data of the target domain and form the task-oriented loss function, which enables our DiffCDR to adapt to specific tasks. By conducting extensive experiments on datasets collected from reality, we demonstrate the effectiveness and adaptability of DiffCDR to outperform baseline models on various CDR tasks in both cold-start and warm-start scenarios.
Challenging Low Homophily in Social Recommendation
Jan 26, 2024Social relations are leveraged to tackle the sparsity issue of user-item interaction data in recommendation under the assumption of social homophily. However, social recommendation paradigms predominantly focus on homophily based on user preferences. While social information can enhance recommendations, its alignment with user preferences is not guaranteed, thereby posing the risk of introducing informational redundancy. We empirically discover that social graphs in real recommendation data exhibit low preference-aware homophily, which limits the effect of social recommendation models. To comprehensively extract preference-aware homophily information latent in the social graph, we propose Social Heterophily-alleviating Rewiring (SHaRe), a data-centric framework for enhancing existing graph-based social recommendation models. We adopt Graph Rewiring technique to capture and add highly homophilic social relations, and cut low homophilic (or heterophilic) relations. To better refine the user representations from reliable social relations, we integrate a contrastive learning method into the training of SHaRe, aiming to calibrate the user representations for enhancing the result of Graph Rewiring. Experiments on real-world datasets show that the proposed framework not only exhibits enhanced performances across varying homophily ratios but also improves the performance of existing state-of-the-art (SOTA) social recommendation models.
Intersectional Two-sided Fairness in Recommendation
Feb 15, 2024Fairness of recommender systems (RS) has attracted increasing attention recently. Based on the involved stakeholders, the fairness of RS can be divided into user fairness, item fairness, and two-sided fairness which considers both user and item fairness simultaneously. However, we argue that the intersectional two-sided unfairness may still exist even if the RS is two-sided fair, which is observed and shown by empirical studies on real-world data in this paper, and has not been well-studied previously. To mitigate this problem, we propose a novel approach called Intersectional Two-sided Fairness Recommendation (ITFR). Our method utilizes a sharpness-aware loss to perceive disadvantaged groups, and then uses collaborative loss balance to develop consistent distinguishing abilities for different intersectional groups. Additionally, predicted score normalization is leveraged to align positive predicted scores to fairly treat positives in different intersectional groups. Extensive experiments and analyses on three public datasets show that our proposed approach effectively alleviates the intersectional two-sided unfairness and consistently outperforms previous state-of-the-art methods.
A Survey of Route Recommendations: Methods, Applications, and Opportunities
Mar 01, 2024
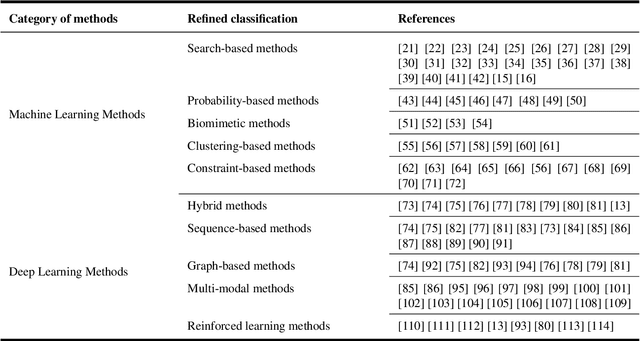
Nowadays, with advanced information technologies deployed citywide, large data volumes and powerful computational resources are intelligentizing modern city development. As an important part of intelligent transportation, route recommendation and its applications are widely used, directly influencing citizens` travel habits. Developing smart and efficient travel routes based on big data (possibly multi-modal) has become a central challenge in route recommendation research. Our survey offers a comprehensive review of route recommendation work based on urban computing. It is organized by the following three parts: 1) Methodology-wise. We categorize a large volume of traditional machine learning and modern deep learning methods. Also, we discuss their historical relations and reveal the edge-cutting progress. 2) Application\-wise. We present numerous novel applications related to route commendation within urban computing scenarios. 3) We discuss current problems and challenges and envision several promising research directions. We believe that this survey can help relevant researchers quickly familiarize themselves with the current state of route recommendation research and then direct them to future research trends.
Fairly Evaluating Large Language Model-based Recommendation Needs Revisit the Cross-Entropy Loss
Feb 09, 2024Large language models (LLMs) have gained much attention in the recommendation community; some studies have observed that LLMs, fine-tuned by the cross-entropy loss with a full softmax, could achieve state-of-the-art performance already. However, these claims are drawn from unobjective and unfair comparisons. In view of the substantial quantity of items in reality, conventional recommenders typically adopt a pointwise/pairwise loss function instead for training. This substitute however causes severe performance degradation, leading to under-estimation of conventional methods and over-confidence in the ranking capability of LLMs. In this work, we theoretically justify the superiority of cross-entropy, and showcase that it can be adequately replaced by some elementary approximations with certain necessary modifications. The remarkable results across three public datasets corroborate that even in a practical sense, existing LLM-based methods are not as effective as claimed for next-item recommendation. We hope that these theoretical understandings in conjunction with the empirical results will facilitate an objective evaluation of LLM-based recommendation in the future.
Discrete Semantic Tokenization for Deep CTR Prediction
Mar 13, 2024Incorporating item content information into click-through rate (CTR) prediction models remains a challenge, especially with the time and space constraints of industrial scenarios. The content-encoding paradigm, which integrates user and item encoders directly into CTR models, prioritizes space over time. In contrast, the embedding-based paradigm transforms item and user semantics into latent embeddings and then caches them, prioritizes space over time. In this paper, we introduce a new semantic-token paradigm and propose a discrete semantic tokenization approach, namely UIST, for user and item representation. UIST facilitates swift training and inference while maintaining a conservative memory footprint. Specifically, UIST quantizes dense embedding vectors into discrete tokens with shorter lengths and employs a hierarchical mixture inference module to weigh the contribution of each user--item token pair. Our experimental results on news recommendation showcase the effectiveness and efficiency (about 200-fold space compression) of UIST for CTR prediction.
Aligning GPTRec with Beyond-Accuracy Goals with Reinforcement Learning
Mar 07, 2024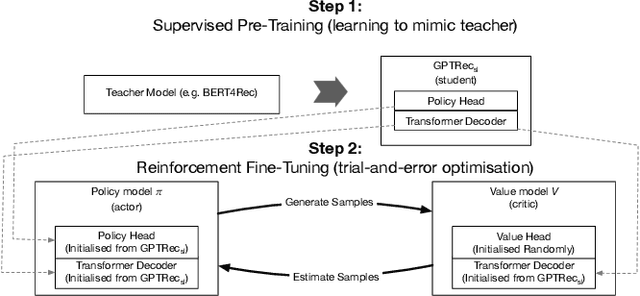
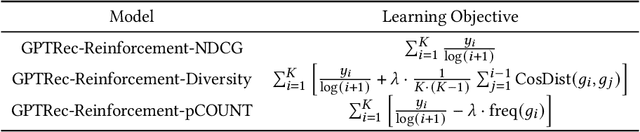
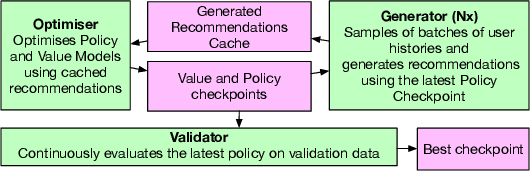

Adaptations of Transformer models, such as BERT4Rec and SASRec, achieve state-of-the-art performance in the sequential recommendation task according to accuracy-based metrics, such as NDCG. These models treat items as tokens and then utilise a score-and-rank approach (Top-K strategy), where the model first computes item scores and then ranks them according to this score. While this approach works well for accuracy-based metrics, it is hard to use it for optimising more complex beyond-accuracy metrics such as diversity. Recently, the GPTRec model, which uses a different Next-K strategy, has been proposed as an alternative to the Top-K models. In contrast with traditional Top-K recommendations, Next-K generates recommendations item-by-item and, therefore, can account for complex item-to-item interdependencies important for the beyond-accuracy measures. However, the original GPTRec paper focused only on accuracy in experiments and needed to address how to optimise the model for complex beyond-accuracy metrics. Indeed, training GPTRec for beyond-accuracy goals is challenging because the interaction training data available for training recommender systems typically needs to be aligned with beyond-accuracy recommendation goals. To solve the misalignment problem, we train GPTRec using a 2-stage approach: in the first stage, we use a teacher-student approach to train GPTRec, mimicking the behaviour of traditional Top-K models; in the second stage, we use Reinforcement Learning to align the model for beyond-accuracy goals. In particular, we experiment with increasing recommendation diversity and reducing popularity bias. Our experiments on two datasets show that in 3 out of 4 cases, GPTRec's Next-K generation approach offers a better tradeoff between accuracy and secondary metrics than classic greedy re-ranking techniques.
RA-Rec: An Efficient ID Representation Alignment Framework for LLM-based Recommendation
Feb 07, 2024Large language models (LLM) have recently emerged as a powerful tool for a variety of natural language processing tasks, bringing a new surge of combining LLM with recommendation systems, termed as LLM-based RS. Current approaches generally fall into two main paradigms, the ID direct usage paradigm and the ID translation paradigm, noting their core weakness stems from lacking recommendation knowledge and uniqueness. To address this limitation, we propose a new paradigm, ID representation, which incorporates pre-trained ID embeddings into LLMs in a complementary manner. In this work, we present RA-Rec, an efficient ID representation alignment framework for LLM-based recommendation, which is compatible with multiple ID-based methods and LLM architectures. Specifically, we treat ID embeddings as soft prompts and design an innovative alignment module and an efficient tuning method with tailored data construction for alignment. Extensive experiments demonstrate RA-Rec substantially outperforms current state-of-the-art methods, achieving up to 3.0% absolute HitRate@100 improvements while utilizing less than 10x training data.