 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reasoning over Hybrid Chain for Table-and-Text Open Domain QA
Jan 15, 2022

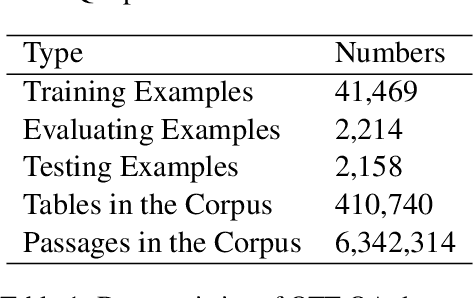
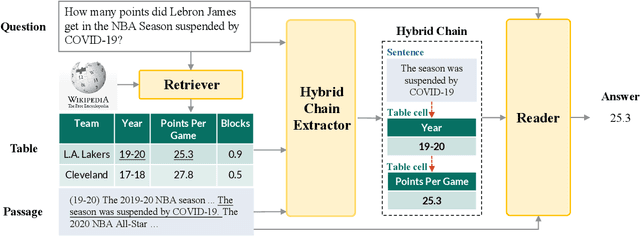
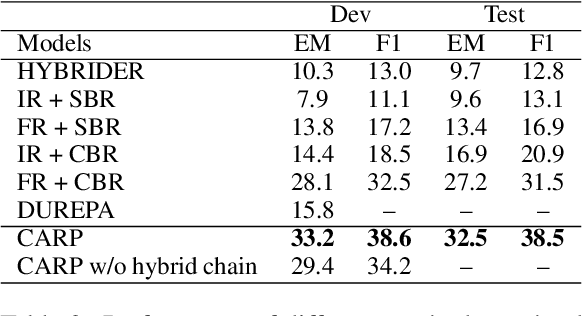
Tabular and textual question answering requires systems to perform reasoning over heterogeneous information, considering table structure, and the connections among table and text. In this paper, we propose a ChAin-centric Reasoning and Pre-training framework (CARP). CARP utilizes hybrid chain to model the explicit intermediate reasoning process across table and text for question answering. We also propose a novel chain-centric pre-training method, to enhance the pre-trained model in identifying the cross-modality reasoning process and alleviating the data sparsity problem. This method constructs the large-scale reasoning corpus by synthesizing pseudo heterogeneous reasoning paths from Wikipedia and generating corresponding questions. We evaluate our system on OTT-QA, a large-scale table-and-text open-domain question answering benchmark, and our system achieves the state-of-the-art performance. Further analyses illustrate that the explicit hybrid chain offers substantial performance improvement and interpretablity of the intermediate reasoning process, and the chain-centric pre-training boosts the performance on the chain extraction.
Computational-Statistical Gaps in Reinforcement Learning
Feb 11, 2022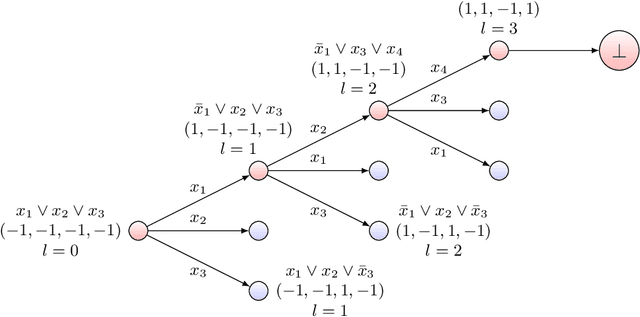
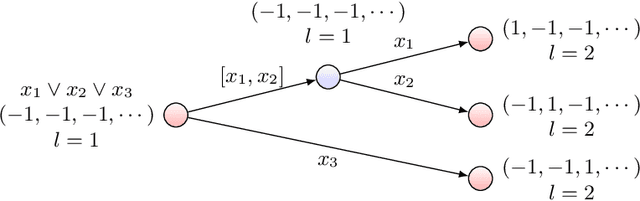
Reinforcement learning with function approximation has recently achieved tremendous results in applications with large state spaces. This empirical success has motivated a growing body of theoretical work proposing necessary and sufficient conditions under which efficient reinforcement learning is possible. From this line of work, a remarkably simple minimal sufficient condition has emerged for sample efficient reinforcement learning: MDPs with optimal value function $V^*$ and $Q^*$ linear in some known low-dimensional features. In this setting, recent works have designed sample efficient algorithms which require a number of samples polynomial in the feature dimension and independent of the size of state space. They however leave finding computationally efficient algorithms as future work and this is considered a major open problem in the community. In this work, we make progress on this open problem by presenting the first computational lower bound for RL with linear function approximation: unless NP=RP, no randomized polynomial time algorithm exists for deterministic transition MDPs with a constant number of actions and linear optimal value functions. To prove this, we show a reduction from Unique-Sat, where we convert a CNF formula into an MDP with deterministic transitions, constant number of actions and low dimensional linear optimal value functions. This result also exhibits the first computational-statistical gap in reinforcement learning with linear function approximation, as the underlying statistical problem is information-theoretically solvable with a polynomial number of queries, but no computationally efficient algorithm exists unless NP=RP. Finally, we also prove a quasi-polynomial time lower bound under the Randomized Exponential Time Hypothesis.
Spatio-Temporal Urban Knowledge Graph Enabled Mobility Prediction
Nov 01, 2021
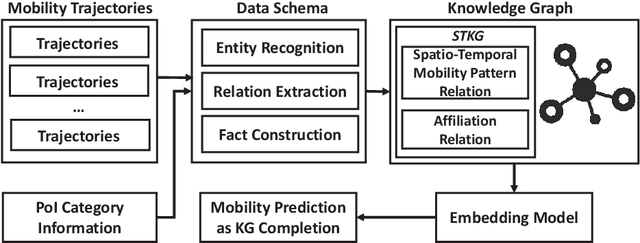

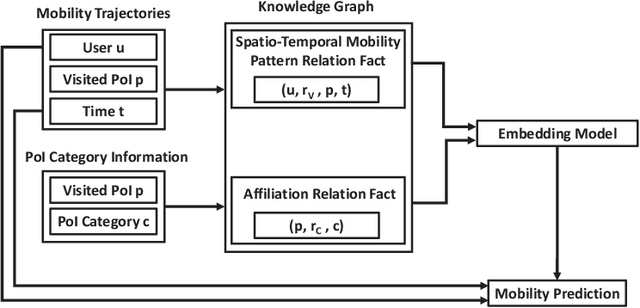
With the rapid development of the mobile communication technology, mobile trajectories of humans are massively collected by Internet service providers (ISPs) and application service providers (ASPs). On the other hand, the rising paradigm of knowledge graph (KG) provides us a promising solution to extract structured "knowledge" from massive trajectory data. In this paper, we focus on modeling users' spatio-temporal mobility patterns based on knowledge graph techniques, and predicting users' future movement based on the ``knowledge'' extracted from multiple sources in a cohesive manner. Specifically, we propose a new type of knowledge graph, i.e., spatio-temporal urban knowledge graph (STKG), where mobility trajectories, category information of venues, and temporal information are jointly modeled by the facts with different relation types in STKG. The mobility prediction problem is converted to the knowledge graph completion problem in STKG. Further, a complex embedding model with elaborately designed scoring functions is proposed to measure the plausibility of facts in STKG to solve the knowledge graph completion problem, which considers temporal dynamics of the mobility patterns and utilizes PoI categories as the auxiliary information and background knowledge. Extensive evaluations confirm the high accuracy of our model in predicting users' mobility, i.e., improving the accuracy by 5.04% compared with the state-of-the-art algorithms. In addition, PoI categories as the background knowledge and auxiliary information are confirmed to be helpful by improving the performance by 3.85% in terms of accuracy. Additionally, experiments show that our proposed method is time-efficient by reducing the computational time by over 43.12% compared with existing methods.
Factored couplings in multi-marginal optimal transport via difference of convex programming
Oct 18, 2021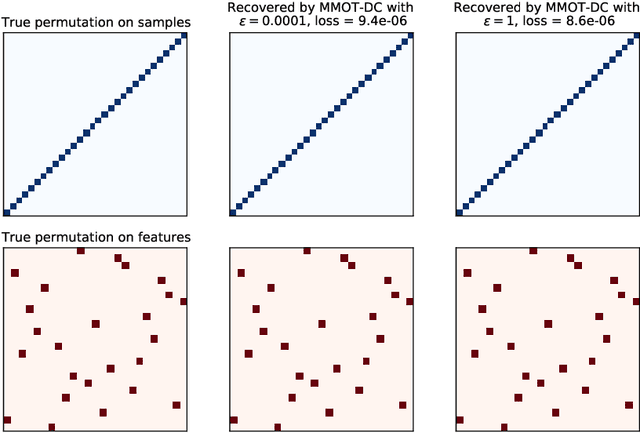
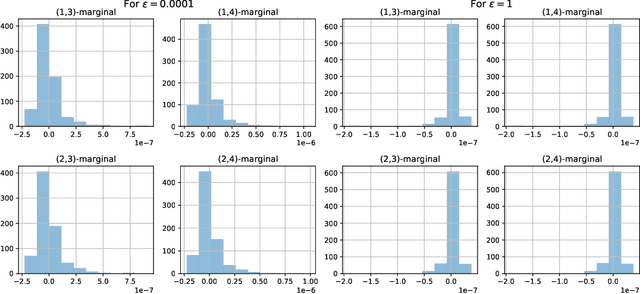
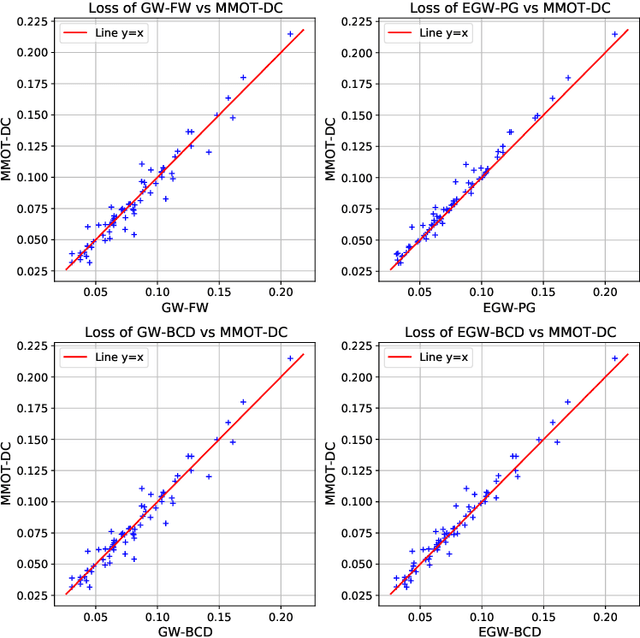
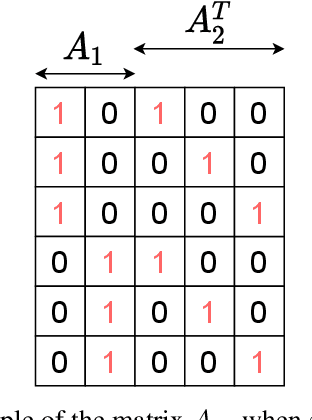
Optimal transport (OT) theory underlies many emerging machine learning (ML) methods nowadays solving a wide range of tasks such as generative modeling, transfer learning and information retrieval. These latter works, however, usually build upon a traditional OT setup with two distributions, while leaving a more general multi-marginal OT formulation somewhat unexplored. In this paper, we study the multi-marginal OT (MMOT) problem and unify several popular OT methods under its umbrella by promoting structural information on the coupling. We show that incorporating such structural information into MMOT results in an instance of a different of convex (DC) programming problem allowing us to solve it numerically. Despite high computational cost of the latter procedure, the solutions provided by DC optimization are usually as qualitative as those obtained using currently employed optimization schemes.
Understanding Knowledge Integration in Language Models with Graph Convolutions
Feb 07, 2022
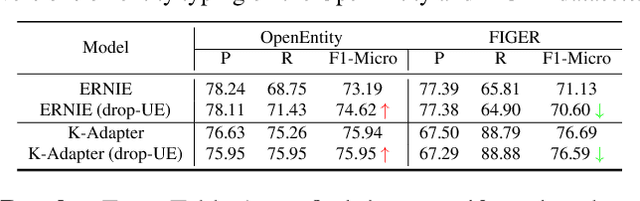
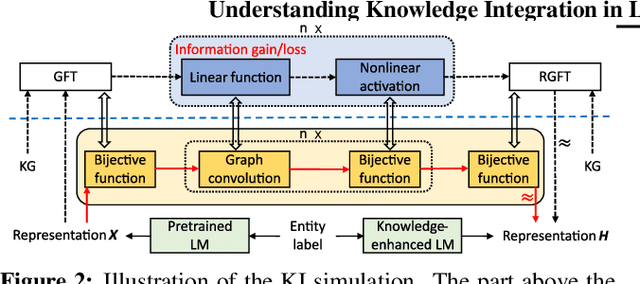
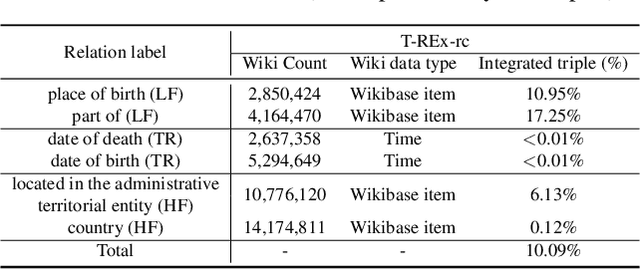
Pretrained language models (LMs) do not capture factual knowledge very well. This has led to the development of a number of knowledge integration (KI) methods which aim to incorporate external knowledge into pretrained LMs. Even though KI methods show some performance gains over vanilla LMs, the inner-workings of these methods are not well-understood. For instance, it is unclear how and what kind of knowledge is effectively integrated into these models and if such integration may lead to catastrophic forgetting of already learned knowledge. This paper revisits the KI process in these models with an information-theoretic view and shows that KI can be interpreted using a graph convolution operation. We propose a probe model called \textit{Graph Convolution Simulator} (GCS) for interpreting knowledge-enhanced LMs and exposing what kind of knowledge is integrated into these models. We conduct experiments to verify that our GCS can indeed be used to correctly interpret the KI process, and we use it to analyze two well-known knowledge-enhanced LMs: ERNIE and K-Adapter, and find that only a small amount of factual knowledge is integrated in them. We stratify knowledge in terms of various relation types and find that ERNIE and K-Adapter integrate different kinds of knowledge to different extent. Our analysis also shows that simply increasing the size of the KI corpus may not lead to better KI; fundamental advances may be needed.
Learn over Past, Evolve for Future: Search-based Time-aware Recommendation with Sequential Behavior Data
Feb 07, 2022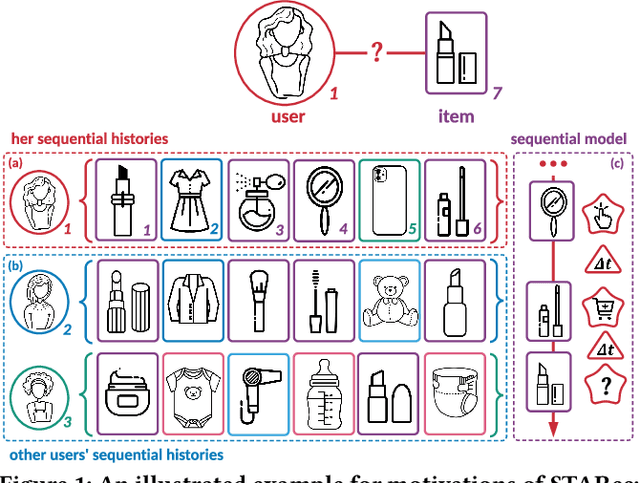
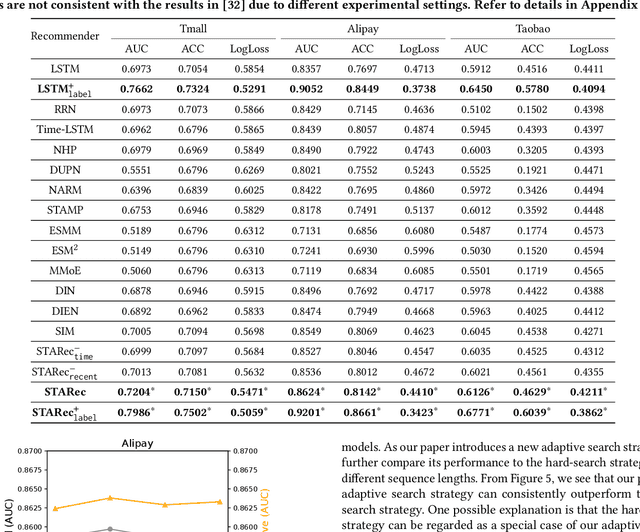
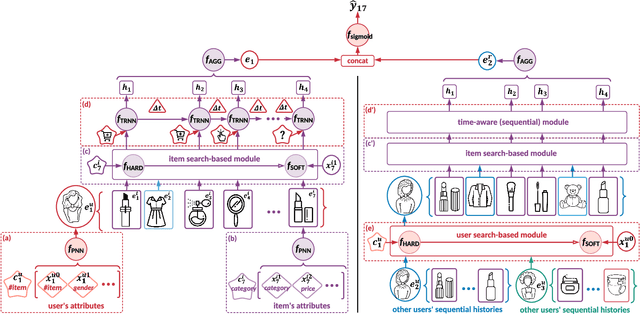
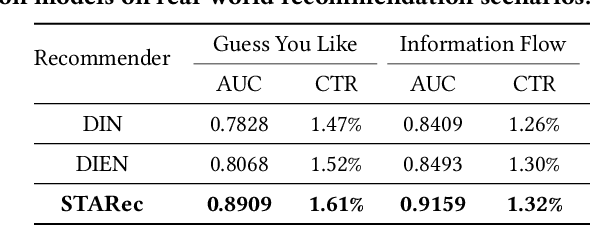
The personalized recommendation is an essential part of modern e-commerce, where user's demands are not only conditioned by their profile but also by their recent browsing behaviors as well as periodical purchases made some time ago. In this paper, we propose a novel framework named Search-based Time-Aware Recommendation (STARec), which captures the evolving demands of users over time through a unified search-based time-aware model. More concretely, we first design a search-based module to retrieve a user's relevant historical behaviors, which are then mixed up with her recent records to be fed into a time-aware sequential network for capturing her time-sensitive demands. Besides retrieving relevant information from her personal history, we also propose to search and retrieve similar user's records as an additional reference. All these sequential records are further fused to make the final recommendation. Beyond this framework, we also develop a novel label trick that uses the previous labels (i.e., user's feedbacks) as the input to better capture the user's browsing pattern. We conduct extensive experiments on three real-world commercial datasets on click-through-rate prediction tasks against state-of-the-art methods. Experimental results demonstrate the superiority and efficiency of our proposed framework and techniques. Furthermore, results of online experiments on a daily item recommendation platform of Company X show that STARec gains average performance improvement of around 6% and 1.5% in its two main item recommendation scenarios on CTR metric respectively.
Catch Me If You Hear Me: Audio-Visual Navigation in Complex Unmapped Environments with Moving Sounds
Nov 29, 2021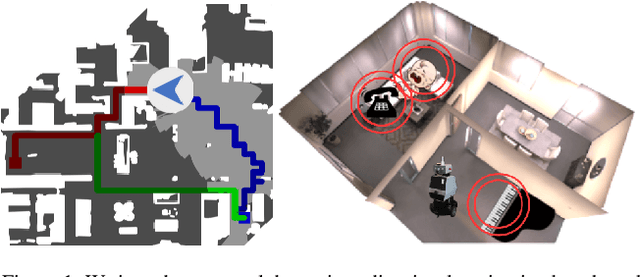
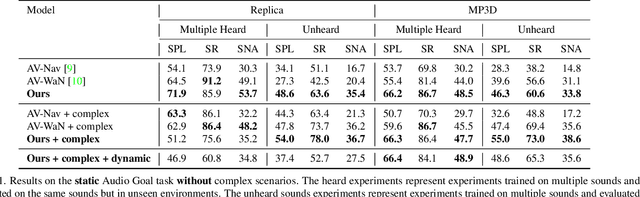
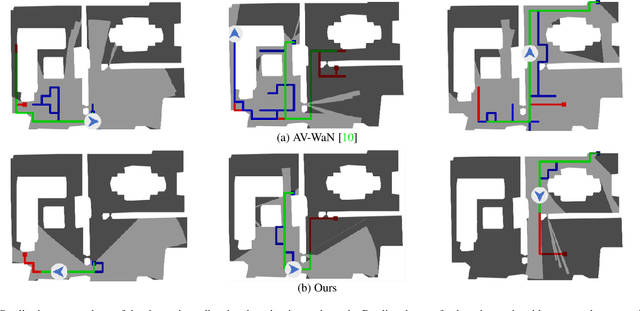
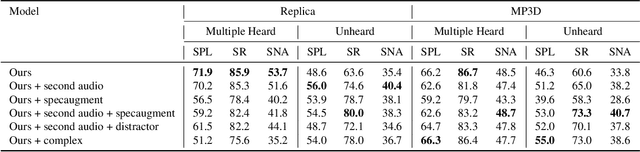
Audio-visual navigation combines sight and hearing to navigate to a sound-emitting source in an unmapped environment. While recent approaches have demonstrated the benefits of audio input to detect and find the goal, they focus on clean and static sound sources and struggle to generalize to unheard sounds. In this work, we propose the novel dynamic audio-visual navigation benchmark which requires to catch a moving sound source in an environment with noisy and distracting sounds. We introduce a reinforcement learning approach that learns a robust navigation policy for these complex settings. To achieve this, we propose an architecture that fuses audio-visual information in the spatial feature space to learn correlations of geometric information inherent in both local maps and audio signals. We demonstrate that our approach consistently outperforms the current state-of-the-art by a large margin across all tasks of moving sounds, unheard sounds, and noisy environments, on two challenging 3D scanned real-world environments, namely Matterport3D and Replica. The benchmark is available at http://dav-nav.cs.uni-freiburg.de.
Measuring Disparate Outcomes of Content Recommendation Algorithms with Distributional Inequality Metrics
Feb 03, 2022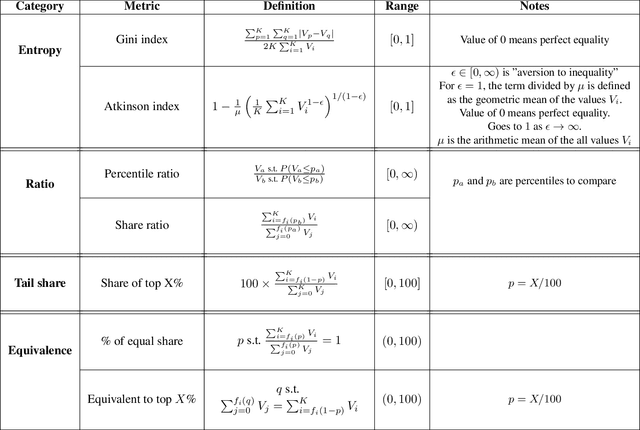
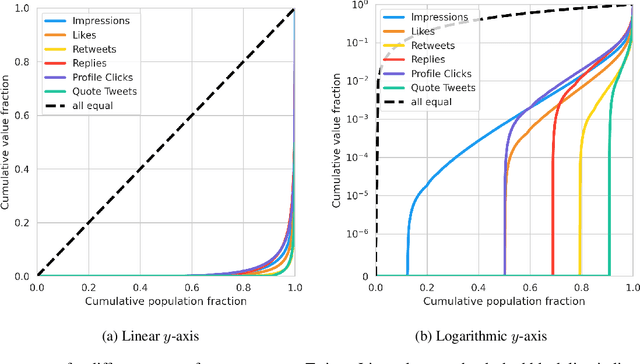
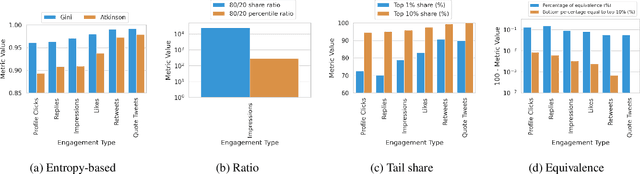
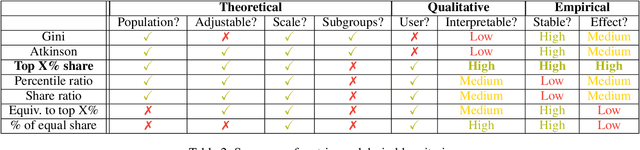
The harmful impacts of algorithmic decision systems have recently come into focus, with many examples of systems such as machine learning (ML) models amplifying existing societal biases. Most metrics attempting to quantify disparities resulting from ML algorithms focus on differences between groups, dividing users based on demographic identities and comparing model performance or overall outcomes between these groups. However, in industry settings, such information is often not available, and inferring these characteristics carries its own risks and biases. Moreover, typical metrics that focus on a single classifier's output ignore the complex network of systems that produce outcomes in real-world settings. In this paper, we evaluate a set of metrics originating from economics, distributional inequality metrics, and their ability to measure disparities in content exposure in a production recommendation system, the Twitter algorithmic timeline. We define desirable criteria for metrics to be used in an operational setting, specifically by ML practitioners. We characterize different types of engagement with content on Twitter using these metrics, and use these results to evaluate the metrics with respect to the desired criteria. We show that we can use these metrics to identify content suggestion algorithms that contribute more strongly to skewed outcomes between users. Overall, we conclude that these metrics can be useful tools for understanding disparate outcomes in online social networks.
Exploring Event-driven Dynamic Context for Accident Scene Segmentation
Dec 09, 2021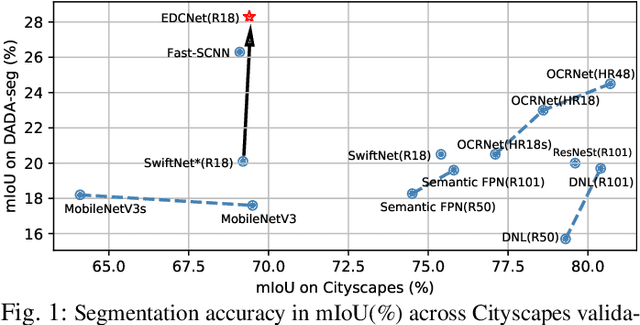


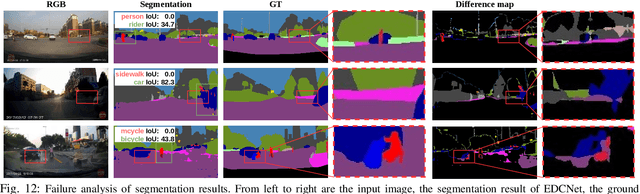
The robustness of semantic segmentation on edge cases of traffic scene is a vital factor for the safety of intelligent transportation. However, most of the critical scenes of traffic accidents are extremely dynamic and previously unseen, which seriously harm the performance of semantic segmentation methods. In addition, the delay of the traditional camera during high-speed driving will further reduce the contextual information in the time dimension. Therefore, we propose to extract dynamic context from event-based data with a higher temporal resolution to enhance static RGB images, even for those from traffic accidents with motion blur, collisions, deformations, overturns, etc. Moreover, in order to evaluate the segmentation performance in traffic accidents, we provide a pixel-wise annotated accident dataset, namely DADA-seg, which contains a variety of critical scenarios from traffic accidents. Our experiments indicate that event-based data can provide complementary information to stabilize semantic segmentation under adverse conditions by preserving fine-grained motion of fast-moving foreground (crash objects) in accidents. Our approach achieves +8.2% performance gain on the proposed accident dataset, exceeding more than 20 state-of-the-art semantic segmentation methods. The proposal has been demonstrated to be consistently effective for models learned on multiple source databases including Cityscapes, KITTI-360, BDD, and ApolloScape.
Transfer Learning Approaches for Building Cross-Language Dense Retrieval Models
Jan 20, 2022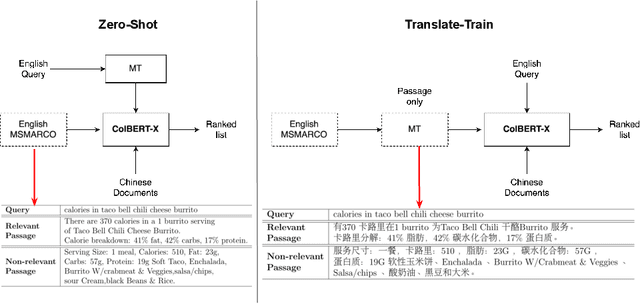
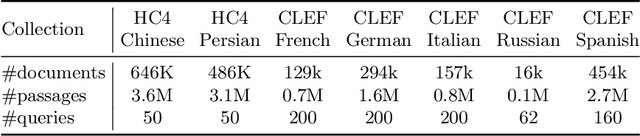
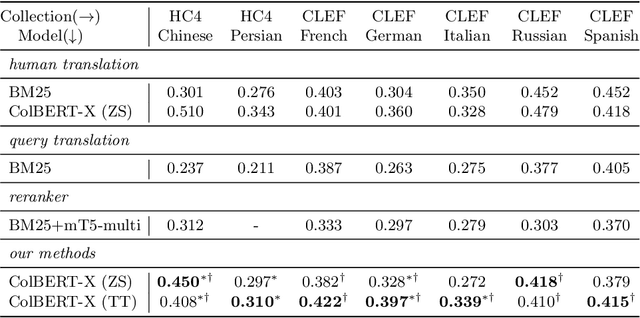
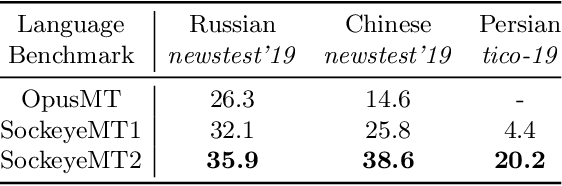
The advent of transformer-based models such as BERT has led to the rise of neural ranking models. These models have improved the effectiveness of retrieval systems well beyond that of lexical term matching models such as BM25. While monolingual retrieval tasks have benefited from large-scale training collections such as MS MARCO and advances in neural architectures, cross-language retrieval tasks have fallen behind these advancements. This paper introduces ColBERT-X, a generalization of the ColBERT multi-representation dense retrieval model that uses the XLM-RoBERTa (XLM-R) encoder to support cross-language information retrieval (CLIR). ColBERT-X can be trained in two ways. In zero-shot training, the system is trained on the English MS MARCO collection, relying on the XLM-R encoder for cross-language mappings. In translate-train, the system is trained on the MS MARCO English queries coupled with machine translations of the associated MS MARCO passages. Results on ad hoc document ranking tasks in several languages demonstrate substantial and statistically significant improvements of these trained dense retrieval models over traditional lexical CLIR baselines.