 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVERA-MH: Validation of Ethical and Responsible AI in Mental Health
May 13, 2026Chatbot usage has increased, including in fields for which they were never developed for--notably mental health support. To that end, we introduce Validations of Ethical and Responsible AI in Mental Health (VERA-MH), a novel clinically-validated evaluation for safety of chatbots in the context of mental health support. The first iteration of VERA-MH focuses on Suicidal Ideation (SI) risks, by assessing how well chatbots can responds to users that might be in crisis. VERA-MH is comprised of three steps: conversation simulation, conversation judging and model rating. First, to simulate conversations with the chatbot under evaluation, another chatbot is tasked with role-playing users based on specific personas. Such user personas have been developed under clinical guidance, to make sure that, among others, multiple risk factors, demographic characteristics and disclosure factors were represented. In the judging step, a second support model is used as an LLM-as-a-Judge, together with a clinically-developed rubric. The rubric is structured as a flow, with a single Yes/No question asked each time, to improve answers' consistency and highlight models' failure modes. In the last stage, results of each conversation are aggregated to present the final evaluation of the chatbot. Together with the framework, we present the result of the evaluations for four leading LLM providers.
VERA-MH: Reliability and Validity of an Open-Source AI Safety Evaluation in Mental Health
Feb 04, 2026Millions now use leading generative AI chatbots for psychological support. Despite the promise related to availability and scale, the single most pressing question in AI for mental health is whether these tools are safe. The Validation of Ethical and Responsible AI in Mental Health (VERA-MH) evaluation was recently proposed to meet the urgent need for an evidence-based automated safety benchmark. This study aimed to examine the clinical validity and reliability of the VERA-MH evaluation for AI safety in suicide risk detection and response. We first simulated a large set of conversations between large language model (LLM)-based users (user-agents) and general-purpose AI chatbots. Licensed mental health clinicians used a rubric (scoring guide) to independently rate the simulated conversations for safe and unsafe chatbot behaviors, as well as user-agent realism. An LLM-based judge used the same scoring rubric to evaluate the same set of simulated conversations. We then compared rating alignment across (a) individual clinicians and (b) clinician consensus and the LLM judge, and (c) examined clinicians' ratings of user-agent realism. Individual clinicians were generally consistent with one another in their safety ratings (chance-corrected inter-rater reliability [IRR]: 0.77), thus establishing a gold-standard clinical reference. The LLM judge was strongly aligned with this clinical consensus (IRR: 0.81) overall and within key conditions. Clinician raters generally perceived the user-agents to be realistic. For the potential mental health benefits of AI chatbots to be realized, attention to safety is paramount. Findings from this human evaluation study support the clinical validity and reliability of VERA-MH: an open-source, fully automated AI safety evaluation for mental health. Further research will address VERA-MH generalizability and robustness.
The Moral Case for Using Language Model Agents for Recommendation
Oct 15, 2024Our information and communication environment has fallen short of the ideals that networked global communication might have served. Identifying all the causes of its pathologies is difficult, but existing recommender systems very likely play a contributing role. In this paper, which draws on the normative tools of philosophy of computing, informed by empirical and technical insights from natural language processing and recommender systems, we make the moral case for an alternative approach. We argue that existing recommenders incentivise mass surveillance, concentrate power, fall prey to narrow behaviourism, and compromise user agency. Rather than just trying to avoid algorithms entirely, or to make incremental improvements to the current paradigm, researchers and engineers should explore an alternative paradigm: the use of language model (LM) agents to source and curate content that matches users' preferences and values, expressed in natural language. The use of LM agents for recommendation poses its own challenges, including those related to candidate generation, computational efficiency, preference modelling, and prompt injection. Nonetheless, if implemented successfully LM agents could: guide us through the digital public sphere without relying on mass surveillance; shift power away from platforms towards users; optimise for what matters instead of just for behavioural proxies; and scaffold our agency instead of undermining it.
A Keyword Based Approach to Understanding the Overpenalization of Marginalized Groups by English Marginal Abuse Models on Twitter
Oct 07, 2022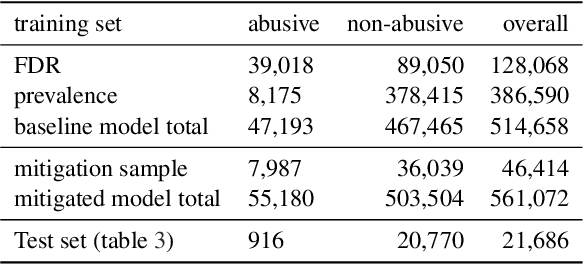
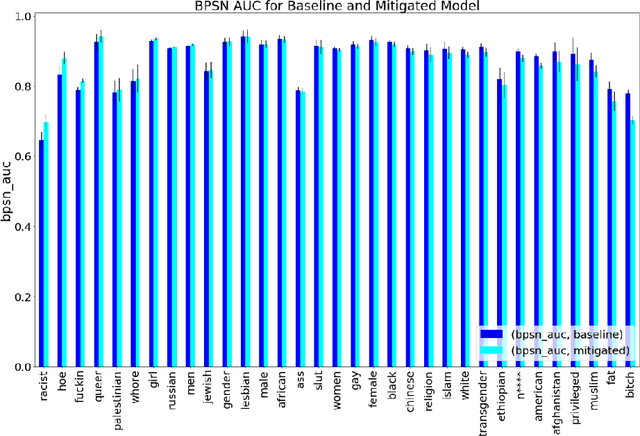
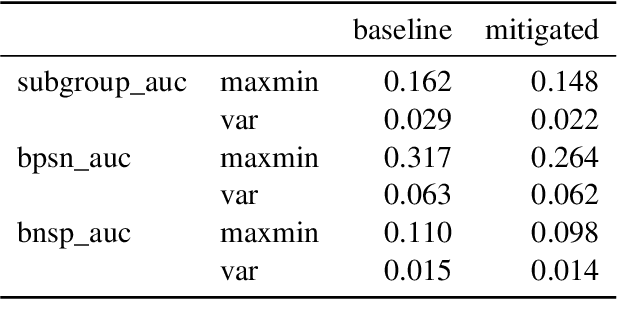
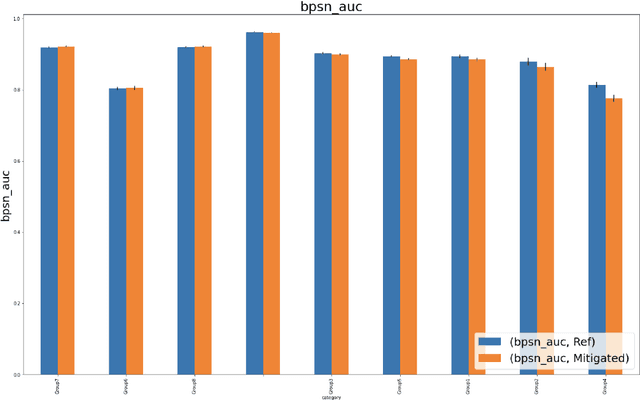
Harmful content detection models tend to have higher false positive rates for content from marginalized groups. In the context of marginal abuse modeling on Twitter, such disproportionate penalization poses the risk of reduced visibility, where marginalized communities lose the opportunity to voice their opinion on the platform. Current approaches to algorithmic harm mitigation, and bias detection for NLP models are often very ad hoc and subject to human bias. We make two main contributions in this paper. First, we design a novel methodology, which provides a principled approach to detecting and measuring the severity of potential harms associated with a text-based model. Second, we apply our methodology to audit Twitter's English marginal abuse model, which is used for removing amplification eligibility of marginally abusive content. Without utilizing demographic labels or dialect classifiers, we are still able to detect and measure the severity of issues related to the over-penalization of the speech of marginalized communities, such as the use of reclaimed speech, counterspeech, and identity related terms. In order to mitigate the associated harms, we experiment with adding additional true negative examples and find that doing so provides improvements to our fairness metrics without large degradations in model performance.
Random Isn't Always Fair: Candidate Set Imbalance and Exposure Inequality in Recommender Systems
Sep 12, 2022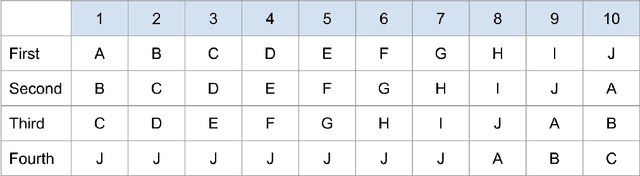

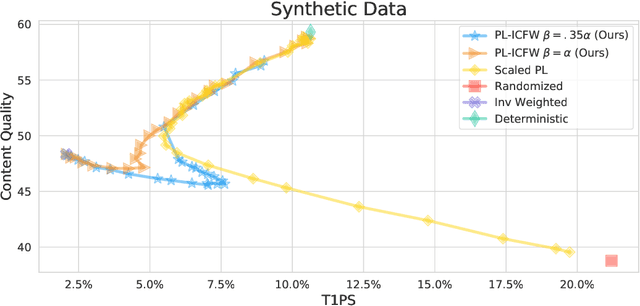
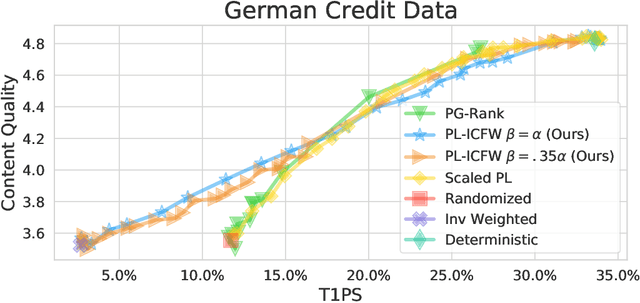
Traditionally, recommender systems operate by returning a user a set of items, ranked in order of estimated relevance to that user. In recent years, methods relying on stochastic ordering have been developed to create "fairer" rankings that reduce inequality in who or what is shown to users. Complete randomization -- ordering candidate items randomly, independent of estimated relevance -- is largely considered a baseline procedure that results in the most equal distribution of exposure. In industry settings, recommender systems often operate via a two-step process in which candidate items are first produced using computationally inexpensive methods and then a full ranking model is applied only to those candidates. In this paper, we consider the effects of inequality at the first step and show that, paradoxically, complete randomization at the second step can result in a higher degree of inequality relative to deterministic ordering of items by estimated relevance scores. In light of this observation, we then propose a simple post-processing algorithm in pursuit of reducing exposure inequality that works both when candidate sets have a high level of imbalance and when they do not. The efficacy of our method is illustrated on both simulated data and a common benchmark data set used in studying fairness in recommender systems.
Measuring Disparate Outcomes of Content Recommendation Algorithms with Distributional Inequality Metrics
Feb 03, 2022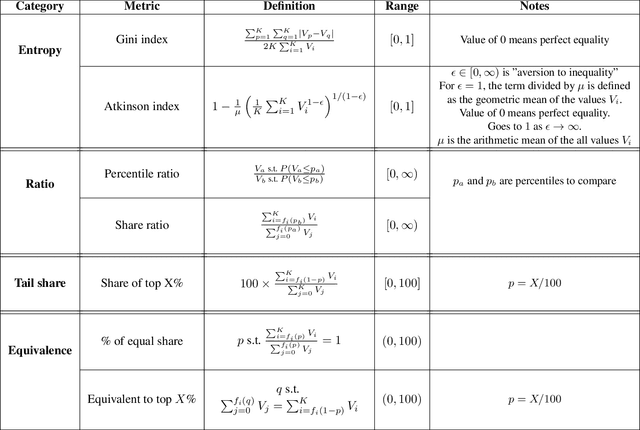
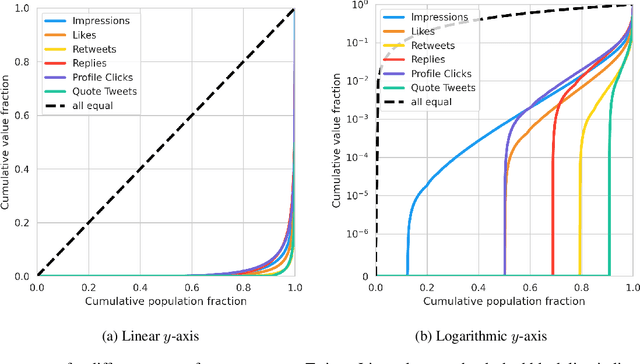
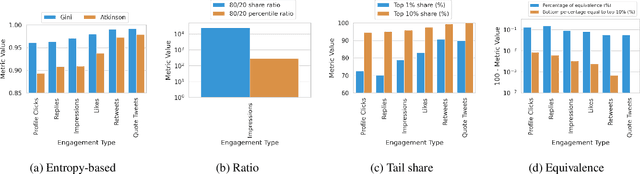
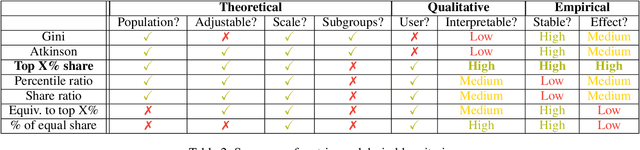
The harmful impacts of algorithmic decision systems have recently come into focus, with many examples of systems such as machine learning (ML) models amplifying existing societal biases. Most metrics attempting to quantify disparities resulting from ML algorithms focus on differences between groups, dividing users based on demographic identities and comparing model performance or overall outcomes between these groups. However, in industry settings, such information is often not available, and inferring these characteristics carries its own risks and biases. Moreover, typical metrics that focus on a single classifier's output ignore the complex network of systems that produce outcomes in real-world settings. In this paper, we evaluate a set of metrics originating from economics, distributional inequality metrics, and their ability to measure disparities in content exposure in a production recommendation system, the Twitter algorithmic timeline. We define desirable criteria for metrics to be used in an operational setting, specifically by ML practitioners. We characterize different types of engagement with content on Twitter using these metrics, and use these results to evaluate the metrics with respect to the desired criteria. We show that we can use these metrics to identify content suggestion algorithms that contribute more strongly to skewed outcomes between users. Overall, we conclude that these metrics can be useful tools for understanding disparate outcomes in online social networks.
Causal Inference Struggles with Agency on Online Platforms
Jul 19, 2021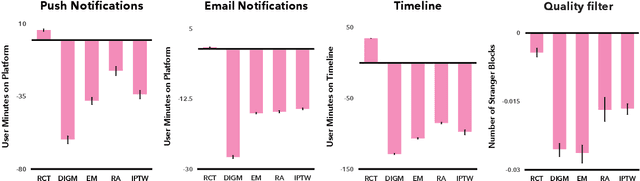

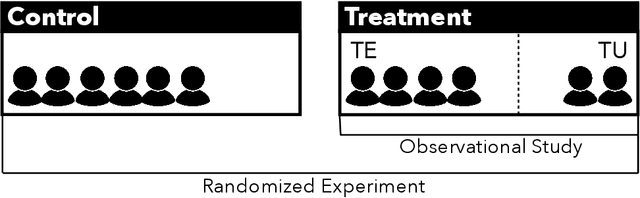
Online platforms regularly conduct randomized experiments to understand how changes to the platform causally affect various outcomes of interest. However, experimentation on online platforms has been criticized for having, among other issues, a lack of meaningful oversight and user consent. As platforms give users greater agency, it becomes possible to conduct observational studies in which users self-select into the treatment of interest as an alternative to experiments in which the platform controls whether the user receives treatment or not. In this paper, we conduct four large-scale within-study comparisons on Twitter aimed at assessing the effectiveness of observational studies derived from user self-selection on online platforms. In a within-study comparison, treatment effects from an observational study are assessed based on how effectively they replicate results from a randomized experiment with the same target population. We test the naive difference in group means estimator, exact matching, regression adjustment, and inverse probability of treatment weighting while controlling for plausible confounding variables. In all cases, all observational estimates perform poorly at recovering the ground-truth estimate from the analogous randomized experiments. In all cases except one, the observational estimates have the opposite sign of the randomized estimate. Our results suggest that observational studies derived from user self-selection are a poor alternative to randomized experimentation on online platforms. In discussing our results, we postulate "Catch-22"s that suggest that the success of causal inference in these settings may be at odds with the original motivations for providing users with greater agency.
From Optimizing Engagement to Measuring Value
Aug 21, 2020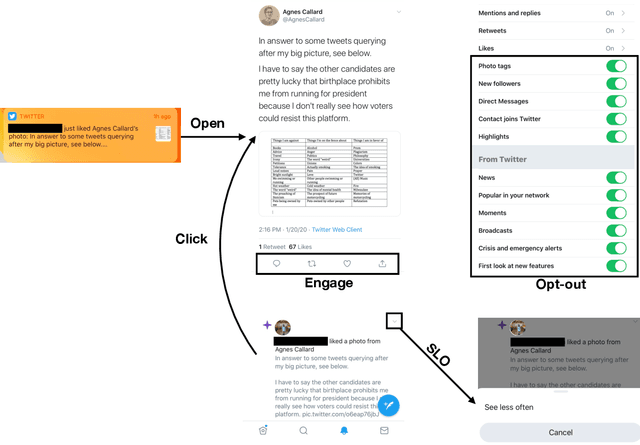
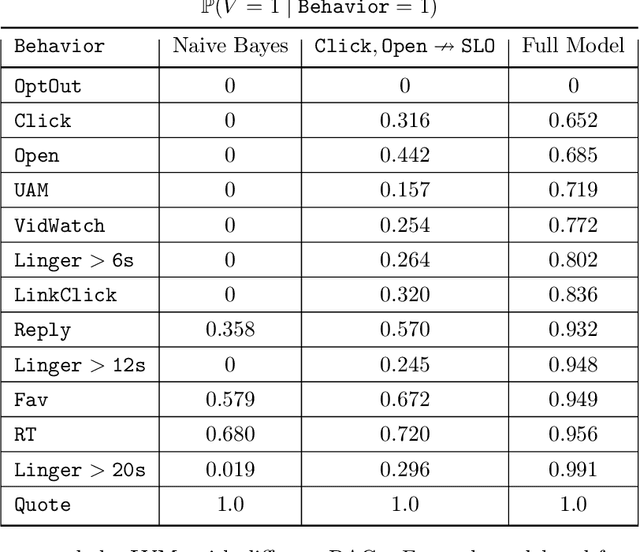
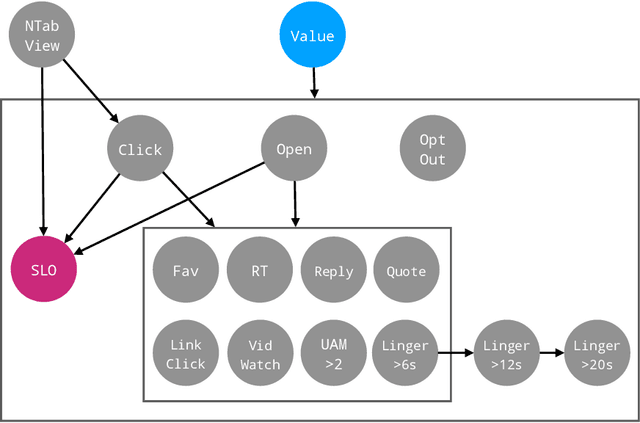
Most recommendation engines today are based on predicting user engagement, e.g. predicting whether a user will click on an item or not. However, there is potentially a large gap between engagement signals and a desired notion of "value" that is worth optimizing for. We use the framework of measurement theory to (a) confront the designer with a normative question about what the designer values, (b) provide a general latent variable model approach that can be used to operationalize the target construct and directly optimize for it, and (c) guide the designer in evaluating and revising their operationalization. We implement our approach on the Twitter platform on millions of users. In line with established approaches to assessing the validity of measurements, we perform a qualitative evaluation of how well our model captures a desired notion of "value".
Assessing Demographic Bias in Named Entity Recognition
Aug 08, 2020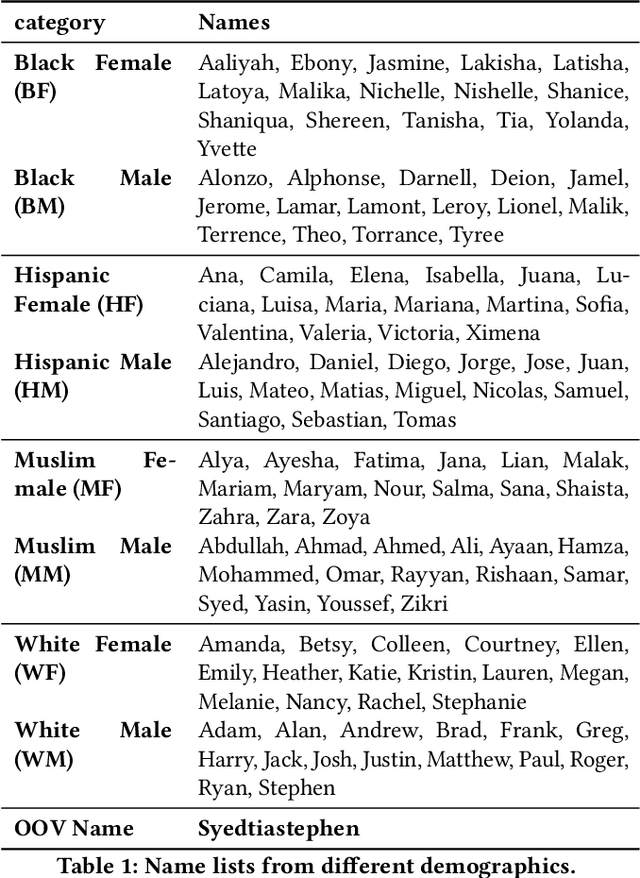
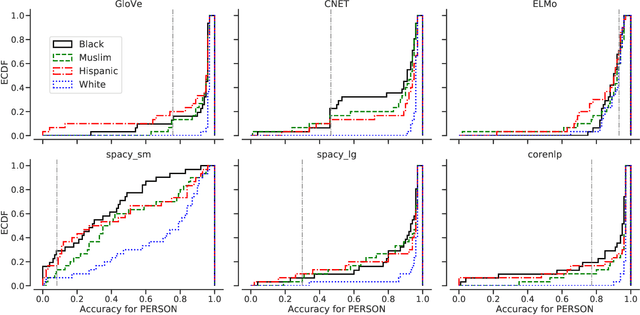

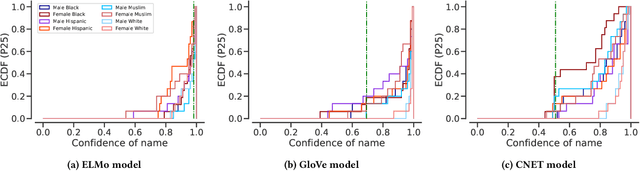
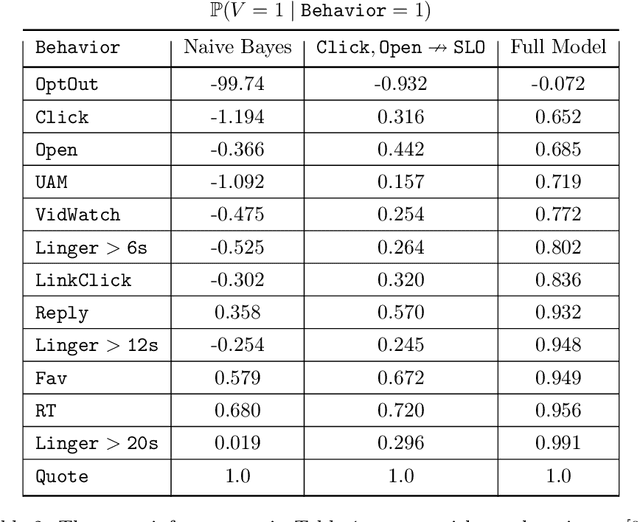
Named Entity Recognition (NER) is often the first step towards automated Knowledge Base (KB) generation from raw text. In this work, we assess the bias in various Named Entity Recognition (NER) systems for English across different demographic groups with synthetically generated corpora. Our analysis reveals that models perform better at identifying names from specific demographic groups across two datasets. We also identify that debiased embeddings do not help in resolving this issue. Finally, we observe that character-based contextualized word representation models such as ELMo results in the least bias across demographics. Our work can shed light on potential biases in automated KB generation due to systematic exclusion of named entities belonging to certain demographics.
Privacy-Preserving Recommender Systems Challenge on Twitter's Home Timeline
Apr 28, 2020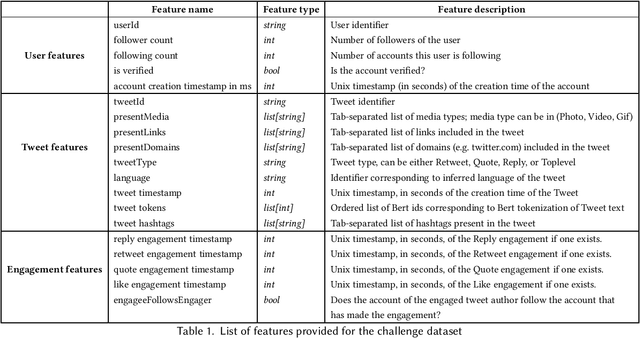
Recommender systems constitute the core engine of most social network platforms nowadays, aiming to maximize user satisfaction along with other key business objectives. Twitter is no exception. Despite the fact that Twitter data has been extensively used to understand socioeconomic and political phenomena and user behaviour, the implicit feedback provided by users on Tweets through their engagements on the Home Timeline has only been explored to a limited extent. At the same time, there is a lack of large-scale public social network datasets that would enable the scientific community to both benchmark and build more powerful and comprehensive models that tailor content to user interests. By releasing an original dataset of 160 million Tweets along with engagement information, Twitter aims to address exactly that. During this release, special attention is drawn on maintaining compliance with existing privacy laws. Apart from user privacy, this paper touches on the key challenges faced by researchers and professionals striving to predict user engagements. It further describes the key aspects of the RecSys 2020 Challenge that was organized by ACM RecSys in partnership with Twitter using this dataset.