 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIRCLE: A Framework for Evaluating AI from a Real-World Lens
Mar 03, 2026This paper proposes CIRCLE, a six-stage, lifecycle-based framework to bridge the reality gap between model-centric performance metrics and AI's materialized outcomes in deployment. While existing frameworks like MLOps focus on system stability and benchmarks measure abstract capabilities, decision-makers outside the AI stack lack systematic evidence about the behavior of AI technologies under real-world user variability and constraints. CIRCLE operationalizes the Validation phase of TEVV (Test, Evaluation, Verification, and Validation) by formalizing the translation of stakeholder concerns outside the stack into measurable signals. Unlike participatory design, which often remains localized, or algorithmic audits, which are often retrospective, CIRCLE provides a structured, prospective protocol for linking context-sensitive qualitative insights to scalable quantitative metrics. By integrating methods such as field testing, red teaming, and longitudinal studies into a coordinated pipeline, CIRCLE produces systematic knowledge: evidence that is comparable across sites yet sensitive to local context. This can enable governance based on materialized downstream effects rather than theoretical capabilities.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Reality Check: A New Evaluation Ecosystem Is Necessary to Understand AI's Real World Effects
May 24, 2025


Conventional AI evaluation approaches concentrated within the AI stack exhibit systemic limitations for exploring, navigating and resolving the human and societal factors that play out in real world deployment such as in education, finance, healthcare, and employment sectors. AI capability evaluations can capture detail about first-order effects, such as whether immediate system outputs are accurate, or contain toxic, biased or stereotypical content, but AI's second-order effects, i.e. any long-term outcomes and consequences that may result from AI use in the real world, have become a significant area of interest as the technology becomes embedded in our daily lives. These secondary effects can include shifts in user behavior, societal, cultural and economic ramifications, workforce transformations, and long-term downstream impacts that may result from a broad and growing set of risks. This position paper argues that measuring the indirect and secondary effects of AI will require expansion beyond static, single-turn approaches conducted in silico to include testing paradigms that can capture what actually materializes when people use AI technology in context. Specifically, we describe the need for data and methods that can facilitate contextual awareness and enable downstream interpretation and decision making about AI's secondary effects, and recommend requirements for a new ecosystem.
On the Societal Impact of Open Foundation Models
Feb 27, 2024

Foundation models are powerful technologies: how they are released publicly directly shapes their societal impact. In this position paper, we focus on open foundation models, defined here as those with broadly available model weights (e.g. Llama 2, Stable Diffusion XL). We identify five distinctive properties (e.g. greater customizability, poor monitoring) of open foundation models that lead to both their benefits and risks. Open foundation models present significant benefits, with some caveats, that span innovation, competition, the distribution of decision-making power, and transparency. To understand their risks of misuse, we design a risk assessment framework for analyzing their marginal risk. Across several misuse vectors (e.g. cyberattacks, bioweapons), we find that current research is insufficient to effectively characterize the marginal risk of open foundation models relative to pre-existing technologies. The framework helps explain why the marginal risk is low in some cases, clarifies disagreements about misuse risks by revealing that past work has focused on different subsets of the framework with different assumptions, and articulates a way forward for more constructive debate. Overall, our work helps support a more grounded assessment of the societal impact of open foundation models by outlining what research is needed to empirically validate their theoretical benefits and risks.
Towards Publicly Accountable Frontier LLMs: Building an External Scrutiny Ecosystem under the ASPIRE Framework
Nov 15, 2023With the increasing integration of frontier large language models (LLMs) into society and the economy, decisions related to their training, deployment, and use have far-reaching implications. These decisions should not be left solely in the hands of frontier LLM developers. LLM users, civil society and policymakers need trustworthy sources of information to steer such decisions for the better. Involving outside actors in the evaluation of these systems - what we term 'external scrutiny' - via red-teaming, auditing, and external researcher access, offers a solution. Though there are encouraging signs of increasing external scrutiny of frontier LLMs, its success is not assured. In this paper, we survey six requirements for effective external scrutiny of frontier AI systems and organize them under the ASPIRE framework: Access, Searching attitude, Proportionality to the risks, Independence, Resources, and Expertise. We then illustrate how external scrutiny might function throughout the AI lifecycle and offer recommendations to policymakers.
Adversarial Machine Learning and Cybersecurity: Risks, Challenges, and Legal Implications
May 23, 2023In July 2022, the Center for Security and Emerging Technology (CSET) at Georgetown University and the Program on Geopolitics, Technology, and Governance at the Stanford Cyber Policy Center convened a workshop of experts to examine the relationship between vulnerabilities in artificial intelligence systems and more traditional types of software vulnerabilities. Topics discussed included the extent to which AI vulnerabilities can be handled under standard cybersecurity processes, the barriers currently preventing the accurate sharing of information about AI vulnerabilities, legal issues associated with adversarial attacks on AI systems, and potential areas where government support could improve AI vulnerability management and mitigation. This report is meant to accomplish two things. First, it provides a high-level discussion of AI vulnerabilities, including the ways in which they are disanalogous to other types of vulnerabilities, and the current state of affairs regarding information sharing and legal oversight of AI vulnerabilities. Second, it attempts to articulate broad recommendations as endorsed by the majority of participants at the workshop.
Measuring Disparate Outcomes of Content Recommendation Algorithms with Distributional Inequality Metrics
Feb 03, 2022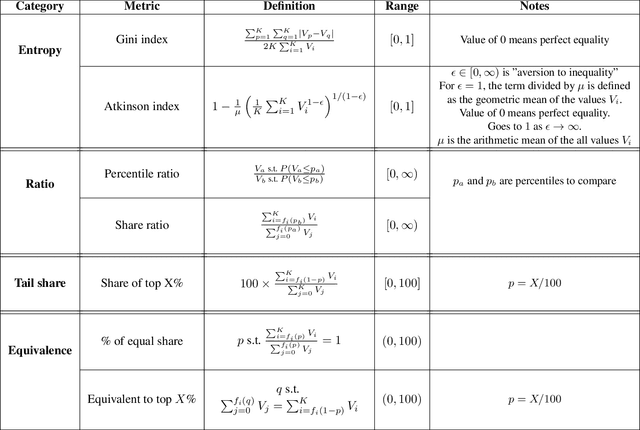
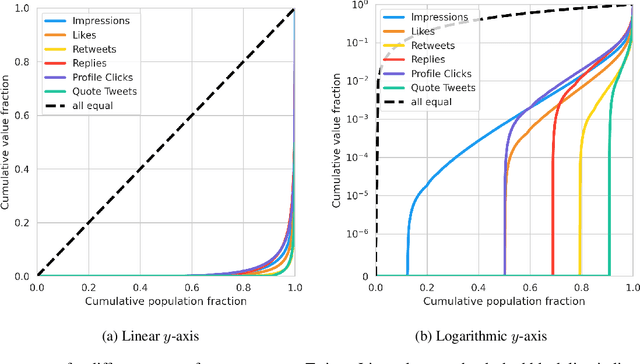
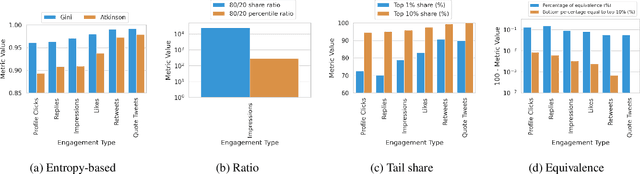
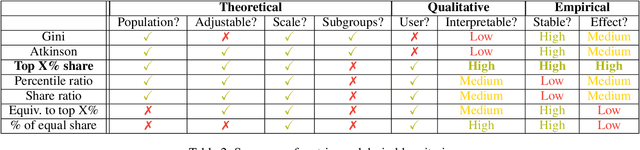
The harmful impacts of algorithmic decision systems have recently come into focus, with many examples of systems such as machine learning (ML) models amplifying existing societal biases. Most metrics attempting to quantify disparities resulting from ML algorithms focus on differences between groups, dividing users based on demographic identities and comparing model performance or overall outcomes between these groups. However, in industry settings, such information is often not available, and inferring these characteristics carries its own risks and biases. Moreover, typical metrics that focus on a single classifier's output ignore the complex network of systems that produce outcomes in real-world settings. In this paper, we evaluate a set of metrics originating from economics, distributional inequality metrics, and their ability to measure disparities in content exposure in a production recommendation system, the Twitter algorithmic timeline. We define desirable criteria for metrics to be used in an operational setting, specifically by ML practitioners. We characterize different types of engagement with content on Twitter using these metrics, and use these results to evaluate the metrics with respect to the desired criteria. We show that we can use these metrics to identify content suggestion algorithms that contribute more strongly to skewed outcomes between users. Overall, we conclude that these metrics can be useful tools for understanding disparate outcomes in online social networks.