 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Local-global speaker representation for target speaker extraction
Oct 28, 2022
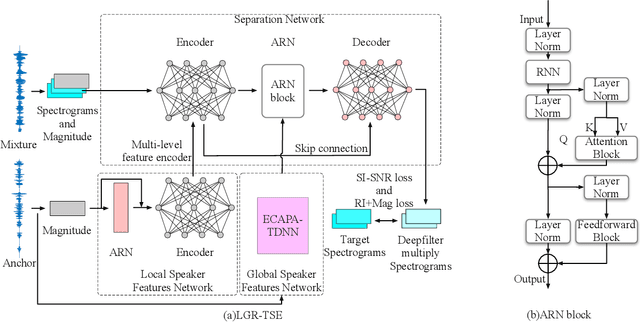
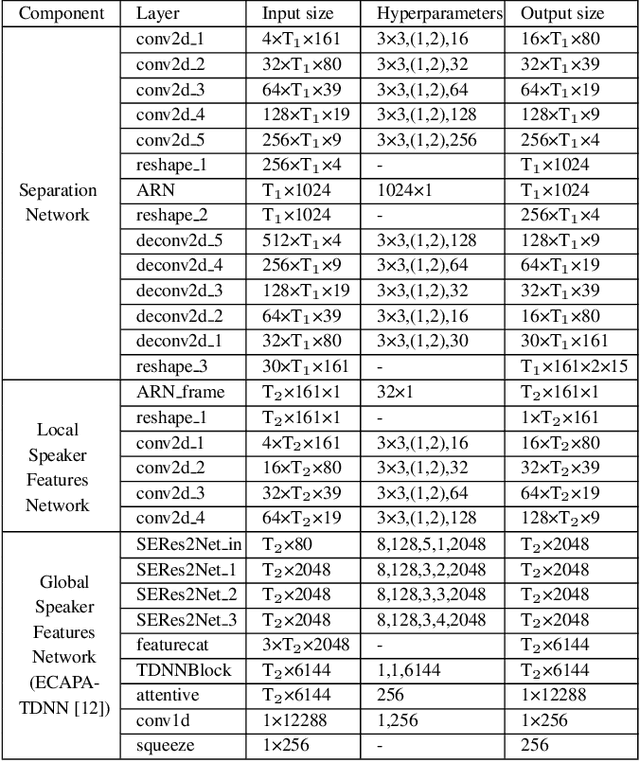
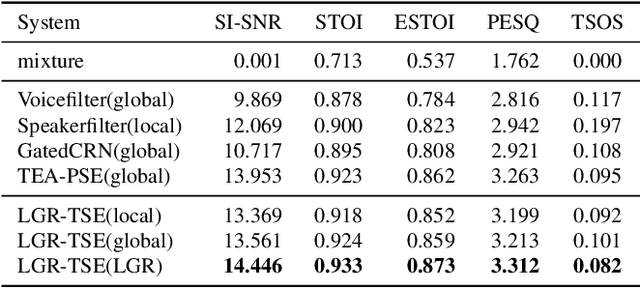
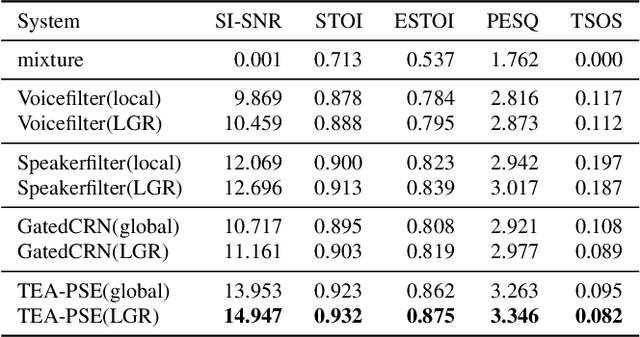
Target speaker extraction is to extract the target speaker's voice from a mixture of signals according to the given enrollment utterance. The target speaker's enrollment utterance is also called as anchor speech. The effective utilization of anchor speech is crucial for speaker extraction. In this study, we propose a new system to exploit speaker information from anchor speech fully. Unlike models that use only local or global features of the anchor, the proposed method extracts speaker information on global and local levels and feeds the features into a speech separation network. Our approach benefits from the complementary advantages of both global and local features, and the performance of speaker extraction is improved. We verified the feasibility of this local-global representation (LGR) method using multiple speaker extraction models. Systematic experiments were conducted on the open-source dataset Libri-2talker, and the results showed that the proposed method significantly outperformed the baseline models.
Semi-UFormer: Semi-supervised Uncertainty-aware Transformer for Image Dehazing
Oct 28, 2022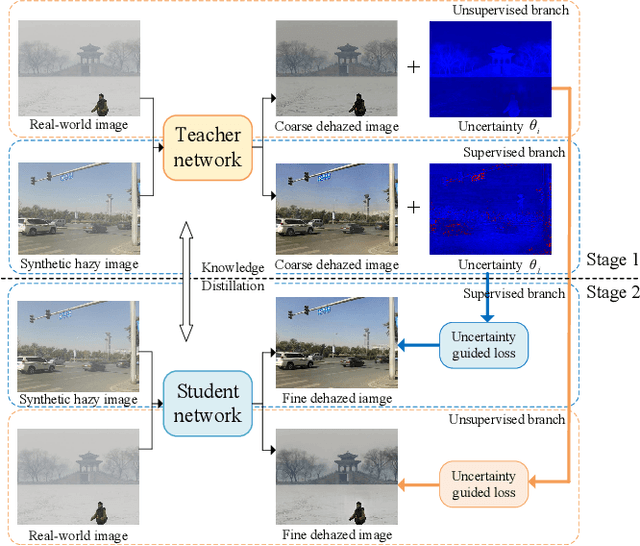
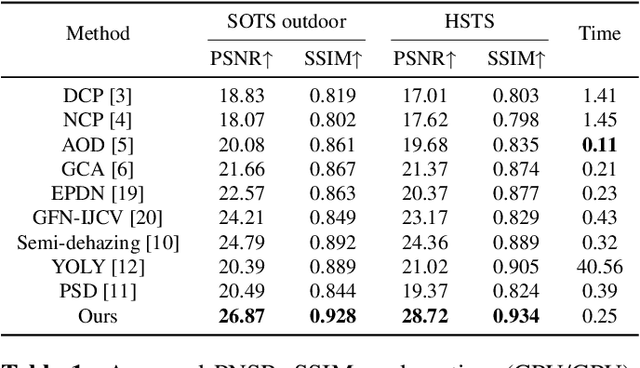
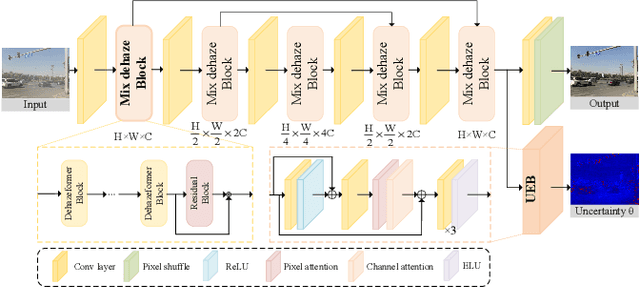
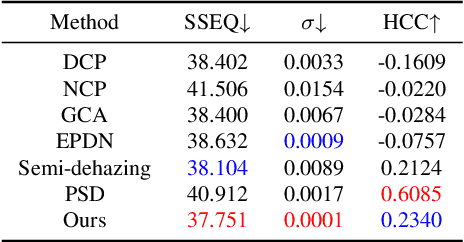
Image dehazing is fundamental yet not well-solved in computer vision. Most cutting-edge models are trained in synthetic data, leading to the poor performance on real-world hazy scenarios. Besides, they commonly give deterministic dehazed images while neglecting to mine their uncertainty. To bridge the domain gap and enhance the dehazing performance, we propose a novel semi-supervised uncertainty-aware transformer network, called Semi-UFormer. Semi-UFormer can well leverage both the real-world hazy images and their uncertainty guidance information. Specifically, Semi-UFormer builds itself on the knowledge distillation framework. Such teacher-student networks effectively absorb real-world haze information for quality dehazing. Furthermore, an uncertainty estimation block is introduced into the model to estimate the pixel uncertainty representations, which is then used as a guidance signal to help the student network produce haze-free images more accurately. Extensive experiments demonstrate that Semi-UFormer generalizes well from synthetic to real-world images.
MAST: Multiscale Audio Spectrogram Transformers
Nov 02, 2022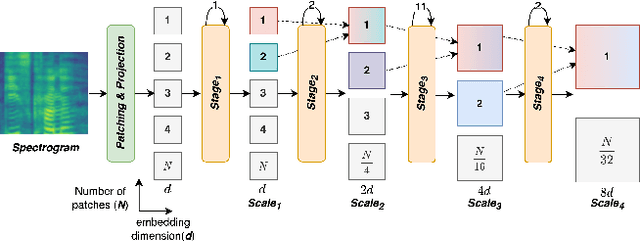
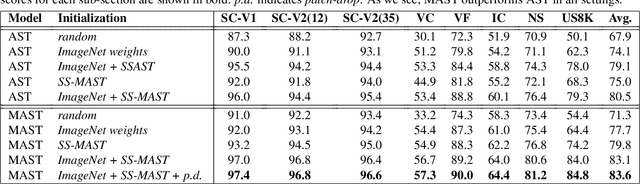
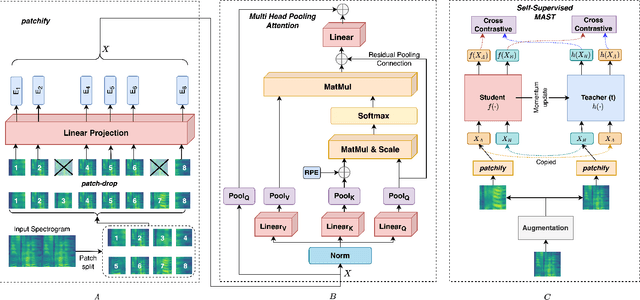
We present Multiscale Audio Spectrogram Transformer (MAST) for audio classification, which brings the concept of multiscale feature hierarchies to the Audio Spectrogram Transformer (AST). Given an input audio spectrogram we first patchify and project it into an initial temporal resolution and embedding dimension, post which the multiple stages in MAST progressively expand the embedding dimension while reducing the temporal resolution of the input. We use a pyramid structure that allows early layers of MAST operating at a high temporal resolution but low embedding space to model simple low-level acoustic information and deeper temporally coarse layers to model high-level acoustic information with high-dimensional embeddings. We also extend our approach to present a new Self-Supervised Learning (SSL) method called SS-MAST, which calculates a symmetric contrastive loss between latent representations from a student and a teacher encoder. In practice, MAST significantly outperforms AST by an average accuracy of 3.4% across 8 speech and non-speech tasks from the LAPE Benchmark. Moreover, SS-MAST achieves an absolute average improvement of 2.6% over SSAST for both AST and MAST encoders. We make all our codes available on GitHub at the time of publication.
Ranking-based Group Identification via Factorized Attention on Social Tripartite Graph
Nov 02, 2022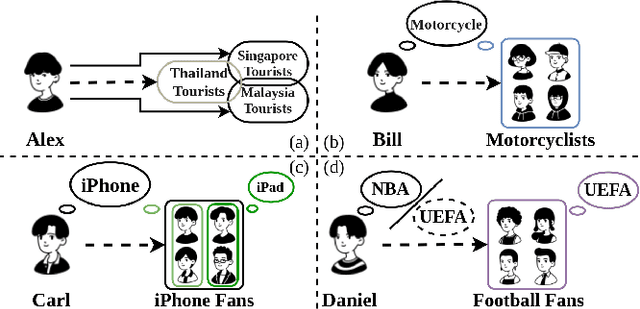
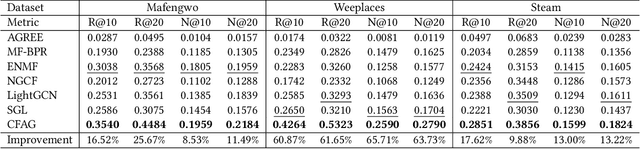
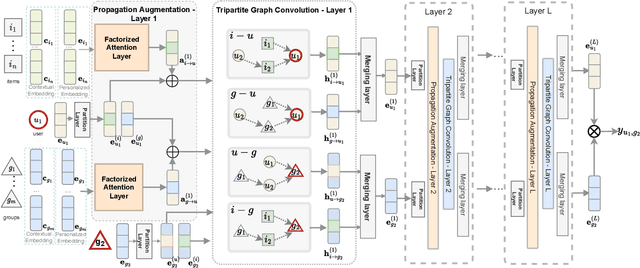
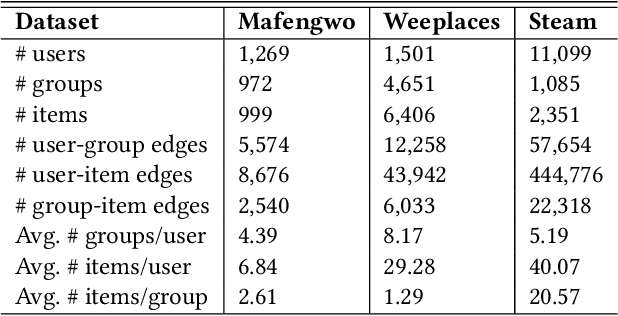
Due to the proliferation of social media, a growing number of users search for and join group activities in their daily life. This develops a need for the study on the ranking-based group identification (RGI) task, i.e., recommending groups to users. The major challenge in this task is how to effectively and efficiently leverage both the item interaction and group participation of users' online behaviors. Though recent developments of Graph Neural Networks (GNNs) succeed in simultaneously aggregating both social and user-item interaction, they however fail to comprehensively resolve this RGI task. In this paper, we propose a novel GNN-based framework named Contextualized Factorized Attention for Group identification (CFAG). We devise tripartite graph convolution layers to aggregate information from different types of neighborhoods among users, groups, and items. To cope with the data sparsity issue, we devise a novel propagation augmentation (PA) layer, which is based on our proposed factorized attention mechanism. PA layers efficiently learn the relatedness of non-neighbor nodes to improve the information propagation to users. Experimental results on three benchmark datasets verify the superiority of CFAG. Additional detailed investigations are conducted to demonstrate the effectiveness of the proposed framework.
Two-Stream Network for Sign Language Recognition and Translation
Nov 02, 2022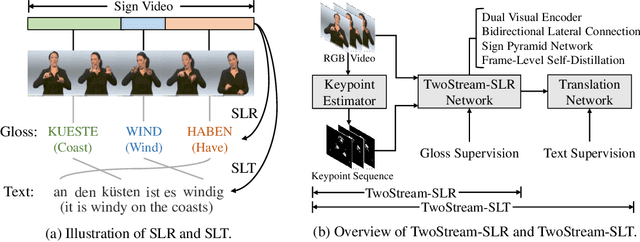
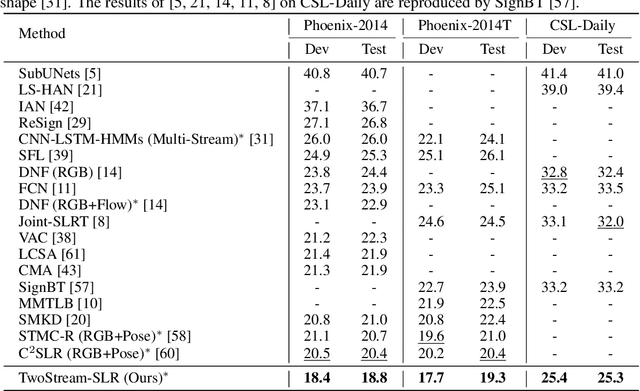
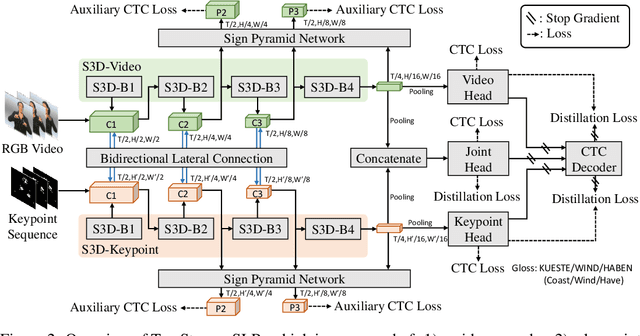
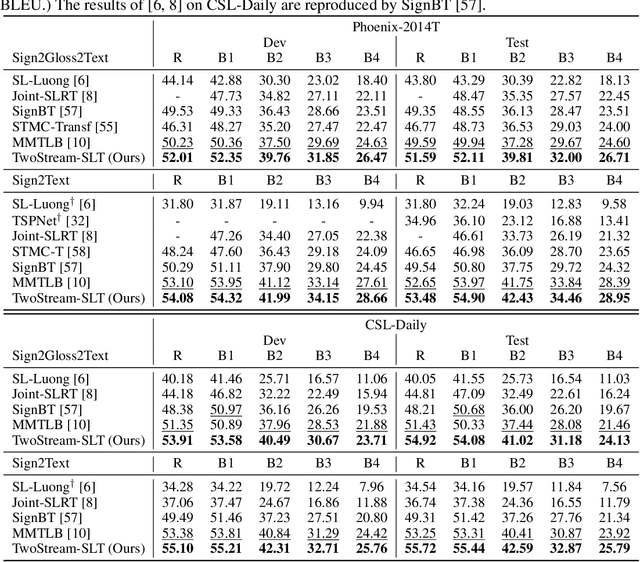
Sign languages are visual languages using manual articulations and non-manual elements to convey information. For sign language recognition and translation, the majority of existing approaches directly encode RGB videos into hidden representations. RGB videos, however, are raw signals with substantial visual redundancy, leading the encoder to overlook the key information for sign language understanding. To mitigate this problem and better incorporate domain knowledge, such as handshape and body movement, we introduce a dual visual encoder containing two separate streams to model both the raw videos and the keypoint sequences generated by an off-the-shelf keypoint estimator. To make the two streams interact with each other, we explore a variety of techniques, including bidirectional lateral connection, sign pyramid network with auxiliary supervision, and frame-level self-distillation. The resulting model is called TwoStream-SLR, which is competent for sign language recognition (SLR). TwoStream-SLR is extended to a sign language translation (SLT) model, TwoStream-SLT, by simply attaching an extra translation network. Experimentally, our TwoStream-SLR and TwoStream-SLT achieve state-of-the-art performance on SLR and SLT tasks across a series of datasets including Phoenix-2014, Phoenix-2014T, and CSL-Daily.
Online LiDAR-Camera Extrinsic Parameters Self-checking
Oct 19, 2022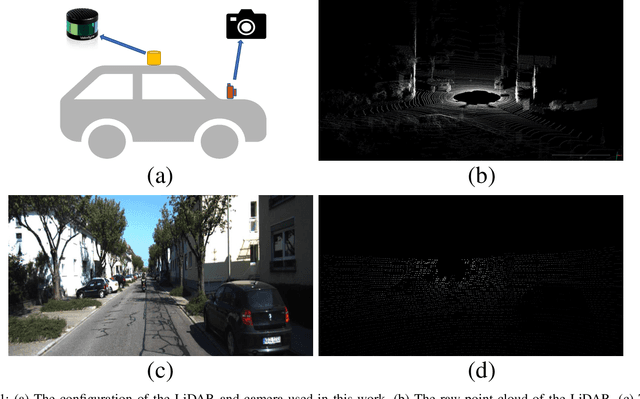
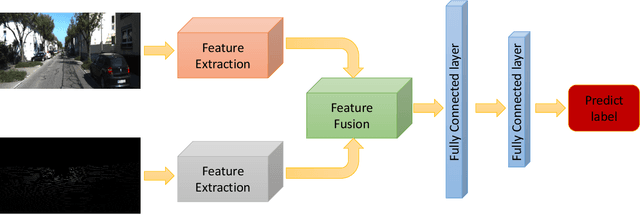

With the development of neural networks and the increasing popularity of automatic driving, the calibration of the LiDAR and the camera has attracted more and more attention. This calibration task is multi-modal, where the rich color and texture information captured by the camera and the accurate three-dimensional spatial information from the LiDAR is incredibly significant for downstream tasks. Current research interests mainly focus on obtaining accurate calibration results through information fusion. However, they seldom analyze whether the calibrated results are correct or not, which could be of significant importance in real-world applications. For example, in large-scale production, the LiDARs and the cameras of each smart car have to get well-calibrated as the car leaves the production line, while in the rest of the car life period, the poses of the LiDARs and cameras should also get continually supervised to ensure the security. To this end, this paper proposes a self-checking algorithm to judge whether the extrinsic parameters are well-calibrated by introducing a binary classification network based on the fused information from the camera and the LiDAR. Moreover, since there is no such dataset for the task in this work, we further generate a new dataset branch from the KITTI dataset tailored for the task. Our experiments on the proposed dataset branch demonstrate the performance of our method. To the best of our knowledge, this is the first work to address the significance of continually checking the calibrated extrinsic parameters for autonomous driving. The code is open-sourced on the Github website at https://github.com/OpenCalib/LiDAR2camera_self-check.
CLIP-Driven Fine-grained Text-Image Person Re-identification
Oct 19, 2022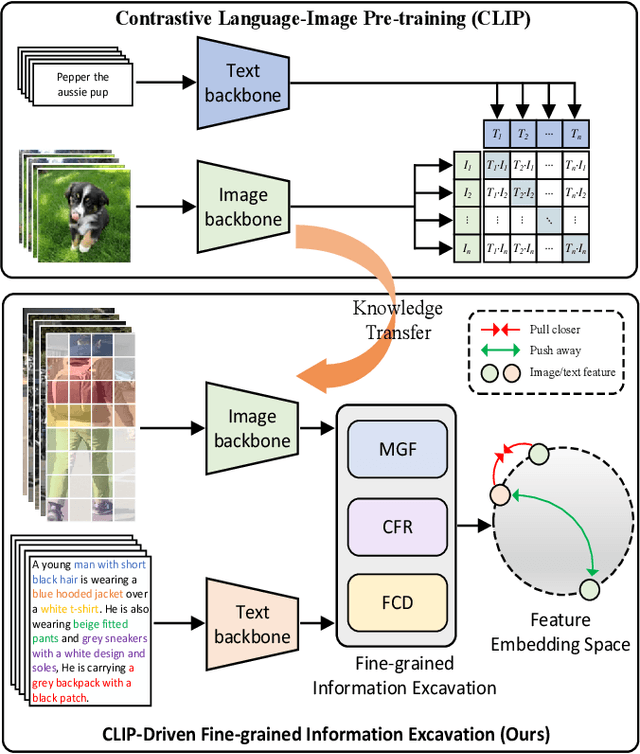
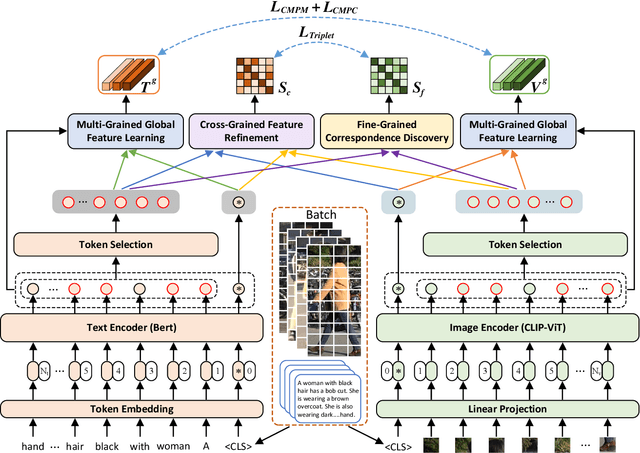
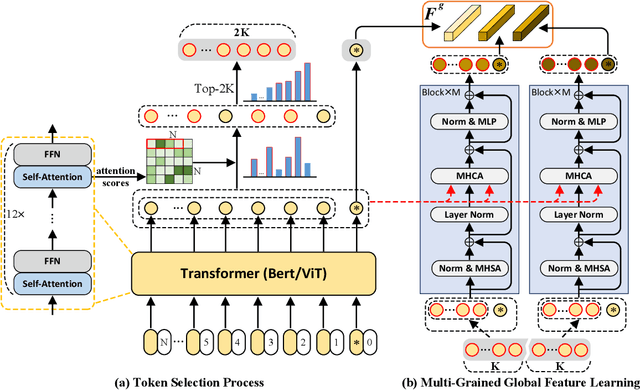
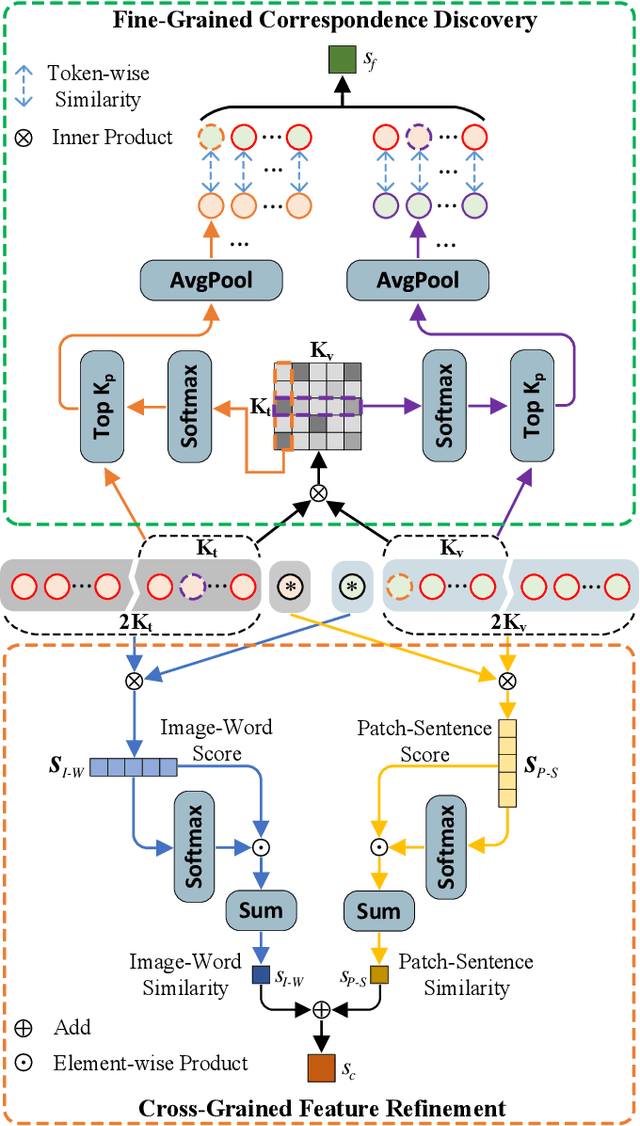
TIReID aims to retrieve the image corresponding to the given text query from a pool of candidate images. Existing methods employ prior knowledge from single-modality pre-training to facilitate learning, but lack multi-modal correspondences. Besides, due to the substantial gap between modalities, existing methods embed the original modal features into the same latent space for cross-modal alignment. However, feature embedding may lead to intra-modal information distortion. Recently, CLIP has attracted extensive attention from researchers due to its powerful semantic concept learning capacity and rich multi-modal knowledge, which can help us solve the above problems. Accordingly, in the paper, we propose a CLIP-driven Fine-grained information excavation framework (CFine) to fully utilize the powerful knowledge of CLIP for TIReID. To transfer the multi-modal knowledge effectively, we perform fine-grained information excavation to mine intra-modal discriminative clues and inter-modal correspondences. Specifically, we first design a multi-grained global feature learning module to fully mine intra-modal discriminative local information, which can emphasize identity-related discriminative clues by enhancing the interactions between global image (text) and informative local patches (words). Secondly, cross-grained feature refinement (CFR) and fine-grained correspondence discovery (FCD) modules are proposed to establish the cross-grained and fine-grained interactions between modalities, which can filter out non-modality-shared image patches/words and mine cross-modal correspondences from coarse to fine. CFR and FCD are removed during inference to save computational costs. Note that the above process is performed in the original modality space without further feature embedding. Extensive experiments on multiple benchmarks demonstrate the superior performance of our method on TIReID.
Hierarchical Multi-Interest Co-Network For Coarse-Grained Ranking
Oct 19, 2022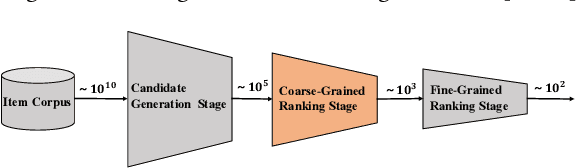
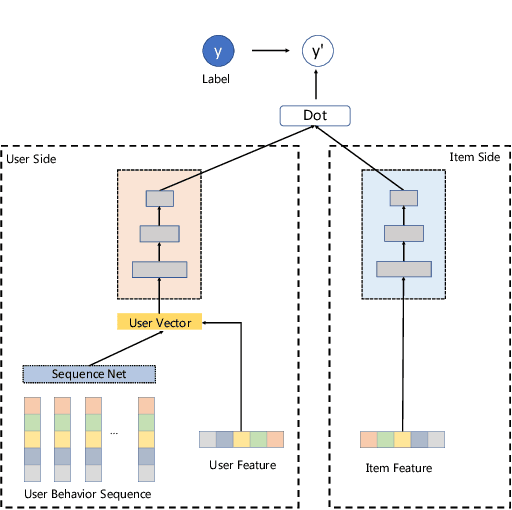
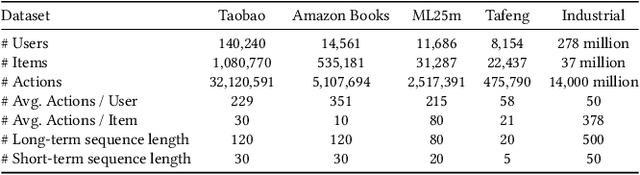
In this era of information explosion, a personalized recommendation system is convenient for users to get information they are interested in. To deal with billions of users and items, large-scale online recommendation services usually consist of three stages: candidate generation, coarse-grained ranking, and fine-grained ranking. The success of each stage depends on whether the model accurately captures the interests of users, which are usually hidden in users' behavior data. Previous research shows that users' interests are diverse, and one vector is not sufficient to capture users' different preferences. Therefore, many methods use multiple vectors to encode users' interests. However, there are two unsolved problems: (1) The similarity of different vectors in existing methods is too high, with too much redundant information. Consequently, the interests of users are not fully represented. (2) Existing methods model the long-term and short-term behaviors together, ignoring the differences between them. This paper proposes a Hierarchical Multi-Interest Co-Network (HCN) to capture users' diverse interests in the coarse-grained ranking stage. Specifically, we design a hierarchical multi-interest extraction layer to update users' diverse interest centers iteratively. The multiple embedded vectors obtained in this way contain more information and represent the interests of users better in various aspects. Furthermore, we develop a Co-Interest Network to integrate users' long-term and short-term interests. Experiments on several real-world datasets and one large-scale industrial dataset show that HCN effectively outperforms the state-of-the-art methods. We deploy HCN into a large-scale real world E-commerce system and achieve extra 2.5\% improvements on GMV (Gross Merchandise Value).
Fast Online Hashing with Multi-Label Projection
Dec 03, 2022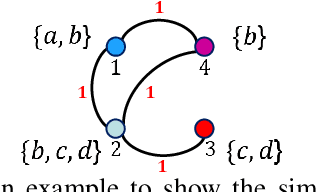
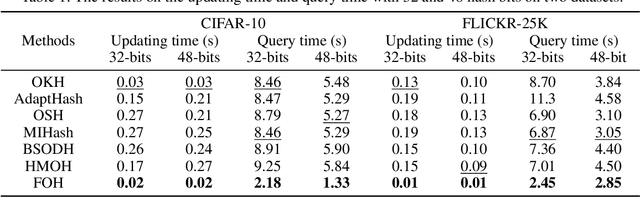
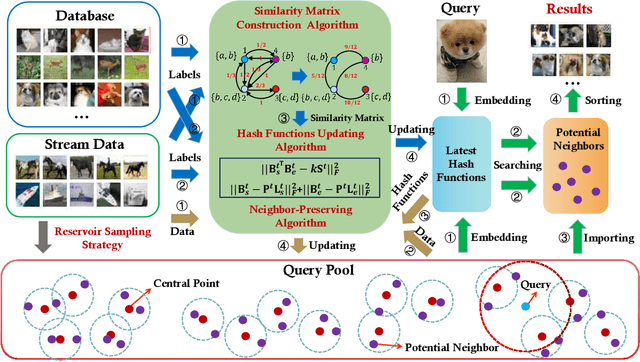

Hashing has been widely researched to solve the large-scale approximate nearest neighbor search problem owing to its time and storage superiority. In recent years, a number of online hashing methods have emerged, which can update the hash functions to adapt to the new stream data and realize dynamic retrieval. However, existing online hashing methods are required to update the whole database with the latest hash functions when a query arrives, which leads to low retrieval efficiency with the continuous increase of the stream data. On the other hand, these methods ignore the supervision relationship among the examples, especially in the multi-label case. In this paper, we propose a novel Fast Online Hashing (FOH) method which only updates the binary codes of a small part of the database. To be specific, we first build a query pool in which the nearest neighbors of each central point are recorded. When a new query arrives, only the binary codes of the corresponding potential neighbors are updated. In addition, we create a similarity matrix which takes the multi-label supervision information into account and bring in the multi-label projection loss to further preserve the similarity among the multi-label data. The experimental results on two common benchmarks show that the proposed FOH can achieve dramatic superiority on query time up to 6.28 seconds less than state-of-the-art baselines with competitive retrieval accuracy.
Modeling Label Correlations for Ultra-Fine Entity Typing with Neural Pairwise Conditional Random Field
Dec 03, 2022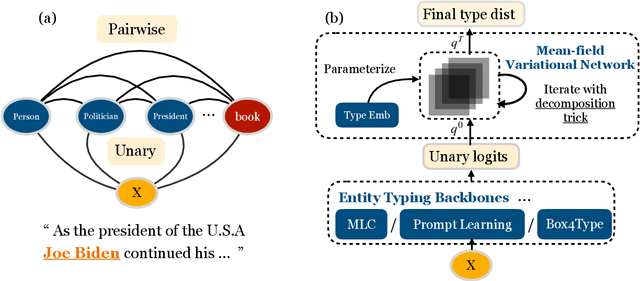

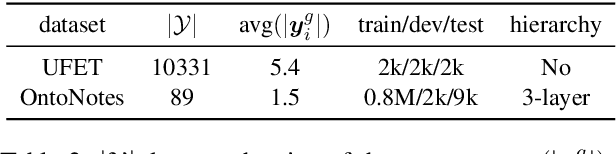
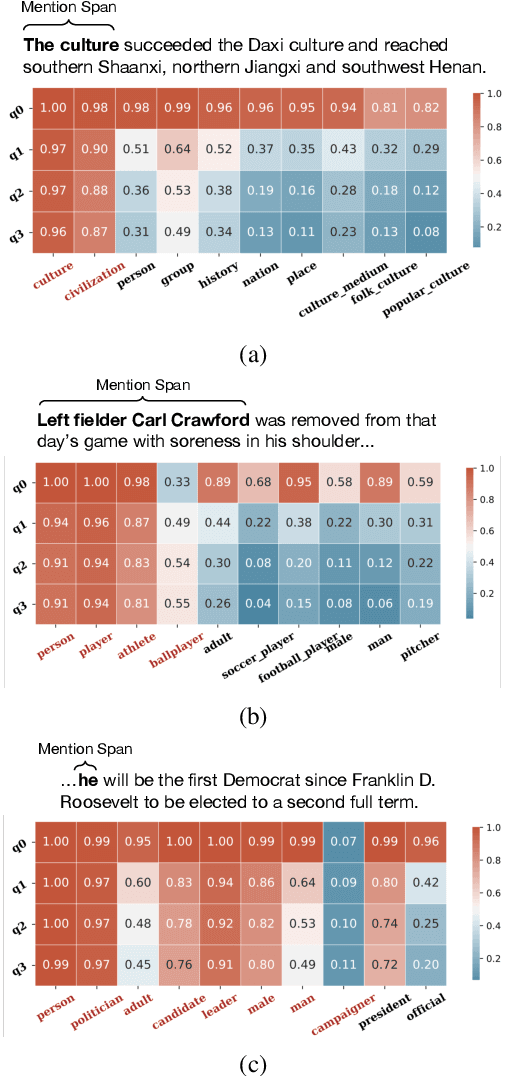
Ultra-fine entity typing (UFET) aims to predict a wide range of type phrases that correctly describe the categories of a given entity mention in a sentence. Most recent works infer each entity type independently, ignoring the correlations between types, e.g., when an entity is inferred as a president, it should also be a politician and a leader. To this end, we use an undirected graphical model called pairwise conditional random field (PCRF) to formulate the UFET problem, in which the type variables are not only unarily influenced by the input but also pairwisely relate to all the other type variables. We use various modern backbones for entity typing to compute unary potentials, and derive pairwise potentials from type phrase representations that both capture prior semantic information and facilitate accelerated inference. We use mean-field variational inference for efficient type inference on very large type sets and unfold it as a neural network module to enable end-to-end training. Experiments on UFET show that the Neural-PCRF consistently outperforms its backbones with little cost and results in a competitive performance against cross-encoder based SOTA while being thousands of times faster. We also find Neural- PCRF effective on a widely used fine-grained entity typing dataset with a smaller type set. We pack Neural-PCRF as a network module that can be plugged onto multi-label type classifiers with ease and release it in https://github.com/modelscope/adaseq/tree/master/examples/NPCRF.