 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Modelling Patient Trajectories Using Multimodal Information
Sep 09, 2022
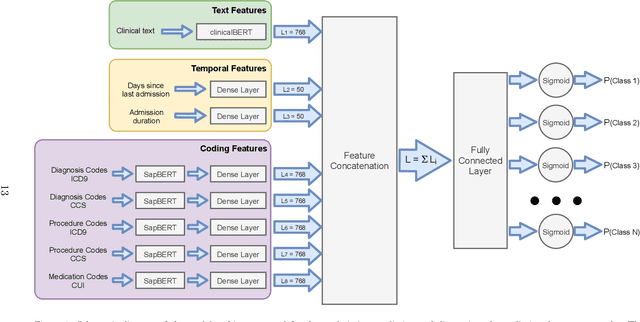
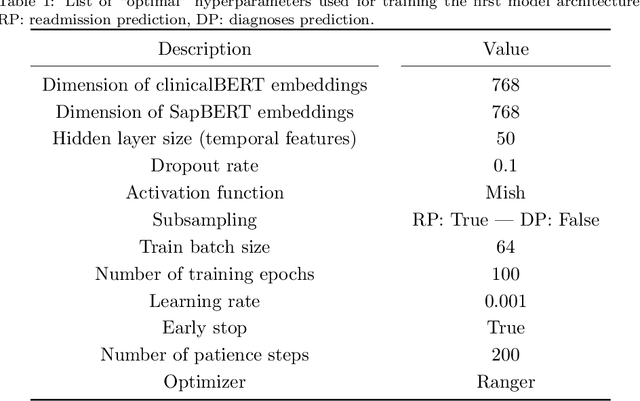
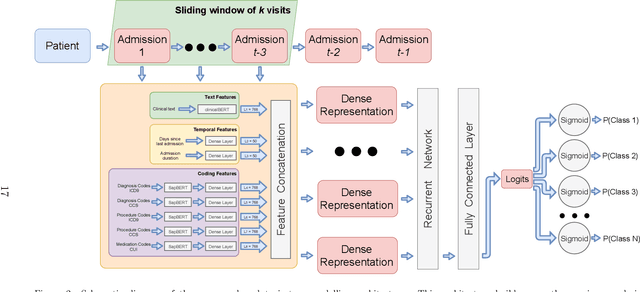

Electronic Health Records (EHRs) aggregate diverse information at the patient level, holding a trajectory representative of the evolution of the patient health status throughout time. Although this information provides context and can be leveraged by physicians to monitor patient health and make more accurate prognoses/diagnoses, patient records can contain information from very long time spans, which combined with the rapid generation rate of medical data makes clinical decision making more complex. Patient trajectory modelling can assist by exploring existing information in a scalable manner, and can contribute in augmenting health care quality by fostering preventive medicine practices. We propose a solution to model patient trajectories that combines different types of information and considers the temporal aspect of clinical data. This solution leverages two different architectures: one supporting flexible sets of input features, to convert patient admissions into dense representations; and a second exploring extracted admission representations in a recurrent-based architecture, where patient trajectories are processed in sub-sequences using a sliding window mechanism. The developed solution was evaluated on two different clinical outcomes, unexpected patient readmission and disease progression, using the publicly available MIMIC-III clinical database. The results obtained demonstrate the potential of the first architecture to model readmission and diagnoses prediction using single patient admissions. While information from clinical text did not show the discriminative power observed in other existing works, this may be explained by the need to fine-tune the clinicalBERT model. Finally, we demonstrate the potential of the sequence-based architecture using a sliding window mechanism to represent the input data, attaining comparable performances to other existing solutions.
Leveraging Foundation Models for Clinical Text Analysis
Mar 20, 2023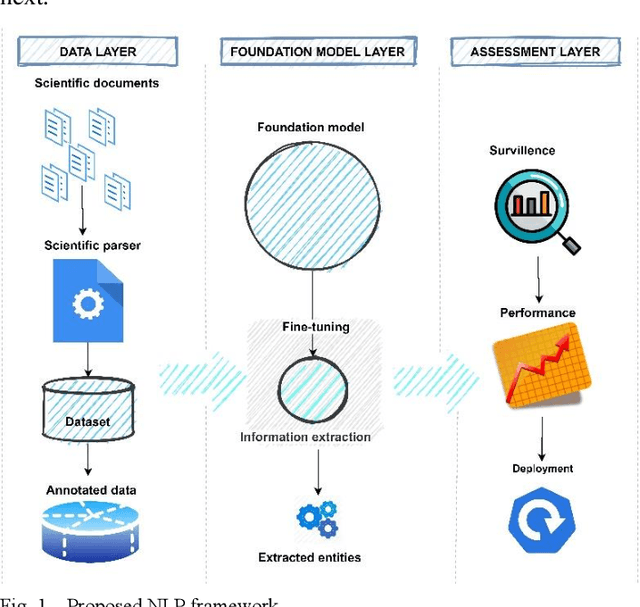
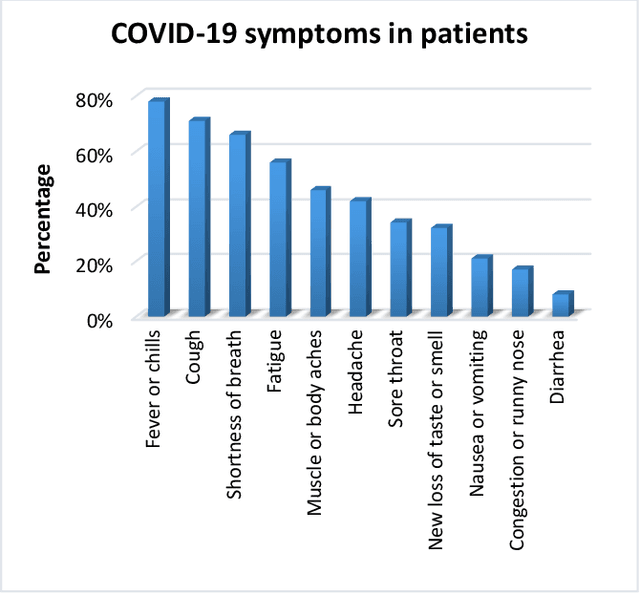
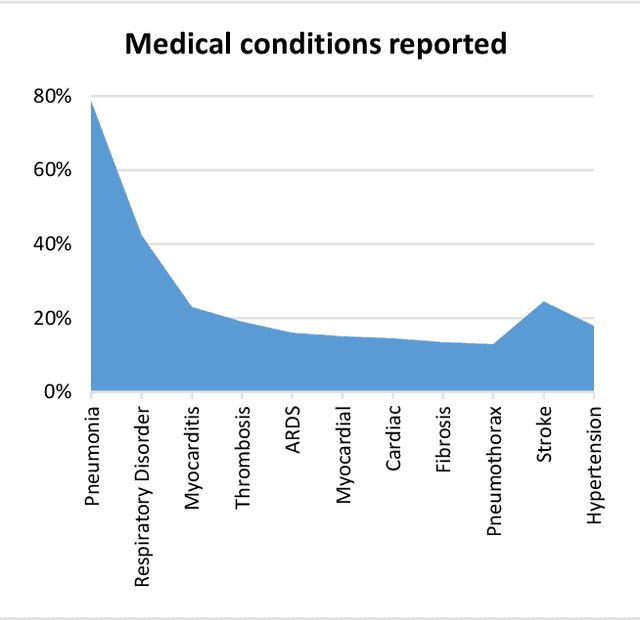
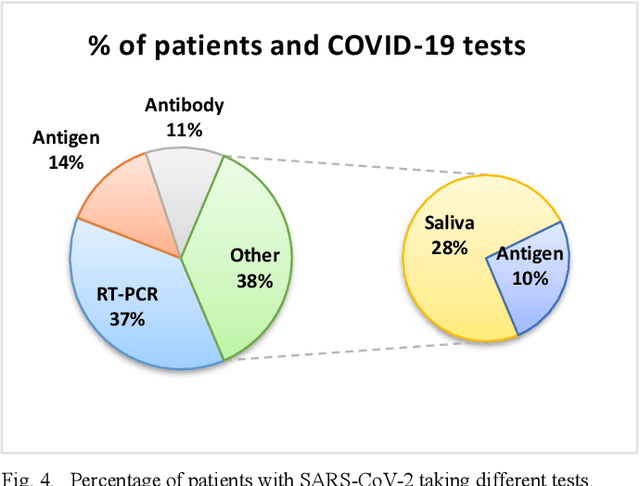
Infectious diseases are a significant public health concern globally, and extracting relevant information from scientific literature can facilitate the development of effective prevention and treatment strategies. However, the large amount of clinical data available presents a challenge for information extraction. To address this challenge, this study proposes a natural language processing (NLP) framework that uses a pre-trained transformer model fine-tuned on task-specific data to extract key information related to infectious diseases from free-text clinical data. The proposed framework includes three components: a data layer for preparing datasets from clinical texts, a foundation model layer for entity extraction, and an assessment layer for performance analysis. The results of the evaluation indicate that the proposed method outperforms standard methods, and leveraging prior knowledge through the pre-trained transformer model makes it useful for investigating other infectious diseases in the future.
Visual Dependency Transformers: Dependency Tree Emerges from Reversed Attention
Apr 06, 2023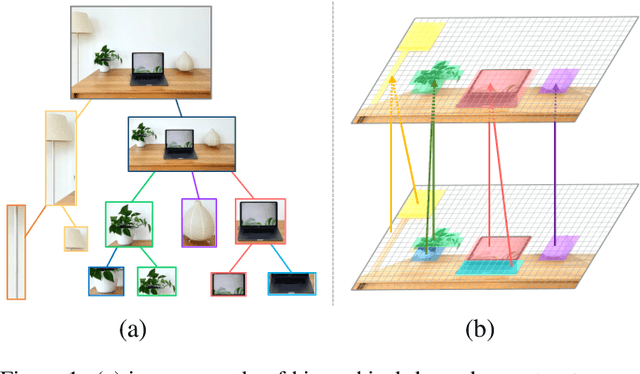
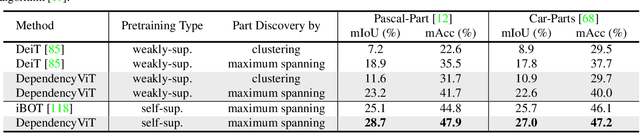
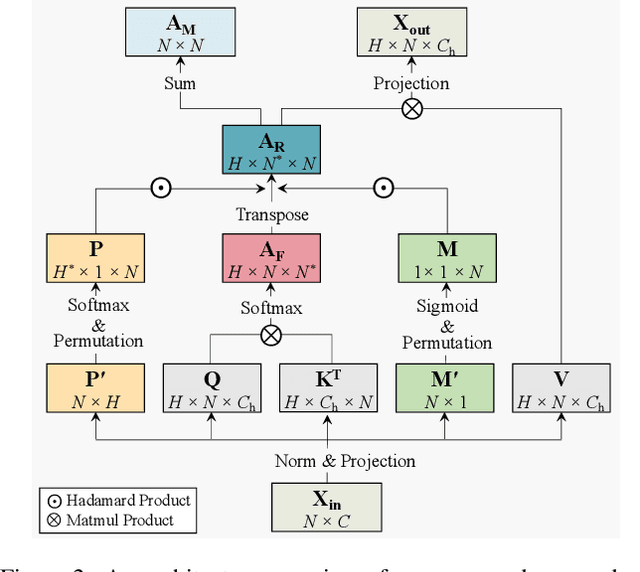
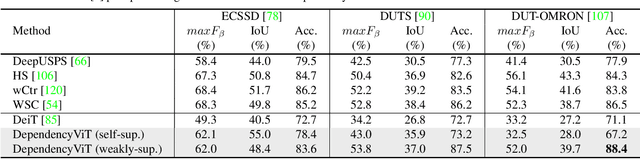
Humans possess a versatile mechanism for extracting structured representations of our visual world. When looking at an image, we can decompose the scene into entities and their parts as well as obtain the dependencies between them. To mimic such capability, we propose Visual Dependency Transformers (DependencyViT) that can induce visual dependencies without any labels. We achieve that with a novel neural operator called \emph{reversed attention} that can naturally capture long-range visual dependencies between image patches. Specifically, we formulate it as a dependency graph where a child token in reversed attention is trained to attend to its parent tokens and send information following a normalized probability distribution rather than gathering information in conventional self-attention. With such a design, hierarchies naturally emerge from reversed attention layers, and a dependency tree is progressively induced from leaf nodes to the root node unsupervisedly. DependencyViT offers several appealing benefits. (i) Entities and their parts in an image are represented by different subtrees, enabling part partitioning from dependencies; (ii) Dynamic visual pooling is made possible. The leaf nodes which rarely send messages can be pruned without hindering the model performance, based on which we propose the lightweight DependencyViT-Lite to reduce the computational and memory footprints; (iii) DependencyViT works well on both self- and weakly-supervised pretraining paradigms on ImageNet, and demonstrates its effectiveness on 8 datasets and 5 tasks, such as unsupervised part and saliency segmentation, recognition, and detection.
Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models
Apr 19, 2023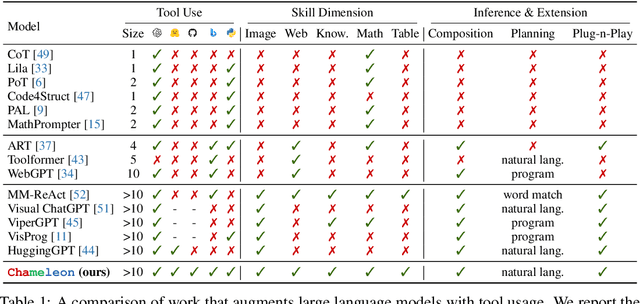
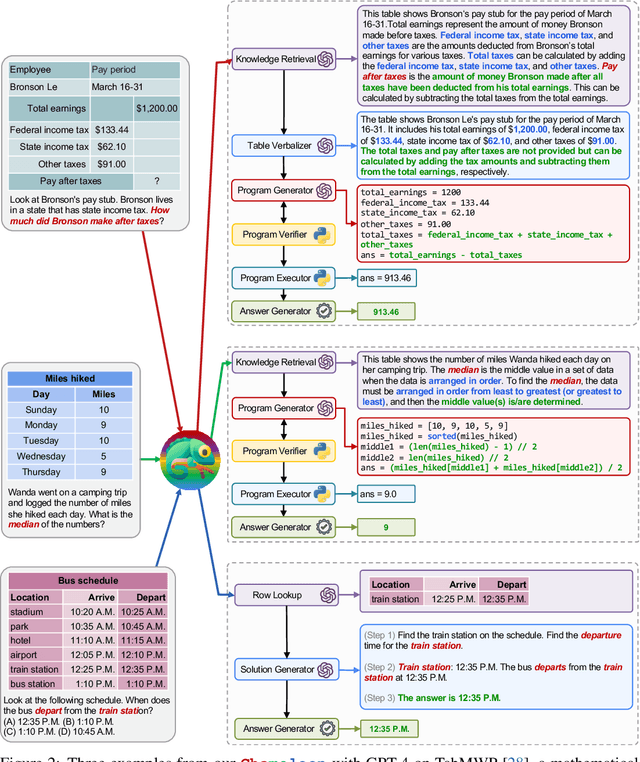


Large language models (LLMs) have achieved remarkable progress in various natural language processing tasks with emergent abilities. However, they face inherent limitations, such as an inability to access up-to-date information, utilize external tools, or perform precise mathematical reasoning. In this paper, we introduce Chameleon, a plug-and-play compositional reasoning framework that augments LLMs to help address these challenges. Chameleon synthesizes programs to compose various tools, including LLM models, off-the-shelf vision models, web search engines, Python functions, and rule-based modules tailored to user interests. Built on top of an LLM as a natural language planner, Chameleon infers the appropriate sequence of tools to compose and execute in order to generate a final response. We showcase the adaptability and effectiveness of Chameleon on two tasks: ScienceQA and TabMWP. Notably, Chameleon with GPT-4 achieves an 86.54% accuracy on ScienceQA, significantly improving upon the best published few-shot model by 11.37%; using GPT-4 as the underlying LLM, Chameleon achieves a 17.8% increase over the state-of-the-art model, leading to a 98.78% overall accuracy on TabMWP. Further studies suggest that using GPT-4 as a planner exhibits more consistent and rational tool selection and is able to infer potential constraints given the instructions, compared to other LLMs like ChatGPT.
DORT: Modeling Dynamic Objects in Recurrent for Multi-Camera 3D Object Detection and Tracking
Apr 19, 2023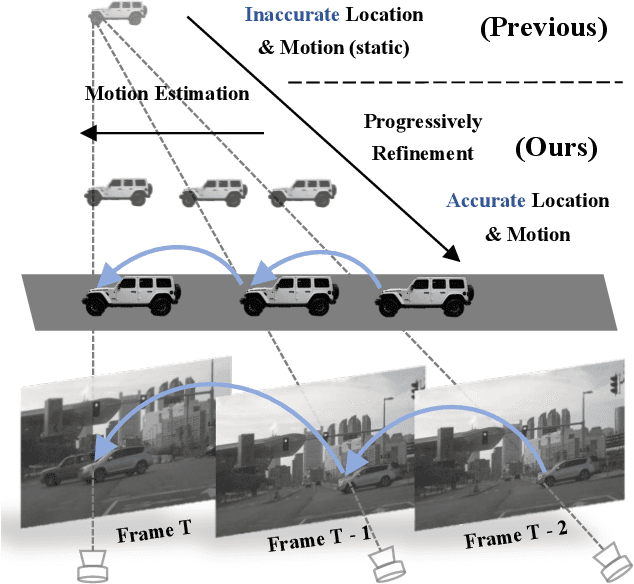
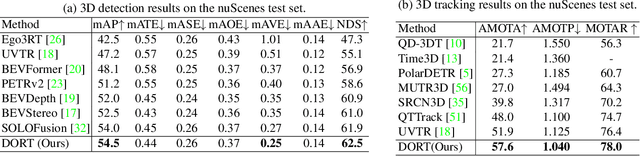
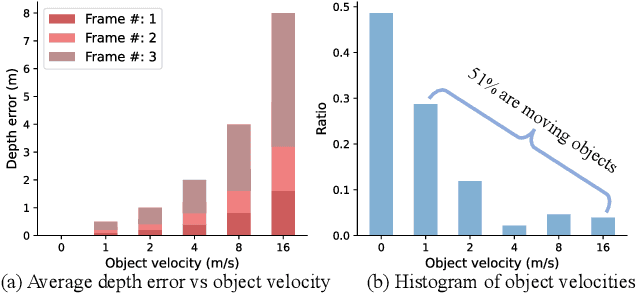
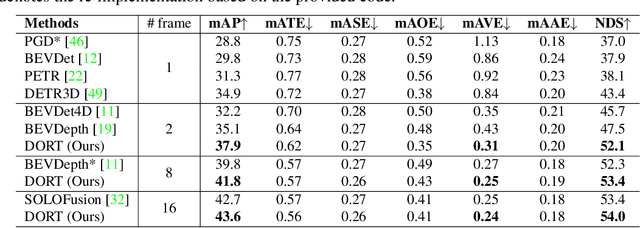
Recent multi-camera 3D object detectors usually leverage temporal information to construct multi-view stereo that alleviates the ill-posed depth estimation. However, they typically assume all the objects are static and directly aggregate features across frames. This work begins with a theoretical and empirical analysis to reveal that ignoring the motion of moving objects can result in serious localization bias. Therefore, we propose to model Dynamic Objects in RecurrenT (DORT) to tackle this problem. In contrast to previous global Bird-Eye-View (BEV) methods, DORT extracts object-wise local volumes for motion estimation that also alleviates the heavy computational burden. By iteratively refining the estimated object motion and location, the preceding features can be precisely aggregated to the current frame to mitigate the aforementioned adverse effects. The simple framework has two significant appealing properties. It is flexible and practical that can be plugged into most camera-based 3D object detectors. As there are predictions of object motion in the loop, it can easily track objects across frames according to their nearest center distances. Without bells and whistles, DORT outperforms all the previous methods on the nuScenes detection and tracking benchmarks with 62.5\% NDS and 57.6\% AMOTA, respectively. The source code will be released.
An Ecosystem for Personal Knowledge Graphs: A Survey and Research Roadmap
Apr 19, 2023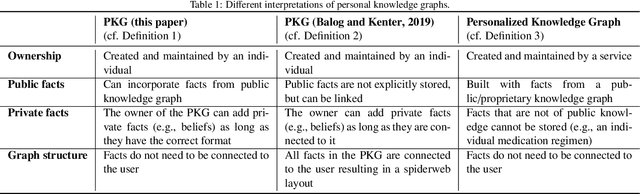
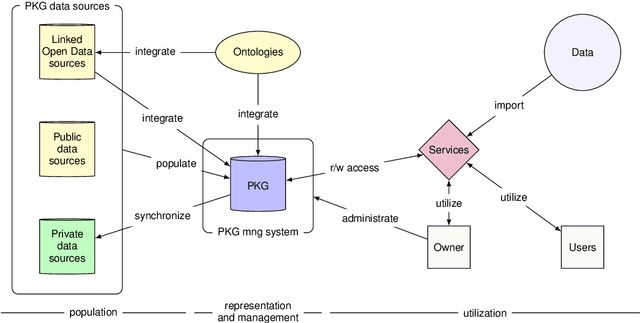
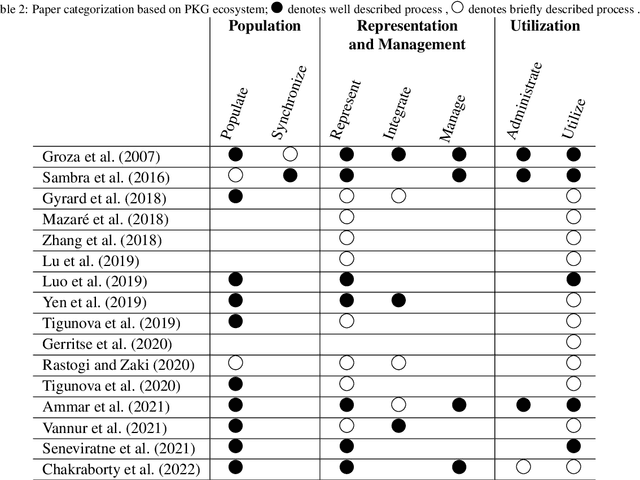
This paper presents an ecosystem for personal knowledge graphs (PKG), commonly defined as resources of structured information about entities related to an individual, their attributes, and the relations between them. PKGs are a key enabler of secure and sophisticated personal data management and personalized services. However, there are challenges that need to be addressed before PKGs can achieve widespread adoption. One of the fundamental challenges is the very definition of what constitutes a PKG, as there are multiple interpretations of the term. We propose our own definition of a PKG, emphasizing the aspects of (1) data ownership by a single individual and (2) the delivery of personalized services as the primary purpose. We further argue that a holistic view of PKGs is needed to unlock their full potential, and propose a unified framework for PKGs, where the PKG is a part of a larger ecosystem with clear interfaces towards data services and data sources. A comprehensive survey and synthesis of existing work is conducted, with a mapping of the surveyed work into the proposed unified ecosystem. Finally, we identify open challenges and research opportunities for the ecosystem as a whole, as well as for the specific aspects of PKGs, which include population, representation and management, and utilization.
Model Based Reinforcement Learning for Personalized Heparin Dosing
Apr 19, 2023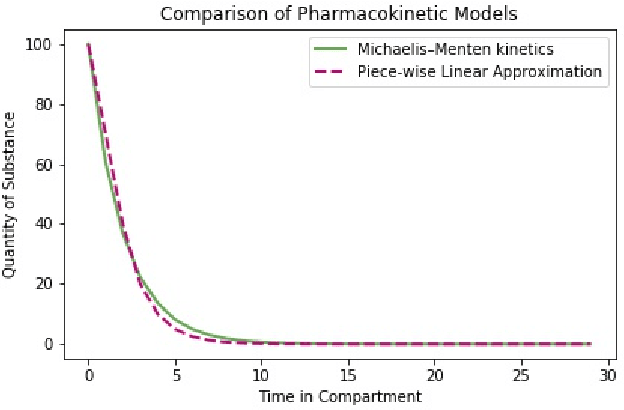
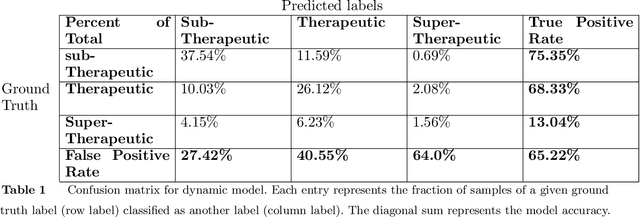
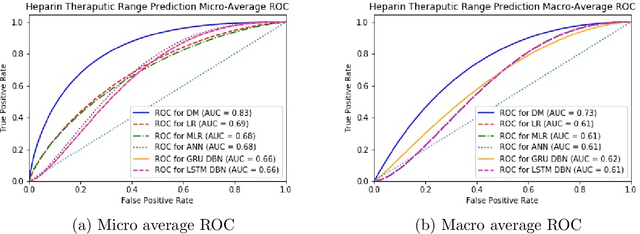
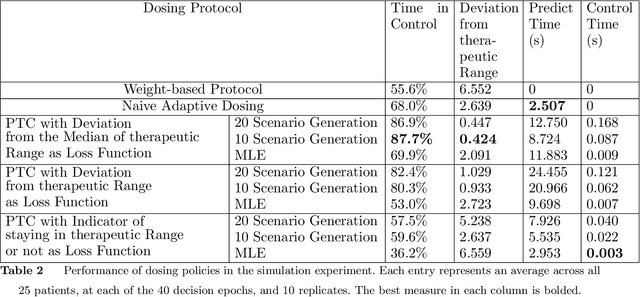
A key challenge in sequential decision making is optimizing systems safely under partial information. While much of the literature has focused on the cases of either partially known states or partially known dynamics, it is further exacerbated in cases where both states and dynamics are partially known. Computing heparin doses for patients fits this paradigm since the concentration of heparin in the patient cannot be measured directly and the rates at which patients metabolize heparin vary greatly between individuals. While many proposed solutions are model free, they require complex models and have difficulty ensuring safety. However, if some of the structure of the dynamics is known, a model based approach can be leveraged to provide safe policies. In this paper we propose such a framework to address the challenge of optimizing personalized heparin doses. We use a predictive model parameterized individually by patient to predict future therapeutic effects. We then leverage this model using a scenario generation based approach that is capable of ensuring patient safety. We validate our models with numerical experiments by comparing the predictive capabilities of our model against existing machine learning techniques and demonstrating how our dosing algorithm can treat patients in a simulated ICU environment.
Biologically inspired structure learning with reverse knowledge distillation for spiking neural networks
Apr 19, 2023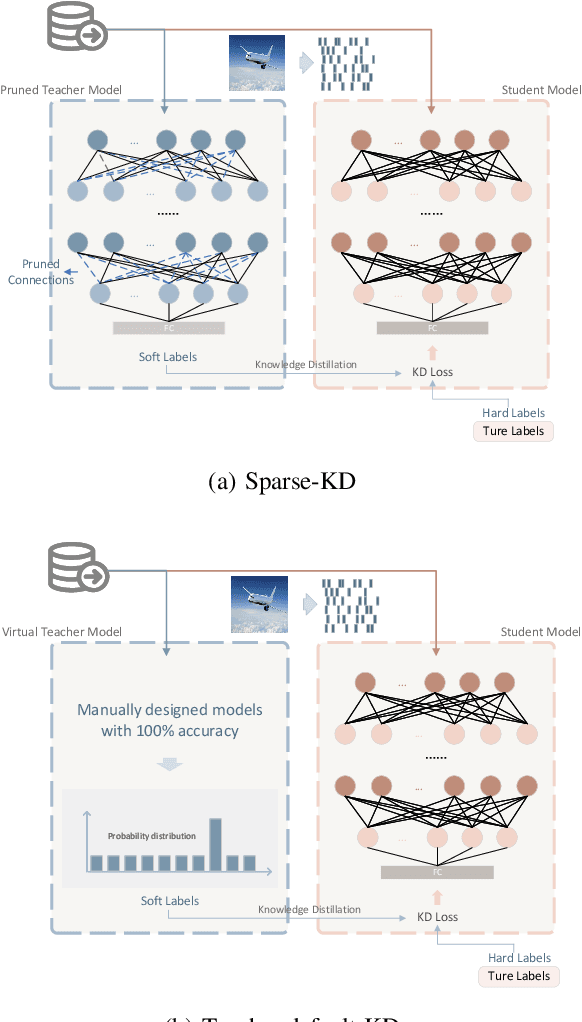
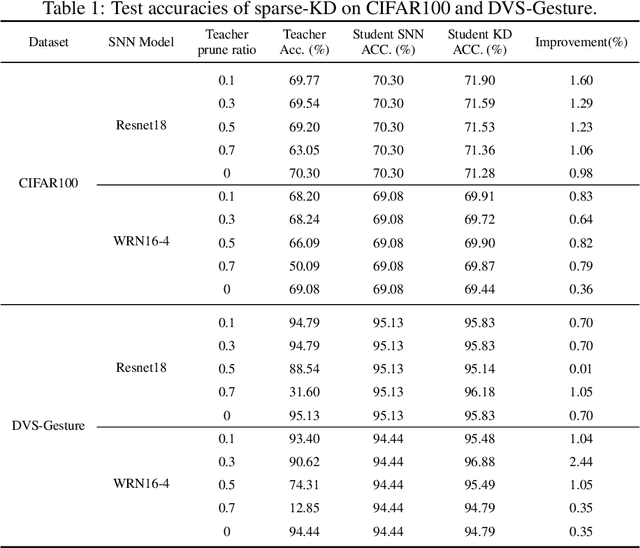
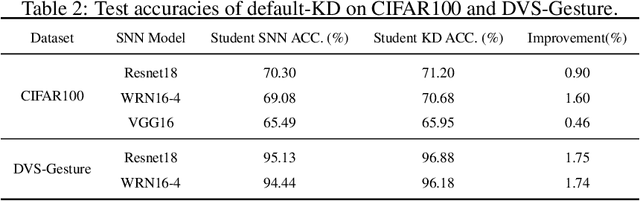
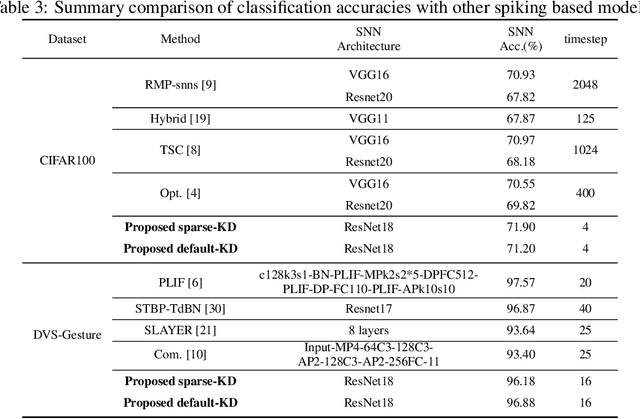
Spiking neural networks (SNNs) have superb characteristics in sensory information recognition tasks due to their biological plausibility. However, the performance of some current spiking-based models is limited by their structures which means either fully connected or too-deep structures bring too much redundancy. This redundancy from both connection and neurons is one of the key factors hindering the practical application of SNNs. Although Some pruning methods were proposed to tackle this problem, they normally ignored the fact the neural topology in the human brain could be adjusted dynamically. Inspired by this, this paper proposed an evolutionary-based structure construction method for constructing more reasonable SNNs. By integrating the knowledge distillation and connection pruning method, the synaptic connections in SNNs can be optimized dynamically to reach an optimal state. As a result, the structure of SNNs could not only absorb knowledge from the teacher model but also search for deep but sparse network topology. Experimental results on CIFAR100 and DVS-Gesture show that the proposed structure learning method can get pretty well performance while reducing the connection redundancy. The proposed method explores a novel dynamical way for structure learning from scratch in SNNs which could build a bridge to close the gap between deep learning and bio-inspired neural dynamics.
Uncertainty-Aware Reward-based Deep Reinforcement Learning for Intent Analysis of Social Media Information
Feb 19, 2023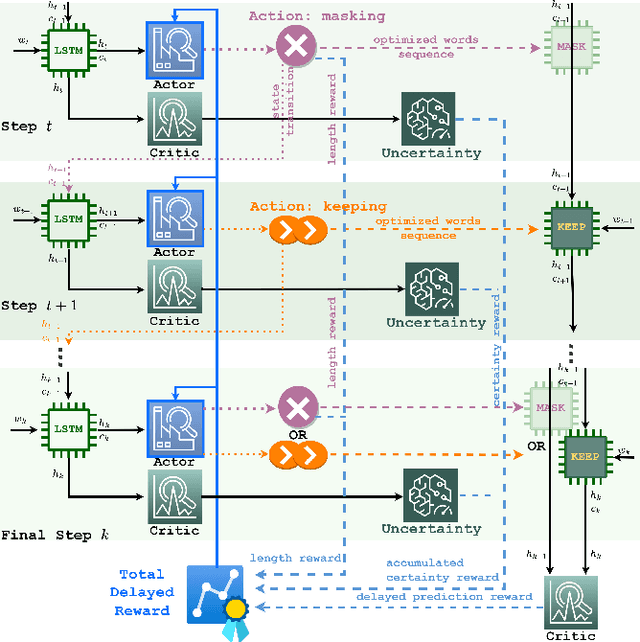
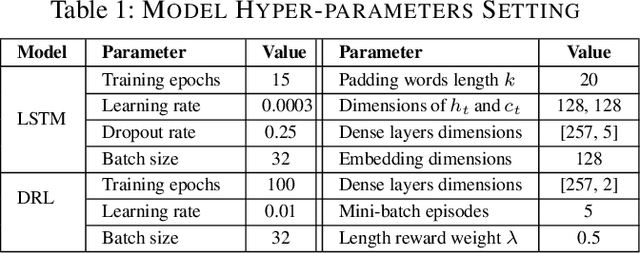
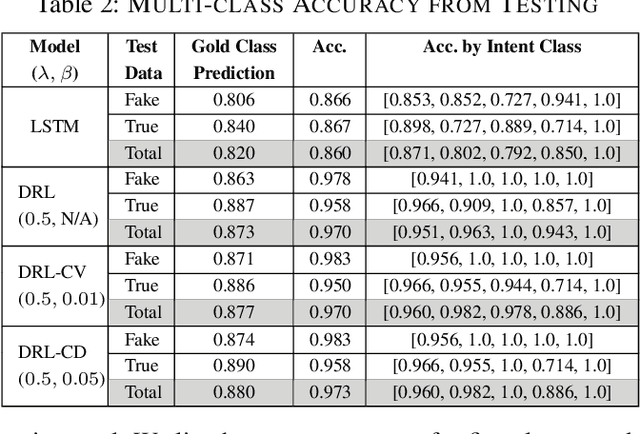
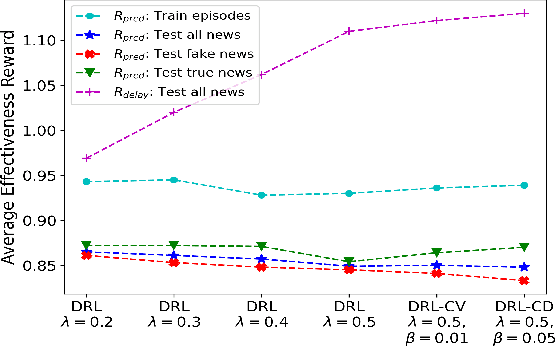
Due to various and serious adverse impacts of spreading fake news, it is often known that only people with malicious intent would propagate fake news. However, it is not necessarily true based on social science studies. Distinguishing the types of fake news spreaders based on their intent is critical because it will effectively guide how to intervene to mitigate the spread of fake news with different approaches. To this end, we propose an intent classification framework that can best identify the correct intent of fake news. We will leverage deep reinforcement learning (DRL) that can optimize the structural representation of each tweet by removing noisy words from the input sequence when appending an actor to the long short-term memory (LSTM) intent classifier. Policy gradient DRL model (e.g., REINFORCE) can lead the actor to a higher delayed reward. We also devise a new uncertainty-aware immediate reward using a subjective opinion that can explicitly deal with multidimensional uncertainty for effective decision-making. Via 600K training episodes from a fake news tweets dataset with an annotated intent class, we evaluate the performance of uncertainty-aware reward in DRL. Evaluation results demonstrate that our proposed framework efficiently reduces the number of selected words to maintain a high 95\% multi-class accuracy.
Using Geographic Location-based Public Health Features in Survival Analysis
Apr 16, 2023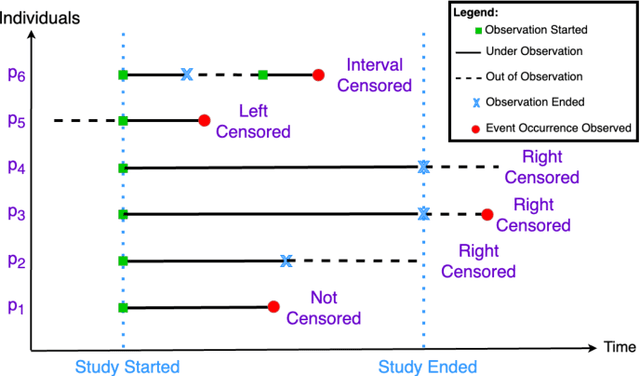
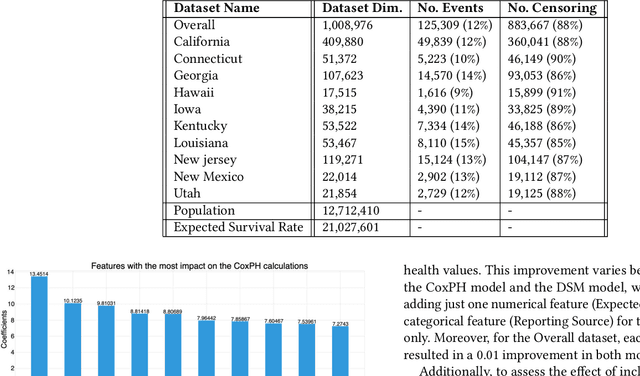

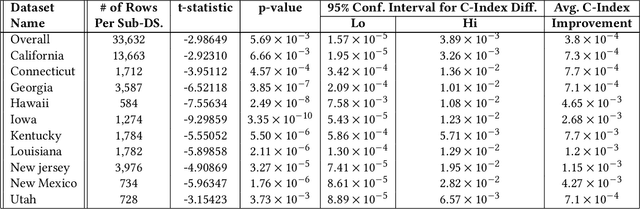
Time elapsed till an event of interest is often modeled using the survival analysis methodology, which estimates a survival score based on the input features. There is a resurgence of interest in developing more accurate prediction models for time-to-event prediction in personalized healthcare using modern tools such as neural networks. Higher quality features and more frequent observations improve the predictions for a patient, however, the impact of including a patient's geographic location-based public health statistics on individual predictions has not been studied. This paper proposes a complementary improvement to survival analysis models by incorporating public health statistics in the input features. We show that including geographic location-based public health information results in a statistically significant improvement in the concordance index evaluated on the Surveillance, Epidemiology, and End Results (SEER) dataset containing nationwide cancer incidence data. The improvement holds for both the standard Cox proportional hazards model and the state-of-the-art Deep Survival Machines model. Our results indicate the utility of geographic location-based public health features in survival analysis.