 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Deepfakes We Missed: We Built Detectors for a Threat That Didn't Arrive
May 12, 2026Nearly a decade of Machine Learning (ML) research on deepfake detection has been organized around a threat model inherited from 2017--2019, revolving around face-swap and talking-head manipulation of public figures, motivated by concerns about large-scale misinformation and video-evidence fraud. This position paper argues that the threat the field prepared for did not arrive, and the threats that did arrive are substantially different. An accounting of deepfake incidents in 2022--2026 shows that the dominant observed harms are peer-generated Non-Consensual Intimate Imagery (NCII), voice-clone scam calls targeting families and finance workers, and emotional-manipulation fraud. The predicted large-scale public-figure deepfake catastrophe did not materialize during the 2024 global information environment despite extensive preparation. Meanwhile, research effort, benchmarks, and detection methods remain concentrated on the inherited threat model. The central claim of this paper is that this misalignment is now the dominant bottleneck on real-world deepfake defense, not model capability. We argue the ML research community should substantially rebalance its research agenda toward the harm categories that are actually growing. We support this position with empirical accounting of research effort and harm distribution, identify the structural reasons the misalignment persists, and outline three concrete technical research agendas for the under-defended harm categories.
Towards Responsible Multimodal Medical Reasoning via Context-Aligned Vision-Language Models
Apr 09, 2026Medical vision-language models (VLMs) show strong performance on radiology tasks but often produce fluent yet weakly grounded conclusions due to over-reliance on a dominant modality. We introduce a context-aligned reasoning framework that enforces agreement across heterogeneous clinical evidence before generating diagnostic conclusions. The proposed approach augments a frozen VLM with structured contextual signals derived from radiomic statistics, explainability activations, and vocabulary-grounded semantic cues. Instead of producing free-form responses, the model generates structured outputs containing supporting evidence, uncertainty estimates, limitations, and safety notes. We observe that auxiliary signals alone provide limited benefit; performance gains emerge only when these signals are integrated through contextual verification. Experiments on chest X-ray datasets demonstrate that context alignment improves discriminative performance (AUC 0.918 to 0.925) while maintaining calibrated uncertainty. The framework also substantially reduces hallucinated keywords (1.14 to 0.25) and produces more concise reasoning explanations (19.4 to 15.3 words) without increasing model confidence (0.70 to 0.68). Cross-dataset evaluation on CheXpert further reveals that modality informativeness significantly influences reasoning behavior. These results suggest that enforcing multi-evidence agreement improves both reliability and trustworthiness in medical multimodal reasoning, while preserving the underlying model architecture.
From Features to Actions: Explainability in Traditional and Agentic AI Systems
Feb 09, 2026Over the last decade, explainable AI has primarily focused on interpreting individual model predictions, producing post-hoc explanations that relate inputs to outputs under a fixed decision structure. Recent advances in large language models (LLMs) have enabled agentic AI systems whose behaviour unfolds over multi-step trajectories. In these settings, success and failure are determined by sequences of decisions rather than a single output. While useful, it remains unclear how explanation approaches designed for static predictions translate to agentic settings where behaviour emerges over time. In this work, we bridge the gap between static and agentic explainability by comparing attribution-based explanations with trace-based diagnostics across both settings. To make this distinction explicit, we empirically compare attribution-based explanations used in static classification tasks with trace-based diagnostics used in agentic benchmarks (TAU-bench Airline and AssistantBench). Our results show that while attribution methods achieve stable feature rankings in static settings (Spearman $ρ= 0.86$), they cannot be applied reliably to diagnose execution-level failures in agentic trajectories. In contrast, trace-grounded rubric evaluation for agentic settings consistently localizes behaviour breakdowns and reveals that state tracking inconsistency is 2.7$\times$ more prevalent in failed runs and reduces success probability by 49\%. These findings motivate a shift towards trajectory-level explainability for agentic systems when evaluating and diagnosing autonomous AI behaviour. Resources: https://github.com/VectorInstitute/unified-xai-evaluation-framework https://vectorinstitute.github.io/unified-xai-evaluation-framework
SONIC-O1: A Real-World Benchmark for Evaluating Multimodal Large Language Models on Audio-Video Understanding
Jan 29, 2026Multimodal Large Language Models (MLLMs) are a major focus of recent AI research. However, most prior work focuses on static image understanding, while their ability to process sequential audio-video data remains underexplored. This gap highlights the need for a high-quality benchmark to systematically evaluate MLLM performance in a real-world setting. We introduce SONIC-O1, a comprehensive, fully human-verified benchmark spanning 13 real-world conversational domains with 4,958 annotations and demographic metadata. SONIC-O1 evaluates MLLMs on key tasks, including open-ended summarization, multiple-choice question (MCQ) answering, and temporal localization with supporting rationales (reasoning). Experiments on closed- and open-source models reveal limitations. While the performance gap in MCQ accuracy between two model families is relatively small, we observe a substantial 22.6% performance difference in temporal localization between the best performing closed-source and open-source models. Performance further degrades across demographic groups, indicating persistent disparities in model behavior. Overall, SONIC-O1 provides an open evaluation suite for temporally grounded and socially robust multimodal understanding. We release SONIC-O1 for reproducibility and research: Project page: https://vectorinstitute.github.io/sonic-o1/ Dataset: https://huggingface.co/datasets/vector-institute/sonic-o1 Github: https://github.com/vectorinstitute/sonic-o1 Leaderboard: https://huggingface.co/spaces/vector-institute/sonic-o1-leaderboard
Reducing Hallucinations in LLMs via Factuality-Aware Preference Learning
Jan 06, 2026Preference alignment methods such as RLHF and Direct Preference Optimization (DPO) improve instruction following, but they can also reinforce hallucinations when preference judgments reward fluency and confidence over factual correctness. We introduce F-DPO (Factuality-aware Direct Preference Optimization), a simple extension of DPO that uses only binary factuality labels. F-DPO (i) applies a label-flipping transformation that corrects misordered preference pairs so the chosen response is never less factual than the rejected one, and (ii) adds a factuality-aware margin that emphasizes pairs with clear correctness differences, while reducing to standard DPO when both responses share the same factuality. We construct factuality-aware preference data by augmenting DPO pairs with binary factuality indicators and synthetic hallucinated variants. Across seven open-weight LLMs (1B-14B), F-DPO consistently improves factuality and reduces hallucination rates relative to both base models and standard DPO. On Qwen3-8B, F-DPO reduces hallucination rates by five times (from 0.424 to 0.084) while improving factuality scores by 50 percent (from 5.26 to 7.90). F-DPO also generalizes to out-of-distribution benchmarks: on TruthfulQA, Qwen2.5-14B achieves plus 17 percent MC1 accuracy (0.500 to 0.585) and plus 49 percent MC2 accuracy (0.357 to 0.531). F-DPO requires no auxiliary reward model, token-level annotations, or multi-stage training.
LinguaMark: Do Multimodal Models Speak Fairly? A Benchmark-Based Evaluation
Jul 09, 2025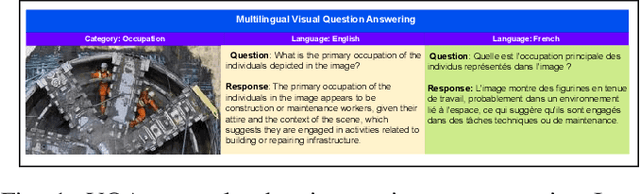
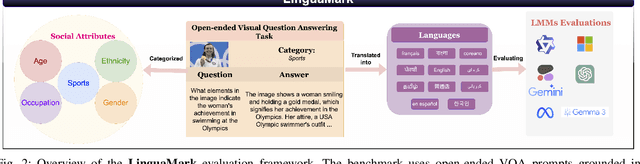


Large Multimodal Models (LMMs) are typically trained on vast corpora of image-text data but are often limited in linguistic coverage, leading to biased and unfair outputs across languages. While prior work has explored multimodal evaluation, less emphasis has been placed on assessing multilingual capabilities. In this work, we introduce LinguaMark, a benchmark designed to evaluate state-of-the-art LMMs on a multilingual Visual Question Answering (VQA) task. Our dataset comprises 6,875 image-text pairs spanning 11 languages and five social attributes. We evaluate models using three key metrics: Bias, Answer Relevancy, and Faithfulness. Our findings reveal that closed-source models generally achieve the highest overall performance. Both closed-source (GPT-4o and Gemini2.5) and open-source models (Gemma3, Qwen2.5) perform competitively across social attributes, and Qwen2.5 demonstrates strong generalization across multiple languages. We release our benchmark and evaluation code to encourage reproducibility and further research.
Thinking Beyond Tokens: From Brain-Inspired Intelligence to Cognitive Foundations for Artificial General Intelligence and its Societal Impact
Jul 01, 2025



Can machines truly think, reason and act in domains like humans? This enduring question continues to shape the pursuit of Artificial General Intelligence (AGI). Despite the growing capabilities of models such as GPT-4.5, DeepSeek, Claude 3.5 Sonnet, Phi-4, and Grok 3, which exhibit multimodal fluency and partial reasoning, these systems remain fundamentally limited by their reliance on token-level prediction and lack of grounded agency. This paper offers a cross-disciplinary synthesis of AGI development, spanning artificial intelligence, cognitive neuroscience, psychology, generative models, and agent-based systems. We analyze the architectural and cognitive foundations of general intelligence, highlighting the role of modular reasoning, persistent memory, and multi-agent coordination. In particular, we emphasize the rise of Agentic RAG frameworks that combine retrieval, planning, and dynamic tool use to enable more adaptive behavior. We discuss generalization strategies, including information compression, test-time adaptation, and training-free methods, as critical pathways toward flexible, domain-agnostic intelligence. Vision-Language Models (VLMs) are reexamined not just as perception modules but as evolving interfaces for embodied understanding and collaborative task completion. We also argue that true intelligence arises not from scale alone but from the integration of memory and reasoning: an orchestration of modular, interactive, and self-improving components where compression enables adaptive behavior. Drawing on advances in neurosymbolic systems, reinforcement learning, and cognitive scaffolding, we explore how recent architectures begin to bridge the gap between statistical learning and goal-directed cognition. Finally, we identify key scientific, technical, and ethical challenges on the path to AGI.
TRiSM for Agentic AI: A Review of Trust, Risk, and Security Management in LLM-based Agentic Multi-Agent Systems
Jun 04, 2025



Agentic AI systems, built on large language models (LLMs) and deployed in multi-agent configurations, are redefining intelligent autonomy, collaboration and decision-making across enterprise and societal domains. This review presents a structured analysis of Trust, Risk, and Security Management (TRiSM) in the context of LLM-based agentic multi-agent systems (AMAS). We begin by examining the conceptual foundations of agentic AI, its architectural differences from traditional AI agents, and the emerging system designs that enable scalable, tool-using autonomy. The TRiSM in the agentic AI framework is then detailed through four pillars governance, explainability, ModelOps, and privacy/security each contextualized for agentic LLMs. We identify unique threat vectors and introduce a comprehensive risk taxonomy for the agentic AI applications, supported by case studies illustrating real-world vulnerabilities. Furthermore, the paper also surveys trust-building mechanisms, transparency and oversight techniques, and state-of-the-art explainability strategies in distributed LLM agent systems. Additionally, metrics for evaluating trust, interpretability, and human-centered performance are reviewed alongside open benchmarking challenges. Security and privacy are addressed through encryption, adversarial defense, and compliance with evolving AI regulations. The paper concludes with a roadmap for responsible agentic AI, proposing research directions to align emerging multi-agent systems with robust TRiSM principles for safe, accountable, and transparent deployment.
Just as Humans Need Vaccines, So Do Models: Model Immunization to Combat Falsehoods
May 23, 2025Generative AI models often learn and reproduce false information present in their training corpora. This position paper argues that, analogous to biological immunization, where controlled exposure to a weakened pathogen builds immunity, AI models should be fine tuned on small, quarantined sets of explicitly labeled falsehoods as a "vaccine" against misinformation. These curated false examples are periodically injected during finetuning, strengthening the model ability to recognize and reject misleading claims while preserving accuracy on truthful inputs. An illustrative case study shows that immunized models generate substantially less misinformation than baselines. To our knowledge, this is the first training framework that treats fact checked falsehoods themselves as a supervised vaccine, rather than relying on input perturbations or generic human feedback signals, to harden models against future misinformation. We also outline ethical safeguards and governance controls to ensure the safe use of false data. Model immunization offers a proactive paradigm for aligning AI systems with factuality.
HumaniBench: A Human-Centric Framework for Large Multimodal Models Evaluation
May 16, 2025



Large multimodal models (LMMs) now excel on many vision language benchmarks, however, they still struggle with human centered criteria such as fairness, ethics, empathy, and inclusivity, key to aligning with human values. We introduce HumaniBench, a holistic benchmark of 32K real-world image question pairs, annotated via a scalable GPT4o assisted pipeline and exhaustively verified by domain experts. HumaniBench evaluates seven Human Centered AI (HCAI) principles: fairness, ethics, understanding, reasoning, language inclusivity, empathy, and robustness, across seven diverse tasks, including open and closed ended visual question answering (VQA), multilingual QA, visual grounding, empathetic captioning, and robustness tests. Benchmarking 15 state of the art LMMs (open and closed source) reveals that proprietary models generally lead, though robustness and visual grounding remain weak points. Some open-source models also struggle to balance accuracy with adherence to human-aligned principles. HumaniBench is the first benchmark purpose built around HCAI principles. It provides a rigorous testbed for diagnosing alignment gaps and guiding LMMs toward behavior that is both accurate and socially responsible. Dataset, annotation prompts, and evaluation code are available at: https://vectorinstitute.github.io/HumaniBench