 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistent Cross-Attempt State Optimization for Repository-Level Code Generation
Apr 04, 2026Large language models (LLMs) have achieved substantial progress in repository-level code generation. However, solving the same repository-level task often requires multiple attempts, while existing methods still optimize each attempt in isolation and do not preserve or reuse task-specific state across attempts. In this paper, we propose LiveCoder, a novel framework for repository-level code generation based on cross-attempt knowledge optimization. LiveCoder maintains persistent task-specific state from prior attempts to guide subsequent generation. This state includes success knowledge, which captures reusable signals from previously strong repositories, failure knowledge, which records unsuccessful outcomes and their diagnostic signals, and a historical-best repository, which preserves the strongest result found so far and prevents regression. These components collectively transform repeated repository generation into a persistent, knowledge-driven optimization process. We evaluate LiveCoder using four frontier LLMs on two representative repository-level code generation benchmarks. Extensive experimental results demonstrate the effectiveness and efficiency of LiveCoder, improving the functional score by up to 22.94 percentage points, increasing repository reuse to 81.58%, and reducing cost by up to 53.63% on RAL-Bench while maintaining broadly stable non-functional quality.
Uncertainty-Aware Reward-based Deep Reinforcement Learning for Intent Analysis of Social Media Information
Feb 19, 2023Due to various and serious adverse impacts of spreading fake news, it is often known that only people with malicious intent would propagate fake news. However, it is not necessarily true based on social science studies. Distinguishing the types of fake news spreaders based on their intent is critical because it will effectively guide how to intervene to mitigate the spread of fake news with different approaches. To this end, we propose an intent classification framework that can best identify the correct intent of fake news. We will leverage deep reinforcement learning (DRL) that can optimize the structural representation of each tweet by removing noisy words from the input sequence when appending an actor to the long short-term memory (LSTM) intent classifier. Policy gradient DRL model (e.g., REINFORCE) can lead the actor to a higher delayed reward. We also devise a new uncertainty-aware immediate reward using a subjective opinion that can explicitly deal with multidimensional uncertainty for effective decision-making. Via 600K training episodes from a fake news tweets dataset with an annotated intent class, we evaluate the performance of uncertainty-aware reward in DRL. Evaluation results demonstrate that our proposed framework efficiently reduces the number of selected words to maintain a high 95\% multi-class accuracy.
PPO-UE: Proximal Policy Optimization via Uncertainty-Aware Exploration
Dec 13, 2022Proximal Policy Optimization (PPO) is a highly popular policy-based deep reinforcement learning (DRL) approach. However, we observe that the homogeneous exploration process in PPO could cause an unexpected stability issue in the training phase. To address this issue, we propose PPO-UE, a PPO variant equipped with self-adaptive uncertainty-aware explorations (UEs) based on a ratio uncertainty level. The proposed PPO-UE is designed to improve convergence speed and performance with an optimized ratio uncertainty level. Through extensive sensitivity analysis by varying the ratio uncertainty level, our proposed PPO-UE considerably outperforms the baseline PPO in Roboschool continuous control tasks.
A Survey on Uncertainty Reasoning and Quantification for Decision Making: Belief Theory Meets Deep Learning
Jun 14, 2022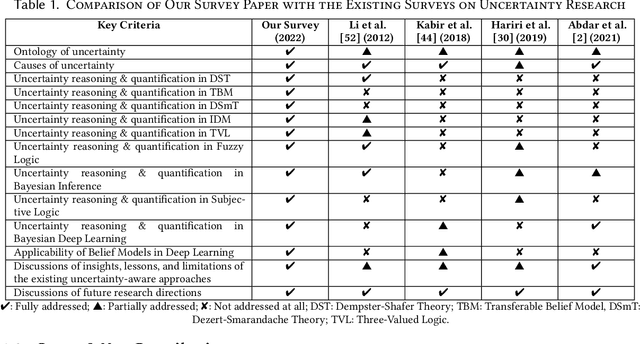
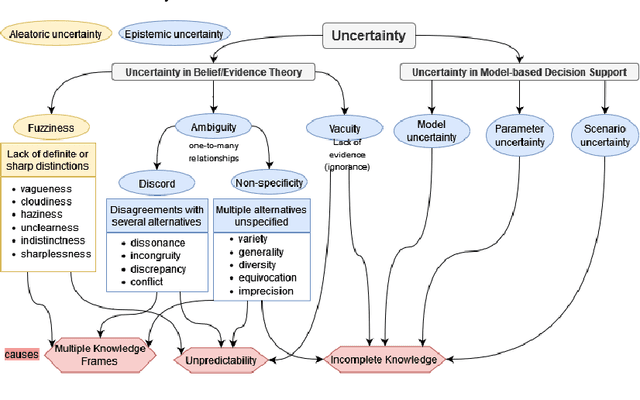
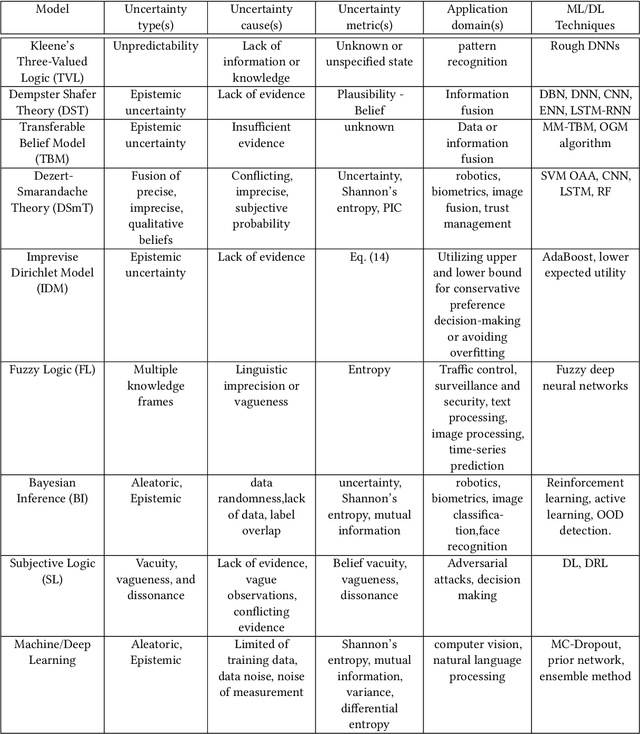
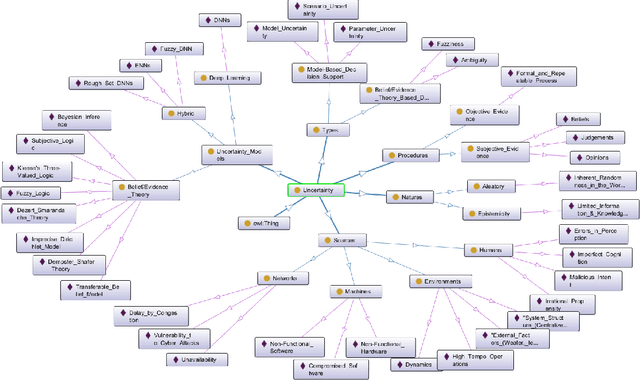
An in-depth understanding of uncertainty is the first step to making effective decisions under uncertainty. Deep/machine learning (ML/DL) has been hugely leveraged to solve complex problems involved with processing high-dimensional data. However, reasoning and quantifying different types of uncertainties to achieve effective decision-making have been much less explored in ML/DL than in other Artificial Intelligence (AI) domains. In particular, belief/evidence theories have been studied in KRR since the 1960s to reason and measure uncertainties to enhance decision-making effectiveness. We found that only a few studies have leveraged the mature uncertainty research in belief/evidence theories in ML/DL to tackle complex problems under different types of uncertainty. In this survey paper, we discuss several popular belief theories and their core ideas dealing with uncertainty causes and types and quantifying them, along with the discussions of their applicability in ML/DL. In addition, we discuss three main approaches that leverage belief theories in Deep Neural Networks (DNNs), including Evidential DNNs, Fuzzy DNNs, and Rough DNNs, in terms of their uncertainty causes, types, and quantification methods along with their applicability in diverse problem domains. Based on our in-depth survey, we discuss insights, lessons learned, limitations of the current state-of-the-art bridging belief theories and ML/DL, and finally, future research directions.