 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Instrumental Variable Learning for Chest X-ray Classification
May 20, 2023
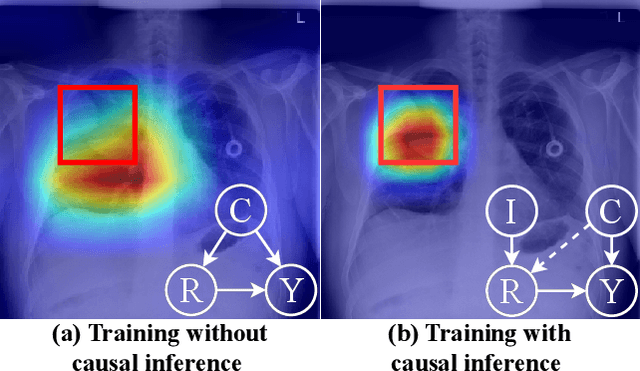
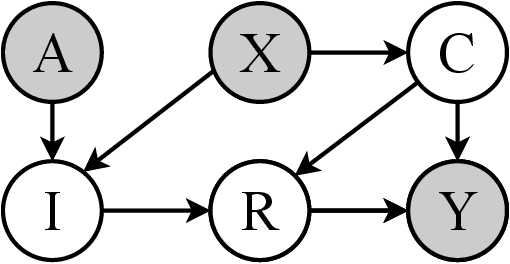
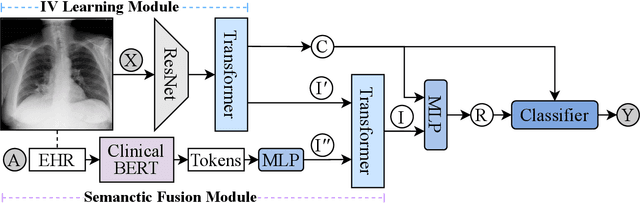
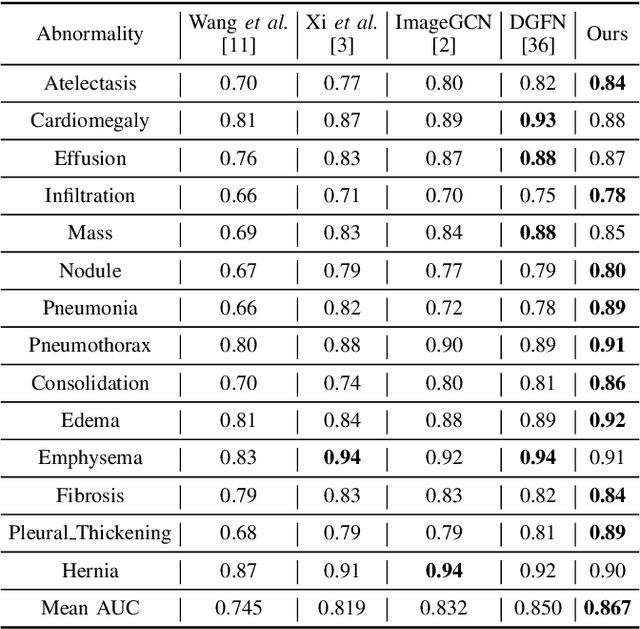
The chest X-ray (CXR) is commonly employed to diagnose thoracic illnesses, but the challenge of achieving accurate automatic diagnosis through this method persists due to the complex relationship between pathology. In recent years, various deep learning-based approaches have been suggested to tackle this problem but confounding factors such as image resolution or noise problems often damage model performance. In this paper, we focus on the chest X-ray classification task and proposed an interpretable instrumental variable (IV) learning framework, to eliminate the spurious association and obtain accurate causal representation. Specifically, we first construct a structural causal model (SCM) for our task and learn the confounders and the preliminary representations of IV, we then leverage electronic health record (EHR) as auxiliary information and we fuse the above feature with our transformer-based semantic fusion module, so the IV has the medical semantic. Meanwhile, the reliability of IV is further guaranteed via the constraints of mutual information between related causal variables. Finally, our approach's performance is demonstrated using the MIMIC-CXR, NIH ChestX-ray 14, and CheXpert datasets, and we achieve competitive results.
Deliberate then Generate: Enhanced Prompting Framework for Text Generation
May 31, 2023
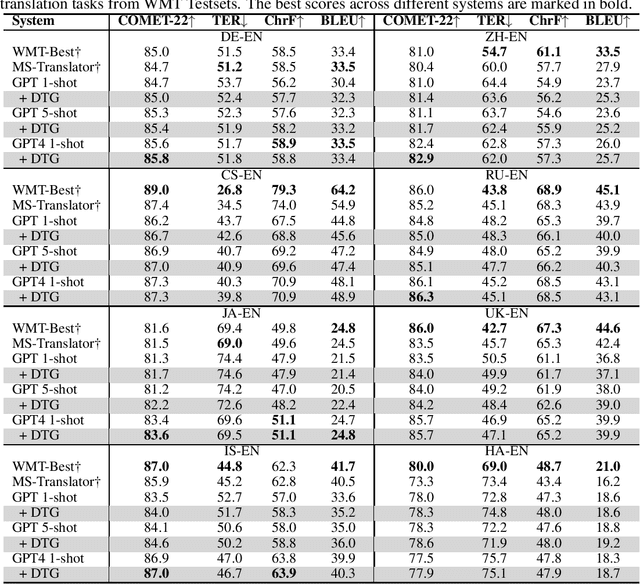

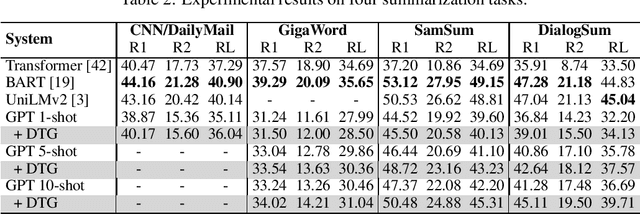
Large language models (LLMs) have shown remarkable success across a wide range of natural language generation tasks, where proper prompt designs make great impacts. While existing prompting methods are normally restricted to providing correct information, in this paper, we encourage the model to deliberate by proposing a novel Deliberate then Generate (DTG) prompting framework, which consists of error detection instructions and candidates that may contain errors. DTG is a simple yet effective technique that can be applied to various text generation tasks with minimal modifications. We conduct extensive experiments on 20+ datasets across 7 text generation tasks, including summarization, translation, dialogue, and more. We show that DTG consistently outperforms existing prompting methods and achieves state-of-the-art performance on multiple text generation tasks. We also provide in-depth analyses to reveal the underlying mechanisms of DTG, which may inspire future research on prompting for LLMs.
Causal discovery for time series with constraint-based model and PMIME measure
May 31, 2023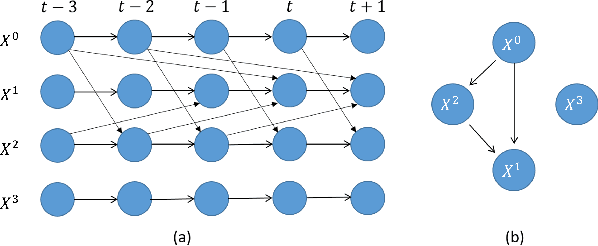
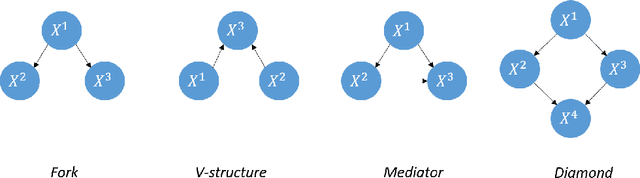
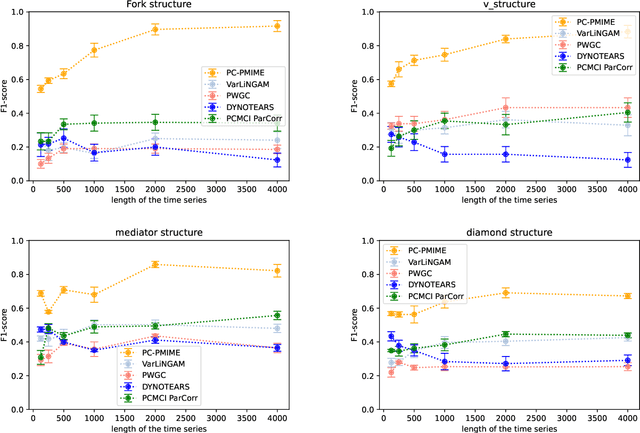
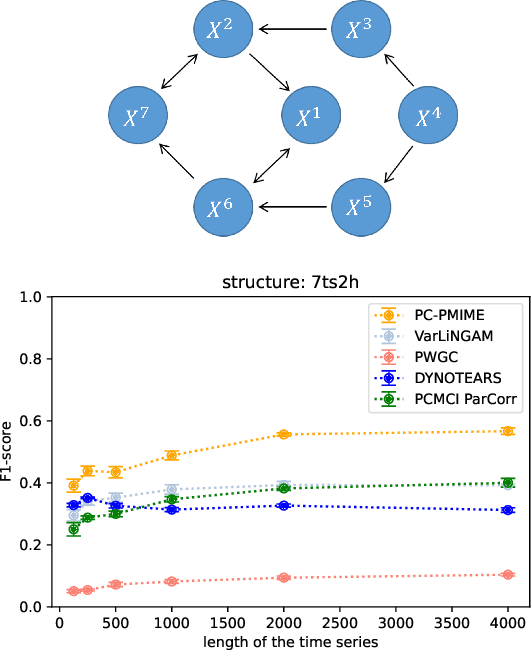
Causality defines the relationship between cause and effect. In multivariate time series field, this notion allows to characterize the links between several time series considering temporal lags. These phenomena are particularly important in medicine to analyze the effect of a drug for example, in manufacturing to detect the causes of an anomaly in a complex system or in social sciences... Most of the time, studying these complex systems is made through correlation only. But correlation can lead to spurious relationships. To circumvent this problem, we present in this paper a novel approach for discovering causality in time series data that combines a causal discovery algorithm with an information theoretic-based measure. Hence the proposed method allows inferring both linear and non-linear relationships and building the underlying causal graph. We evaluate the performance of our approach on several simulated data sets, showing promising results.
ViLaS: Integrating Vision and Language into Automatic Speech Recognition
May 31, 2023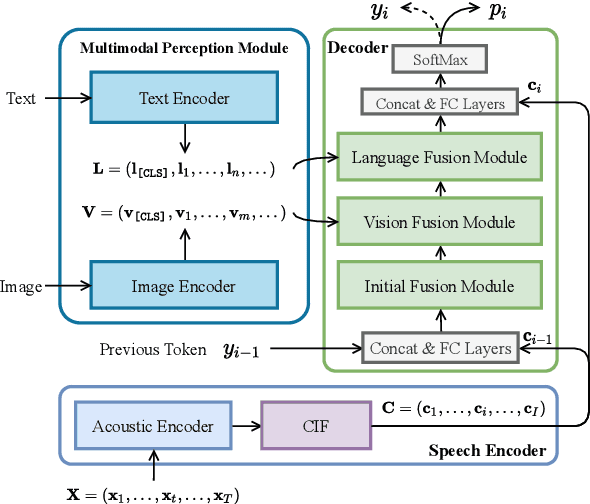
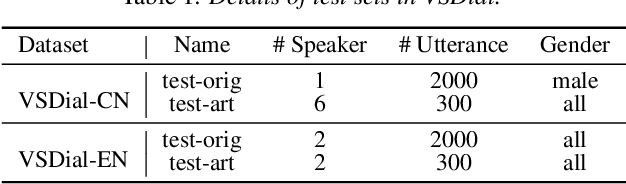
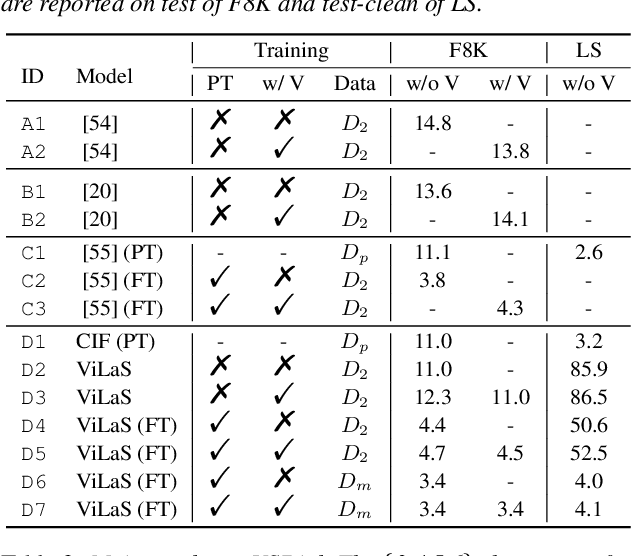
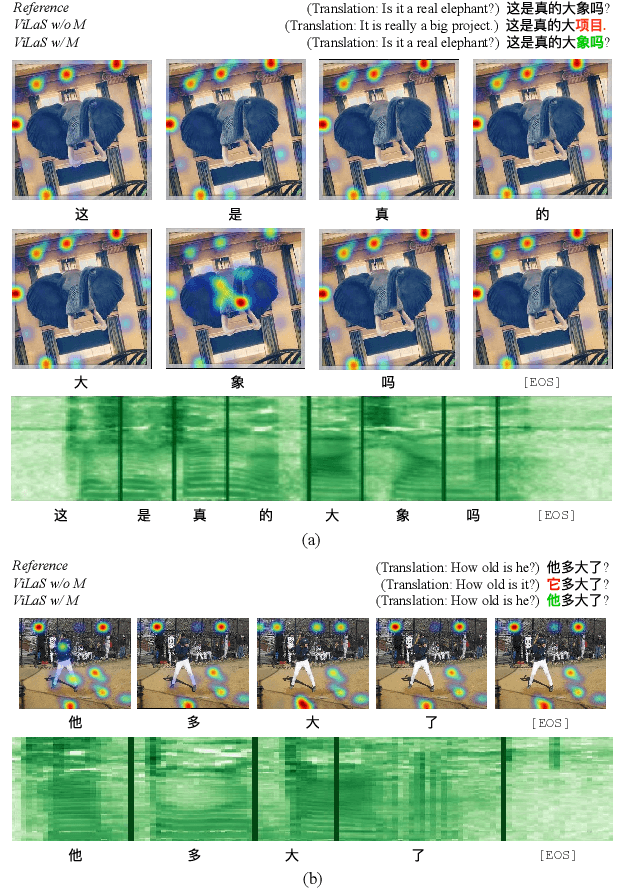
Employing additional multimodal information to improve automatic speech recognition (ASR) performance has been proven effective in previous works. However, many of these works focus only on the utilization of visual cues from human lip motion. In fact, context-dependent visual and linguistic cues can also be used to improve ASR performance in many scenarios. In this paper, we first propose a multimodal ASR model (ViLaS) that can simultaneously or separately integrate visual and linguistic cues to help recognize the input speech, and introduce a training strategy that can improve performance in modal-incomplete test scenarios. Then, we create a multimodal ASR dataset (VSDial) with visual and linguistic cues to explore the effects of integrating vision and language. Finally, we report empirical results on the public Flickr8K and self-constructed VSDial datasets, investigate cross-modal fusion schemes, and analyze fine-grained cross-modal alignment on VSDial.
Designing Closed-Loop Models for Task Allocation
May 31, 2023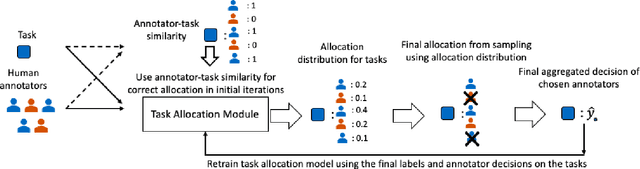
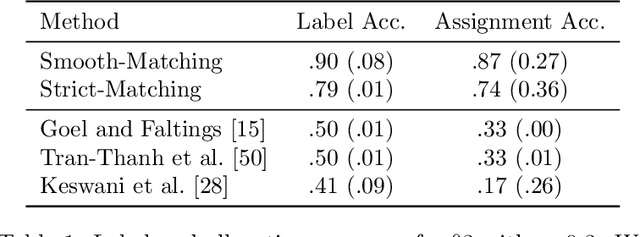

Automatically assigning tasks to people is challenging because human performance can vary across tasks for many reasons. This challenge is further compounded in real-life settings in which no oracle exists to assess the quality of human decisions and task assignments made. Instead, we find ourselves in a "closed" decision-making loop in which the same fallible human decisions we rely on in practice must also be used to guide task allocation. How can imperfect and potentially biased human decisions train an accurate allocation model? Our key insight is to exploit weak prior information on human-task similarity to bootstrap model training. We show that the use of such a weak prior can improve task allocation accuracy, even when human decision-makers are fallible and biased. We present both theoretical analysis and empirical evaluation over synthetic data and a social media toxicity detection task. Results demonstrate the efficacy of our approach.
Space Net Optimization
May 31, 2023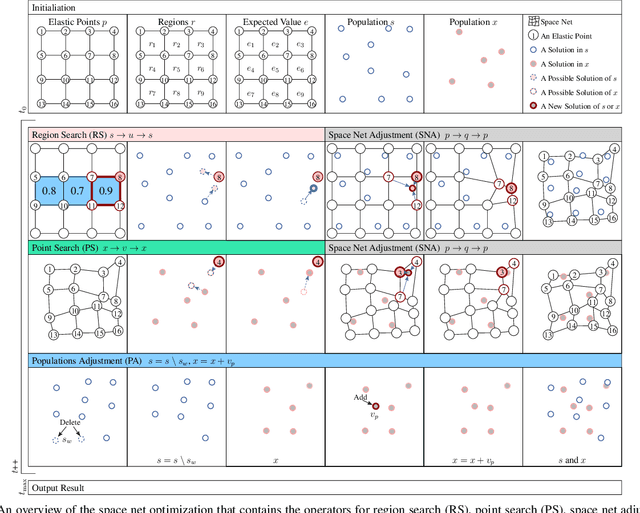

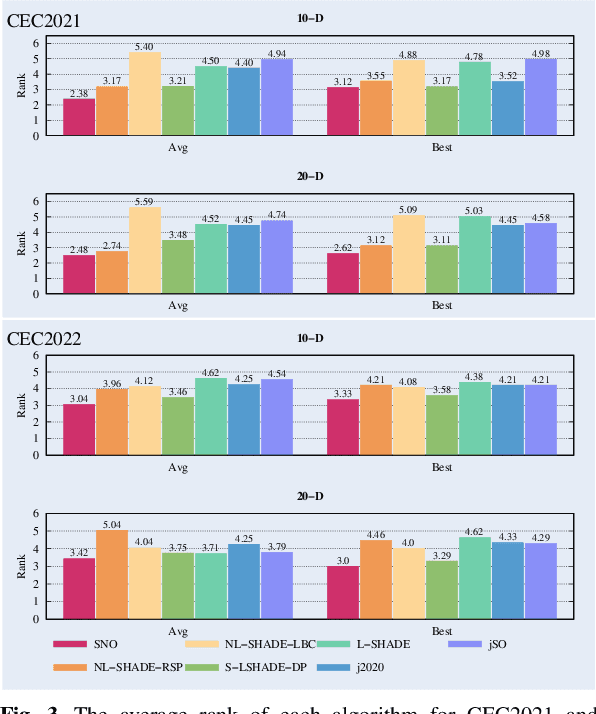
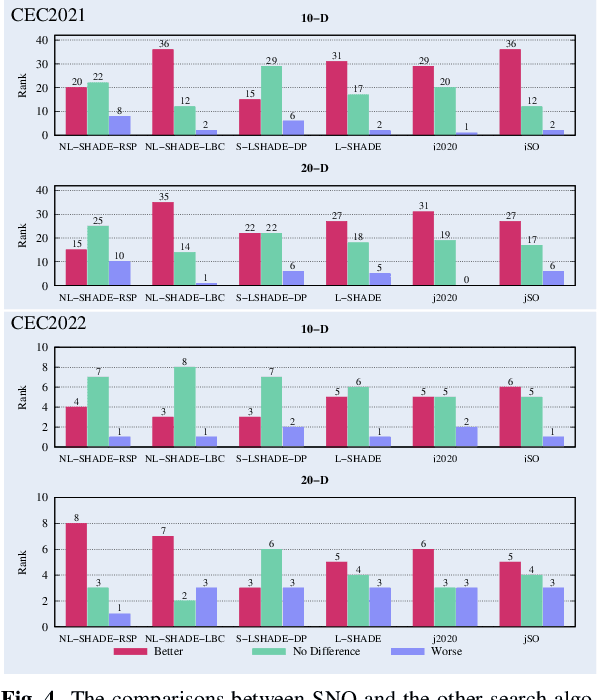
Most metaheuristic algorithms rely on a few searched solutions to guide later searches during the convergence process for a simple reason: the limited computing resource of a computer makes it impossible to retain all the searched solutions. This also reveals that each search of most metaheuristic algorithms is just like a ballpark guess. To help address this issue, we present a novel metaheuristic algorithm called space net optimization (SNO). It is equipped with a new mechanism called space net; thus, making it possible for a metaheuristic algorithm to use most information provided by all searched solutions to depict the landscape of the solution space. With the space net, a metaheuristic algorithm is kind of like having a ``vision'' on the solution space. Simulation results show that SNO outperforms all the other metaheuristic algorithms compared in this study for a set of well-known single objective bound constrained problems in most cases.
The Tag-Team Approach: Leveraging CLS and Language Tagging for Enhancing Multilingual ASR
May 31, 2023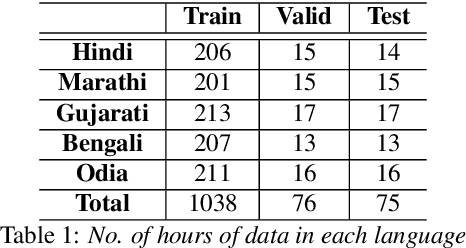

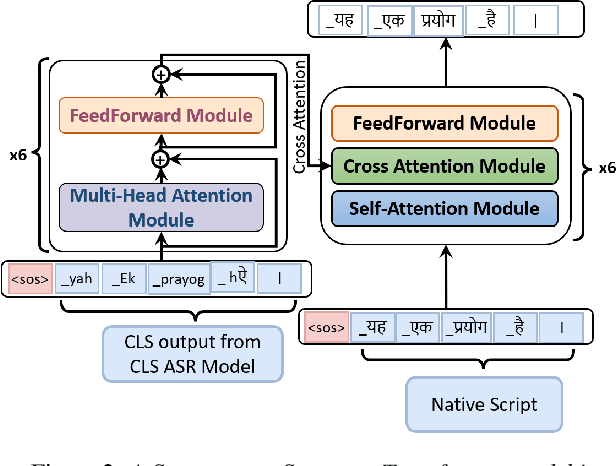

Building a multilingual Automated Speech Recognition (ASR) system in a linguistically diverse country like India can be a challenging task due to the differences in scripts and the limited availability of speech data. This problem can be solved by exploiting the fact that many of these languages are phonetically similar. These languages can be converted into a Common Label Set (CLS) by mapping similar sounds to common labels. In this paper, new approaches are explored and compared to improve the performance of CLS based multilingual ASR model. Specific language information is infused in the ASR model by giving Language ID or using CLS to Native script converter on top of the CLS Multilingual model. These methods give a significant improvement in Word Error Rate (WER) compared to the CLS baseline. These methods are further tried on out-of-distribution data to check their robustness.
Risk-limiting Financial Audits via Weighted Sampling without Replacement
May 08, 2023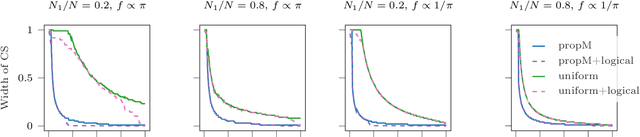
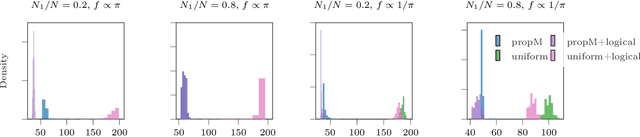
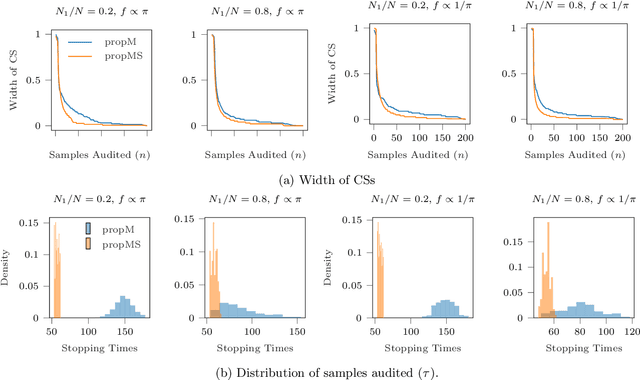
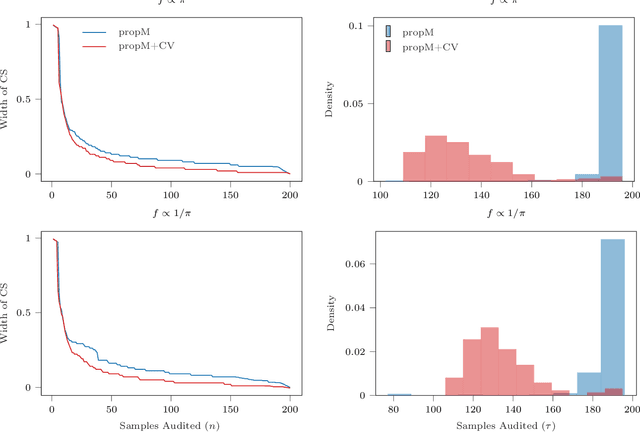
We introduce the notion of a risk-limiting financial auditing (RLFA): given $N$ transactions, the goal is to estimate the total misstated monetary fraction~($m^*$) to a given accuracy $\epsilon$, with confidence $1-\delta$. We do this by constructing new confidence sequences (CSs) for the weighted average of $N$ unknown values, based on samples drawn without replacement according to a (randomized) weighted sampling scheme. Using the idea of importance weighting to construct test martingales, we first develop a framework to construct CSs for arbitrary sampling strategies. Next, we develop methods to improve the quality of CSs by incorporating side information about the unknown values associated with each item. We show that when the side information is sufficiently predictive, it can directly drive the sampling. Addressing the case where the accuracy is unknown a priori, we introduce a method that incorporates side information via control variates. Crucially, our construction is adaptive: if the side information is highly predictive of the unknown misstated amounts, then the benefits of incorporating it are significant; but if the side information is uncorrelated, our methods learn to ignore it. Our methods recover state-of-the-art bounds for the special case when the weights are equal, which has already found applications in election auditing. The harder weighted case solves our more challenging problem of AI-assisted financial auditing.
Pretrained Language Model based Web Search Ranking: From Relevance to Satisfaction
Jun 02, 2023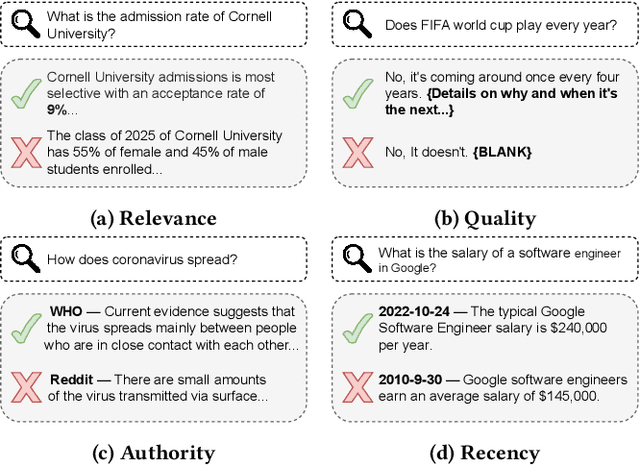

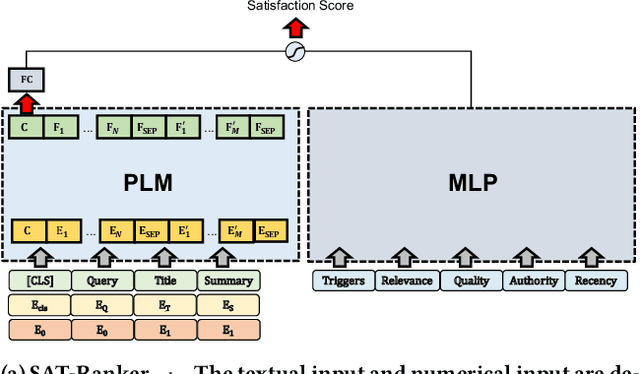
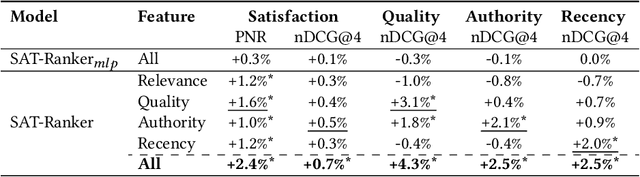
Search engine plays a crucial role in satisfying users' diverse information needs. Recently, Pretrained Language Models (PLMs) based text ranking models have achieved huge success in web search. However, many state-of-the-art text ranking approaches only focus on core relevance while ignoring other dimensions that contribute to user satisfaction, e.g., document quality, recency, authority, etc. In this work, we focus on ranking user satisfaction rather than relevance in web search, and propose a PLM-based framework, namely SAT-Ranker, which comprehensively models different dimensions of user satisfaction in a unified manner. In particular, we leverage the capacities of PLMs on both textual and numerical inputs, and apply a multi-field input that modularizes each dimension of user satisfaction as an input field. Overall, SAT-Ranker is an effective, extensible, and data-centric framework that has huge potential for industrial applications. On rigorous offline and online experiments, SAT-Ranker obtains remarkable gains on various evaluation sets targeting different dimensions of user satisfaction. It is now fully deployed online to improve the usability of our search engine.
Recent Advances of Local Mechanisms in Computer Vision: A Survey and Outlook of Recent Work
Jun 02, 2023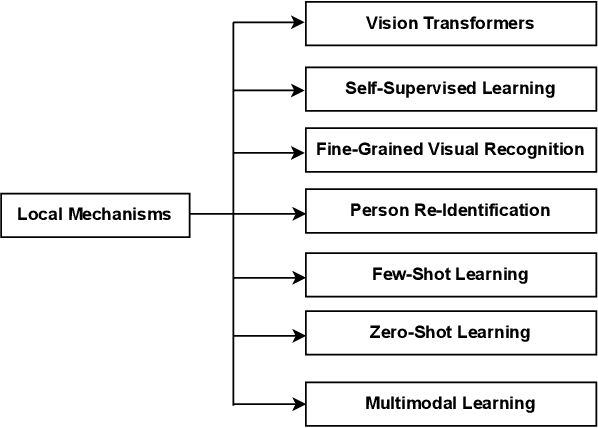
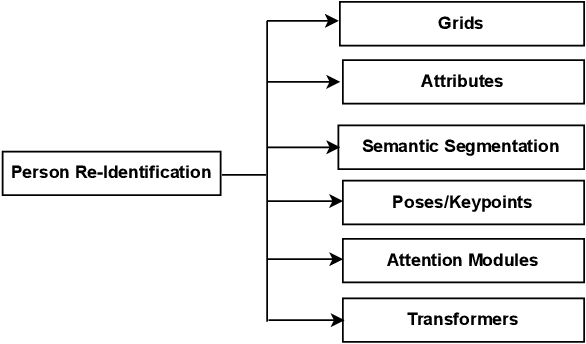
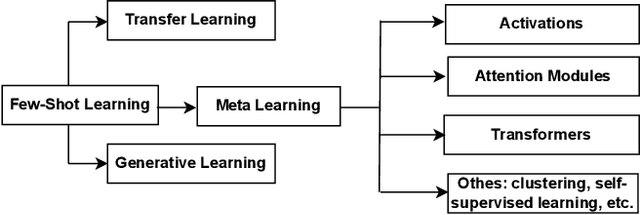
Inspired by the fact that human brains can emphasize discriminative parts of the input and suppress irrelevant ones, substantial local mechanisms have been designed to boost the development of computer vision. They can not only focus on target parts to learn discriminative local representations, but also process information selectively to improve the efficiency. In terms of application scenarios and paradigms, local mechanisms have different characteristics. In this survey, we provide a systematic review of local mechanisms for various computer vision tasks and approaches, including fine-grained visual recognition, person re-identification, few-/zero-shot learning, multi-modal learning, self-supervised learning, Vision Transformers, and so on. Categorization of local mechanisms in each field is summarized. Then, advantages and disadvantages for every category are analyzed deeply, leaving room for exploration. Finally, future research directions about local mechanisms have also been discussed that may benefit future works. To the best our knowledge, this is the first survey about local mechanisms on computer vision. We hope that this survey can shed light on future research in the computer vision field.