 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQTalker: Towards Multilingual Talking Avatars through Facial Motion Tokenization
Dec 13, 2024



We present VQTalker, a Vector Quantization-based framework for multilingual talking head generation that addresses the challenges of lip synchronization and natural motion across diverse languages. Our approach is grounded in the phonetic principle that human speech comprises a finite set of distinct sound units (phonemes) and corresponding visual articulations (visemes), which often share commonalities across languages. We introduce a facial motion tokenizer based on Group Residual Finite Scalar Quantization (GRFSQ), which creates a discretized representation of facial features. This method enables comprehensive capture of facial movements while improving generalization to multiple languages, even with limited training data. Building on this quantized representation, we implement a coarse-to-fine motion generation process that progressively refines facial animations. Extensive experiments demonstrate that VQTalker achieves state-of-the-art performance in both video-driven and speech-driven scenarios, particularly in multilingual settings. Notably, our method achieves high-quality results at a resolution of 512*512 pixels while maintaining a lower bitrate of approximately 11 kbps. Our work opens new possibilities for cross-lingual talking face generation. Synthetic results can be viewed at https://x-lance.github.io/VQTalker.
AniTalker: Animate Vivid and Diverse Talking Faces through Identity-Decoupled Facial Motion Encoding
May 06, 2024



The paper introduces AniTalker, an innovative framework designed to generate lifelike talking faces from a single portrait. Unlike existing models that primarily focus on verbal cues such as lip synchronization and fail to capture the complex dynamics of facial expressions and nonverbal cues, AniTalker employs a universal motion representation. This innovative representation effectively captures a wide range of facial dynamics, including subtle expressions and head movements. AniTalker enhances motion depiction through two self-supervised learning strategies: the first involves reconstructing target video frames from source frames within the same identity to learn subtle motion representations, and the second develops an identity encoder using metric learning while actively minimizing mutual information between the identity and motion encoders. This approach ensures that the motion representation is dynamic and devoid of identity-specific details, significantly reducing the need for labeled data. Additionally, the integration of a diffusion model with a variance adapter allows for the generation of diverse and controllable facial animations. This method not only demonstrates AniTalker's capability to create detailed and realistic facial movements but also underscores its potential in crafting dynamic avatars for real-world applications. Synthetic results can be viewed at https://github.com/X-LANCE/AniTalker.
DiffDub: Person-generic Visual Dubbing Using Inpainting Renderer with Diffusion Auto-encoder
Nov 03, 2023Generating high-quality and person-generic visual dubbing remains a challenge. Recent innovation has seen the advent of a two-stage paradigm, decoupling the rendering and lip synchronization process facilitated by intermediate representation as a conduit. Still, previous methodologies rely on rough landmarks or are confined to a single speaker, thus limiting their performance. In this paper, we propose DiffDub: Diffusion-based dubbing. We first craft the Diffusion auto-encoder by an inpainting renderer incorporating a mask to delineate editable zones and unaltered regions. This allows for seamless filling of the lower-face region while preserving the remaining parts. Throughout our experiments, we encountered several challenges. Primarily, the semantic encoder lacks robustness, constricting its ability to capture high-level features. Besides, the modeling ignored facial positioning, causing mouth or nose jitters across frames. To tackle these issues, we employ versatile strategies, including data augmentation and supplementary eye guidance. Moreover, we encapsulated a conformer-based reference encoder and motion generator fortified by a cross-attention mechanism. This enables our model to learn person-specific textures with varying references and reduces reliance on paired audio-visual data. Our rigorous experiments comprehensively highlight that our ground-breaking approach outpaces existing methods with considerable margins and delivers seamless, intelligible videos in person-generic and multilingual scenarios.
ViLaS: Integrating Vision and Language into Automatic Speech Recognition
May 31, 2023



Employing additional multimodal information to improve automatic speech recognition (ASR) performance has been proven effective in previous works. However, many of these works focus only on the utilization of visual cues from human lip motion. In fact, context-dependent visual and linguistic cues can also be used to improve ASR performance in many scenarios. In this paper, we first propose a multimodal ASR model (ViLaS) that can simultaneously or separately integrate visual and linguistic cues to help recognize the input speech, and introduce a training strategy that can improve performance in modal-incomplete test scenarios. Then, we create a multimodal ASR dataset (VSDial) with visual and linguistic cues to explore the effects of integrating vision and language. Finally, we report empirical results on the public Flickr8K and self-constructed VSDial datasets, investigate cross-modal fusion schemes, and analyze fine-grained cross-modal alignment on VSDial.
X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages
May 10, 2023



Large language models (LLMs) have demonstrated remarkable language abilities. GPT-4, based on advanced LLMs, exhibits extraordinary multimodal capabilities beyond previous visual language models. We attribute this to the use of more advanced LLMs compared with previous multimodal models. Unfortunately, the model architecture and training strategies of GPT-4 are unknown. To endow LLMs with multimodal capabilities, we propose X-LLM, which converts Multi-modalities (images, speech, videos) into foreign languages using X2L interfaces and inputs them into a large Language model (ChatGLM). Specifically, X-LLM aligns multiple frozen single-modal encoders and a frozen LLM using X2L interfaces, where ``X'' denotes multi-modalities such as image, speech, and videos, and ``L'' denotes languages. X-LLM's training consists of three stages: (1) Converting Multimodal Information: The first stage trains each X2L interface to align with its respective single-modal encoder separately to convert multimodal information into languages. (2) Aligning X2L representations with the LLM: single-modal encoders are aligned with the LLM through X2L interfaces independently. (3) Integrating multiple modalities: all single-modal encoders are aligned with the LLM through X2L interfaces to integrate multimodal capabilities into the LLM. Our experiments show that X-LLM demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 84.5\% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. And we also conduct quantitative tests on using LLM for ASR and multimodal ASR, hoping to promote the era of LLM-based speech recognition.
Knowledge Transfer from Pre-trained Language Models to Cif-based Speech Recognizers via Hierarchical Distillation
Jan 30, 2023



Large-scale pre-trained language models (PLMs) with powerful language modeling capabilities have been widely used in natural language processing. For automatic speech recognition (ASR), leveraging PLMs to improve performance has also become a promising research trend. However, most previous works may suffer from the inflexible sizes and structures of PLMs, along with the insufficient utilization of the knowledge in PLMs. To alleviate these problems, we propose the hierarchical knowledge distillation on the continuous integrate-and-fire (CIF) based ASR models. Specifically, we distill the knowledge from PLMs to the ASR model by applying cross-modal distillation with contrastive loss at the acoustic level and applying distillation with regression loss at the linguistic level. On the AISHELL-1 dataset, our method achieves 15% relative error rate reduction over the original CIF-based model and achieves comparable performance (3.8%/4.1% on dev/test) to the state-of-the-art model.
An Online Sparse Streaming Feature Selection Algorithm
Aug 03, 2022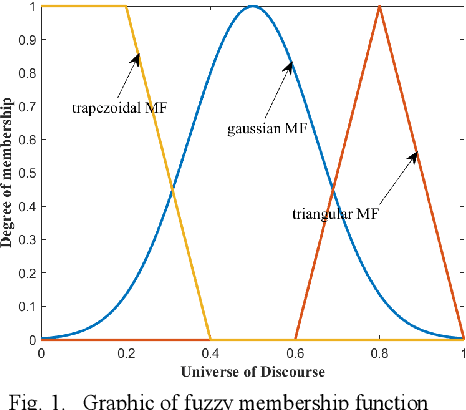
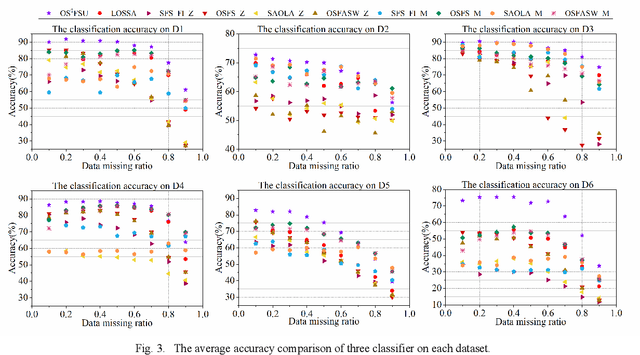
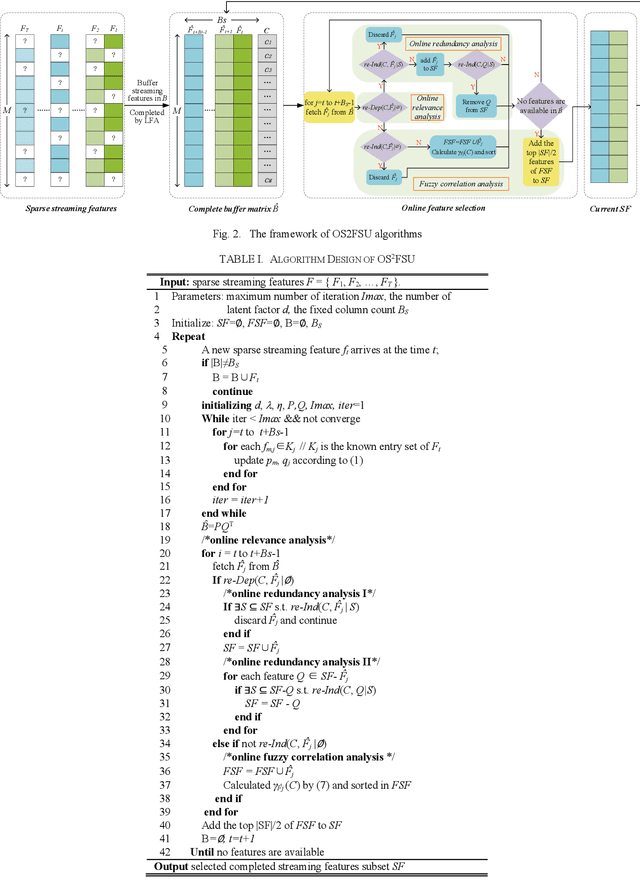
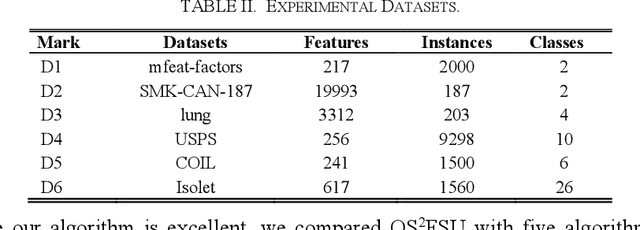
Online streaming feature selection (OSFS), which conducts feature selection in an online manner, plays an important role in dealing with high-dimensional data. In many real applications such as intelligent healthcare platform, streaming feature always has some missing data, which raises a crucial challenge in conducting OSFS, i.e., how to establish the uncertain relationship between sparse streaming features and labels. Unfortunately, existing OSFS algorithms never consider such uncertain relationship. To fill this gap, we in this paper propose an online sparse streaming feature selection with uncertainty (OS2FSU) algorithm. OS2FSU consists of two main parts: 1) latent factor analysis is utilized to pre-estimate the missing data in sparse streaming features before con-ducting feature selection, and 2) fuzzy logic and neighborhood rough set are employed to alleviate the uncertainty between estimated streaming features and labels during conducting feature selection. In the experiments, OS2FSU is compared with five state-of-the-art OSFS algorithms on six real datasets. The results demonstrate that OS2FSU outperforms its competitors when missing data are encountered in OSFS.
HiVLP: Hierarchical Vision-Language Pre-Training for Fast Image-Text Retrieval
May 31, 2022
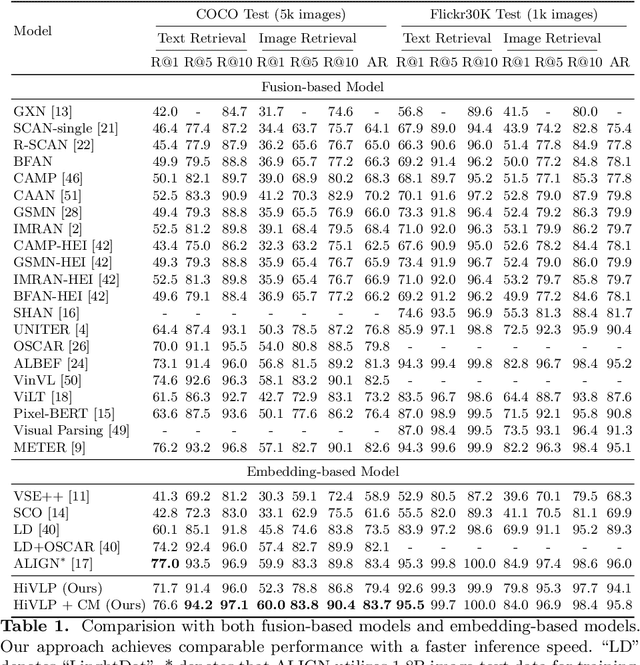
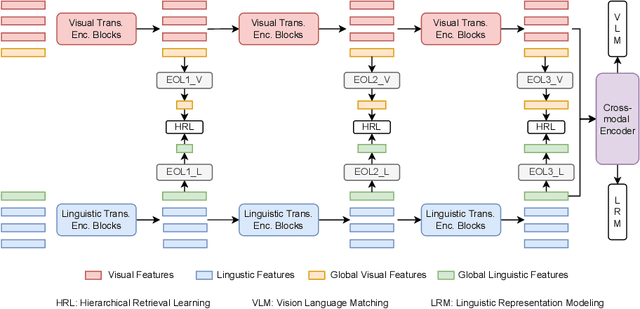
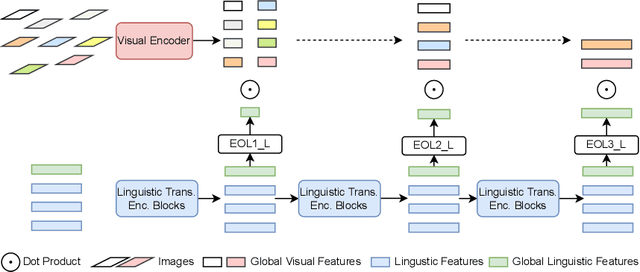
In the past few years, the emergence of vision-language pre-training (VLP) has brought cross-modal retrieval to a new era. However, due to the latency and computation demand, it is commonly challenging to apply VLP in a real-time online retrieval system. To alleviate the defect, this paper proposes a \textbf{Hi}erarchical \textbf{V}ision-\textbf{}Language \textbf{P}re-Training (\textbf{HiVLP}) for fast Image-Text Retrieval (ITR). Specifically, we design a novel hierarchical retrieval objective, which uses the representation of different dimensions for coarse-to-fine ITR, i.e., using low-dimensional representation for large-scale coarse retrieval and high-dimensional representation for small-scale fine retrieval. We evaluate our proposed HiVLP on two popular image-text retrieval benchmarks, i.e., Flickr30k and COCO. Extensive experiments demonstrate that our HiVLP not only has fast inference speed but also can be easily scaled to large-scale ITR scenarios. The detailed results show that HiVLP is $1,427$$\sim$$120,649\times$ faster than the fusion-based model UNITER and 2$\sim$5 faster than the fastest embedding-based model LightingDot in different candidate scenarios. It also achieves about +4.9 AR on COCO and +3.8 AR on Flickr30K than LightingDot and achieves comparable performance with the state-of-the-art (SOTA) fusion-based model METER.
Improving Cross-Modal Understanding in Visual Dialog via Contrastive Learning
Apr 15, 2022
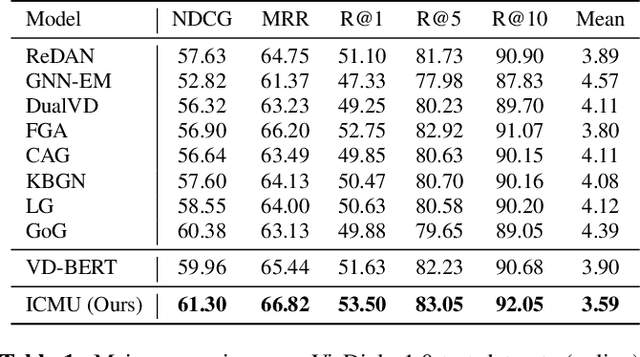
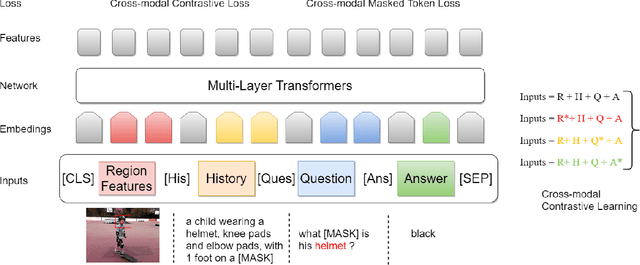
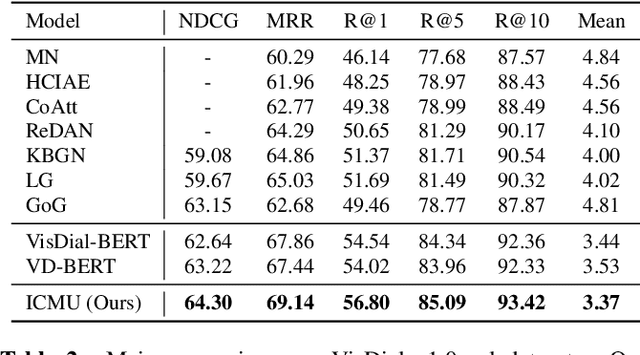
Visual Dialog is a challenging vision-language task since the visual dialog agent needs to answer a series of questions after reasoning over both the image content and dialog history. Though existing methods try to deal with the cross-modal understanding in visual dialog, they are still not enough in ranking candidate answers based on their understanding of visual and textual contexts. In this paper, we analyze the cross-modal understanding in visual dialog based on the vision-language pre-training model VD-BERT and propose a novel approach to improve the cross-modal understanding for visual dialog, named ICMU. ICMU enhances cross-modal understanding by distinguishing different pulled inputs (i.e. pulled images, questions or answers) based on four-way contrastive learning. In addition, ICMU exploits the single-turn visual question answering to enhance the visual dialog model's cross-modal understanding to handle a multi-turn visually-grounded conversation. Experiments show that the proposed approach improves the visual dialog model's cross-modal understanding and brings satisfactory gain to the VisDial dataset.
VLP: A Survey on Vision-Language Pre-training
Feb 21, 2022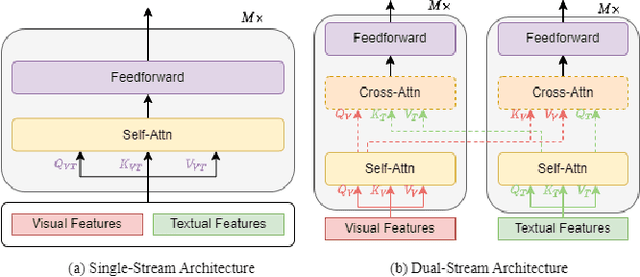
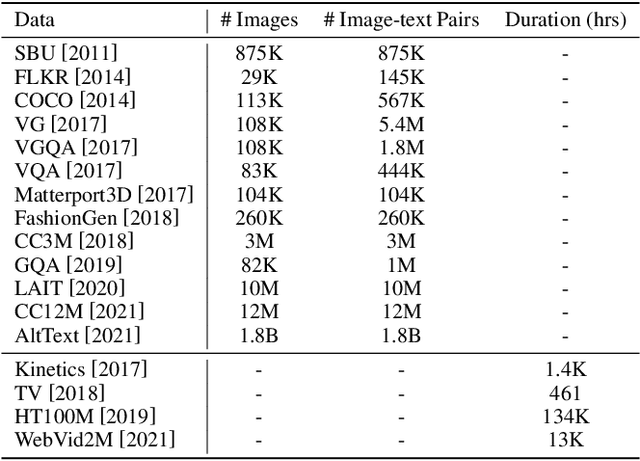
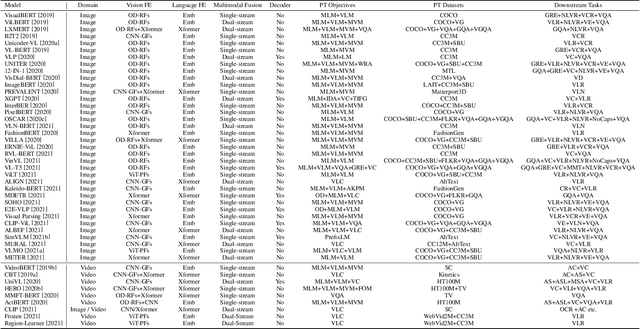
In the past few years, the emergence of pre-training models has brought uni-modal fields such as computer vision (CV) and natural language processing (NLP) to a new era. Substantial works have shown they are beneficial for downstream uni-modal tasks and avoid training a new model from scratch. So can such pre-trained models be applied to multi-modal tasks? Researchers have explored this problem and made significant progress. This paper surveys recent advances and new frontiers in vision-language pre-training (VLP), including image-text and video-text pre-training. To give readers a better overall grasp of VLP, we first review its recent advances from five aspects: feature extraction, model architecture, pre-training objectives, pre-training datasets, and downstream tasks. Then, we summarize the specific VLP models in detail. Finally, we discuss the new frontiers in VLP. To the best of our knowledge, this is the first survey on VLP. We hope that this survey can shed light on future research in the VLP field.