 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Costs of Perceived Bias in Fair Selection
Oct 23, 2025Meritocratic systems, from admissions to hiring, aim to impartially reward skill and effort. Yet persistent disparities across race, gender, and class challenge this ideal. Some attribute these gaps to structural inequality; others to individual choice. We develop a game-theoretic model in which candidates from different socioeconomic groups differ in their perceived post-selection value--shaped by social context and, increasingly, by AI-powered tools offering personalized career or salary guidance. Each candidate strategically chooses effort, balancing its cost against expected reward; effort translates into observable merit, and selection is based solely on merit. We characterize the unique Nash equilibrium in the large-agent limit and derive explicit formulas showing how valuation disparities and institutional selectivity jointly determine effort, representation, social welfare, and utility. We further propose a cost-sensitive optimization framework that quantifies how modifying selectivity or perceived value can reduce disparities without compromising institutional goals. Our analysis reveals a perception-driven bias: when perceptions of post-selection value differ across groups, these differences translate into rational differences in effort, propagating disparities backward through otherwise "fair" selection processes. While the model is static, it captures one stage of a broader feedback cycle linking perceptions, incentives, and outcome--bridging rational-choice and structural explanations of inequality by showing how techno-social environments shape individual incentives in meritocratic systems.
Centralized Selection with Preferences in the Presence of Biases
Sep 07, 2024



This paper considers the scenario in which there are multiple institutions, each with a limited capacity for candidates, and candidates, each with preferences over the institutions. A central entity evaluates the utility of each candidate to the institutions, and the goal is to select candidates for each institution in a way that maximizes utility while also considering the candidates' preferences. The paper focuses on the setting in which candidates are divided into multiple groups and the observed utilities of candidates in some groups are biased--systematically lower than their true utilities. The first result is that, in these biased settings, prior algorithms can lead to selections with sub-optimal true utility and significant discrepancies in the fraction of candidates from each group that get their preferred choices. Subsequently, an algorithm is presented along with proof that it produces selections that achieve near-optimal group fairness with respect to preferences while also nearly maximizing the true utility under distributional assumptions. Further, extensive empirical validation of these results in real-world and synthetic settings, in which the distributional assumptions may not hold, are presented.
Fair Classification with Partial Feedback: An Exploration-Based Data-Collection Approach
Feb 17, 2024In many predictive contexts (e.g., credit lending), true outcomes are only observed for samples that were positively classified in the past. These past observations, in turn, form training datasets for classifiers that make future predictions. However, such training datasets lack information about the outcomes of samples that were (incorrectly) negatively classified in the past and can lead to erroneous classifiers. We present an approach that trains a classifier using available data and comes with a family of exploration strategies to collect outcome data about subpopulations that otherwise would have been ignored. For any exploration strategy, the approach comes with guarantees that (1) all sub-populations are explored, (2) the fraction of false positives is bounded, and (3) the trained classifier converges to a "desired" classifier. The right exploration strategy is context-dependent; it can be chosen to improve learning guarantees and encode context-specific group fairness properties. Evaluation on real-world datasets shows that this approach consistently boosts the quality of collected outcome data and improves the fraction of true positives for all groups, with only a small reduction in predictive utility.
Bias in Evaluation Processes: An Optimization-Based Model
Oct 26, 2023



Biases with respect to socially-salient attributes of individuals have been well documented in evaluation processes used in settings such as admissions and hiring. We view such an evaluation process as a transformation of a distribution of the true utility of an individual for a task to an observed distribution and model it as a solution to a loss minimization problem subject to an information constraint. Our model has two parameters that have been identified as factors leading to biases: the resource-information trade-off parameter in the information constraint and the risk-averseness parameter in the loss function. We characterize the distributions that arise from our model and study the effect of the parameters on the observed distribution. The outputs of our model enrich the class of distributions that can be used to capture variation across groups in the observed evaluations. We empirically validate our model by fitting real-world datasets and use it to study the effect of interventions in a downstream selection task. These results contribute to an understanding of the emergence of bias in evaluation processes and provide tools to guide the deployment of interventions to mitigate biases.
Subset Selection Based On Multiple Rankings in the Presence of Bias: Effectiveness of Fairness Constraints for Multiwinner Voting Score Functions
Jun 16, 2023



We consider the problem of subset selection where one is given multiple rankings of items and the goal is to select the highest ``quality'' subset. Score functions from the multiwinner voting literature have been used to aggregate rankings into quality scores for subsets. We study this setting of subset selection problems when, in addition, rankings may contain systemic or unconscious biases toward a group of items. For a general model of input rankings and biases, we show that requiring the selected subset to satisfy group fairness constraints can improve the quality of the selection with respect to unbiased rankings. Importantly, we show that for fairness constraints to be effective, different multiwinner score functions may require a drastically different number of rankings: While for some functions, fairness constraints need an exponential number of rankings to recover a close-to-optimal solution, for others, this dependency is only polynomial. This result relies on a novel notion of ``smoothness'' of submodular functions in this setting that quantifies how well a function can ``correctly'' assess the quality of items in the presence of bias. The results in this paper can be used to guide the choice of multiwinner score functions for the subset selection setting considered here; we additionally provide a tool to empirically enable this.
Designing Closed-Loop Models for Task Allocation
May 31, 2023Automatically assigning tasks to people is challenging because human performance can vary across tasks for many reasons. This challenge is further compounded in real-life settings in which no oracle exists to assess the quality of human decisions and task assignments made. Instead, we find ourselves in a "closed" decision-making loop in which the same fallible human decisions we rely on in practice must also be used to guide task allocation. How can imperfect and potentially biased human decisions train an accurate allocation model? Our key insight is to exploit weak prior information on human-task similarity to bootstrap model training. We show that the use of such a weak prior can improve task allocation accuracy, even when human decision-makers are fallible and biased. We present both theoretical analysis and empirical evaluation over synthetic data and a social media toxicity detection task. Results demonstrate the efficacy of our approach.
Addressing Strategic Manipulation Disparities in Fair Classification
May 22, 2022



In real-world classification settings, individuals respond to classifier predictions by updating their features to increase their likelihood of receiving a particular (positive) decision (at a certain cost). Yet, when different demographic groups have different feature distributions or different cost functions, prior work has shown that individuals from minority groups often pay a higher cost to update their features. Fair classification aims to address such classifier performance disparities by constraining the classifiers to satisfy statistical fairness properties. However, we show that standard fairness constraints do not guarantee that the constrained classifier reduces the disparity in strategic manipulation cost. To address such biases in strategic settings and provide equal opportunities for strategic manipulation, we propose a constrained optimization framework that constructs classifiers that lower the strategic manipulation cost for the minority groups. We develop our framework by studying theoretical connections between group-specific strategic cost disparity and standard selection rate fairness metrics (e.g., statistical rate and true positive rate). Empirically, we show the efficacy of this approach over multiple real-world datasets.
Auditing for Diversity using Representative Examples
Jul 15, 2021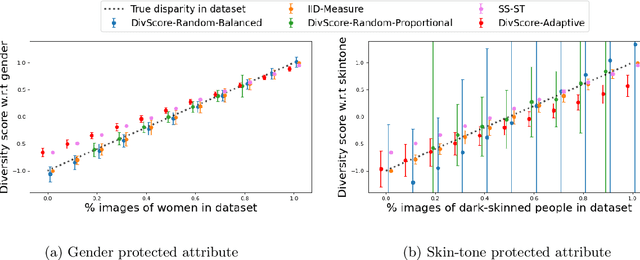
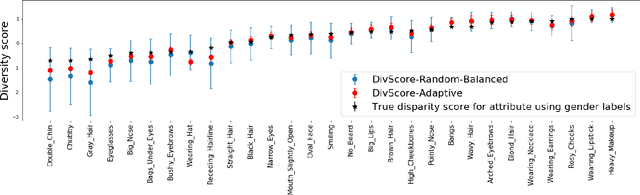
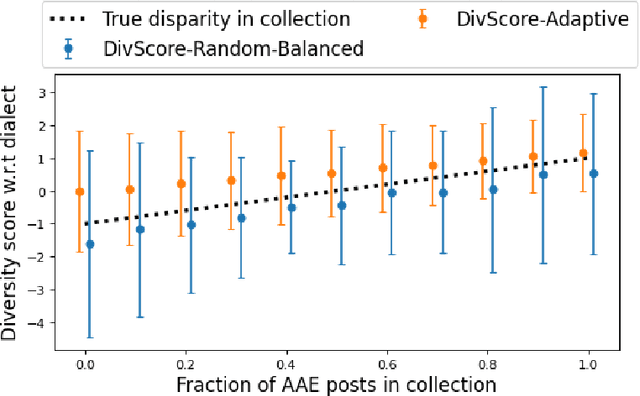
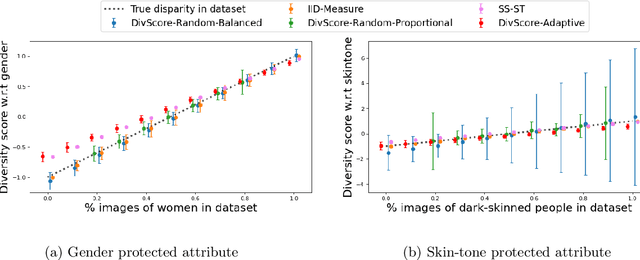
Assessing the diversity of a dataset of information associated with people is crucial before using such data for downstream applications. For a given dataset, this often involves computing the imbalance or disparity in the empirical marginal distribution of a protected attribute (e.g. gender, dialect, etc.). However, real-world datasets, such as images from Google Search or collections of Twitter posts, often do not have protected attributes labeled. Consequently, to derive disparity measures for such datasets, the elements need to hand-labeled or crowd-annotated, which are expensive processes. We propose a cost-effective approach to approximate the disparity of a given unlabeled dataset, with respect to a protected attribute, using a control set of labeled representative examples. Our proposed algorithm uses the pairwise similarity between elements in the dataset and elements in the control set to effectively bootstrap an approximation to the disparity of the dataset. Importantly, we show that using a control set whose size is much smaller than the size of the dataset is sufficient to achieve a small approximation error. Further, based on our theoretical framework, we also provide an algorithm to construct adaptive control sets that achieve smaller approximation errors than randomly chosen control sets. Simulations on two image datasets and one Twitter dataset demonstrate the efficacy of our approach (using random and adaptive control sets) in auditing the diversity of a wide variety of datasets.
Fair Classification with Adversarial Perturbations
Jun 10, 2021
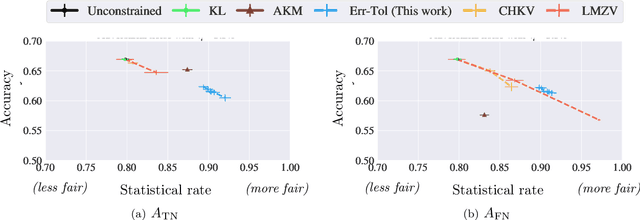
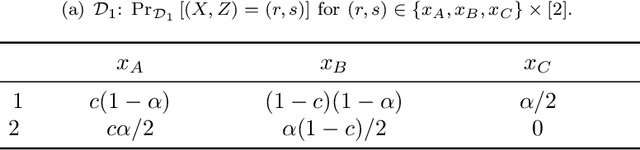
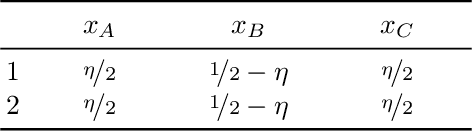
We study fair classification in the presence of an omniscient adversary that, given an $\eta$, is allowed to choose an arbitrary $\eta$-fraction of the training samples and arbitrarily perturb their protected attributes. The motivation comes from settings in which protected attributes can be incorrect due to strategic misreporting, malicious actors, or errors in imputation; and prior approaches that make stochastic or independence assumptions on errors may not satisfy their guarantees in this adversarial setting. Our main contribution is an optimization framework to learn fair classifiers in this adversarial setting that comes with provable guarantees on accuracy and fairness. Our framework works with multiple and non-binary protected attributes, is designed for the large class of linear-fractional fairness metrics, and can also handle perturbations besides protected attributes. We prove near-tightness of our framework's guarantees for natural hypothesis classes: no algorithm can have significantly better accuracy and any algorithm with better fairness must have lower accuracy. Empirically, we evaluate the classifiers produced by our framework for statistical rate on real-world and synthetic datasets for a family of adversaries.
Mitigating Bias in Set Selection with Noisy Protected Attributes
Nov 09, 2020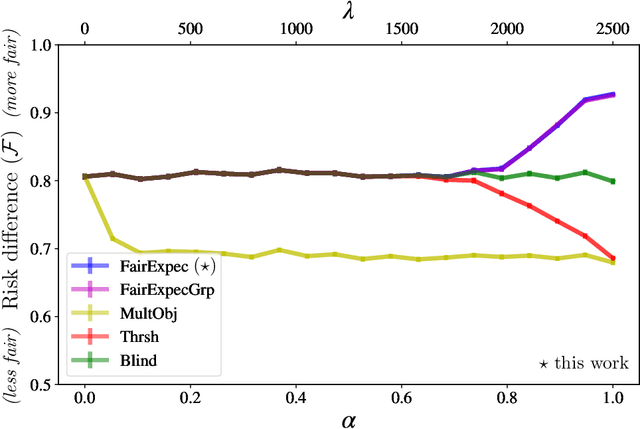
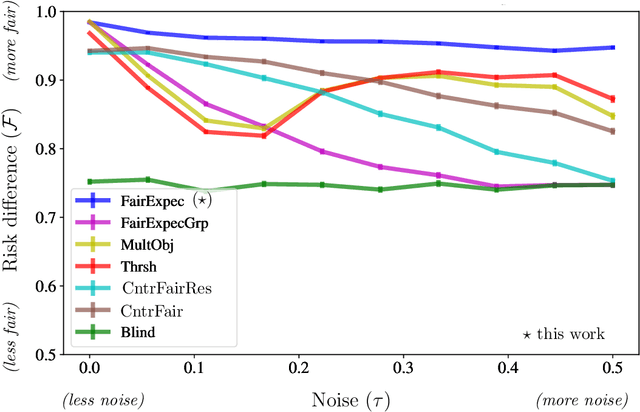
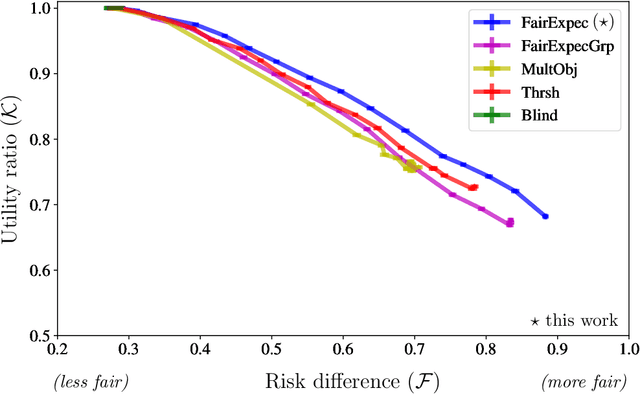

Subset selection algorithms are ubiquitous in AI-driven applications, including, online recruiting portals and image search engines, so it is imperative that these tools are not discriminatory on the basis of protected attributes such as gender or race. Currently, fair subset selection algorithms assume that the protected attributes are known as part of the dataset. However, attributes may be noisy due to errors during data collection or if they are imputed (as is often the case in real-world settings). While a wide body of work addresses the effect of noise on the performance of machine learning algorithms, its effect on fairness remains largely unexamined. We find that in the presence of noisy protected attributes, in attempting to increase fairness without considering noise, one can, in fact, decrease the fairness of the result! Towards addressing this, we consider an existing noise model in which there is probabilistic information about the protected attributes (e.g.,[19, 32, 56, 44]), and ask is fair selection is possible under noisy conditions? We formulate a ``denoised'' selection problem which functions for a large class of fairness metrics; given the desired fairness goal, the solution to the denoised problem violates the goal by at most a small multiplicative amount with high probability. Although the denoised problem turns out to be NP-hard, we give a linear-programming based approximation algorithm for it. We empirically evaluate our approach on both synthetic and real-world datasets. Our empirical results show that this approach can produce subsets which significantly improve the fairness metrics despite the presence of noisy protected attributes, and, compared to prior noise-oblivious approaches, has better Pareto-tradeoffs between utility and fairness.