 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoral Change or Noise? On Problems of Aligning AI With Temporally Unstable Human Feedback
Nov 13, 2025Alignment methods in moral domains seek to elicit moral preferences of human stakeholders and incorporate them into AI. This presupposes moral preferences as static targets, but such preferences often evolve over time. Proper alignment of AI to dynamic human preferences should ideally account for "legitimate" changes to moral reasoning, while ignoring changes related to attention deficits, cognitive biases, or other arbitrary factors. However, common AI alignment approaches largely neglect temporal changes in preferences, posing serious challenges to proper alignment, especially in high-stakes applications of AI, e.g., in healthcare domains, where misalignment can jeopardize the trustworthiness of the system and yield serious individual and societal harms. This work investigates the extent to which people's moral preferences change over time, and the impact of such changes on AI alignment. Our study is grounded in the kidney allocation domain, where we elicit responses to pairwise comparisons of hypothetical kidney transplant patients from over 400 participants across 3-5 sessions. We find that, on average, participants change their response to the same scenario presented at different times around 6-20% of the time (exhibiting "response instability"). Additionally, we observe significant shifts in several participants' retrofitted decision-making models over time (capturing "model instability"). The predictive performance of simple AI models decreases as a function of both response and model instability. Moreover, predictive performance diminishes over time, highlighting the importance of accounting for temporal changes in preferences during training. These findings raise fundamental normative and technical challenges relevant to AI alignment, highlighting the need to better understand the object of alignment (what to align to) when user preferences change significantly over time.
Towards Cognitively-Faithful Decision-Making Models to Improve AI Alignment
Sep 04, 2025Recent AI work trends towards incorporating human-centric objectives, with the explicit goal of aligning AI models to personal preferences and societal values. Using standard preference elicitation methods, researchers and practitioners build models of human decisions and judgments, which are then used to align AI behavior with that of humans. However, models commonly used in such elicitation processes often do not capture the true cognitive processes of human decision making, such as when people use heuristics to simplify information associated with a decision problem. As a result, models learned from people's decisions often do not align with their cognitive processes, and can not be used to validate the learning framework for generalization to other decision-making tasks. To address this limitation, we take an axiomatic approach to learning cognitively faithful decision processes from pairwise comparisons. Building on the vast literature characterizing the cognitive processes that contribute to human decision-making, and recent work characterizing such processes in pairwise comparison tasks, we define a class of models in which individual features are first processed and compared across alternatives, and then the processed features are then aggregated via a fixed rule, such as the Bradley-Terry rule. This structured processing of information ensures such models are realistic and feasible candidates to represent underlying human decision-making processes. We demonstrate the efficacy of this modeling approach in learning interpretable models of human decision making in a kidney allocation task, and show that our proposed models match or surpass the accuracy of prior models of human pairwise decision-making.
Can AI Model the Complexities of Human Moral Decision-Making? A Qualitative Study of Kidney Allocation Decisions
Mar 02, 2025A growing body of work in Ethical AI attempts to capture human moral judgments through simple computational models. The key question we address in this work is whether such simple AI models capture {the critical} nuances of moral decision-making by focusing on the use case of kidney allocation. We conducted twenty interviews where participants explained their rationale for their judgments about who should receive a kidney. We observe participants: (a) value patients' morally-relevant attributes to different degrees; (b) use diverse decision-making processes, citing heuristics to reduce decision complexity; (c) can change their opinions; (d) sometimes lack confidence in their decisions (e.g., due to incomplete information); and (e) express enthusiasm and concern regarding AI assisting humans in kidney allocation decisions. Based on these findings, we discuss challenges of computationally modeling moral judgments {as a stand-in for human input}, highlight drawbacks of current approaches, and suggest future directions to address these issues.
On The Stability of Moral Preferences: A Problem with Computational Elicitation Methods
Aug 05, 2024



Preference elicitation frameworks feature heavily in the research on participatory ethical AI tools and provide a viable mechanism to enquire and incorporate the moral values of various stakeholders. As part of the elicitation process, surveys about moral preferences, opinions, and judgments are typically administered only once to each participant. This methodological practice is reasonable if participants' responses are stable over time such that, all other relevant factors being held constant, their responses today will be the same as their responses to the same questions at a later time. However, we do not know how often that is the case. It is possible that participants' true moral preferences change, are subject to temporary moods or whims, or are influenced by environmental factors we don't track. If participants' moral responses are unstable in such ways, it would raise important methodological and theoretical issues for how participants' true moral preferences, opinions, and judgments can be ascertained. We address this possibility here by asking the same survey participants the same moral questions about which patient should receive a kidney when only one is available ten times in ten different sessions over two weeks, varying only presentation order across sessions. We measured how often participants gave different responses to simple (Study One) and more complicated (Study Two) repeated scenarios. On average, the fraction of times participants changed their responses to controversial scenarios was around 10-18% across studies, and this instability is observed to have positive associations with response time and decision-making difficulty. We discuss the implications of these results for the efficacy of moral preference elicitation, highlighting the role of response instability in causing value misalignment between stakeholders and AI tools trained on their moral judgments.
On the Pros and Cons of Active Learning for Moral Preference Elicitation
Jul 26, 2024Computational preference elicitation methods are tools used to learn people's preferences quantitatively in a given context. Recent works on preference elicitation advocate for active learning as an efficient method to iteratively construct queries (framed as comparisons between context-specific cases) that are likely to be most informative about an agent's underlying preferences. In this work, we argue that the use of active learning for moral preference elicitation relies on certain assumptions about the underlying moral preferences, which can be violated in practice. Specifically, we highlight the following common assumptions (a) preferences are stable over time and not sensitive to the sequence of presented queries, (b) the appropriate hypothesis class is chosen to model moral preferences, and (c) noise in the agent's responses is limited. While these assumptions can be appropriate for preference elicitation in certain domains, prior research on moral psychology suggests they may not be valid for moral judgments. Through a synthetic simulation of preferences that violate the above assumptions, we observe that active learning can have similar or worse performance than a basic random query selection method in certain settings. Yet, simulation results also demonstrate that active learning can still be viable if the degree of instability or noise is relatively small and when the agent's preferences can be approximately represented with the hypothesis class used for learning. Our study highlights the nuances associated with effective moral preference elicitation in practice and advocates for the cautious use of active learning as a methodology to learn moral preferences.
Fair Classification with Partial Feedback: An Exploration-Based Data-Collection Approach
Feb 17, 2024In many predictive contexts (e.g., credit lending), true outcomes are only observed for samples that were positively classified in the past. These past observations, in turn, form training datasets for classifiers that make future predictions. However, such training datasets lack information about the outcomes of samples that were (incorrectly) negatively classified in the past and can lead to erroneous classifiers. We present an approach that trains a classifier using available data and comes with a family of exploration strategies to collect outcome data about subpopulations that otherwise would have been ignored. For any exploration strategy, the approach comes with guarantees that (1) all sub-populations are explored, (2) the fraction of false positives is bounded, and (3) the trained classifier converges to a "desired" classifier. The right exploration strategy is context-dependent; it can be chosen to improve learning guarantees and encode context-specific group fairness properties. Evaluation on real-world datasets shows that this approach consistently boosts the quality of collected outcome data and improves the fraction of true positives for all groups, with only a small reduction in predictive utility.
Designing Closed-Loop Models for Task Allocation
May 31, 2023Automatically assigning tasks to people is challenging because human performance can vary across tasks for many reasons. This challenge is further compounded in real-life settings in which no oracle exists to assess the quality of human decisions and task assignments made. Instead, we find ourselves in a "closed" decision-making loop in which the same fallible human decisions we rely on in practice must also be used to guide task allocation. How can imperfect and potentially biased human decisions train an accurate allocation model? Our key insight is to exploit weak prior information on human-task similarity to bootstrap model training. We show that the use of such a weak prior can improve task allocation accuracy, even when human decision-makers are fallible and biased. We present both theoretical analysis and empirical evaluation over synthetic data and a social media toxicity detection task. Results demonstrate the efficacy of our approach.
Addressing Strategic Manipulation Disparities in Fair Classification
May 22, 2022



In real-world classification settings, individuals respond to classifier predictions by updating their features to increase their likelihood of receiving a particular (positive) decision (at a certain cost). Yet, when different demographic groups have different feature distributions or different cost functions, prior work has shown that individuals from minority groups often pay a higher cost to update their features. Fair classification aims to address such classifier performance disparities by constraining the classifiers to satisfy statistical fairness properties. However, we show that standard fairness constraints do not guarantee that the constrained classifier reduces the disparity in strategic manipulation cost. To address such biases in strategic settings and provide equal opportunities for strategic manipulation, we propose a constrained optimization framework that constructs classifiers that lower the strategic manipulation cost for the minority groups. We develop our framework by studying theoretical connections between group-specific strategic cost disparity and standard selection rate fairness metrics (e.g., statistical rate and true positive rate). Empirically, we show the efficacy of this approach over multiple real-world datasets.
Designing Closed Human-in-the-loop Deferral Pipelines
Feb 09, 2022



In hybrid human-machine deferral frameworks, a classifier can defer uncertain cases to human decision-makers (who are often themselves fallible). Prior work on simultaneous training of such classifier and deferral models has typically assumed access to an oracle during training to obtain true class labels for training samples, but in practice there often is no such oracle. In contrast, we consider a "closed" decision-making pipeline in which the same fallible human decision-makers used in deferral also provide training labels. How can imperfect and biased human expert labels be used to train a fair and accurate deferral framework? Our key insight is that by exploiting weak prior information, we can match experts to input examples to ensure fairness and accuracy of the resulting deferral framework, even when imperfect and biased experts are used in place of ground truth labels. The efficacy of our approach is shown both by theoretical analysis and by evaluation on two tasks.
Auditing for Diversity using Representative Examples
Jul 15, 2021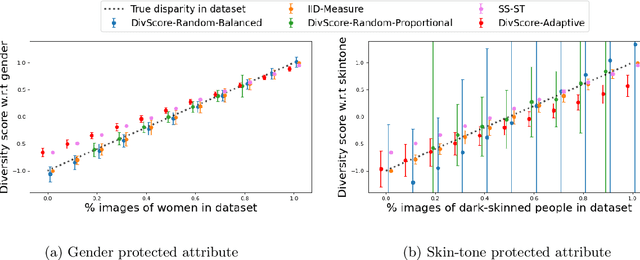
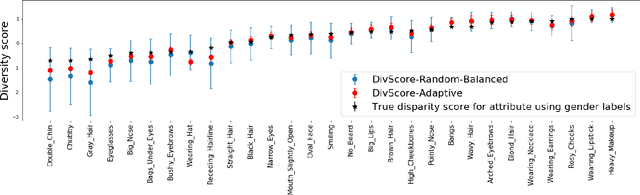
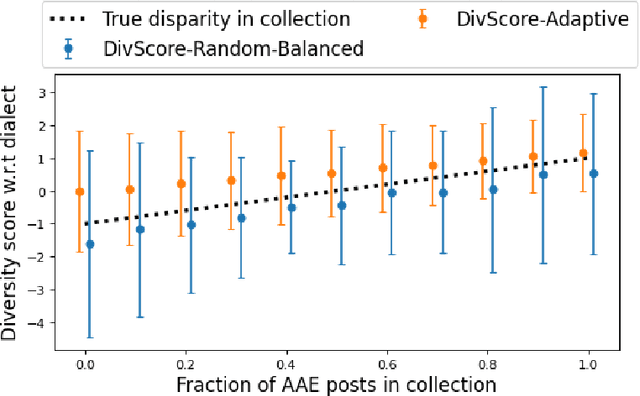
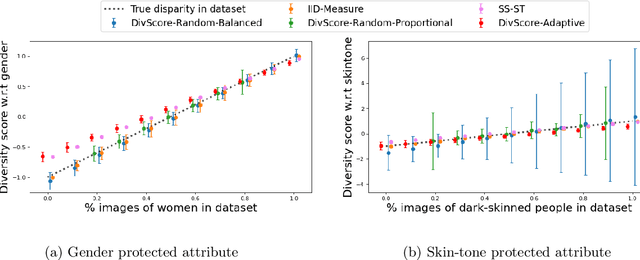
Assessing the diversity of a dataset of information associated with people is crucial before using such data for downstream applications. For a given dataset, this often involves computing the imbalance or disparity in the empirical marginal distribution of a protected attribute (e.g. gender, dialect, etc.). However, real-world datasets, such as images from Google Search or collections of Twitter posts, often do not have protected attributes labeled. Consequently, to derive disparity measures for such datasets, the elements need to hand-labeled or crowd-annotated, which are expensive processes. We propose a cost-effective approach to approximate the disparity of a given unlabeled dataset, with respect to a protected attribute, using a control set of labeled representative examples. Our proposed algorithm uses the pairwise similarity between elements in the dataset and elements in the control set to effectively bootstrap an approximation to the disparity of the dataset. Importantly, we show that using a control set whose size is much smaller than the size of the dataset is sufficient to achieve a small approximation error. Further, based on our theoretical framework, we also provide an algorithm to construct adaptive control sets that achieve smaller approximation errors than randomly chosen control sets. Simulations on two image datasets and one Twitter dataset demonstrate the efficacy of our approach (using random and adaptive control sets) in auditing the diversity of a wide variety of datasets.