 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenUnlearning: Accelerating LLM Unlearning via Unified Benchmarking of Methods and Metrics
Jun 14, 2025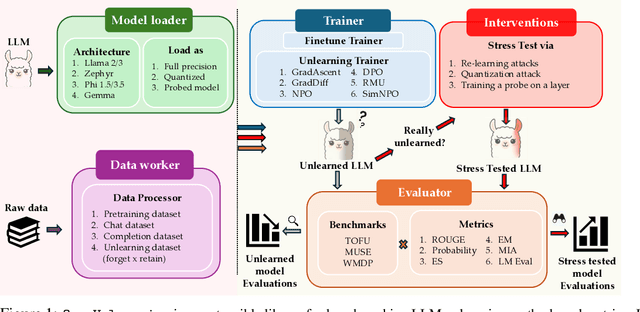



Robust unlearning is crucial for safely deploying large language models (LLMs) in environments where data privacy, model safety, and regulatory compliance must be ensured. Yet the task is inherently challenging, partly due to difficulties in reliably measuring whether unlearning has truly occurred. Moreover, fragmentation in current methodologies and inconsistent evaluation metrics hinder comparative analysis and reproducibility. To unify and accelerate research efforts, we introduce OpenUnlearning, a standardized and extensible framework designed explicitly for benchmarking both LLM unlearning methods and metrics. OpenUnlearning integrates 9 unlearning algorithms and 16 diverse evaluations across 3 leading benchmarks (TOFU, MUSE, and WMDP) and also enables analyses of forgetting behaviors across 450+ checkpoints we publicly release. Leveraging OpenUnlearning, we propose a novel meta-evaluation benchmark focused specifically on assessing the faithfulness and robustness of evaluation metrics themselves. We also benchmark diverse unlearning methods and provide a comparative analysis against an extensive evaluation suite. Overall, we establish a clear, community-driven pathway toward rigorous development in LLM unlearning research.
No Free Lunch: Non-Asymptotic Analysis of Prediction-Powered Inference
May 26, 2025Prediction-Powered Inference (PPI) is a popular strategy for combining gold-standard and possibly noisy pseudo-labels to perform statistical estimation. Prior work has shown an asymptotic "free lunch" for PPI++, an adaptive form of PPI, showing that the *asymptotic* variance of PPI++ is always less than or equal to the variance obtained from using gold-standard labels alone. Notably, this result holds *regardless of the quality of the pseudo-labels*. In this work, we demystify this result by conducting an exact finite-sample analysis of the estimation error of PPI++ on the mean estimation problem. We give a "no free lunch" result, characterizing the settings (and sample sizes) where PPI++ has provably worse estimation error than using gold-standard labels alone. Specifically, PPI++ will outperform if and only if the correlation between pseudo- and gold-standard is above a certain level that depends on the number of labeled samples ($n$). In some cases our results simplify considerably: For Gaussian data, the correlation must be at least $1/\sqrt{n - 2}$ in order to see improvement, and a similar result holds for binary labels. In experiments, we illustrate that our theoretical findings hold on real-world datasets, and give insights into trade-offs between single-sample and sample-splitting variants of PPI++.
Generate to Discriminate: Expert Routing for Continual Learning
Dec 22, 2024In many real-world settings, regulations and economic incentives permit the sharing of models but not data across institutional boundaries. In such scenarios, practitioners might hope to adapt models to new domains, without losing performance on previous domains (so-called catastrophic forgetting). While any single model may struggle to achieve this goal, learning an ensemble of domain-specific experts offers the potential to adapt more closely to each individual institution. However, a core challenge in this context is determining which expert to deploy at test time. In this paper, we propose Generate to Discriminate (G2D), a domain-incremental continual learning method that leverages synthetic data to train a domain-discriminator that routes samples at inference time to the appropriate expert. Surprisingly, we find that leveraging synthetic data in this capacity is more effective than using the samples to \textit{directly} train the downstream classifier (the more common approach to leveraging synthetic data in the lifelong learning literature). We observe that G2D outperforms competitive domain-incremental learning methods on tasks in both vision and language modalities, providing a new perspective on the use of synthetic data in the lifelong learning literature.
The Limited Impact of Medical Adaptation of Large Language and Vision-Language Models
Nov 13, 2024



Several recent works seek to develop foundation models specifically for medical applications, adapting general-purpose large language models (LLMs) and vision-language models (VLMs) via continued pretraining on publicly available biomedical corpora. These works typically claim that such domain-adaptive pretraining (DAPT) improves performance on downstream medical tasks, such as answering medical licensing exam questions. In this paper, we compare ten public "medical" LLMs and two VLMs against their corresponding base models, arriving at a different conclusion: all medical VLMs and nearly all medical LLMs fail to consistently improve over their base models in the zero-/few-shot prompting and supervised fine-tuning regimes for medical question-answering (QA). For instance, across all tasks and model pairs we consider in the 3-shot setting, medical LLMs only outperform their base models in 22.7% of cases, reach a (statistical) tie in 36.8% of cases, and are significantly worse than their base models in the remaining 40.5% of cases. Our conclusions are based on (i) comparing each medical model head-to-head, directly against the corresponding base model; (ii) optimizing the prompts for each model separately in zero-/few-shot prompting; and (iii) accounting for statistical uncertainty in comparisons. While these basic practices are not consistently adopted in the literature, our ablations show that they substantially impact conclusions. Meanwhile, we find that after fine-tuning on specific QA tasks, medical LLMs can show performance improvements, but the benefits do not carry over to tasks based on clinical notes. Our findings suggest that state-of-the-art general-domain models may already exhibit strong medical knowledge and reasoning capabilities, and offer recommendations to strengthen the conclusions of future studies.
Medical Adaptation of Large Language and Vision-Language Models: Are We Making Progress?
Nov 06, 2024



Several recent works seek to develop foundation models specifically for medical applications, adapting general-purpose large language models (LLMs) and vision-language models (VLMs) via continued pretraining on publicly available biomedical corpora. These works typically claim that such domain-adaptive pretraining (DAPT) improves performance on downstream medical tasks, such as answering medical licensing exam questions. In this paper, we compare seven public "medical" LLMs and two VLMs against their corresponding base models, arriving at a different conclusion: all medical VLMs and nearly all medical LLMs fail to consistently improve over their base models in the zero-/few-shot prompting regime for medical question-answering (QA) tasks. For instance, across the tasks and model pairs we consider in the 3-shot setting, medical LLMs only outperform their base models in 12.1% of cases, reach a (statistical) tie in 49.8% of cases, and are significantly worse than their base models in the remaining 38.2% of cases. Our conclusions are based on (i) comparing each medical model head-to-head, directly against the corresponding base model; (ii) optimizing the prompts for each model separately; and (iii) accounting for statistical uncertainty in comparisons. While these basic practices are not consistently adopted in the literature, our ablations show that they substantially impact conclusions. Our findings suggest that state-of-the-art general-domain models may already exhibit strong medical knowledge and reasoning capabilities, and offer recommendations to strengthen the conclusions of future studies.
Online Data Collection for Efficient Semiparametric Inference
Nov 05, 2024



While many works have studied statistical data fusion, they typically assume that the various datasets are given in advance. However, in practice, estimation requires difficult data collection decisions like determining the available data sources, their costs, and how many samples to collect from each source. Moreover, this process is often sequential because the data collected at a given time can improve collection decisions in the future. In our setup, given access to multiple data sources and budget constraints, the agent must sequentially decide which data source to query to efficiently estimate a target parameter. We formalize this task using Online Moment Selection, a semiparametric framework that applies to any parameter identified by a set of moment conditions. Interestingly, the optimal budget allocation depends on the (unknown) true parameters. We present two online data collection policies, Explore-then-Commit and Explore-then-Greedy, that use the parameter estimates at a given time to optimally allocate the remaining budget in the future steps. We prove that both policies achieve zero regret (assessed by asymptotic MSE) relative to an oracle policy. We empirically validate our methods on both synthetic and real-world causal effect estimation tasks, demonstrating that the online data collection policies outperform their fixed counterparts.
Failure Modes of LLMs for Causal Reasoning on Narratives
Oct 31, 2024



In this work, we investigate the causal reasoning abilities of large language models (LLMs) through the representative problem of inferring causal relationships from narratives. We find that even state-of-the-art language models rely on unreliable shortcuts, both in terms of the narrative presentation and their parametric knowledge. For example, LLMs tend to determine causal relationships based on the topological ordering of events (i.e., earlier events cause later ones), resulting in lower performance whenever events are not narrated in their exact causal order. Similarly, we demonstrate that LLMs struggle with long-term causal reasoning and often fail when the narratives are long and contain many events. Additionally, we show LLMs appear to rely heavily on their parametric knowledge at the expense of reasoning over the provided narrative. This degrades their abilities whenever the narrative opposes parametric knowledge. We extensively validate these failure modes through carefully controlled synthetic experiments, as well as evaluations on real-world narratives. Finally, we observe that explicitly generating a causal graph generally improves performance while naive chain-of-thought is ineffective. Collectively, our results distill precise failure modes of current state-of-the-art models and can pave the way for future techniques to enhance causal reasoning in LLMs.
The Fragility of Fairness: Causal Sensitivity Analysis for Fair Machine Learning
Oct 15, 2024



Fairness metrics are a core tool in the fair machine learning literature (FairML), used to determine that ML models are, in some sense, "fair". Real-world data, however, are typically plagued by various measurement biases and other violated assumptions, which can render fairness assessments meaningless. We adapt tools from causal sensitivity analysis to the FairML context, providing a general framework which (1) accommodates effectively any combination of fairness metric and bias that can be posed in the "oblivious setting"; (2) allows researchers to investigate combinations of biases, resulting in non-linear sensitivity; and (3) enables flexible encoding of domain-specific constraints and assumptions. Employing this framework, we analyze the sensitivity of the most common parity metrics under 3 varieties of classifier across 14 canonical fairness datasets. Our analysis reveals the striking fragility of fairness assessments to even minor dataset biases. We show that causal sensitivity analysis provides a powerful and necessary toolkit for gauging the informativeness of parity metric evaluations. Our repository is available here: https://github.com/Jakefawkes/fragile_fair.
LLM-Select: Feature Selection with Large Language Models
Jul 02, 2024In this paper, we demonstrate a surprising capability of large language models (LLMs): given only input feature names and a description of a prediction task, they are capable of selecting the most predictive features, with performance rivaling the standard tools of data science. Remarkably, these models exhibit this capacity across various query mechanisms. For example, we zero-shot prompt an LLM to output a numerical importance score for a feature (e.g., "blood pressure") in predicting an outcome of interest (e.g., "heart failure"), with no additional context. In particular, we find that the latest models, such as GPT-4, can consistently identify the most predictive features regardless of the query mechanism and across various prompting strategies. We illustrate these findings through extensive experiments on real-world data, where we show that LLM-based feature selection consistently achieves strong performance competitive with data-driven methods such as the LASSO, despite never having looked at the downstream training data. Our findings suggest that LLMs may be useful not only for selecting the best features for training but also for deciding which features to collect in the first place. This could potentially benefit practitioners in domains like healthcare, where collecting high-quality data comes at a high cost.
Understanding Hallucinations in Diffusion Models through Mode Interpolation
Jun 13, 2024



Colloquially speaking, image generation models based upon diffusion processes are frequently said to exhibit "hallucinations," samples that could never occur in the training data. But where do such hallucinations come from? In this paper, we study a particular failure mode in diffusion models, which we term mode interpolation. Specifically, we find that diffusion models smoothly "interpolate" between nearby data modes in the training set, to generate samples that are completely outside the support of the original training distribution; this phenomenon leads diffusion models to generate artifacts that never existed in real data (i.e., hallucinations). We systematically study the reasons for, and the manifestation of this phenomenon. Through experiments on 1D and 2D Gaussians, we show how a discontinuous loss landscape in the diffusion model's decoder leads to a region where any smooth approximation will cause such hallucinations. Through experiments on artificial datasets with various shapes, we show how hallucination leads to the generation of combinations of shapes that never existed. Finally, we show that diffusion models in fact know when they go out of support and hallucinate. This is captured by the high variance in the trajectory of the generated sample towards the final few backward sampling process. Using a simple metric to capture this variance, we can remove over 95% of hallucinations at generation time while retaining 96% of in-support samples. We conclude our exploration by showing the implications of such hallucination (and its removal) on the collapse (and stabilization) of recursive training on synthetic data with experiments on MNIST and 2D Gaussians dataset. We release our code at https://github.com/locuslab/diffusion-model-hallucination.