 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Trial-and-Error Navigation With a Sequential Decision Model of Information Scent
Mar 12, 2026Users often struggle to locate an item within an information architecture, particularly when links are ambiguous or deeply nested in hierarchies. Information scent has been used to explain why users select incorrect links, but this concept assumes that users see all available links before deciding. In practice, users frequently select a link too quickly, overlook relevant cues, and then rely on backtracking when errors occur. We extend the concept of information scent by framing navigation as a sequential decision-making problem under memory constraints. Specifically, we assume that users do not scan entire pages but instead inspect strategically, looking "just enough" to find the target given their time budget. To choose which item to inspect next, they consider both local (this page) and global (site) scent; however, both are constrained by memory. Trying to avoid wasting time, they occasionally choose the wrong links without inspecting everything on a page. Comparisons with empirical data show that our model replicates key navigation behaviors: premature selections, wrong turns, and recovery from backtracking. We conclude that trial-and-error behavior is well explained by information scent when accounting for the sequential and bounded characteristics of the navigation problem.
A Resource-Rational Principle for Modeling Visual Attention Control
Mar 02, 2026Understanding how people allocate visual attention is central to Human-Computer Interaction (HCI), yet existing computational models of attention are often either descriptive, task-specific, or difficult to interpret. My dissertation develops a resource-rational, simulation-based framework for modeling visual attention as a sequential decision-making process under perceptual, memory, and time constraints. I formalize visual tasks, such as reading and multitasking, as bounded-optimal control problems using Partially Observable Markov Decision Processes, enabling eye-movement behaviors such as fixation and attention switching to emerge from rational adaptation rather than being hand-coded or purely data-driven. These models are instantiated in simulation environments spanning traditional text reading and reading-while-walking with smart glasses, where they reproduce classic empirical effects, explain observed trade-offs between comprehension and safety, and generate novel predictions under time pressure and interface variation. Collectively, this work contributes a unified computational account of visual attention, offering new tools for theory-driven and resource-efficient HCI design.
Simulation-based Optimization for Augmented Reading
Feb 26, 2026Augmented reading systems aim to adapt text presentation to improve comprehension and task performance, yet existing approaches rely heavily on heuristics, opaque data-driven models, or repeated human involvement in the design loop. We propose framing augmented reading as a simulation-based optimization problem grounded in resource-rational models of human reading. These models instantiate a simulated reader that allocates limited cognitive resources, such as attention, memory, and time under task demands, enabling systematic evaluation of text user interfaces. We introduce two complementary optimization pipelines: an offline approach that explores design alternatives using simulated readers, and an online approach that personalizes reading interfaces in real time using ongoing interaction data. Together, this perspective enables adaptive, explainable, and scalable augmented reading design without relying solely on human testing.
AutoRegressive Generation with B-rep Holistic Token Sequence Representation
Jan 23, 2026Previous representation and generation approaches for the B-rep relied on graph-based representations that disentangle geometric and topological features through decoupled computational pipelines, thereby precluding the application of sequence-based generative frameworks, such as transformer architectures that have demonstrated remarkable performance. In this paper, we propose BrepARG, the first attempt to encode B-rep's geometry and topology into a holistic token sequence representation, enabling sequence-based B-rep generation with an autoregressive architecture. Specifically, BrepARG encodes B-rep into 3 types of tokens: geometry and position tokens representing geometric features, and face index tokens representing topology. Then the holistic token sequence is constructed hierarchically, starting with constructing the geometry blocks (i.e., faces and edges) using the above tokens, followed by geometry block sequencing. Finally, we assemble the holistic sequence representation for the entire B-rep. We also construct a transformer-based autoregressive model that learns the distribution over holistic token sequences via next-token prediction, using a multi-layer decoder-only architecture with causal masking. Experiments demonstrate that BrepARG achieves state-of-the-art (SOTA) performance. BrepARG validates the feasibility of representing B-rep as holistic token sequences, opening new directions for B-rep generation.
BrepLLM: Native Boundary Representation Understanding with Large Language Models
Dec 18, 2025



Current token-sequence-based Large Language Models (LLMs) are not well-suited for directly processing 3D Boundary Representation (Brep) models that contain complex geometric and topological information. We propose BrepLLM, the first framework that enables LLMs to parse and reason over raw Brep data, bridging the modality gap between structured 3D geometry and natural language. BrepLLM employs a two-stage training pipeline: Cross-modal Alignment Pre-training and Multi-stage LLM Fine-tuning. In the first stage, an adaptive UV sampling strategy converts Breps into graphs representation with geometric and topological information. We then design a hierarchical BrepEncoder to extract features from geometry (i.e., faces and edges) and topology, producing both a single global token and a sequence of node tokens. Then we align the global token with text embeddings from a frozen CLIP text encoder (ViT-L/14) via contrastive learning. In the second stage, we integrate the pretrained BrepEncoder into an LLM. We then align its sequence of node tokens using a three-stage progressive training strategy: (1) training an MLP-based semantic mapping from Brep representation to 2D with 2D-LLM priors. (2) performing fine-tuning of the LLM. (3) designing a Mixture-of-Query Experts (MQE) to enhance geometric diversity modeling. We also construct Brep2Text, a dataset comprising 269,444 Brep-text question-answer pairs. Experiments show that BrepLLM achieves state-of-the-art (SOTA) results on 3D object classification and captioning tasks.
WorldReel: 4D Video Generation with Consistent Geometry and Motion Modeling
Dec 08, 2025Recent video generators achieve striking photorealism, yet remain fundamentally inconsistent in 3D. We present WorldReel, a 4D video generator that is natively spatio-temporally consistent. WorldReel jointly produces RGB frames together with 4D scene representations, including pointmaps, camera trajectory, and dense flow mapping, enabling coherent geometry and appearance modeling over time. Our explicit 4D representation enforces a single underlying scene that persists across viewpoints and dynamic content, yielding videos that remain consistent even under large non-rigid motion and significant camera movement. We train WorldReel by carefully combining synthetic and real data: synthetic data providing precise 4D supervision (geometry, motion, and camera), while real videos contribute visual diversity and realism. This blend allows WorldReel to generalize to in-the-wild footage while preserving strong geometric fidelity. Extensive experiments demonstrate that WorldReel sets a new state-of-the-art for consistent video generation with dynamic scenes and moving cameras, improving metrics of geometric consistency, motion coherence, and reducing view-time artifacts over competing methods. We believe that WorldReel brings video generation closer to 4D-consistent world modeling, where agents can render, interact, and reason about scenes through a single and stable spatiotemporal representation.
Positional Encoding Field
Oct 23, 2025Diffusion Transformers (DiTs) have emerged as the dominant architecture for visual generation, powering state-of-the-art image and video models. By representing images as patch tokens with positional encodings (PEs), DiTs combine Transformer scalability with spatial and temporal inductive biases. In this work, we revisit how DiTs organize visual content and discover that patch tokens exhibit a surprising degree of independence: even when PEs are perturbed, DiTs still produce globally coherent outputs, indicating that spatial coherence is primarily governed by PEs. Motivated by this finding, we introduce the Positional Encoding Field (PE-Field), which extends positional encodings from the 2D plane to a structured 3D field. PE-Field incorporates depth-aware encodings for volumetric reasoning and hierarchical encodings for fine-grained sub-patch control, enabling DiTs to model geometry directly in 3D space. Our PE-Field-augmented DiT achieves state-of-the-art performance on single-image novel view synthesis and generalizes to controllable spatial image editing.
Organ-Agents: Virtual Human Physiology Simulator via LLMs
Aug 20, 2025Recent advances in large language models (LLMs) have enabled new possibilities in simulating complex physiological systems. We introduce Organ-Agents, a multi-agent framework that simulates human physiology via LLM-driven agents. Each Simulator models a specific system (e.g., cardiovascular, renal, immune). Training consists of supervised fine-tuning on system-specific time-series data, followed by reinforcement-guided coordination using dynamic reference selection and error correction. We curated data from 7,134 sepsis patients and 7,895 controls, generating high-resolution trajectories across 9 systems and 125 variables. Organ-Agents achieved high simulation accuracy on 4,509 held-out patients, with per-system MSEs <0.16 and robustness across SOFA-based severity strata. External validation on 22,689 ICU patients from two hospitals showed moderate degradation under distribution shifts with stable simulation. Organ-Agents faithfully reproduces critical multi-system events (e.g., hypotension, hyperlactatemia, hypoxemia) with coherent timing and phase progression. Evaluation by 15 critical care physicians confirmed realism and physiological plausibility (mean Likert ratings 3.9 and 3.7). Organ-Agents also enables counterfactual simulations under alternative sepsis treatment strategies, generating trajectories and APACHE II scores aligned with matched real-world patients. In downstream early warning tasks, classifiers trained on synthetic data showed minimal AUROC drops (<0.04), indicating preserved decision-relevant patterns. These results position Organ-Agents as a credible, interpretable, and generalizable digital twin for precision diagnosis, treatment simulation, and hypothesis testing in critical care.
BRepFormer: Transformer-Based B-rep Geometric Feature Recognition
Apr 10, 2025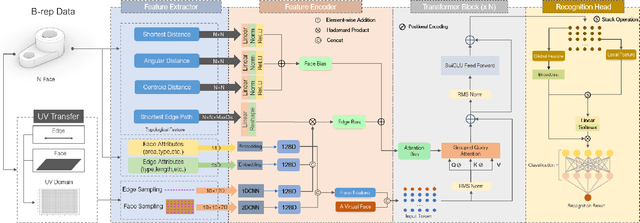

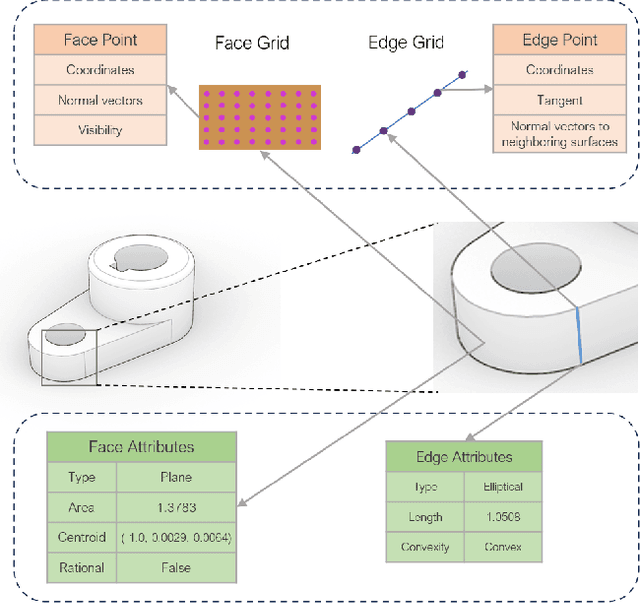
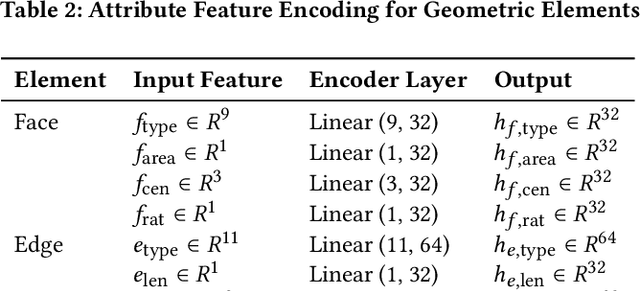
Recognizing geometric features on B-rep models is a cornerstone technique for multimedia content-based retrieval and has been widely applied in intelligent manufacturing. However, previous research often merely focused on Machining Feature Recognition (MFR), falling short in effectively capturing the intricate topological and geometric characteristics of complex geometry features. In this paper, we propose BRepFormer, a novel transformer-based model to recognize both machining feature and complex CAD models' features. BRepFormer encodes and fuses the geometric and topological features of the models. Afterwards, BRepFormer utilizes a transformer architecture for feature propagation and a recognition head to identify geometry features. During each iteration of the transformer, we incorporate a bias that combines edge features and topology features to reinforce geometric constraints on each face. In addition, we also proposed a dataset named Complex B-rep Feature Dataset (CBF), comprising 20,000 B-rep models. By covering more complex B-rep models, it is better aligned with industrial applications. The experimental results demonstrate that BRepFormer achieves state-of-the-art accuracy on the MFInstSeg, MFTRCAD, and our CBF datasets.
DragScene: Interactive 3D Scene Editing with Single-view Drag Instructions
Dec 18, 2024



3D editing has shown remarkable capability in editing scenes based on various instructions. However, existing methods struggle with achieving intuitive, localized editing, such as selectively making flowers blossom. Drag-style editing has shown exceptional capability to edit images with direct manipulation instead of ambiguous text commands. Nevertheless, extending drag-based editing to 3D scenes presents substantial challenges due to multi-view inconsistency. To this end, we introduce DragScene, a framework that integrates drag-style editing with diverse 3D representations. First, latent optimization is performed on a reference view to generate 2D edits based on user instructions. Subsequently, coarse 3D clues are reconstructed from the reference view using a point-based representation to capture the geometric details of the edits. The latent representation of the edited view is then mapped to these 3D clues, guiding the latent optimization of other views. This process ensures that edits are propagated seamlessly across multiple views, maintaining multi-view consistency. Finally, the target 3D scene is reconstructed from the edited multi-view images. Extensive experiments demonstrate that DragScene facilitates precise and flexible drag-style editing of 3D scenes, supporting broad applicability across diverse 3D representations.