 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Non-Adversarial Image Synthesis with Generative Latent Nearest Neighbors
Dec 21, 2018


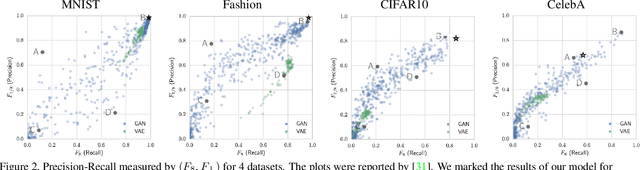

Unconditional image generation has recently been dominated by generative adversarial networks (GANs). GAN methods train a generator which regresses images from random noise vectors, as well as a discriminator that attempts to differentiate between the generated images and a training set of real images. GANs have shown amazing results at generating realistic looking images. Despite their success, GANs suffer from critical drawbacks including: unstable training and mode-dropping. The weaknesses in GANs have motivated research into alternatives including: variational auto-encoders (VAEs), latent embedding learning methods (e.g. GLO) and nearest-neighbor based implicit maximum likelihood estimation (IMLE). Unfortunately at the moment, GANs still significantly outperform the alternative methods for image generation. In this work, we present a novel method - Generative Latent Nearest Neighbors (GLANN) - for training generative models without adversarial training. GLANN combines the strengths of IMLE and GLO in a way that overcomes the main drawbacks of each method. Consequently, GLANN generates images that are far better than GLO and IMLE. Our method does not suffer from mode collapse which plagues GAN training and is much more stable. Qualitative results show that GLANN outperforms a baseline consisting of 800 GANs and VAEs on commonly used datasets. Our models are also shown to be effective for training truly non-adversarial unsupervised image translation.
Areas of Attention for Image Captioning
Aug 25, 2017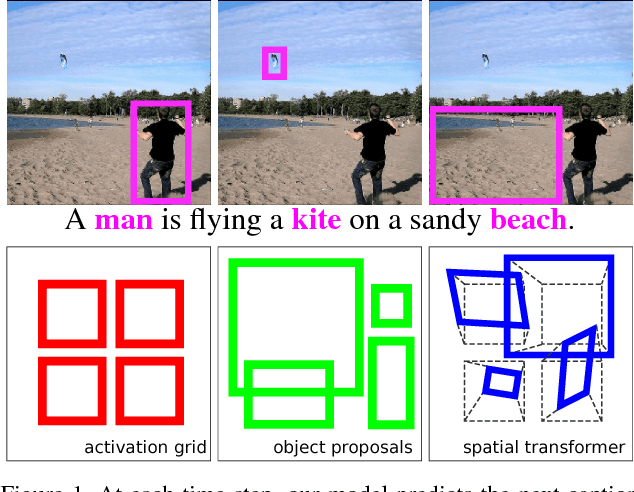
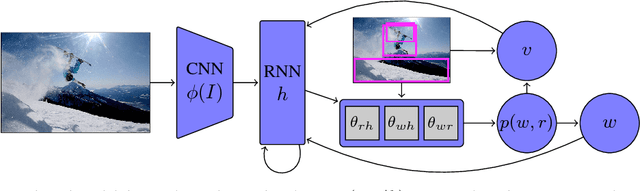
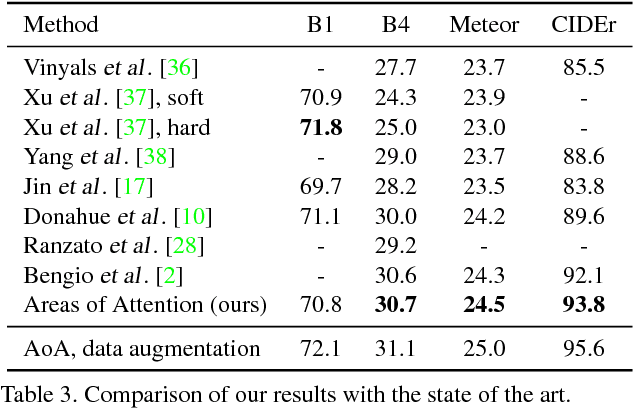

We propose "Areas of Attention", a novel attention-based model for automatic image captioning. Our approach models the dependencies between image regions, caption words, and the state of an RNN language model, using three pairwise interactions. In contrast to previous attention-based approaches that associate image regions only to the RNN state, our method allows a direct association between caption words and image regions. During training these associations are inferred from image-level captions, akin to weakly-supervised object detector training. These associations help to improve captioning by localizing the corresponding regions during testing. We also propose and compare different ways of generating attention areas: CNN activation grids, object proposals, and spatial transformers nets applied in a convolutional fashion. Spatial transformers give the best results. They allow for image specific attention areas, and can be trained jointly with the rest of the network. Our attention mechanism and spatial transformer attention areas together yield state-of-the-art results on the MSCOCO dataset.o meaningful latent semantic structure in the generated captions.
ACN: Adversarial Co-training Network for Brain Tumor Segmentation with Missing Modalities
Jun 29, 2021
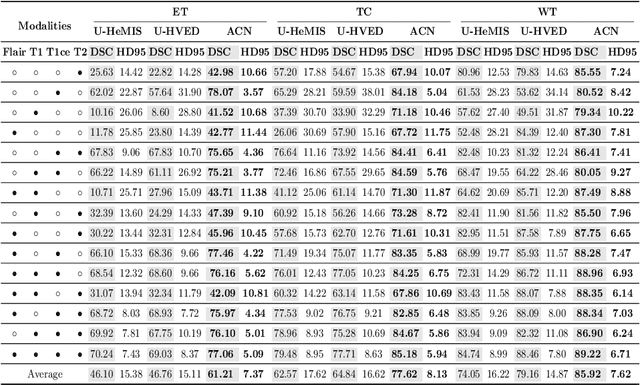
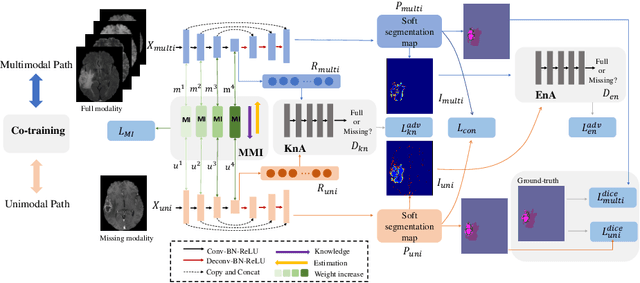
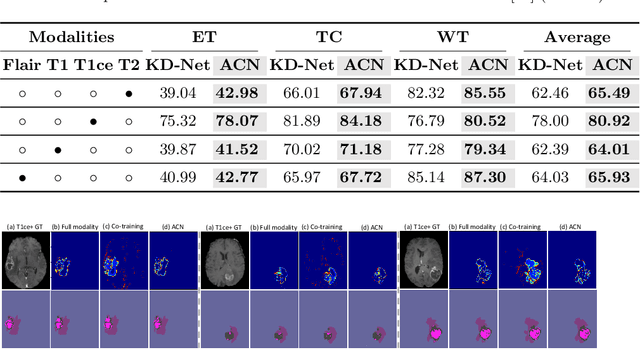
Accurate segmentation of brain tumors from magnetic resonance imaging (MRI) is clinically relevant in diagnoses, prognoses and surgery treatment, which requires multiple modalities to provide complementary morphological and physiopathologic information. However, missing modality commonly occurs due to image corruption, artifacts, different acquisition protocols or allergies to certain contrast agents in clinical practice. Though existing efforts demonstrate the possibility of a unified model for all missing situations, most of them perform poorly when more than one modality is missing. In this paper, we propose a novel Adversarial Co-training Network (ACN) to solve this issue, in which a series of independent yet related models are trained dedicated to each missing situation with significantly better results. Specifically, ACN adopts a novel co-training network, which enables a coupled learning process for both full modality and missing modality to supplement each other's domain and feature representations, and more importantly, to recover the `missing' information of absent modalities. Then, two unsupervised modules, i.e., entropy and knowledge adversarial learning modules are proposed to minimize the domain gap while enhancing prediction reliability and encouraging the alignment of latent representations, respectively. We also adapt modality-mutual information knowledge transfer learning to ACN to retain the rich mutual information among modalities. Extensive experiments on BraTS2018 dataset show that our proposed method significantly outperforms all state-of-the-art methods under any missing situation.
Consistent Recurrent Neural Networks for 3D Neuron Segmentation
Feb 01, 2021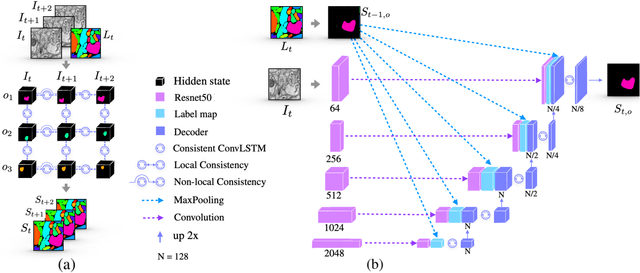

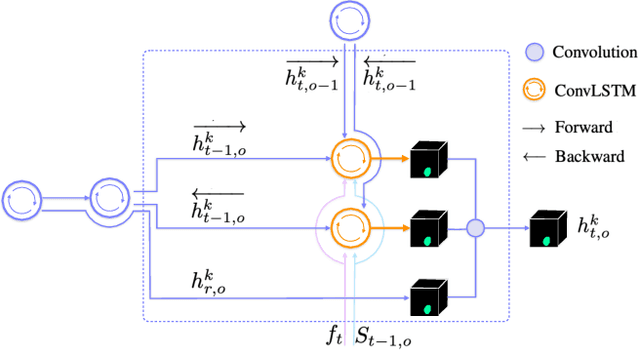

We present a recurrent network for the 3D reconstruction of neurons that sequentially generates binary masks for every object in an image with spatio-temporal consistency. Our network models consistency in two parts: (i) local, which allows exploring non-occluding and temporally-adjacent object relationships with bi-directional recurrence. (ii) non-local, which allows exploring long-range object relationships in the temporal domain with skip connections. Our proposed network is end-to-end trainable from an input image to a sequence of object masks, and, compared to methods relying on object boundaries, its output does not require post-processing. We evaluate our method on three benchmarks for neuron segmentation and achieved state-of-the-art performance on the SNEMI3D challenge.
Wallpaper Texture Generation and Style Transfer Based on Multi-label Semantics
Jun 22, 2021


Textures contain a wealth of image information and are widely used in various fields such as computer graphics and computer vision. With the development of machine learning, the texture synthesis and generation have been greatly improved. As a very common element in everyday life, wallpapers contain a wealth of texture information, making it difficult to annotate with a simple single label. Moreover, wallpaper designers spend significant time to create different styles of wallpaper. For this purpose, this paper proposes to describe wallpaper texture images by using multi-label semantics. Based on these labels and generative adversarial networks, we present a framework for perception driven wallpaper texture generation and style transfer. In this framework, a perceptual model is trained to recognize whether the wallpapers produced by the generator network are sufficiently realistic and have the attribute designated by given perceptual description; these multi-label semantic attributes are treated as condition variables to generate wallpaper images. The generated wallpaper images can be converted to those with well-known artist styles using CycleGAN. Finally, using the aesthetic evaluation method, the generated wallpaper images are quantitatively measured. The experimental results demonstrate that the proposed method can generate wallpaper textures conforming to human aesthetics and have artistic characteristics.
Cross-Domain Car Detection Using Unsupervised Image-to-Image Translation: From Day to Night
Jul 19, 2019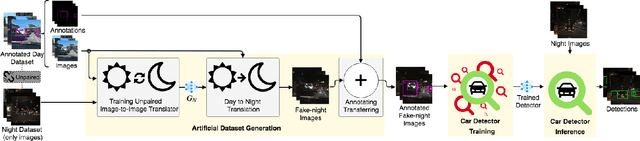
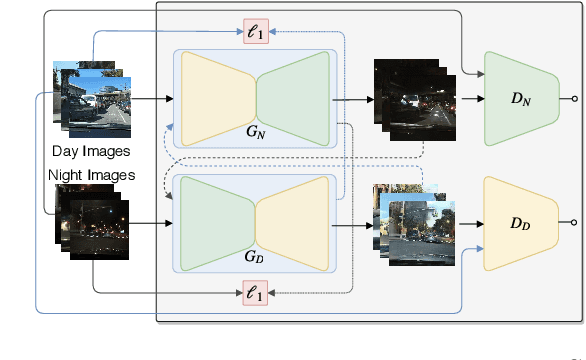


Deep learning techniques have enabled the emergence of state-of-the-art models to address object detection tasks. However, these techniques are data-driven, delegating the accuracy to the training dataset which must resemble the images in the target task. The acquisition of a dataset involves annotating images, an arduous and expensive process, generally requiring time and manual effort. Thus, a challenging scenario arises when the target domain of application has no annotated dataset available, making tasks in such situation to lean on a training dataset of a different domain. Sharing this issue, object detection is a vital task for autonomous vehicles where the large amount of driving scenarios yields several domains of application requiring annotated data for the training process. In this work, a method for training a car detection system with annotated data from a source domain (day images) without requiring the image annotations of the target domain (night images) is presented. For that, a model based on Generative Adversarial Networks (GANs) is explored to enable the generation of an artificial dataset with its respective annotations. The artificial dataset (fake dataset) is created translating images from day-time domain to night-time domain. The fake dataset, which comprises annotated images of only the target domain (night images), is then used to train the car detector model. Experimental results showed that the proposed method achieved significant and consistent improvements, including the increasing by more than 10% of the detection performance when compared to the training with only the available annotated data (i.e., day images).
Consistency-based Active Learning for Object Detection
Mar 23, 2021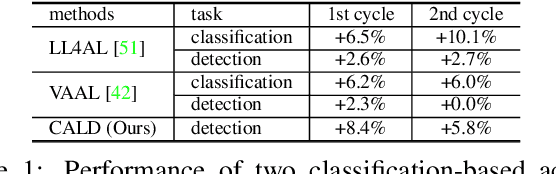
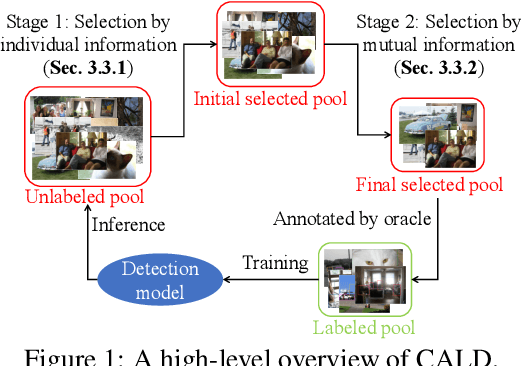
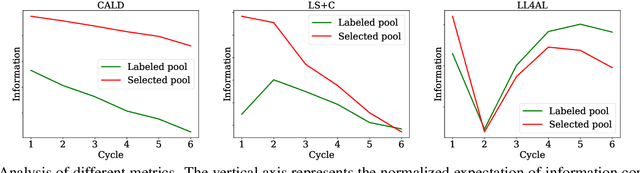
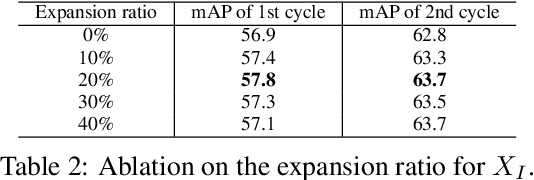
Active learning aims to improve the performance of task model by selecting the most informative samples with a limited budget. Unlike most recent works that focused on applying active learning for image classification, we propose an effective Consistency-based Active Learning method for object Detection (CALD), which fully explores the consistency between original and augmented data. CALD has three appealing benefits. (i) CALD is systematically designed by investigating the weaknesses of existing active learning methods, which do not take the unique challenges of object detection into account. (ii) CALD unifies box regression and classification with a single metric, which is not concerned by active learning methods for classification. CALD also focuses on the most informative local region rather than the whole image, which is beneficial for object detection. (iii) CALD not only gauges individual information for sample selection, but also leverages mutual information to encourage a balanced data distribution. Extensive experiments show that CALD significantly outperforms existing state-of-the-art task-agnostic and detection-specific active learning methods on general object detection datasets. Based on the Faster R-CNN detector, CALD consistently surpasses the baseline method (random selection) by 2.9/2.8/0.8 mAP on average on PASCAL VOC 2007, PASCAL VOC 2012, and MS COCO. Code is available at \url{https://github.com/we1pingyu/CALD}
Enhanced Gradient for Differentiable Architecture Search
Mar 23, 2021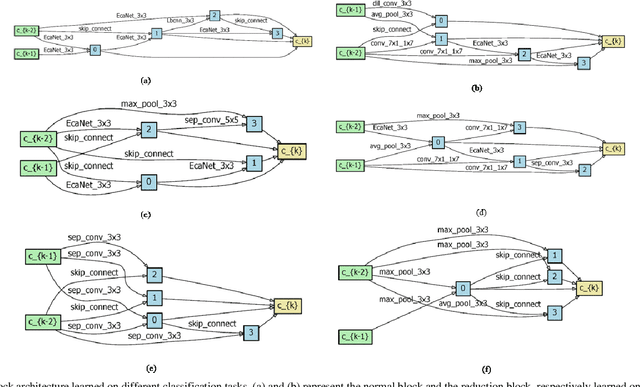
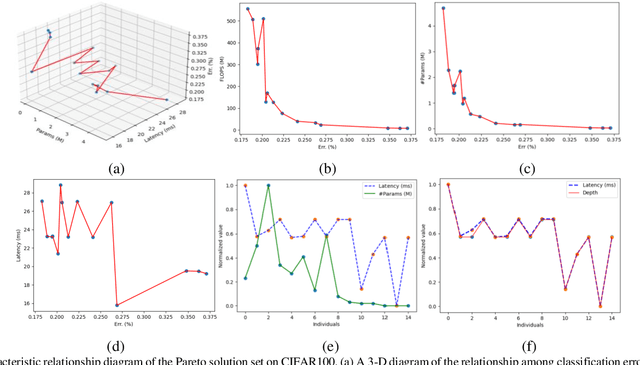
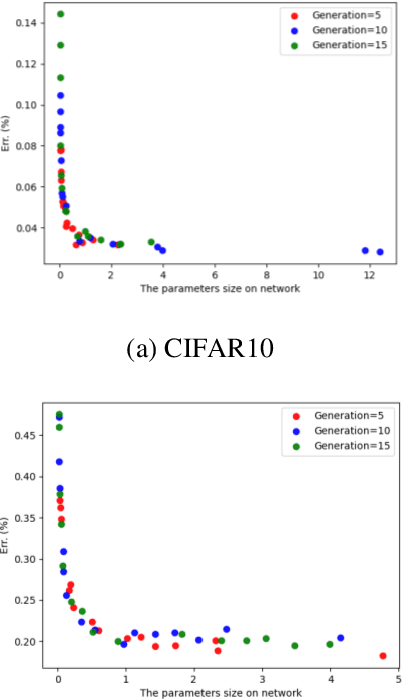
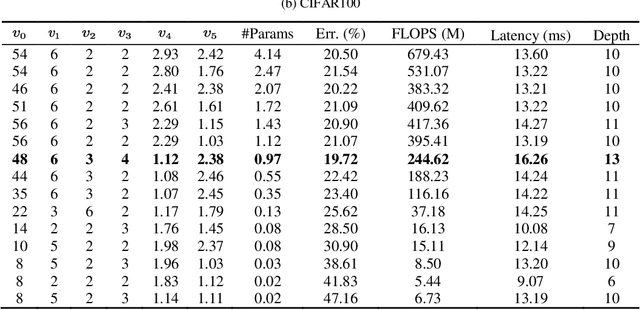
In recent years, neural architecture search (NAS) methods have been proposed for the automatic generation of task-oriented network architecture in image classification. However, the architectures obtained by existing NAS approaches are optimized only for classification performance and do not adapt to devices with limited computational resources. To address this challenge, we propose a neural network architecture search algorithm aiming to simultaneously improve network performance (e.g., classification accuracy) and reduce network complexity. The proposed framework automatically builds the network architecture at two stages: block-level search and network-level search. At the stage of block-level search, a relaxation method based on the gradient is proposed, using an enhanced gradient to design high-performance and low-complexity blocks. At the stage of network-level search, we apply an evolutionary multi-objective algorithm to complete the automatic design from blocks to the target network. The experiment results demonstrate that our method outperforms all evaluated hand-crafted networks in image classification, with an error rate of on CIFAR10 and an error rate of on CIFAR100, both at network parameter size less than one megabit. Moreover, compared with other neural architecture search methods, our method offers a tremendous reduction in designed network architecture parameters.
MarioNette: Self-Supervised Sprite Learning
Apr 29, 2021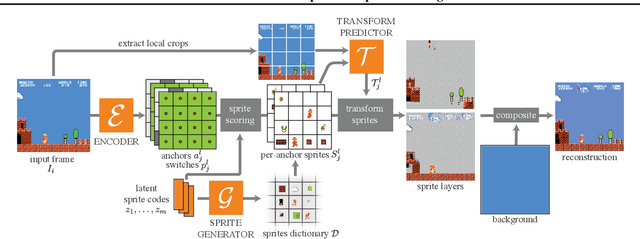
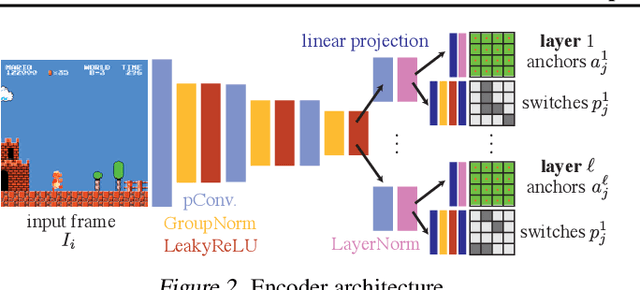
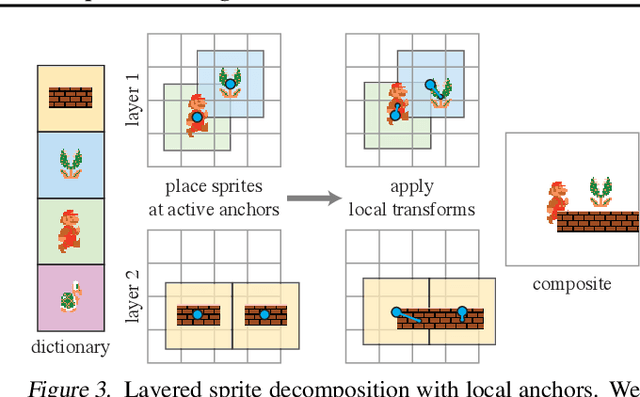
Visual content often contains recurring elements. Text is made up of glyphs from the same font, animations, such as cartoons or video games, are composed of sprites moving around the screen, and natural videos frequently have repeated views of objects. In this paper, we propose a deep learning approach for obtaining a graphically disentangled representation of recurring elements in a completely self-supervised manner. By jointly learning a dictionary of texture patches and training a network that places them onto a canvas, we effectively deconstruct sprite-based content into a sparse, consistent, and interpretable representation that can be easily used in downstream tasks. Our framework offers a promising approach for discovering recurring patterns in image collections without supervision.
Semantic Scene Completion via Integrating Instances and Scene in-the-Loop
Apr 08, 2021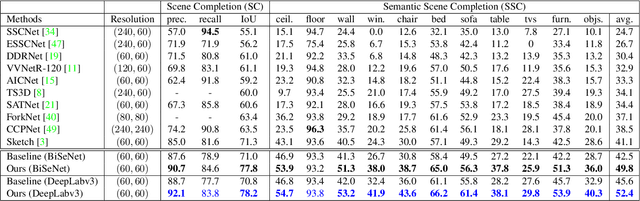

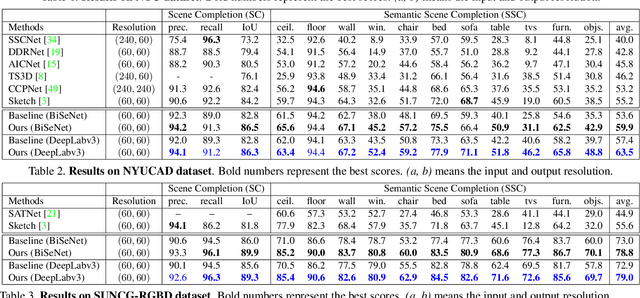
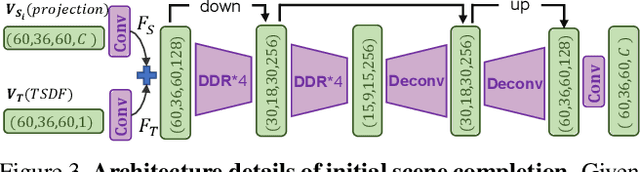
Semantic Scene Completion aims at reconstructing a complete 3D scene with precise voxel-wise semantics from a single-view depth or RGBD image. It is a crucial but challenging problem for indoor scene understanding. In this work, we present a novel framework named Scene-Instance-Scene Network (\textit{SISNet}), which takes advantages of both instance and scene level semantic information. Our method is capable of inferring fine-grained shape details as well as nearby objects whose semantic categories are easily mixed-up. The key insight is that we decouple the instances from a coarsely completed semantic scene instead of a raw input image to guide the reconstruction of instances and the overall scene. SISNet conducts iterative scene-to-instance (SI) and instance-to-scene (IS) semantic completion. Specifically, the SI is able to encode objects' surrounding context for effectively decoupling instances from the scene and each instance could be voxelized into higher resolution to capture finer details. With IS, fine-grained instance information can be integrated back into the 3D scene and thus leads to more accurate semantic scene completion. Utilizing such an iterative mechanism, the scene and instance completion benefits each other to achieve higher completion accuracy. Extensively experiments show that our proposed method consistently outperforms state-of-the-art methods on both real NYU, NYUCAD and synthetic SUNCG-RGBD datasets. The code and the supplementary material will be available at \url{https://github.com/yjcaimeow/SISNet}.