 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShotFinder: Imagination-Driven Open-Domain Video Shot Retrieval via Web Search
Jan 30, 2026In recent years, large language models (LLMs) have made rapid progress in information retrieval, yet existing research has mainly focused on text or static multimodal settings. Open-domain video shot retrieval, which involves richer temporal structure and more complex semantics, still lacks systematic benchmarks and analysis. To fill this gap, we introduce ShotFinder, a benchmark that formalizes editing requirements as keyframe-oriented shot descriptions and introduces five types of controllable single-factor constraints: Temporal order, Color, Visual style, Audio, and Resolution. We curate 1,210 high-quality samples from YouTube across 20 thematic categories, using large models for generation with human verification. Based on the benchmark, we propose ShotFinder, a text-driven three-stage retrieval and localization pipeline: (1) query expansion via video imagination, (2) candidate video retrieval with a search engine, and (3) description-guided temporal localization. Experiments on multiple closed-source and open-source models reveal a significant gap to human performance, with clear imbalance across constraints: temporal localization is relatively tractable, while color and visual style remain major challenges. These results reveal that open-domain video shot retrieval is still a critical capability that multimodal large models have yet to overcome.
AgentGC: Evolutionary Learning-based Lossless Compression for Genomics Data with LLM-driven Multiple Agent
Jan 20, 2026Lossless compression has made significant advancements in Genomics Data (GD) storage, sharing and management. Current learning-based methods are non-evolvable with problems of low-level compression modeling, limited adaptability, and user-unfriendly interface. To this end, we propose AgentGC, the first evolutionary Agent-based GD Compressor, consisting of 3 layers with multi-agent named Leader and Worker. Specifically, the 1) User layer provides a user-friendly interface via Leader combined with LLM; 2) Cognitive layer, driven by the Leader, integrates LLM to consider joint optimization of algorithm-dataset-system, addressing the issues of low-level modeling and limited adaptability; and 3) Compression layer, headed by Worker, performs compression & decompression via a automated multi-knowledge learning-based compression framework. On top of AgentGC, we design 3 modes to support diverse scenarios: CP for compression-ratio priority, TP for throughput priority, and BM for balanced mode. Compared with 14 baselines on 9 datasets, the average compression ratios gains are 16.66%, 16.11%, and 16.33%, the throughput gains are 4.73x, 9.23x, and 9.15x, respectively.
LGFN: Lightweight Light Field Image Super-Resolution using Local Convolution Modulation and Global Attention Feature Extraction
Sep 26, 2024



Capturing different intensity and directions of light rays at the same scene Light field (LF) can encode the 3D scene cues into a 4D LF image which has a wide range of applications (i.e. post-capture refocusing and depth sensing). LF image super-resolution (SR) aims to improve the image resolution limited by the performance of LF camera sensor. Although existing methods have achieved promising results the practical application of these models is limited because they are not lightweight enough. In this paper we propose a lightweight model named LGFN which integrates the local and global features of different views and the features of different channels for LF image SR. Specifically owing to neighboring regions of the same pixel position in different sub-aperture images exhibit similar structural relationships we design a lightweight CNN-based feature extraction module (namely DGCE) to extract local features better through feature modulation. Meanwhile as the position beyond the boundaries in the LF image presents a large disparity we propose an efficient spatial attention module (namely ESAM) which uses decomposable large-kernel convolution to obtain an enlarged receptive field and an efficient channel attention module (namely ECAM). Compared with the existing LF image SR models with large parameter our model has a parameter of 0.45M and a FLOPs of 19.33G which has achieved a competitive effect. Extensive experiments with ablation studies demonstrate the effectiveness of our proposed method which ranked the second place in the Track 2 Fidelity & Efficiency of NTIRE2024 Light Field Super Resolution Challenge and the seventh place in the Track 1 Fidelity.
* 10 pages, 5 figures
MECD: Unlocking Multi-Event Causal Discovery in Video Reasoning
Sep 26, 2024



Video causal reasoning aims to achieve a high-level understanding of video content from a causal perspective. However, current video reasoning tasks are limited in scope, primarily executed in a question-answering paradigm and focusing on short videos containing only a single event and simple causal relationships, lacking comprehensive and structured causality analysis for videos with multiple events. To fill this gap, we introduce a new task and dataset, Multi-Event Causal Discovery (MECD). It aims to uncover the causal relationships between events distributed chronologically across long videos. Given visual segments and textual descriptions of events, MECD requires identifying the causal associations between these events to derive a comprehensive, structured event-level video causal diagram explaining why and how the final result event occurred. To address MECD, we devise a novel framework inspired by the Granger Causality method, using an efficient mask-based event prediction model to perform an Event Granger Test, which estimates causality by comparing the predicted result event when premise events are masked versus unmasked. Furthermore, we integrate causal inference techniques such as front-door adjustment and counterfactual inference to address challenges in MECD like causality confounding and illusory causality. Experiments validate the effectiveness of our framework in providing causal relationships in multi-event videos, outperforming GPT-4o and VideoLLaVA by 5.7% and 4.1%, respectively.
DomainVerse: A Benchmark Towards Real-World Distribution Shifts For Tuning-Free Adaptive Domain Generalization
Mar 05, 2024Traditional cross-domain tasks, including domain adaptation and domain generalization, rely heavily on training model by source domain data. With the recent advance of vision-language models (VLMs), viewed as natural source models, the cross-domain task changes to directly adapt the pre-trained source model to arbitrary target domains equipped with prior domain knowledge, and we name this task Adaptive Domain Generalization (ADG). However, current cross-domain datasets have many limitations, such as unrealistic domains, unclear domain definitions, and the inability to fine-grained domain decomposition, which drives us to establish a novel dataset DomainVerse for ADG. Benefiting from the introduced hierarchical definition of domain shifts, DomainVerse consists of about 0.5 million images from 390 fine-grained realistic domains. With the help of the constructed DomainVerse and VLMs, we propose two methods called Domain CLIP and Domain++ CLIP for tuning-free adaptive domain generalization. Extensive and comprehensive experiments demonstrate the significance of the dataset and the effectiveness of the proposed methods.
Collaborative Weakly Supervised Video Correlation Learning for Procedure-Aware Instructional Video Analysis
Dec 18, 2023



Video Correlation Learning (VCL), which aims to analyze the relationships between videos, has been widely studied and applied in various general video tasks. However, applying VCL to instructional videos is still quite challenging due to their intrinsic procedural temporal structure. Specifically, procedural knowledge is critical for accurate correlation analyses on instructional videos. Nevertheless, current procedure-learning methods heavily rely on step-level annotations, which are costly and not scalable. To address this problem, we introduce a weakly supervised framework called Collaborative Procedure Alignment (CPA) for procedure-aware correlation learning on instructional videos. Our framework comprises two core modules: collaborative step mining and frame-to-step alignment. The collaborative step mining module enables simultaneous and consistent step segmentation for paired videos, leveraging the semantic and temporal similarity between frames. Based on the identified steps, the frame-to-step alignment module performs alignment between the frames and steps across videos. The alignment result serves as a measurement of the correlation distance between two videos. We instantiate our framework in two distinct instructional video tasks: sequence verification and action quality assessment. Extensive experiments validate the effectiveness of our approach in providing accurate and interpretable correlation analyses for instructional videos.
DISC-MedLLM: Bridging General Large Language Models and Real-World Medical Consultation
Aug 28, 2023



We propose DISC-MedLLM, a comprehensive solution that leverages Large Language Models (LLMs) to provide accurate and truthful medical response in end-to-end conversational healthcare services. To construct high-quality Supervised Fine-Tuning (SFT) datasets, we employ three strategies: utilizing medical knowledge-graphs, reconstructing real-world dialogues, and incorporating human-guided preference rephrasing. These datasets are instrumental in training DISC-MedLLM, surpassing existing medical LLMs in both single-turn and multi-turn consultation scenarios. Extensive experimental results demonstrate the effectiveness of the proposed model in bridging the gap between general language models and real-world medical consultation. Additionally, we release the constructed dataset and model weights to further contribute to research and development. Further details and resources can be found at https://github.com/FudanDISC/DISC-MedLLM
Learning to Learn Domain-invariant Parameters for Domain Generalization
Nov 04, 2022



Due to domain shift, deep neural networks (DNNs) usually fail to generalize well on unknown test data in practice. Domain generalization (DG) aims to overcome this issue by capturing domain-invariant representations from source domains. Motivated by the insight that only partial parameters of DNNs are optimized to extract domain-invariant representations, we expect a general model that is capable of well perceiving and emphatically updating such domain-invariant parameters. In this paper, we propose two modules of Domain Decoupling and Combination (DDC) and Domain-invariance-guided Backpropagation (DIGB), which can encourage such general model to focus on the parameters that have a unified optimization direction between pairs of contrastive samples. Our extensive experiments on two benchmarks have demonstrated that our proposed method has achieved state-of-the-art performance with strong generalization capability.
Decoupled Pyramid Correlation Network for Liver Tumor Segmentation from CT images
May 26, 2022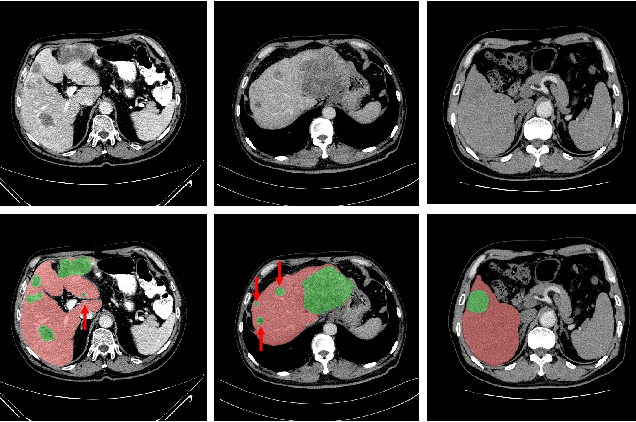
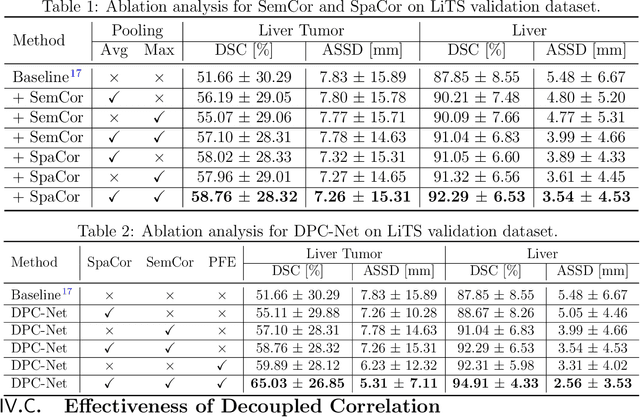
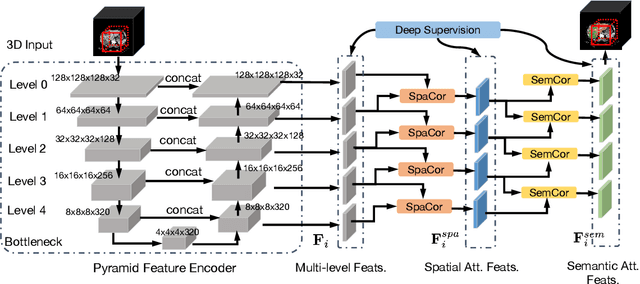
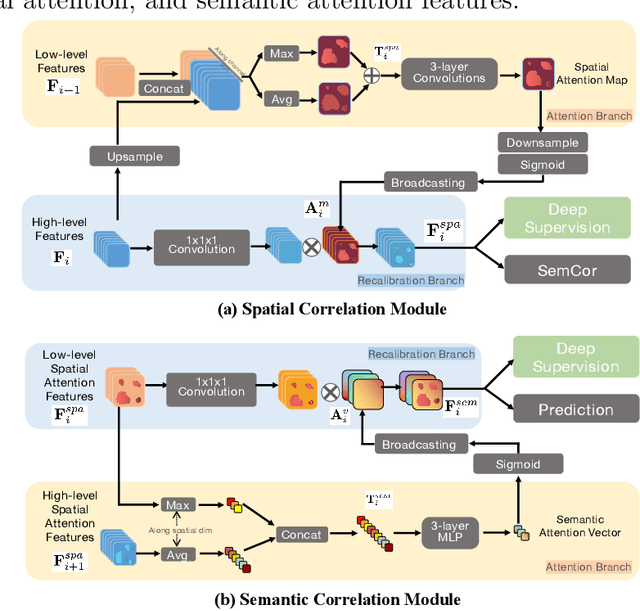
Purpose: Automated liver tumor segmentation from Computed Tomography (CT) images is a necessary prerequisite in the interventions of hepatic abnormalities and surgery planning. However, accurate liver tumor segmentation remains challenging due to the large variability of tumor sizes and inhomogeneous texture. Recent advances based on Fully Convolutional Network (FCN) for medical image segmentation drew on the success of learning discriminative pyramid features. In this paper, we propose a Decoupled Pyramid Correlation Network (DPC-Net) that exploits attention mechanisms to fully leverage both low- and high-level features embedded in FCN to segment liver tumor. Methods: We first design a powerful Pyramid Feature Encoder (PFE) to extract multi-level features from input images. Then we decouple the characteristics of features concerning spatial dimension (i.e., height, width, depth) and semantic dimension (i.e., channel). On top of that, we present two types of attention modules, Spatial Correlation (SpaCor) and Semantic Correlation (SemCor) modules, to recursively measure the correlation of multi-level features. The former selectively emphasizes global semantic information in low-level features with the guidance of high-level ones. The latter adaptively enhance spatial details in high-level features with the guidance of low-level ones. Results: We evaluate the DPC-Net on MICCAI 2017 LiTS Liver Tumor Segmentation (LiTS) challenge dataset. Dice Similarity Coefficient (DSC) and Average Symmetric Surface Distance (ASSD) are employed for evaluation. The proposed method obtains a DSC of 76.4% and an ASSD of 0.838 mm for liver tumor segmentation, outperforming the state-of-the-art methods. It also achieves a competitive results with a DSC of 96.0% and an ASSD of 1.636 mm for liver segmentation.
DxFormer: A Decoupled Automatic Diagnostic System Based on Decoder-Encoder Transformer with Dense Symptom Representations
May 08, 2022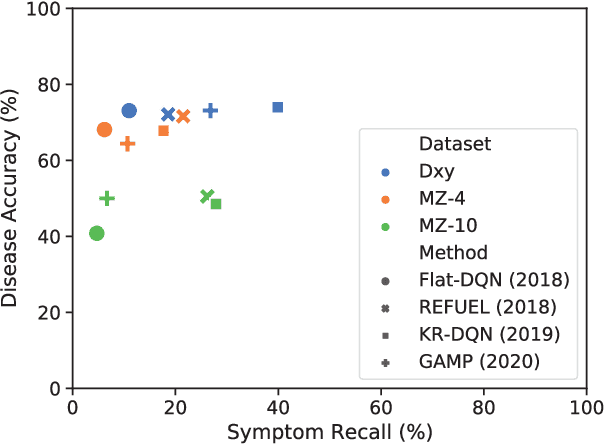
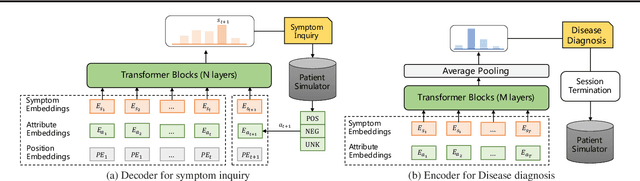

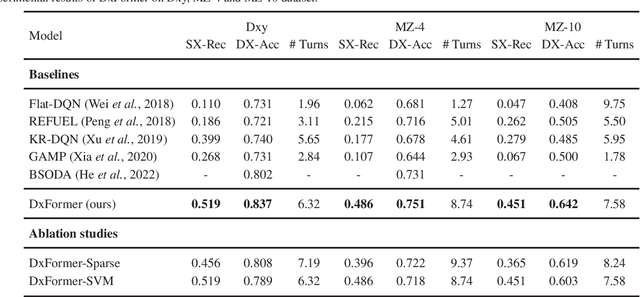
Diagnosis-oriented dialogue system queries the patient's health condition and makes predictions about possible diseases through continuous interaction with the patient. A few studies use reinforcement learning (RL) to learn the optimal policy from the joint action space of symptoms and diseases. However, existing RL (or Non-RL) methods cannot achieve sufficiently good prediction accuracy, still far from its upper limit. To address the problem, we propose a decoupled automatic diagnostic framework DxFormer, which divides the diagnosis process into two steps: symptom inquiry and disease diagnosis, where the transition from symptom inquiry to disease diagnosis is explicitly determined by the stopping criteria. In DxFormer, we treat each symptom as a token, and formalize the symptom inquiry and disease diagnosis to a language generation model and a sequence classification model respectively. We use the inverted version of Transformer, i.e., the decoder-encoder structure, to learn the representation of symptoms by jointly optimizing the reinforce reward and cross entropy loss. Extensive experiments on three public real-world datasets prove that our proposed model can effectively learn doctors' clinical experience and achieve the state-of-the-art results in terms of symptom recall and diagnostic accuracy.