 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Saliency detection based on structural dissimilarity induced by image quality assessment model
May 24, 2019
The distinctiveness of image regions is widely used as the cue of saliency. Generally, the distinctiveness is computed according to the absolute difference of features. However, according to the image quality assessment (IQA) studies, the human visual system is highly sensitive to structural changes rather than absolute difference. Accordingly, we propose the computation of the structural dissimilarity between image patches as the distinctiveness measure for saliency detection. Similar to IQA models, the structural dissimilarity is computed based on the correlation of the structural features. The global structural dissimilarity of a patch to all the other patches represents saliency of the patch. We adopt two widely used structural features, namely the local contrast and gradient magnitude, into the structural dissimilarity computation in the proposed model. Without any postprocessing, the proposed model based on the correlation of either of the two structural features outperforms 11 state-of-the-art saliency models on three saliency databases.
* For associated source code, see https://github.com/yangli-xjtu/SDS
MeanShift++: Extremely Fast Mode-Seeking With Applications to Segmentation and Object Tracking
Apr 01, 2021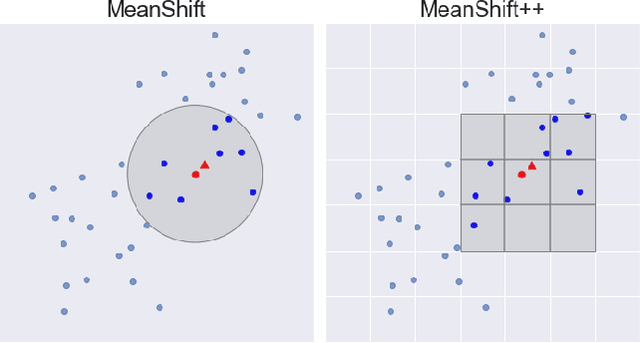
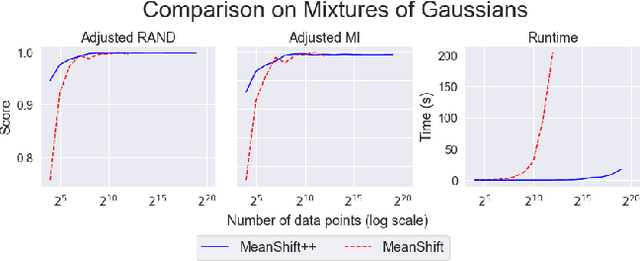
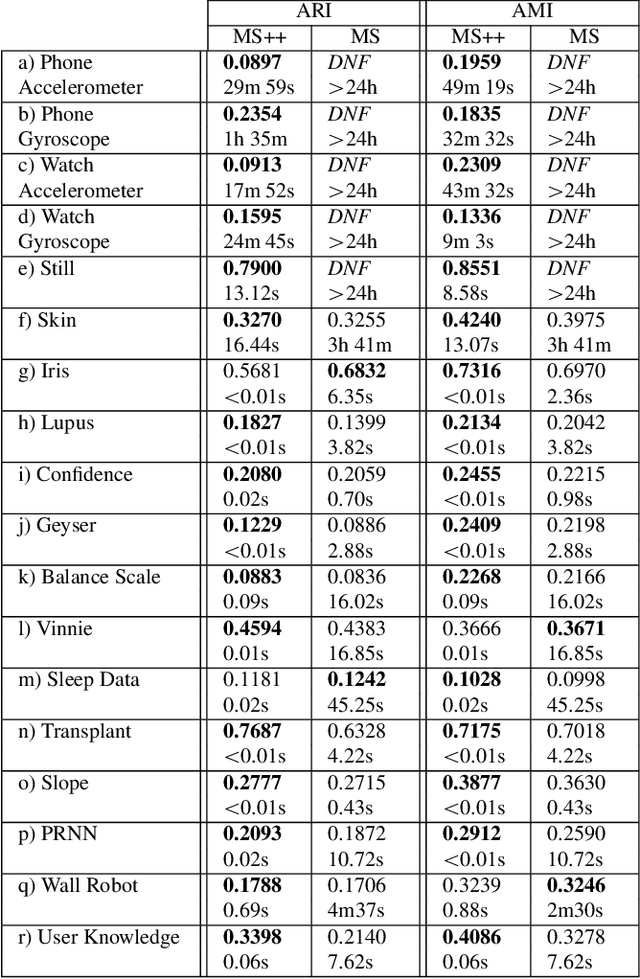
MeanShift is a popular mode-seeking clustering algorithm used in a wide range of applications in machine learning. However, it is known to be prohibitively slow, with quadratic runtime per iteration. We propose MeanShift++, an extremely fast mode-seeking algorithm based on MeanShift that uses a grid-based approach to speed up the mean shift step, replacing the computationally expensive neighbors search with a density-weighted mean of adjacent grid cells. In addition, we show that this grid-based technique for density estimation comes with theoretical guarantees. The runtime is linear in the number of points and exponential in dimension, which makes MeanShift++ ideal on low-dimensional applications such as image segmentation and object tracking. We provide extensive experimental analysis showing that MeanShift++ can be more than 10,000x faster than MeanShift with competitive clustering results on benchmark datasets and nearly identical image segmentations as MeanShift. Finally, we show promising results for object tracking.
Multi-Instance Multi-Scale CNN for Medical Image Classification
Jul 18, 2019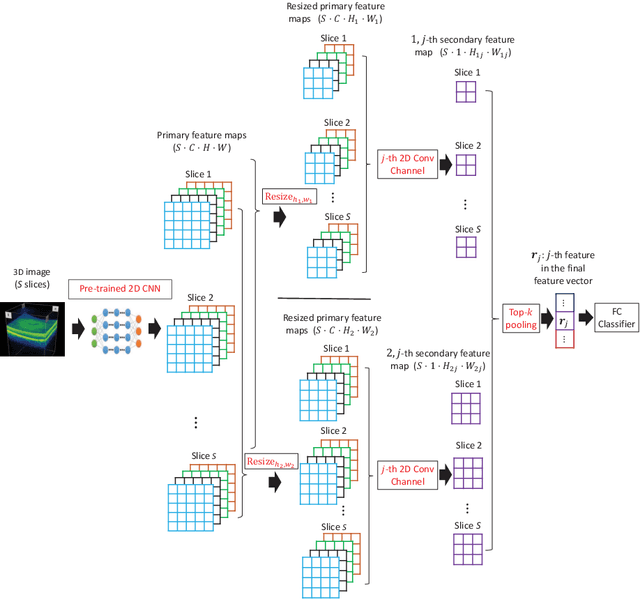
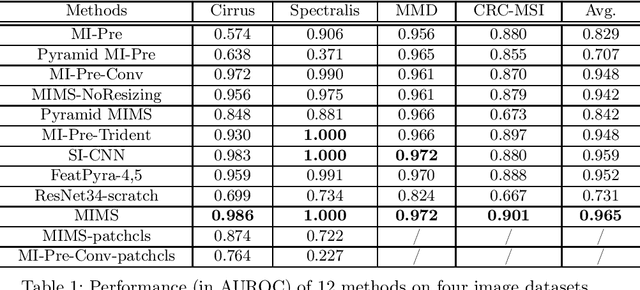
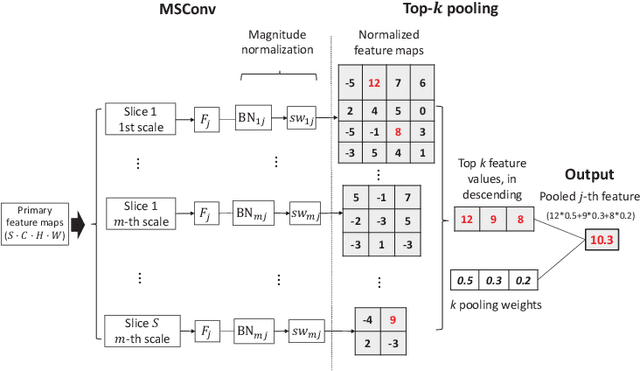

Deep learning for medical image classification faces three major challenges: 1) the number of annotated medical images for training are usually small; 2) regions of interest (ROIs) are relatively small with unclear boundaries in the whole medical images, and may appear in arbitrary positions across the x,y (and also z in 3D images) dimensions. However often only labels of the whole images are annotated, and localized ROIs are unavailable; and 3) ROIs in medical images often appear in varying sizes (scales). We approach these three challenges with a Multi-Instance Multi-Scale (MIMS) CNN: 1) We propose a multi-scale convolutional layer, which extracts patterns of different receptive fields with a shared set of convolutional kernels, so that scale-invariant patterns are captured by this compact set of kernels. As this layer contains only a small number of parameters, training on small datasets becomes feasible; 2) We propose a "top-k pooling" to aggregate the feature maps in varying scales from multiple spatial dimensions, allowing the model to be trained using weak annotations within the multiple instance learning (MIL) framework. Our method is shown to perform well on three classification tasks involving two 3D and two 2D medical image datasets.
SCNet: Enhancing Few-Shot Semantic Segmentation by Self-Contrastive Background Prototypes
Apr 19, 2021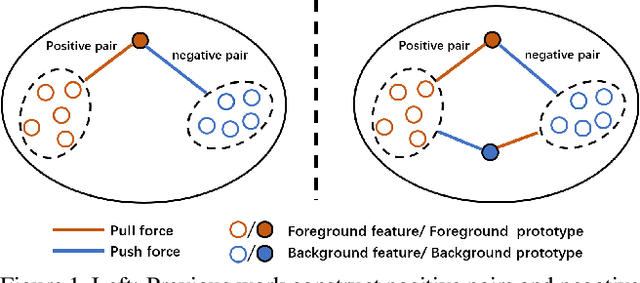
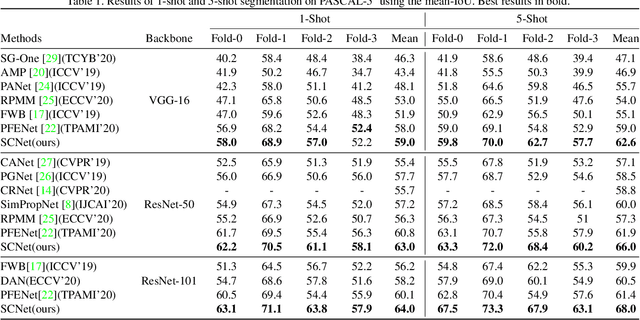
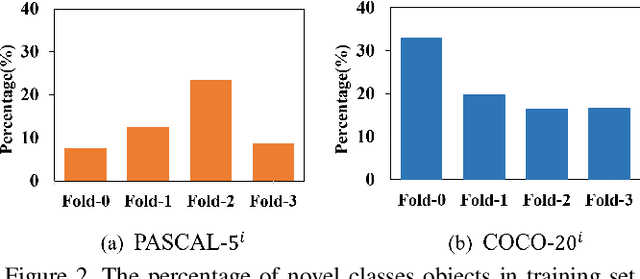
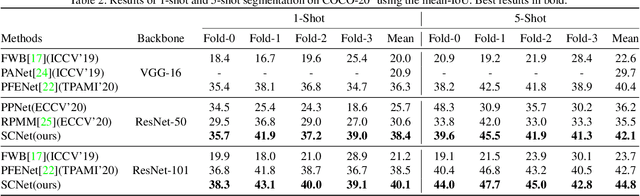
Few-shot semantic segmentation aims to segment novel-class objects in a query image with only a few annotated examples in support images. Most of advanced solutions exploit a metric learning framework that performs segmentation through matching each pixel to a learned foreground prototype. However, this framework suffers from biased classification due to incomplete construction of sample pairs with the foreground prototype only. To address this issue, in this paper, we introduce a complementary self-contrastive task into few-shot semantic segmentation. Our new model is able to associate the pixels in a region with the prototype of this region, no matter they are in the foreground or background. To this end, we generate self-contrastive background prototypes directly from the query image, with which we enable the construction of complete sample pairs and thus a complementary and auxiliary segmentation task to achieve the training of a better segmentation model. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ demonstrate clearly the superiority of our proposal. At no expense of inference efficiency, our model achieves state-of-the results in both 1-shot and 5-shot settings for few-shot semantic segmentation.
Poisoning the Search Space in Neural Architecture Search
Jun 28, 2021
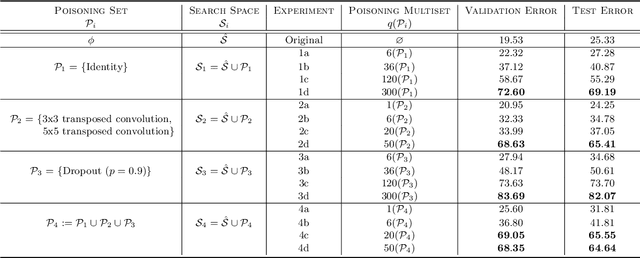

Deep learning has proven to be a highly effective problem-solving tool for object detection and image segmentation across various domains such as healthcare and autonomous driving. At the heart of this performance lies neural architecture design which relies heavily on domain knowledge and prior experience on the researchers' behalf. More recently, this process of finding the most optimal architectures, given an initial search space of possible operations, was automated by Neural Architecture Search (NAS). In this paper, we evaluate the robustness of one such algorithm known as Efficient NAS (ENAS) against data agnostic poisoning attacks on the original search space with carefully designed ineffective operations. By evaluating algorithm performance on the CIFAR-10 dataset, we empirically demonstrate how our novel search space poisoning (SSP) approach and multiple-instance poisoning attacks exploit design flaws in the ENAS controller to result in inflated prediction error rates for child networks. Our results provide insights into the challenges to surmount in using NAS for more adversarially robust architecture search.
Improved Acyclicity Reasoning for Bayesian Network Structure Learning with Constraint Programming
Jun 23, 2021
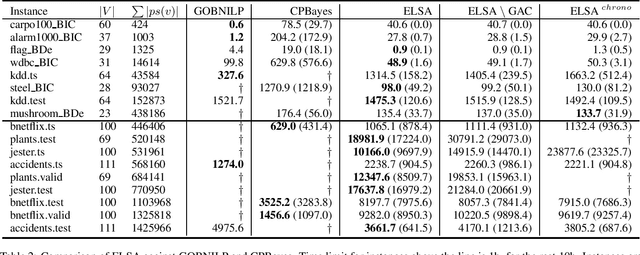
Bayesian networks are probabilistic graphical models with a wide range of application areas including gene regulatory networks inference, risk analysis and image processing. Learning the structure of a Bayesian network (BNSL) from discrete data is known to be an NP-hard task with a superexponential search space of directed acyclic graphs. In this work, we propose a new polynomial time algorithm for discovering a subset of all possible cluster cuts, a greedy algorithm for approximately solving the resulting linear program, and a generalised arc consistency algorithm for the acyclicity constraint. We embed these in the constraint programmingbased branch-and-bound solver CPBayes and show that, despite being suboptimal, they improve performance by orders of magnitude. The resulting solver also compares favourably with GOBNILP, a state-of-the-art solver for the BNSL problem which solves an NP-hard problem to discover each cut and solves the linear program exactly.
Rail-5k: a Real-World Dataset for Rail Surface Defects Detection
Jun 28, 2021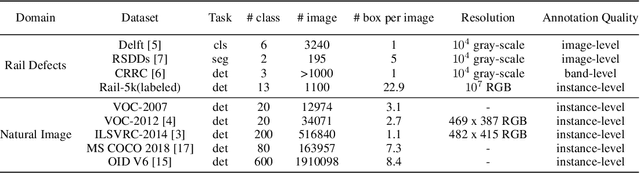
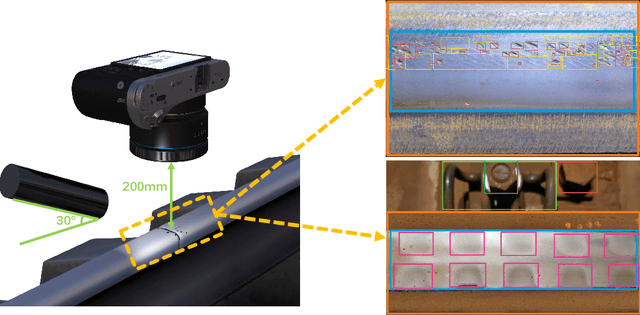
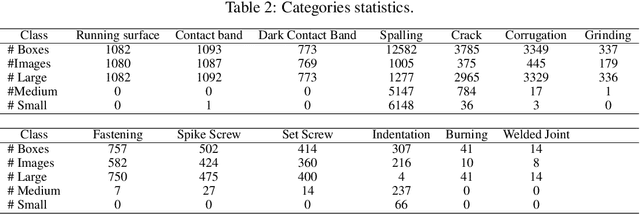
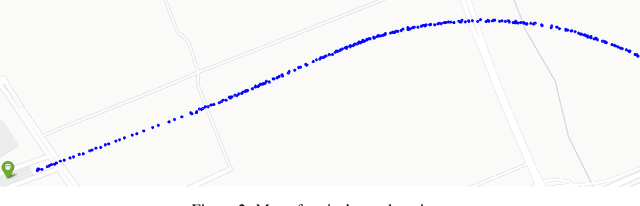
This paper presents the Rail-5k dataset for benchmarking the performance of visual algorithms in a real-world application scenario, namely the rail surface defects detection task. We collected over 5k high-quality images from railways across China, and annotated 1100 images with the help from railway experts to identify the most common 13 types of rail defects. The dataset can be used for two settings both with unique challenges, the first is the fully-supervised setting using the 1k+ labeled images for training, fine-grained nature and long-tailed distribution of defect classes makes it hard for visual algorithms to tackle. The second is the semi-supervised learning setting facilitated by the 4k unlabeled images, these 4k images are uncurated containing possible image corruptions and domain shift with the labeled images, which can not be easily tackle by previous semi-supervised learning methods. We believe our dataset could be a valuable benchmark for evaluating robustness and reliability of visual algorithms.
Cross-modality Discrepant Interaction Network for RGB-D Salient Object Detection
Aug 04, 2021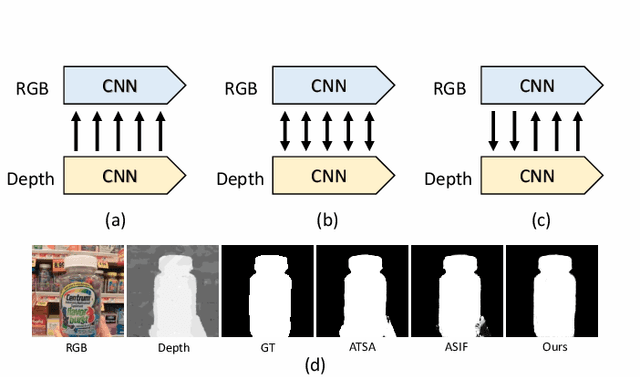
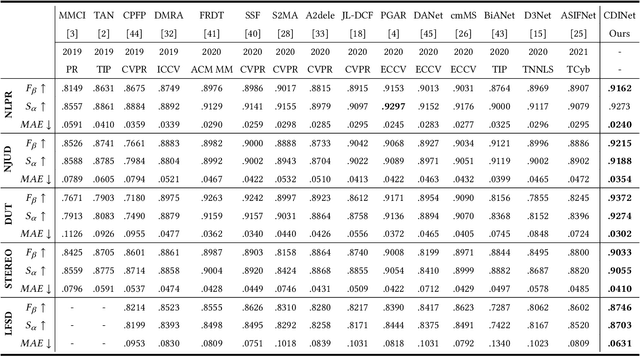
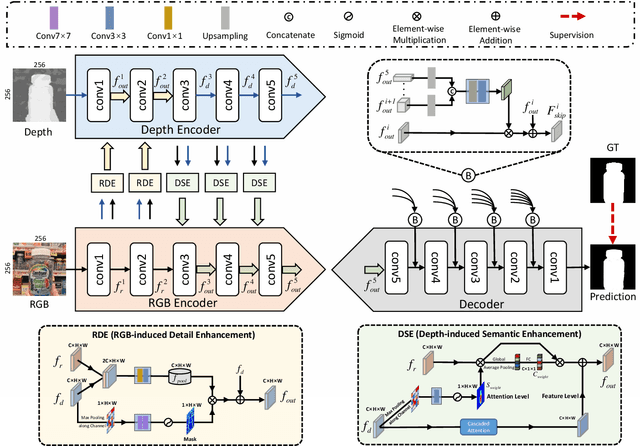
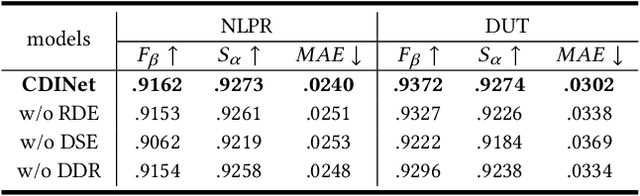
The popularity and promotion of depth maps have brought new vigor and vitality into salient object detection (SOD), and a mass of RGB-D SOD algorithms have been proposed, mainly concentrating on how to better integrate cross-modality features from RGB image and depth map. For the cross-modality interaction in feature encoder, existing methods either indiscriminately treat RGB and depth modalities, or only habitually utilize depth cues as auxiliary information of the RGB branch. Different from them, we reconsider the status of two modalities and propose a novel Cross-modality Discrepant Interaction Network (CDINet) for RGB-D SOD, which differentially models the dependence of two modalities according to the feature representations of different layers. To this end, two components are designed to implement the effective cross-modality interaction: 1) the RGB-induced Detail Enhancement (RDE) module leverages RGB modality to enhance the details of the depth features in low-level encoder stage. 2) the Depth-induced Semantic Enhancement (DSE) module transfers the object positioning and internal consistency of depth features to the RGB branch in high-level encoder stage. Furthermore, we also design a Dense Decoding Reconstruction (DDR) structure, which constructs a semantic block by combining multi-level encoder features to upgrade the skip connection in the feature decoding. Extensive experiments on five benchmark datasets demonstrate that our network outperforms $15$ state-of-the-art methods both quantitatively and qualitatively. Our code is publicly available at: https://rmcong.github.io/proj_CDINet.html.
Document-level Relation Extraction as Semantic Segmentation
Jun 07, 2021
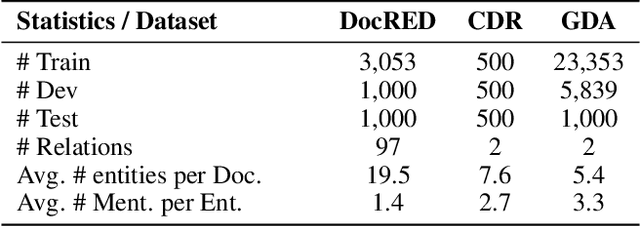
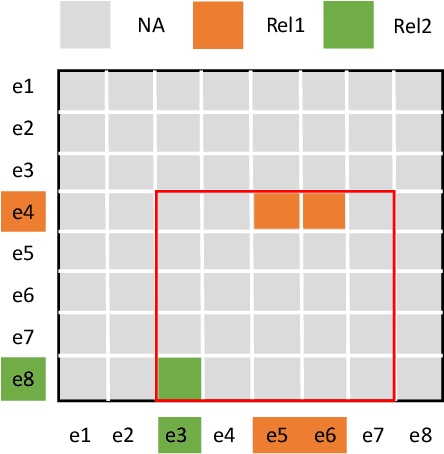
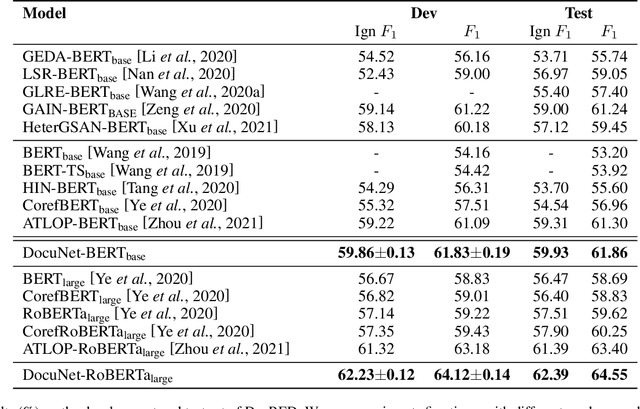
Document-level relation extraction aims to extract relations among multiple entity pairs from a document. Previously proposed graph-based or transformer-based models utilize the entities independently, regardless of global information among relational triples. This paper approaches the problem by predicting an entity-level relation matrix to capture local and global information, parallel to the semantic segmentation task in computer vision. Herein, we propose a Document U-shaped Network for document-level relation extraction. Specifically, we leverage an encoder module to capture the context information of entities and a U-shaped segmentation module over the image-style feature map to capture global interdependency among triples. Experimental results show that our approach can obtain state-of-the-art performance on three benchmark datasets DocRED, CDR, and GDA.
More unlabelled data or label more data? A study on semi-supervised laparoscopic image segmentation
Aug 20, 2019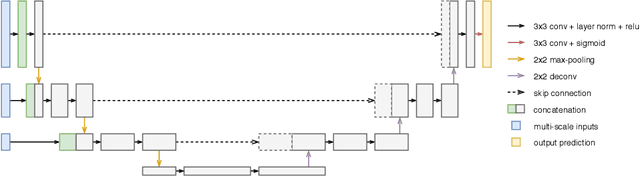
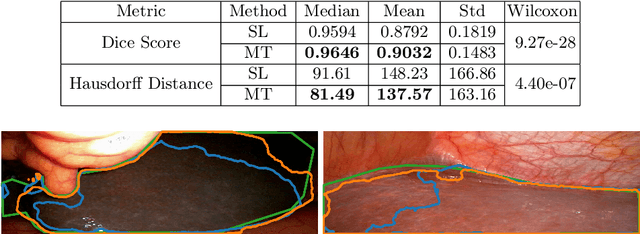
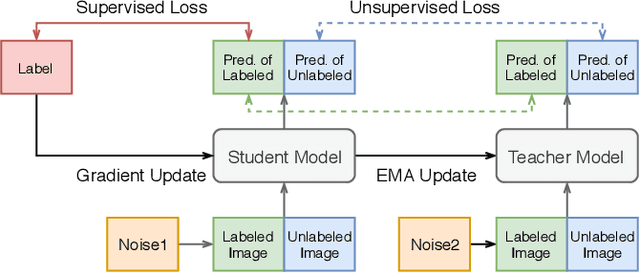
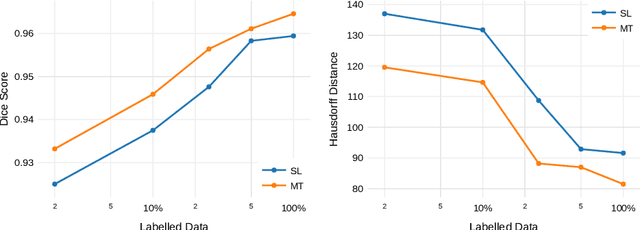
Improving a semi-supervised image segmentation task has the option of adding more unlabelled images, labelling the unlabelled images or combining both, as neither image acquisition nor expert labelling can be considered trivial in most clinical applications. With a laparoscopic liver image segmentation application, we investigate the performance impact by altering the quantities of labelled and unlabelled training data, using a semi-supervised segmentation algorithm based on the mean teacher learning paradigm. We first report a significantly higher segmentation accuracy, compared with supervised learning. Interestingly, this comparison reveals that the training strategy adopted in the semi-supervised algorithm is also responsible for this observed improvement, in addition to the added unlabelled data. We then compare different combinations of labelled and unlabelled data set sizes for training semi-supervised segmentation networks, to provide a quantitative example of the practically useful trade-off between the two data planning strategies in this surgical guidance application.