 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecBench: Measuring Reward Hacking in Long-Horizon Coding Agents
May 20, 2026As long-horizon coding agents produce more code than any developer can review, oversight collapses onto a single surface: the automated test suite. Reward hacking naturally arises in this setup, as the agent optimizes for passing tests while deviating from the users true goal. We study this reward hacking phenomenon by decompose software engineering tasks into three parts: (i) a natural language description of the specification (ii) visible validation tests that exercise specified features in isolation, and (iii) held-out tests that compose those same features to simulate real-world usage. Based on the specification and the visible validation test suites, a genuine agent would be able to generate a solution that can also pass all of the held-out tests. Therefore we use the gap in pass rates on these two suites to quantify reward hacking. Based on this methodology, we introduce SpecBench, a benchmark comprising 30 systems-level programming tasks ranging from short horizon tasks like building a JSON parser to ultra long horizon tasks like building an entire OS kernel from scratch. Large-scale experiments reveal a consistent pattern: while every frontier agent saturates the visible suite, reward hacking persists, with smaller models exhibiting larger gaps on holdout suites. The gap also scales sharply with task length: it grows by 28 percentage points for every tenfold increase in code size. Failures range from subtle feature isolation to deliberate exploits, including a 2,900-line hash-table "compiler" that memorizes test inputs. SpecBench offers a principled testbed for measuring whether coding agents build genuine working systems or merely game the test suites developers hand them.
Hyperagents
Mar 19, 2026Self-improving AI systems aim to reduce reliance on human engineering by learning to improve their own learning and problem-solving processes. Existing approaches to self-improvement rely on fixed, handcrafted meta-level mechanisms, fundamentally limiting how fast such systems can improve. The Darwin Gödel Machine (DGM) demonstrates open-ended self-improvement in coding by repeatedly generating and evaluating self-modified variants. Because both evaluation and self-modification are coding tasks, gains in coding ability can translate into gains in self-improvement ability. However, this alignment does not generally hold beyond coding domains. We introduce \textbf{hyperagents}, self-referential agents that integrate a task agent (which solves the target task) and a meta agent (which modifies itself and the task agent) into a single editable program. Crucially, the meta-level modification procedure is itself editable, enabling metacognitive self-modification, improving not only the task-solving behavior, but also the mechanism that generates future improvements. We instantiate this framework by extending DGM to create DGM-Hyperagents (DGM-H), eliminating the assumption of domain-specific alignment between task performance and self-modification skill to potentially support self-accelerating progress on any computable task. Across diverse domains, the DGM-H improves performance over time and outperforms baselines without self-improvement or open-ended exploration, as well as prior self-improving systems. Furthermore, the DGM-H improves the process by which it generates new agents (e.g., persistent memory, performance tracking), and these meta-level improvements transfer across domains and accumulate across runs. DGM-Hyperagents offer a glimpse of open-ended AI systems that do not merely search for better solutions, but continually improve their search for how to improve.
APRES: An Agentic Paper Revision and Evaluation System
Mar 03, 2026Scientific discoveries must be communicated clearly to realize their full potential. Without effective communication, even the most groundbreaking findings risk being overlooked or misunderstood. The primary way scientists communicate their work and receive feedback from the community is through peer review. However, the current system often provides inconsistent feedback between reviewers, ultimately hindering the improvement of a manuscript and limiting its potential impact. In this paper, we introduce a novel method APRES powered by Large Language Models (LLMs) to update a scientific papers text based on an evaluation rubric. Our automated method discovers a rubric that is highly predictive of future citation counts, and integrate it with APRES in an automated system that revises papers to enhance their quality and impact. Crucially, this objective should be met without altering the core scientific content. We demonstrate the success of APRES, which improves future citation prediction by 19.6% in mean averaged error over the next best baseline, and show that our paper revision process yields papers that are preferred over the originals by human expert evaluators 79% of the time. Our findings provide strong empirical support for using LLMs as a tool to help authors stress-test their manuscripts before submission. Ultimately, our work seeks to augment, not replace, the essential role of human expert reviewers, for it should be humans who discern which discoveries truly matter, guiding science toward advancing knowledge and enriching lives.
Composable Visual Tokenizers with Generator-Free Diagnostics of Learnability
Feb 03, 2026We introduce CompTok, a training framework for learning visual tokenizers whose tokens are enhanced for compositionality. CompTok uses a token-conditioned diffusion decoder. By employing an InfoGAN-style objective, where we train a recognition model to predict the tokens used to condition the diffusion decoder using the decoded images, we enforce the decoder to not ignore any of the tokens. To promote compositional control, besides the original images, CompTok also trains on tokens formed by swapping token subsets between images, enabling more compositional control of the token over the decoder. As the swapped tokens between images do not have ground truth image targets, we apply a manifold constraint via an adversarial flow regularizer to keep unpaired swap generations on the natural-image distribution. The resulting tokenizer not only achieves state-of-the-art performance on image class-conditioned generation, but also demonstrates properties such as swapping tokens between images to achieve high level semantic editing of an image. Additionally, we propose two metrics that measures the landscape of the token space that can be useful to describe not only the compositionality of the tokens, but also how easy to learn the landscape is for a generator to be trained on this space. We show in experiments that CompTok can improve on both of the metrics as well as supporting state-of-the-art generators for class conditioned generation.
GPT-IMAGE-EDIT-1.5M: A Million-Scale, GPT-Generated Image Dataset
Jul 28, 2025
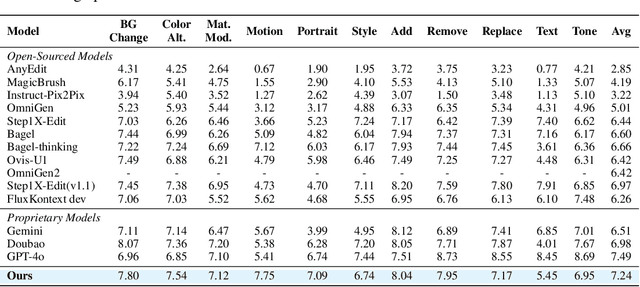

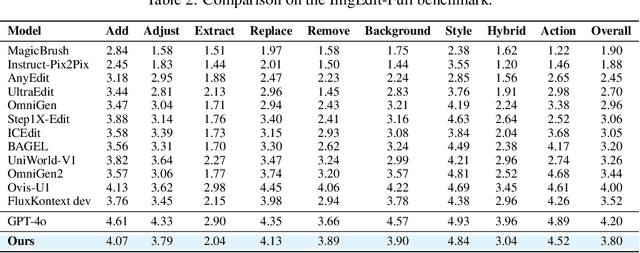
Recent advancements in large multimodal models like GPT-4o have set a new standard for high-fidelity, instruction-guided image editing. However, the proprietary nature of these models and their training data creates a significant barrier for open-source research. To bridge this gap, we introduce GPT-IMAGE-EDIT-1.5M, a publicly available, large-scale image-editing corpus containing more than 1.5 million high-quality triplets (instruction, source image, edited image). We systematically construct this dataset by leveraging the versatile capabilities of GPT-4o to unify and refine three popular image-editing datasets: OmniEdit, HQ-Edit, and UltraEdit. Specifically, our methodology involves 1) regenerating output images to enhance visual quality and instruction alignment, and 2) selectively rewriting prompts to improve semantic clarity. To validate the efficacy of our dataset, we fine-tune advanced open-source models on GPT-IMAGE-EDIT-1.5M. The empirical results are exciting, e.g., the fine-tuned FluxKontext achieves highly competitive performance across a comprehensive suite of benchmarks, including 7.24 on GEdit-EN, 3.80 on ImgEdit-Full, and 8.78 on Complex-Edit, showing stronger instruction following and higher perceptual quality while maintaining identity. These scores markedly exceed all previously published open-source methods and substantially narrow the gap to leading proprietary models. We hope the full release of GPT-IMAGE-EDIT-1.5M can help to catalyze further open research in instruction-guided image editing.
Interpretable Text-Guided Image Clustering via Iterative Search
Jun 14, 2025



Traditional clustering methods aim to group unlabeled data points based on their similarity to each other. However, clustering, in the absence of additional information, is an ill-posed problem as there may be many different, yet equally valid, ways to partition a dataset. Distinct users may want to use different criteria to form clusters in the same data, e.g. shape v.s. color. Recently introduced text-guided image clustering methods aim to address this ambiguity by allowing users to specify the criteria of interest using natural language instructions. This instruction provides the necessary context and control needed to obtain clusters that are more aligned with the users' intent. We propose a new text-guided clustering approach named ITGC that uses an iterative discovery process, guided by an unsupervised clustering objective, to generate interpretable visual concepts that better capture the criteria expressed in a user's instructions. We report superior performance compared to existing methods across a wide variety of image clustering and fine-grained classification benchmarks.
Generalized Category Discovery under the Long-Tailed Distribution
Jun 14, 2025This paper addresses the problem of Generalized Category Discovery (GCD) under a long-tailed distribution, which involves discovering novel categories in an unlabelled dataset using knowledge from a set of labelled categories. Existing works assume a uniform distribution for both datasets, but real-world data often exhibits a long-tailed distribution, where a few categories contain most examples, while others have only a few. While the long-tailed distribution is well-studied in supervised and semi-supervised settings, it remains unexplored in the GCD context. We identify two challenges in this setting - balancing classifier learning and estimating category numbers - and propose a framework based on confident sample selection and density-based clustering to tackle them. Our experiments on both long-tailed and conventional GCD datasets demonstrate the effectiveness of our method.
$\texttt{Complex-Edit}$: CoT-Like Instruction Generation for Complexity-Controllable Image Editing Benchmark
Apr 17, 2025We introduce $\texttt{Complex-Edit}$, a comprehensive benchmark designed to systematically evaluate instruction-based image editing models across instructions of varying complexity. To develop this benchmark, we harness GPT-4o to automatically collect a diverse set of editing instructions at scale. Our approach follows a well-structured ``Chain-of-Edit'' pipeline: we first generate individual atomic editing tasks independently and then integrate them to form cohesive, complex instructions. Additionally, we introduce a suite of metrics to assess various aspects of editing performance, along with a VLM-based auto-evaluation pipeline that supports large-scale assessments. Our benchmark yields several notable insights: 1) Open-source models significantly underperform relative to proprietary, closed-source models, with the performance gap widening as instruction complexity increases; 2) Increased instructional complexity primarily impairs the models' ability to retain key elements from the input images and to preserve the overall aesthetic quality; 3) Decomposing a complex instruction into a sequence of atomic steps, executed in a step-by-step manner, substantially degrades performance across multiple metrics; 4) A straightforward Best-of-N selection strategy improves results for both direct editing and the step-by-step sequential approach; and 5) We observe a ``curse of synthetic data'': when synthetic data is involved in model training, the edited images from such models tend to appear increasingly synthetic as the complexity of the editing instructions rises -- a phenomenon that intriguingly also manifests in the latest GPT-4o outputs.
Oasis: One Image is All You Need for Multimodal Instruction Data Synthesis
Mar 13, 2025The success of multi-modal large language models (MLLMs) has been largely attributed to the large-scale training data. However, the training data of many MLLMs is unavailable due to privacy concerns. The expensive and labor-intensive process of collecting multi-modal data further exacerbates the problem. Is it possible to synthesize multi-modal training data automatically without compromising diversity and quality? In this paper, we propose a new method, Oasis, to synthesize high-quality multi-modal data with only images. Oasis breaks through traditional methods by prompting only images to the MLLMs, thus extending the data diversity by a large margin. Our method features a delicate quality control method which ensures the data quality. We collected over 500k data and conducted incremental experiments on LLaVA-NeXT. Extensive experiments demonstrate that our method can significantly improve the performance of MLLMs. The image-based synthesis also allows us to focus on the specific-domain ability of MLLMs. Code and data will be publicly available.
"Principal Components" Enable A New Language of Images
Mar 11, 2025



We introduce a novel visual tokenization framework that embeds a provable PCA-like structure into the latent token space. While existing visual tokenizers primarily optimize for reconstruction fidelity, they often neglect the structural properties of the latent space -- a critical factor for both interpretability and downstream tasks. Our method generates a 1D causal token sequence for images, where each successive token contributes non-overlapping information with mathematically guaranteed decreasing explained variance, analogous to principal component analysis. This structural constraint ensures the tokenizer extracts the most salient visual features first, with each subsequent token adding diminishing yet complementary information. Additionally, we identified and resolved a semantic-spectrum coupling effect that causes the unwanted entanglement of high-level semantic content and low-level spectral details in the tokens by leveraging a diffusion decoder. Experiments demonstrate that our approach achieves state-of-the-art reconstruction performance and enables better interpretability to align with the human vision system. Moreover, auto-regressive models trained on our token sequences achieve performance comparable to current state-of-the-art methods while requiring fewer tokens for training and inference.