 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Facial Landmark Points Detection Using Knowledge Distillation-Based Neural Networks
Nov 13, 2021
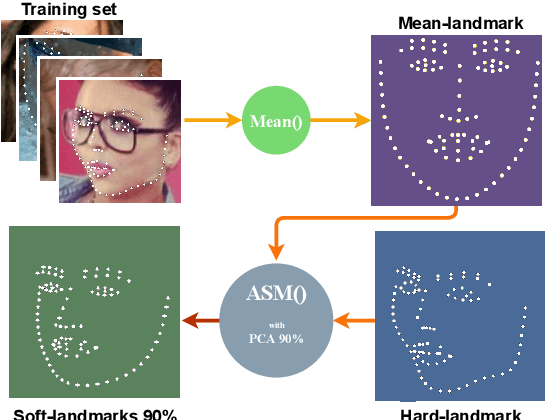
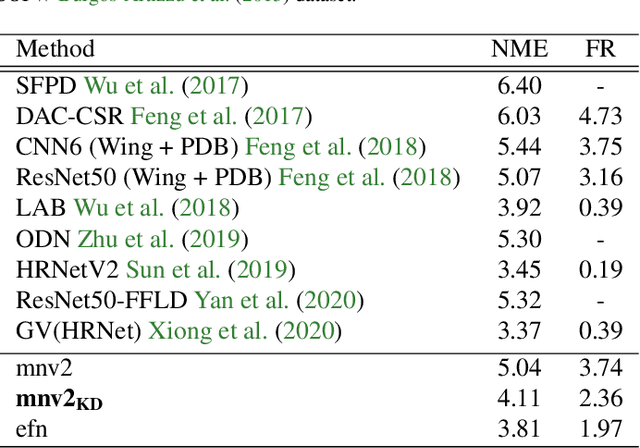

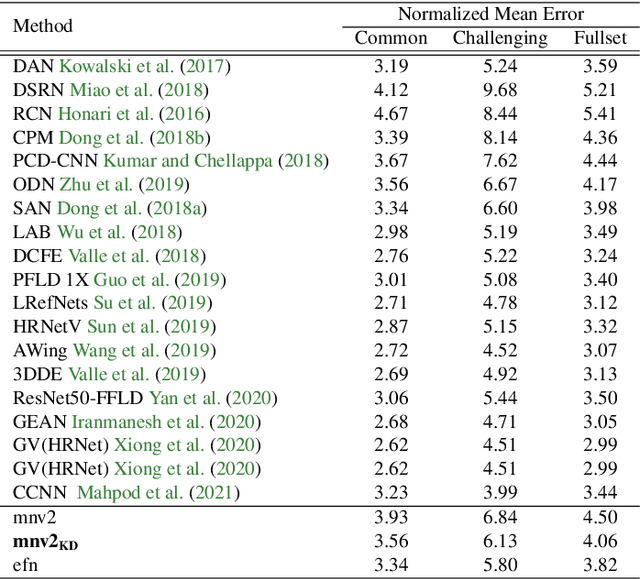
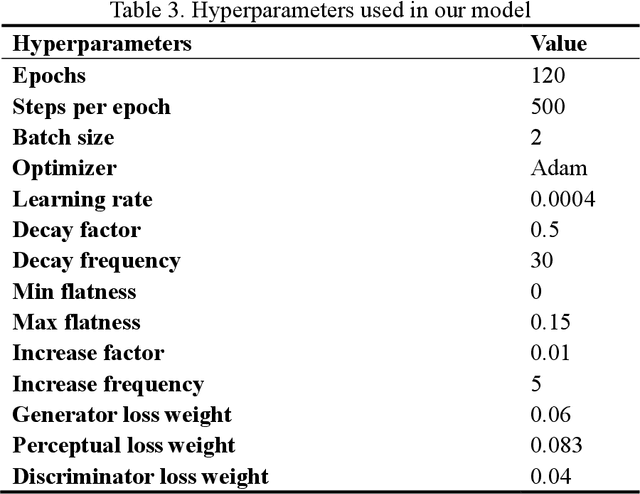
Facial landmark detection is a vital step for numerous facial image analysis applications. Although some deep learning-based methods have achieved good performances in this task, they are often not suitable for running on mobile devices. Such methods rely on networks with many parameters, which makes the training and inference time-consuming. Training lightweight neural networks such as MobileNets are often challenging, and the models might have low accuracy. Inspired by knowledge distillation (KD), this paper presents a novel loss function to train a lightweight Student network (e.g., MobileNetV2) for facial landmark detection. We use two Teacher networks, a Tolerant-Teacher and a Tough-Teacher in conjunction with the Student network. The Tolerant-Teacher is trained using Soft-landmarks created by active shape models, while the Tough-Teacher is trained using the ground truth (aka Hard-landmarks) landmark points. To utilize the facial landmark points predicted by the Teacher networks, we define an Assistive Loss (ALoss) for each Teacher network. Moreover, we define a loss function called KD-Loss that utilizes the facial landmark points predicted by the two pre-trained Teacher networks (EfficientNet-b3) to guide the lightweight Student network towards predicting the Hard-landmarks. Our experimental results on three challenging facial datasets show that the proposed architecture will result in a better-trained Student network that can extract facial landmark points with high accuracy.
Multi-scale super-resolution generation of low-resolution scanned pathological images
May 15, 2021

Digital pathology slide is easy to store and manage, convenient to browse and transmit. However, because of the high-resolution scan for example 40 times magnification(40X) during the digitization, the file size of each whole slide image exceeds 1Gigabyte, which eventually leads to huge storage capacity and very slow network transmission. We design a strategy to scan slides with low resolution (5X) and a super-resolution method is proposed to restore the image details when in diagnosis. The method is based on a multi-scale generative adversarial network, which sequentially generate three high-resolution images such as 10X, 20X and 40X. The perceived loss, generator loss of the generated images and real images are compared on three image resolutions, and a discriminator is used to evaluate the difference of highest-resolution generated image and real image. A dataset consisting of 100,000 pathological images from 10 types of human tissues is performed for training and testing the network. The generated images have high peak-signal-to-noise-ratio (PSNR) and structural-similarity-index (SSIM). The PSNR of 10X to 40X image are 24.16, 22.27 and 20.44, and the SSIM are 0.845, 0.680 and 0.512, which are better than other super-resolution networks such as DBPN, ESPCN, RDN, EDSR and MDSR. Moreover, visual inspections show that the generated high-resolution images by our network have enough details for diagnosis, good color reproduction and close to real images, while other five networks are severely blurred, local deformation or miss important details. Moreover, no significant differences can be found on pathological diagnosis based on the generated and real images. The proposed multi-scale network can generate good high-resolution pathological images, and will provide a low-cost storage (about 15MB/image on 5X), faster image sharing method for digital pathology.
Modeling Temporal Concept Receptive Field Dynamically for Untrimmed Video Analysis
Nov 23, 2021
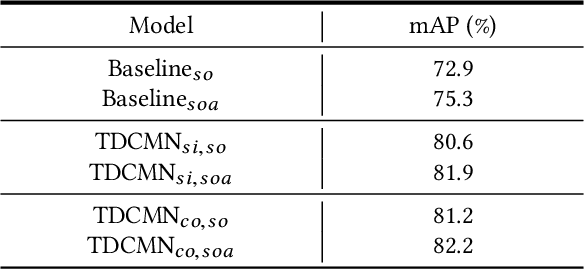
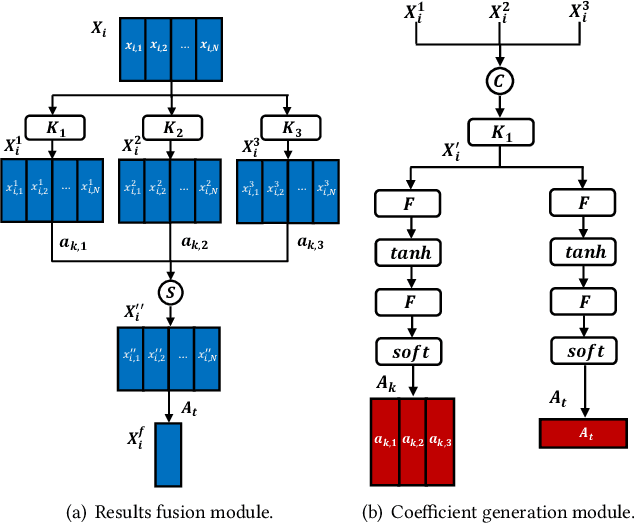
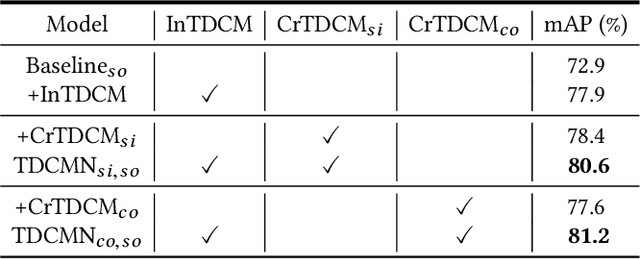
Event analysis in untrimmed videos has attracted increasing attention due to the application of cutting-edge techniques such as CNN. As a well studied property for CNN-based models, the receptive field is a measurement for measuring the spatial range covered by a single feature response, which is crucial in improving the image categorization accuracy. In video domain, video event semantics are actually described by complex interaction among different concepts, while their behaviors vary drastically from one video to another, leading to the difficulty in concept-based analytics for accurate event categorization. To model the concept behavior, we study temporal concept receptive field of concept-based event representation, which encodes the temporal occurrence pattern of different mid-level concepts. Accordingly, we introduce temporal dynamic convolution (TDC) to give stronger flexibility to concept-based event analytics. TDC can adjust the temporal concept receptive field size dynamically according to different inputs. Notably, a set of coefficients are learned to fuse the results of multiple convolutions with different kernel widths that provide various temporal concept receptive field sizes. Different coefficients can generate appropriate and accurate temporal concept receptive field size according to input videos and highlight crucial concepts. Based on TDC, we propose the temporal dynamic concept modeling network (TDCMN) to learn an accurate and complete concept representation for efficient untrimmed video analysis. Experiment results on FCVID and ActivityNet show that TDCMN demonstrates adaptive event recognition ability conditioned on different inputs, and improve the event recognition performance of Concept-based methods by a large margin. Code is available at https://github.com/qzhb/TDCMN.
Image2Point: 3D Point-Cloud Understanding with Pretrained 2D ConvNets
Jun 08, 2021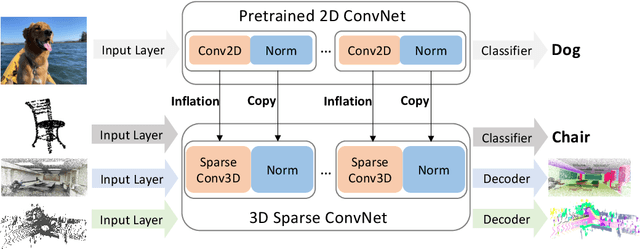
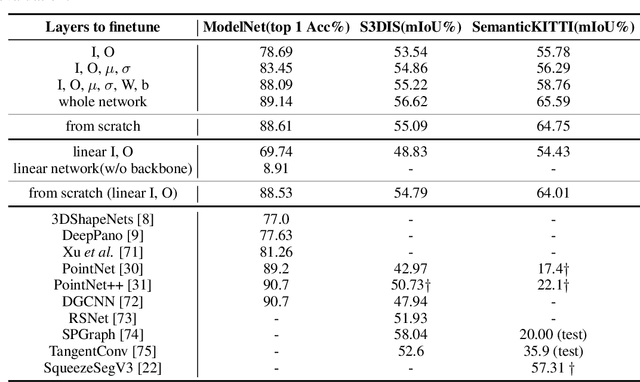


3D point-clouds and 2D images are different visual representations of the physical world. While human vision can understand both representations, computer vision models designed for 2D image and 3D point-cloud understanding are quite different. Our paper investigates the potential for transferability between these two representations by empirically investigating whether this approach works, what factors affect the transfer performance, and how to make it work even better. We discovered that we can indeed use the same neural net model architectures to understand both images and point-clouds. Moreover, we can transfer pretrained weights from image models to point-cloud models with minimal effort. Specifically, based on a 2D ConvNet pretrained on an image dataset, we can transfer the image model to a point-cloud model by \textit{inflating} 2D convolutional filters to 3D then finetuning its input, output, and optionally normalization layers. The transferred model can achieve competitive performance on 3D point-cloud classification, indoor and driving scene segmentation, even beating a wide range of point-cloud models that adopt task-specific architectures and use a variety of tricks.
Tagged Documents Co-Clustering
Oct 14, 2021
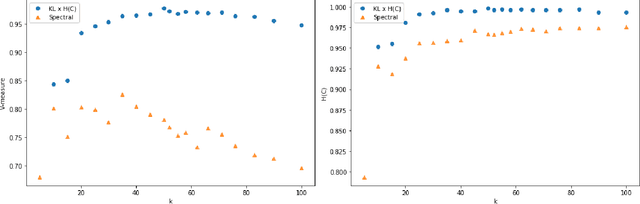
Tags are short sequences of words allowing to describe textual and non-texual resources such as as music, image or book. Tags could be used by machine information retrieval systems to access quickly a document. These tags can be used to build recommender systems to suggest similar items to a user. However, the number of tags per document is limited, and often distributed according to a Zipf law. In this paper, we propose a methodology to cluster tags into conceptual groups. Data are preprocessed to remove power-law effects and enhance the context of low-frequency words. Then, a hierarchical agglomerative co-clustering algorithm is proposed to group together the most related tags into clusters. The capabilities were evaluated on a sparse synthetic dataset and a real-world tag collection associated with scientific papers. The task being unsupervised, we propose some stopping criterion for selectecting an optimal partitioning.
Joint Learning of Multiple Image Restoration Tasks
Jul 10, 2019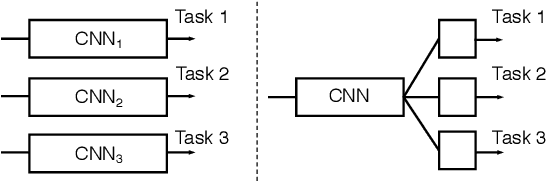



Convolutional neural networks have recently been successfully applied to the problems of restoring clean images from their degraded versions. Most studies have designed and trained a dedicated network for each of many image restoration tasks, such as motion blur removal, rain-streak removal, haze removal, etc. In this paper, we show that a single network having a single input and multiple output branches can solve multiple image restoration tasks. This is made possible by improving the attention mechanism and an internal structure of the basic blocks used in the dual residual networks, which was recently proposed and shown to work well for a number of image restoration tasks by Liu et al. Experimental results show that the proposed approach achieves a new state-of-the-art performance on haze removal (both in PSNR/SSIM) and JPEG artifact removal (in SSIM). To the authors' knowledge, this is the first report of successful multi-task learning on diverse image restoration tasks.
Training Deep Neural Networks with Adaptive Momentum Inspired by the Quadratic Optimization
Oct 18, 2021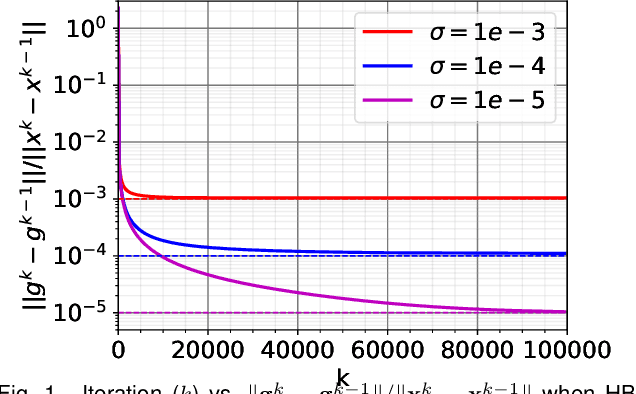


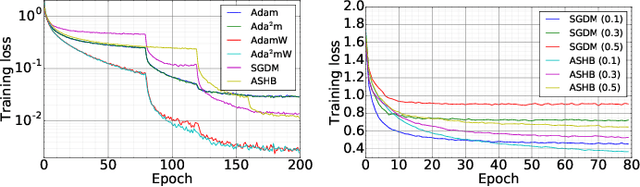
Heavy ball momentum is crucial in accelerating (stochastic) gradient-based optimization algorithms for machine learning. Existing heavy ball momentum is usually weighted by a uniform hyperparameter, which relies on excessive tuning. Moreover, the calibrated fixed hyperparameter may not lead to optimal performance. In this paper, to eliminate the effort for tuning the momentum-related hyperparameter, we propose a new adaptive momentum inspired by the optimal choice of the heavy ball momentum for quadratic optimization. Our proposed adaptive heavy ball momentum can improve stochastic gradient descent (SGD) and Adam. SGD and Adam with the newly designed adaptive momentum are more robust to large learning rates, converge faster, and generalize better than the baselines. We verify the efficiency of SGD and Adam with the new adaptive momentum on extensive machine learning benchmarks, including image classification, language modeling, and machine translation. Finally, we provide convergence guarantees for SGD and Adam with the proposed adaptive momentum.
BachGAN: High-Resolution Image Synthesis from Salient Object Layout
Mar 27, 2020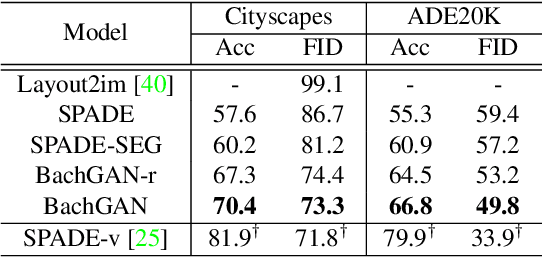
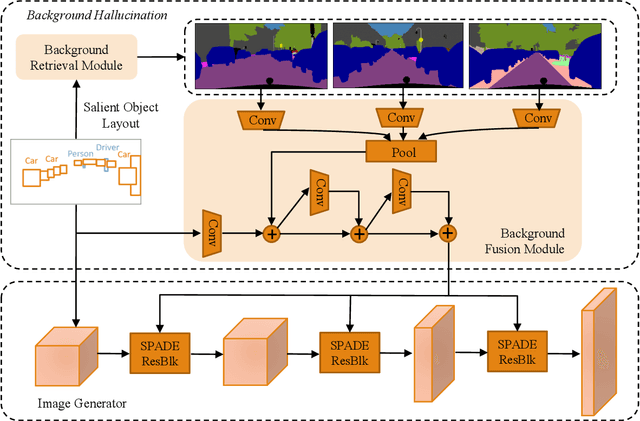


We propose a new task towards more practical application for image generation - high-quality image synthesis from salient object layout. This new setting allows users to provide the layout of salient objects only (i.e., foreground bounding boxes and categories), and lets the model complete the drawing with an invented background and a matching foreground. Two main challenges spring from this new task: (i) how to generate fine-grained details and realistic textures without segmentation map input; and (ii) how to create a background and weave it seamlessly into standalone objects. To tackle this, we propose Background Hallucination Generative Adversarial Network (BachGAN), which first selects a set of segmentation maps from a large candidate pool via a background retrieval module, then encodes these candidate layouts via a background fusion module to hallucinate a suitable background for the given objects. By generating the hallucinated background representation dynamically, our model can synthesize high-resolution images with both photo-realistic foreground and integral background. Experiments on Cityscapes and ADE20K datasets demonstrate the advantage of BachGAN over existing methods, measured on both visual fidelity of generated images and visual alignment between output images and input layouts.
BUNET: Blind Medical Image Segmentation Based on Secure UNET
Jul 14, 2020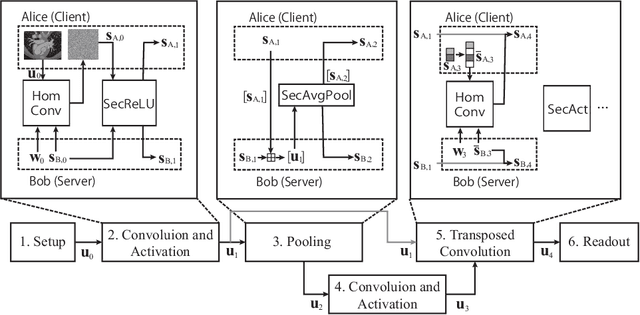
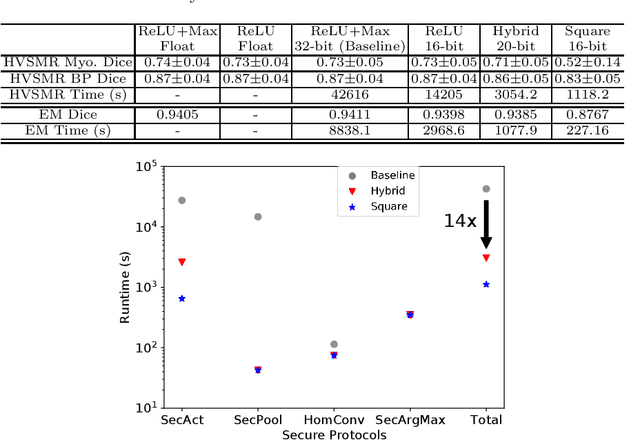
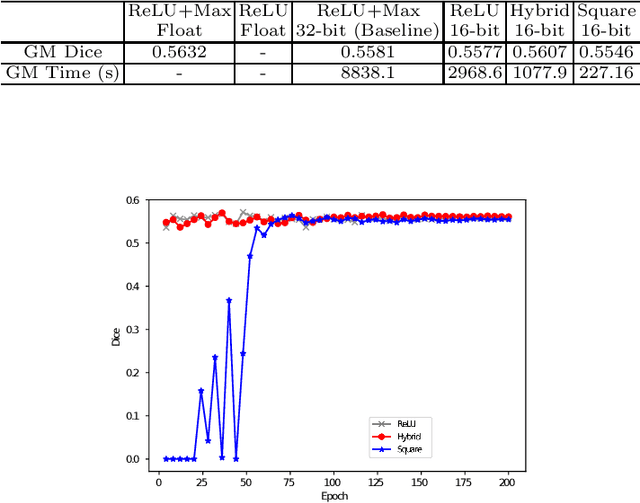
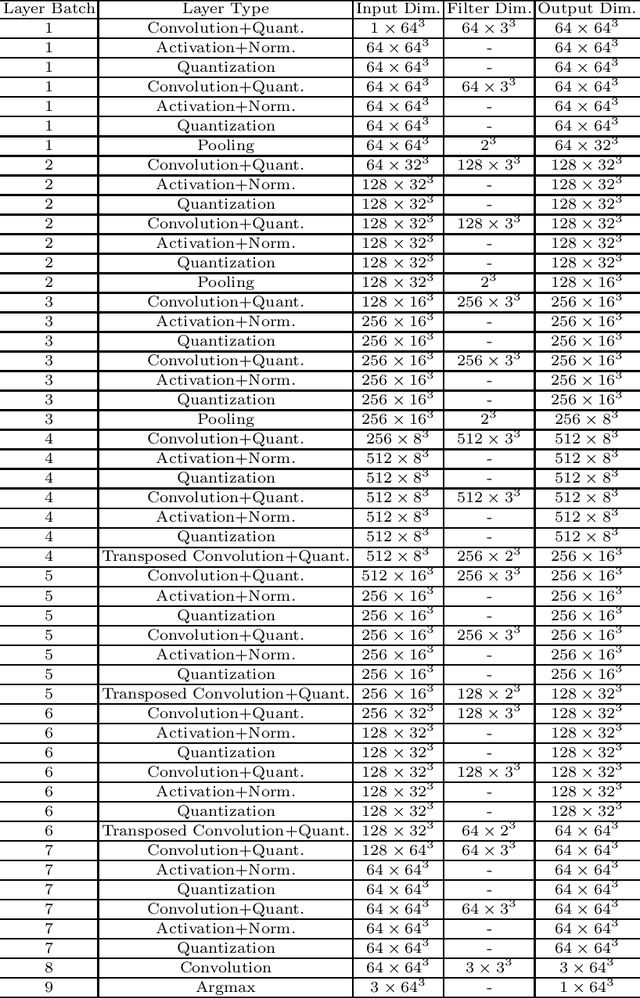
The strict security requirements placed on medical records by various privacy regulations become major obstacles in the age of big data. To ensure efficient machine learning as a service schemes while protecting data confidentiality, in this work, we propose blind UNET (BUNET), a secure protocol that implements privacy-preserving medical image segmentation based on the UNET architecture. In BUNET, we efficiently utilize cryptographic primitives such as homomorphic encryption and garbled circuits (GC) to design a complete secure protocol for the UNET neural architecture. In addition, we perform extensive architectural search in reducing the computational bottleneck of GC-based secure activation protocols with high-dimensional input data. In the experiment, we thoroughly examine the parameter space of our protocol, and show that we can achieve up to 14x inference time reduction compared to the-state-of-the-art secure inference technique on a baseline architecture with negligible accuracy degradation.
Pneumothorax Segmentation: Deep Learning Image Segmentation to predict Pneumothorax
Dec 16, 2019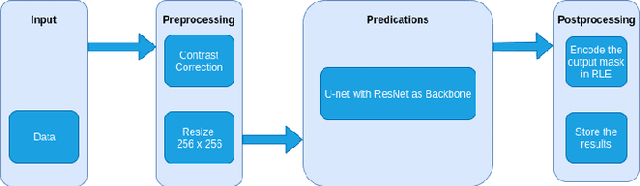
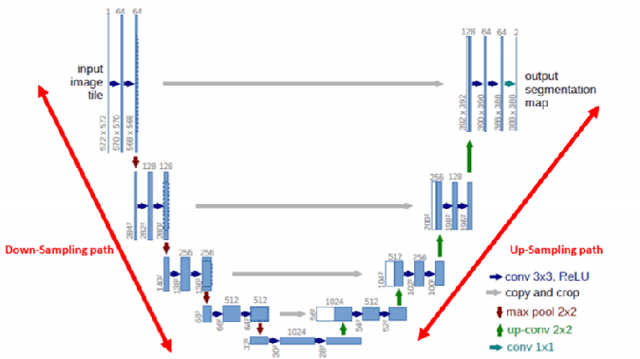
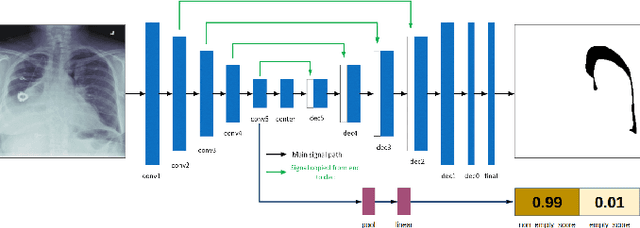
Computer vision has shown promising results in medical image processing. Pneumothorax is a deadly condition and if not diagnosed and treated at time then it causes death. It can be diagnosed with chest X-ray images. We need an expert and experienced radiologist to predict whether a person is suffering from pneumothorax or not by looking at the chest X-ray images. Everyone does not have access to such a facility. Moreover, in some cases, we need quick diagnoses. So we propose an image segmentation model to predict and give the output a mask that will assist the doctor in taking this crucial decision. Deep Learning has proved their worth in many areas and outperformed man state-of-the-art models. We want to use the power of these deep learning model to solve this problem. We have used U-net [13] architecture with ResNet [17] as a backbone and achieved promising results. U-net [13] performs very well in medical image processing and semantic segmentation. Our problem falls in the semantic segmentation category.