 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Synergistic Learning with Vision-Language Adaption for Low-Resource Biomedical Image Classification
Apr 27, 2026Accurate biomedical image classification under low-resource conditions remains challenging due to limited annotations, subtle inter-class visual differences, and complex disease semantics. While vision--language models offer a promising foundation for mitigating data scarcity, their effective adaptation in biomedical settings is constrained by the need for parameter-efficient tuning alongside fine-grained and semantically consistent representation learning. In this work, we propose Multi-View Synergistic Learning (MVSL), a unified framework that addresses these challenges by jointly considering adaptation paradigms, representation granularity, and disease semantic relationships. MVSL decouples the adaptation of visual and textual encoders to respect their distinct representational characteristics, enabling more stable and effective parameter-efficient fine-tuning. It further introduces multi-granularity contrastive learning to explicitly model both global image semantics and localized lesion-level evidence, improving fine-grained discrimination for visually similar disease categories. In addition, MVSL preserves disease-level semantic structure by incorporating structured supervision derived from large language models, which constrains textual representations at the class level and indirectly regularizes visual embeddings through cross-modal alignment. Together, these components enable more stable cross-modal alignment and improved discrimination under limited supervision. Extensive experiments on $11$ public biomedical datasets spanning $9$ imaging modalities and $10$ anatomical regions demonstrate that MVSL consistently outperforms state-of-the-art methods in few-shot and zero-shot classification settings.
PokeGym: A Visually-Driven Long-Horizon Benchmark for Vision-Language Models
Apr 09, 2026While Vision-Language Models (VLMs) have achieved remarkable progress in static visual understanding, their deployment in complex 3D embodied environments remains severely limited. Existing benchmarks suffer from four critical deficiencies: (1) passive perception tasks circumvent interactive dynamics; (2) simplified 2D environments fail to assess depth perception; (3) privileged state leakage bypasses genuine visual processing; and (4) human evaluation is prohibitively expensive and unscalable. We introduce PokeGym, a visually-driven long-horizon benchmark instantiated within Pokemon Legends: Z-A, a visually complex 3D open-world Role-Playing Game. PokeGym enforces strict code-level isolation: agents operate solely on raw RGB observations while an independent evaluator verifies success via memory scanning, ensuring pure vision-based decision-making and automated, scalable assessment. The benchmark comprises 30 tasks (30-220 steps) spanning navigation, interaction, and mixed scenarios, with three instruction granularities (Visual-Guided, Step-Guided, Goal-Only) to systematically deconstruct visual grounding, semantic reasoning, and autonomous exploration capabilities. Our evaluation reveals a key limitation of current VLMs: physical deadlock recovery, rather than high-level planning, constitutes the primary bottleneck, with deadlocks showing a strong negative correlation with task success. Furthermore, we uncover a metacognitive divergence: weaker models predominantly suffer from Unaware Deadlocks (oblivious to entrapment), whereas advanced models exhibit Aware Deadlocks (recognizing entrapment yet failing to recover). These findings highlight the need to integrate explicit spatial intuition into VLM architectures. The code and benchmark will be available on GitHub.
OTCE: Hybrid SSM and Attention with Cross Domain Mixture of Experts to construct Observer-Thinker-Conceiver-Expresser
Jun 25, 2024



Recent research has shown that combining Mamba with Transformer architecture, which has selective state space and quadratic self-attention mechanism, outperforms using Mamba or Transformer architecture alone in language modeling tasks. The quadratic self-attention mechanism effectively alleviates the shortcomings of selective state space in handling long-term dependencies of any element in the sequence. We propose a position information injection method that connects the selective state space model with the quadratic attention, and integrates these two architectures with hybrid experts with cross-sharing domains, so that we can enjoy the advantages of both. We design a new architecture with a more biomimetic idea: Observer-Thinker-Conceiver-Expresser (OTCE), which can compete with well-known medium-scale open-source language models on a small scale in language modeling tasks.
Multi-scale super-resolution generation of low-resolution scanned pathological images
May 15, 2021

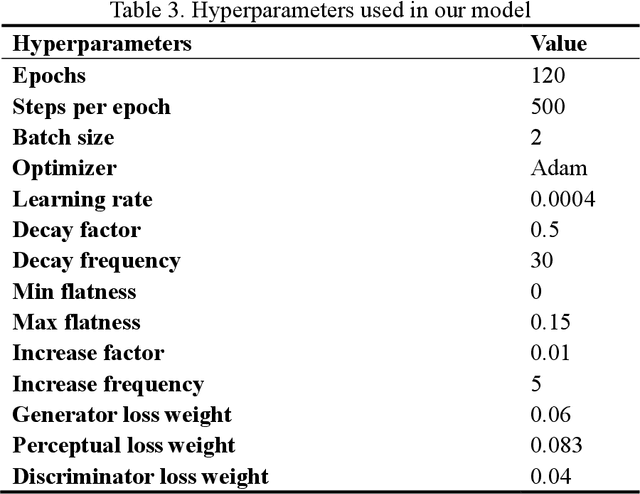
Digital pathology slide is easy to store and manage, convenient to browse and transmit. However, because of the high-resolution scan for example 40 times magnification(40X) during the digitization, the file size of each whole slide image exceeds 1Gigabyte, which eventually leads to huge storage capacity and very slow network transmission. We design a strategy to scan slides with low resolution (5X) and a super-resolution method is proposed to restore the image details when in diagnosis. The method is based on a multi-scale generative adversarial network, which sequentially generate three high-resolution images such as 10X, 20X and 40X. The perceived loss, generator loss of the generated images and real images are compared on three image resolutions, and a discriminator is used to evaluate the difference of highest-resolution generated image and real image. A dataset consisting of 100,000 pathological images from 10 types of human tissues is performed for training and testing the network. The generated images have high peak-signal-to-noise-ratio (PSNR) and structural-similarity-index (SSIM). The PSNR of 10X to 40X image are 24.16, 22.27 and 20.44, and the SSIM are 0.845, 0.680 and 0.512, which are better than other super-resolution networks such as DBPN, ESPCN, RDN, EDSR and MDSR. Moreover, visual inspections show that the generated high-resolution images by our network have enough details for diagnosis, good color reproduction and close to real images, while other five networks are severely blurred, local deformation or miss important details. Moreover, no significant differences can be found on pathological diagnosis based on the generated and real images. The proposed multi-scale network can generate good high-resolution pathological images, and will provide a low-cost storage (about 15MB/image on 5X), faster image sharing method for digital pathology.