 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware-Friendly Delayed-Feedback Reservoir for Multivariate Time-Series Classification
Apr 16, 2025Reservoir computing (RC) is attracting attention as a machine-learning technique for edge computing. In time-series classification tasks, the number of features obtained using a reservoir depends on the length of the input series. Therefore, the features must be converted to a constant-length intermediate representation (IR), such that they can be processed by an output layer. Existing conversion methods involve computationally expensive matrix inversion that significantly increases the circuit size and requires processing power when implemented in hardware. In this article, we propose a simple but effective IR, namely, dot-product-based reservoir representation (DPRR), for RC based on the dot product of data features. Additionally, we propose a hardware-friendly delayed-feedback reservoir (DFR) consisting of a nonlinear element and delayed feedback loop with DPRR. The proposed DFR successfully classified multivariate time series data that has been considered particularly difficult to implement efficiently in hardware. In contrast to conventional DFR models that require analog circuits, the proposed model can be implemented in a fully digital manner suitable for high-level syntheses. A comparison with existing machine-learning methods via field-programmable gate array implementation using 12 multivariate time-series classification tasks confirmed the superior accuracy and small circuit size of the proposed method.
Modular DFR: Digital Delayed Feedback Reservoir Model for Enhancing Design Flexibility
Jul 05, 2023A delayed feedback reservoir (DFR) is a type of reservoir computing system well-suited for hardware implementations owing to its simple structure. Most existing DFR implementations use analog circuits that require both digital-to-analog and analog-to-digital converters for interfacing. However, digital DFRs emulate analog nonlinear components in the digital domain, resulting in a lack of design flexibility and higher power consumption. In this paper, we propose a novel modular DFR model that is suitable for fully digital implementations. The proposed model reduces the number of hyperparameters and allows flexibility in the selection of the nonlinear function, which improves the accuracy while reducing the power consumption. We further present two DFR realizations with different nonlinear functions, achieving 10x power reduction and 5.3x throughput improvement while maintaining equal or better accuracy.
Accelerating Parameter Extraction of Power MOSFET Models Using Automatic Differentiation
Oct 22, 2021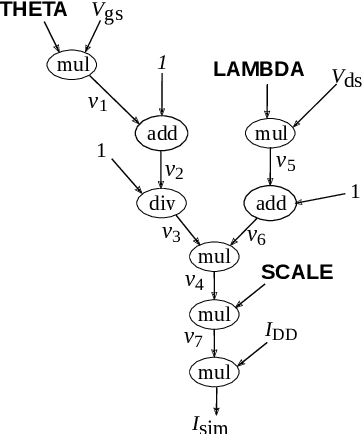
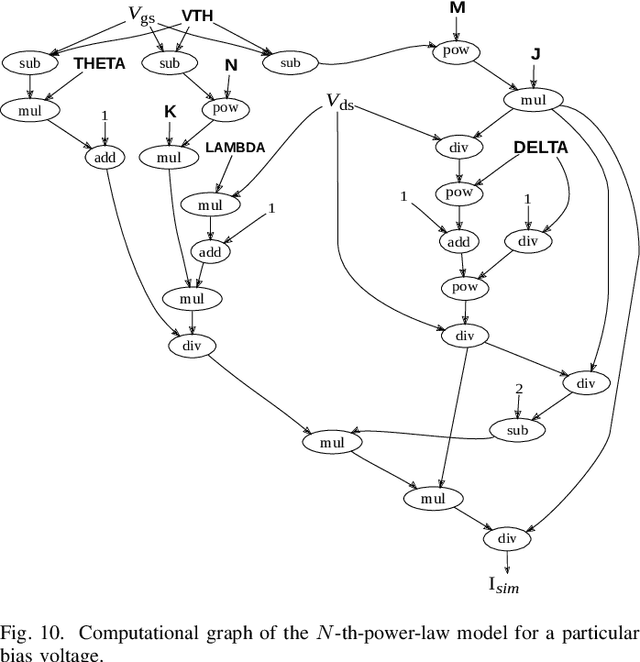
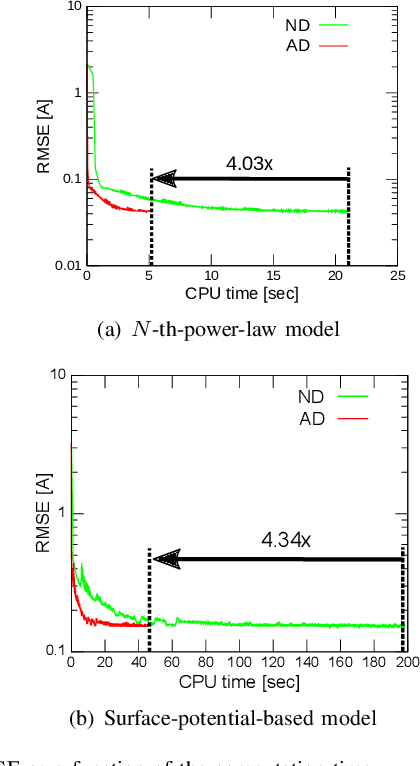

The extraction of the model parameters is as important as the development of compact model itself because simulation accuracy is fully determined by the accuracy of the parameters used. This study proposes an efficient model-parameter extraction method for compact models of power MOSFETs. The proposed method employs automatic differentiation (AD), which is extensively used for training artificial neural networks. In the proposed AD-based parameter extraction, gradient of all the model parameters is analytically calculated by forming a graph that facilitates the backward propagation of errors. Based on the calculated gradient, computationally intensive numerical differentiation is eliminated and the model parameters are efficiently optimized. Experiments are conducted to fit current and capacitance characteristics of commercially available silicon carbide MOSFET using power MOSFET models having 13 model parameters. Results demonstrated that the proposed method could successfully derive the model parameters 3.50x faster than a conventional numerical-differentiation method while achieving the equal accuracy.
FedNNNN: Norm-Normalized Neural Network Aggregation for Fast and Accurate Federated Learning
Aug 11, 2020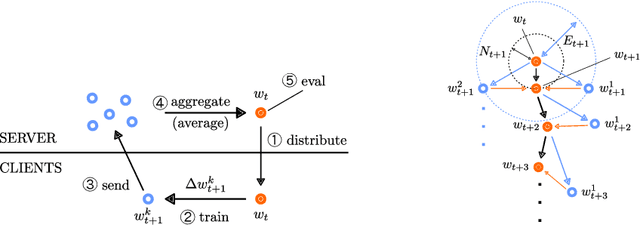
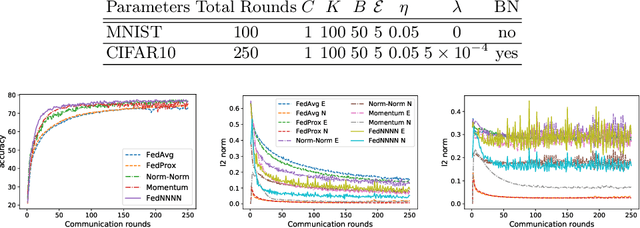
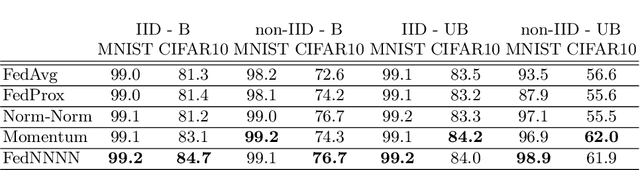
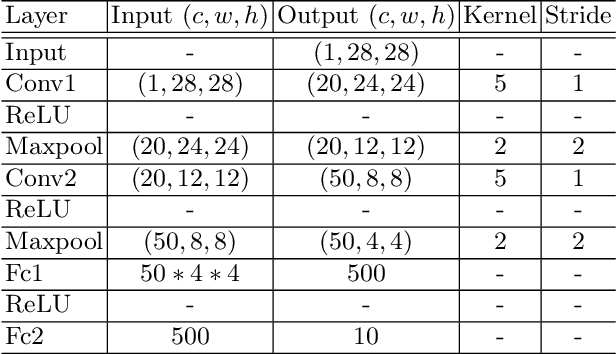
Federated learning (FL) is a distributed learning protocol in which a server needs to aggregate a set of models learned some independent clients to proceed the learning process. At present, model averaging, known as FedAvg, is one of the most widely adapted aggregation techniques. However, it is known to yield the models with degraded prediction accuracy and slow convergence. In this work, we find out that averaging models from different clients significantly diminishes the norm of the update vectors, resulting in slow learning rate and low prediction accuracy. Therefore, we propose a new aggregation method called FedNNNN. Instead of simple model averaging, we adjust the norm of the update vector and introduce momentum control techniques to improve the aggregation effectiveness of FL. As a demonstration, we evaluate FedNNNN on multiple datasets and scenarios with different neural network models, and observe up to 5.4% accuracy improvement.
BUNET: Blind Medical Image Segmentation Based on Secure UNET
Jul 14, 2020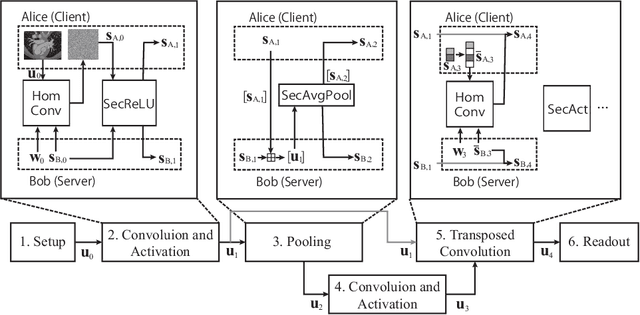
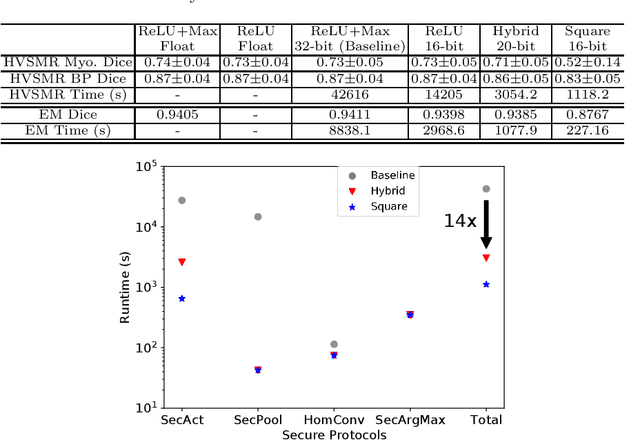
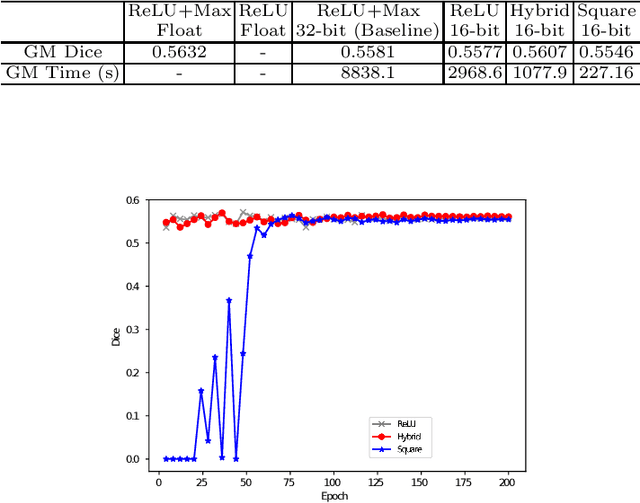
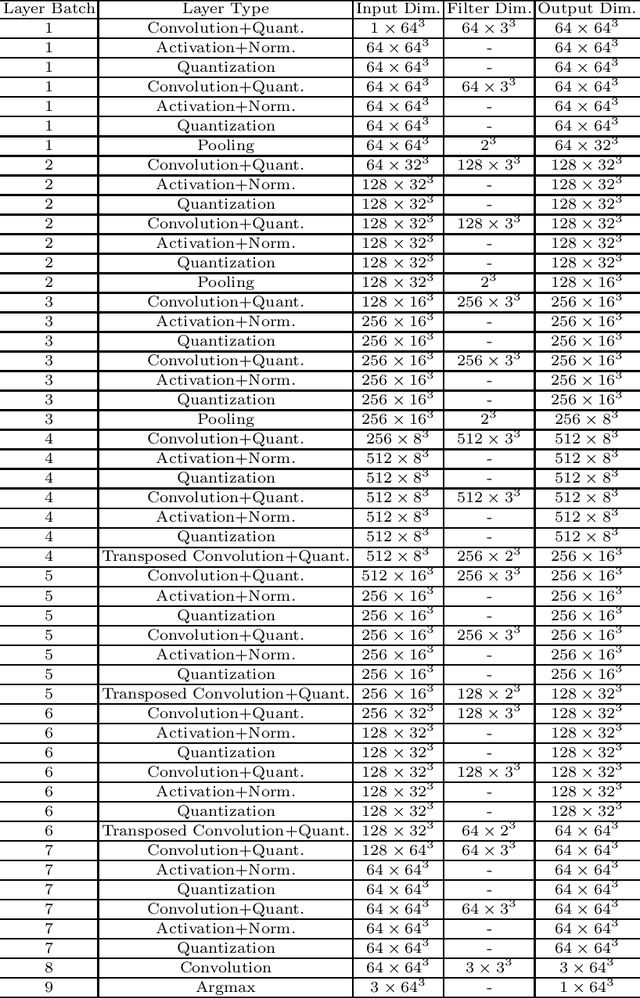
The strict security requirements placed on medical records by various privacy regulations become major obstacles in the age of big data. To ensure efficient machine learning as a service schemes while protecting data confidentiality, in this work, we propose blind UNET (BUNET), a secure protocol that implements privacy-preserving medical image segmentation based on the UNET architecture. In BUNET, we efficiently utilize cryptographic primitives such as homomorphic encryption and garbled circuits (GC) to design a complete secure protocol for the UNET neural architecture. In addition, we perform extensive architectural search in reducing the computational bottleneck of GC-based secure activation protocols with high-dimensional input data. In the experiment, we thoroughly examine the parameter space of our protocol, and show that we can achieve up to 14x inference time reduction compared to the-state-of-the-art secure inference technique on a baseline architecture with negligible accuracy degradation.
ENSEI: Efficient Secure Inference via Frequency-Domain Homomorphic Convolution for Privacy-Preserving Visual Recognition
Mar 11, 2020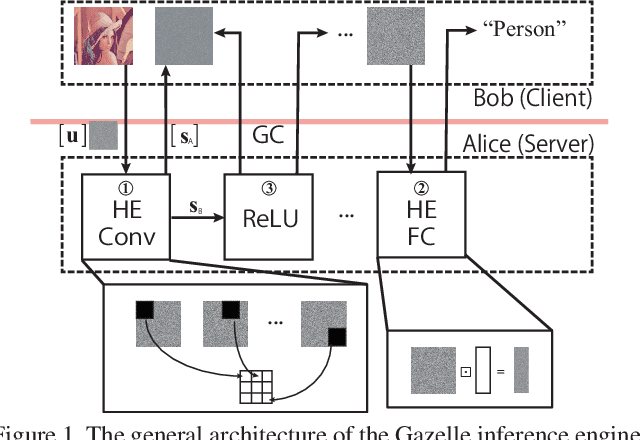
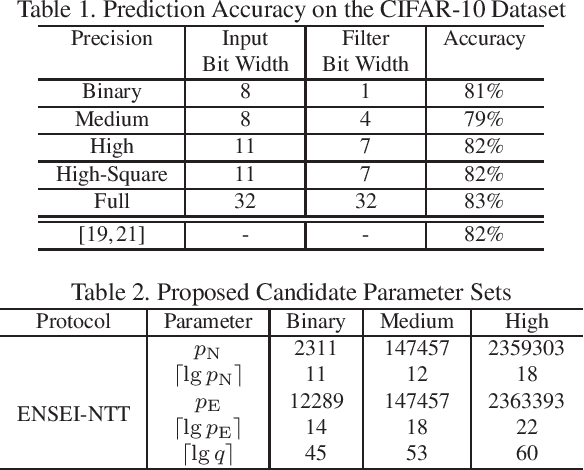
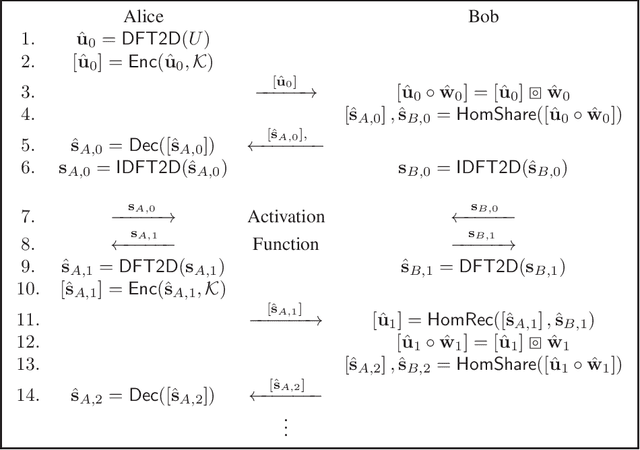
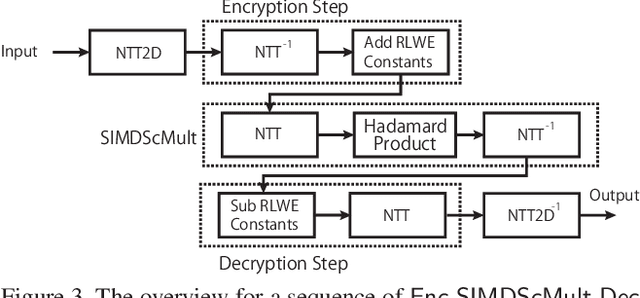
In this work, we propose ENSEI, a secure inference (SI) framework based on the frequency-domain secure convolution (FDSC) protocol for the efficient execution of privacy-preserving visual recognition. Our observation is that, under the combination of homomorphic encryption and secret sharing, homomorphic convolution can be obliviously carried out in the frequency domain, significantly simplifying the related computations. We provide protocol designs and parameter derivations for number-theoretic transform (NTT) based FDSC. In the experiment, we thoroughly study the accuracy-efficiency trade-offs between time- and frequency-domain homomorphic convolution. With ENSEI, compared to the best known works, we achieve 5--11x online time reduction, up to 33x setup time reduction, and up to 10x reduction in the overall inference time. A further 33% of bandwidth reductions can be obtained on binary neural networks with only 1% of accuracy degradation on the CIFAR-10 dataset.
NASS: Optimizing Secure Inference via Neural Architecture Search
Feb 16, 2020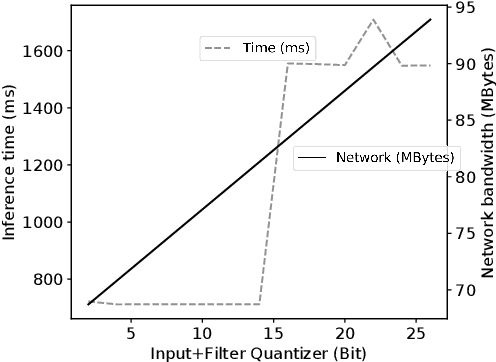
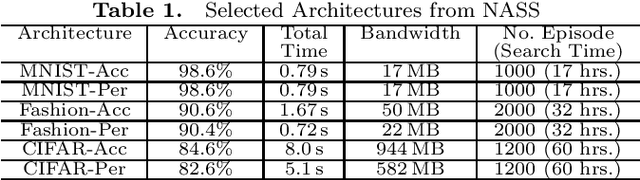
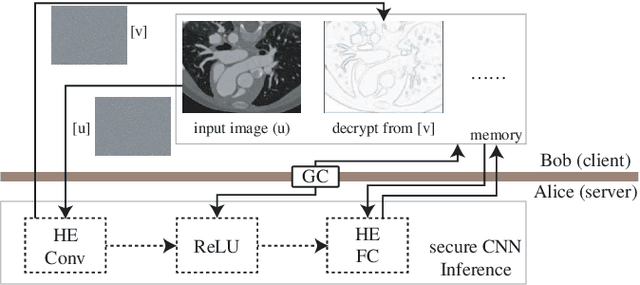
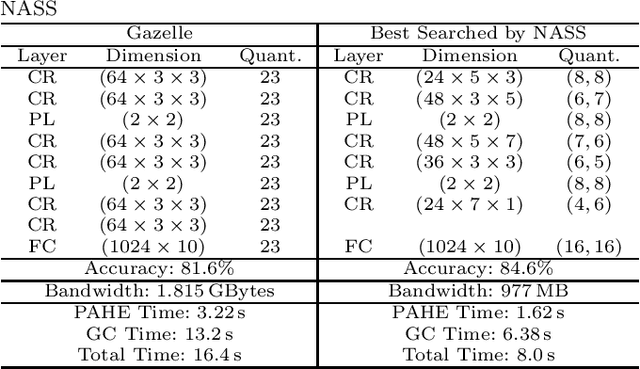
Due to increasing privacy concerns, neural network (NN) based secure inference (SI) schemes that simultaneously hide the client inputs and server models attract major research interests. While existing works focused on developing secure protocols for NN-based SI, in this work, we take a different approach. We propose NASS, an integrated framework to search for tailored NN architectures designed specifically for SI. In particular, we propose to model cryptographic protocols as design elements with associated reward functions. The characterized models are then adopted in a joint optimization with predicted hyperparameters in identifying the best NN architectures that balance prediction accuracy and execution efficiency. In the experiment, it is demonstrated that we can achieve the best of both worlds by using NASS, where the prediction accuracy can be improved from 81.6% to 84.6%, while the inference runtime is reduced by 2x and communication bandwidth by 1.9x on the CIFAR-10 dataset.