 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Effects of Image Distribution and Task on Adversarial Robustness
Feb 21, 2021
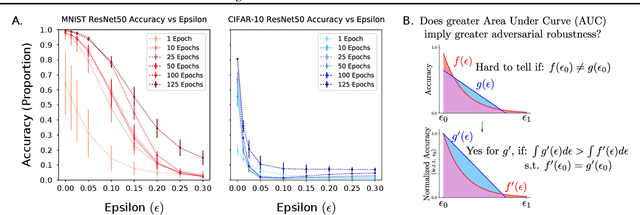
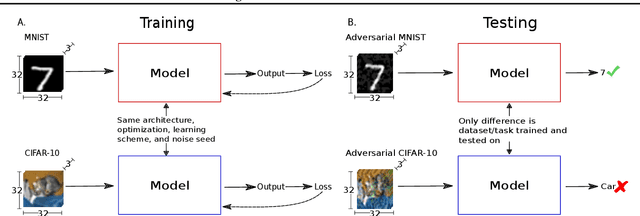

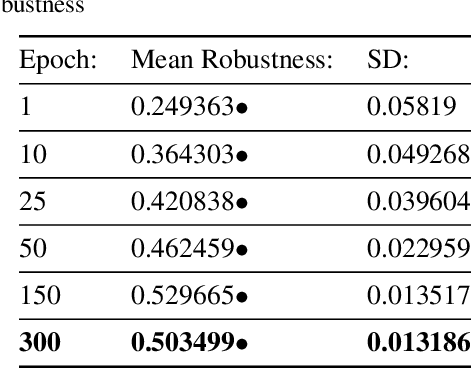
In this paper, we propose an adaptation to the area under the curve (AUC) metric to measure the adversarial robustness of a model over a particular $\epsilon$-interval $[\epsilon_0, \epsilon_1]$ (interval of adversarial perturbation strengths) that facilitates unbiased comparisons across models when they have different initial $\epsilon_0$ performance. This can be used to determine how adversarially robust a model is to different image distributions or task (or some other variable); and/or to measure how robust a model is comparatively to other models. We used this adversarial robustness metric on models of an MNIST, CIFAR-10, and a Fusion dataset (CIFAR-10 + MNIST) where trained models performed either a digit or object recognition task using a LeNet, ResNet50, or a fully connected network (FullyConnectedNet) architecture and found the following: 1) CIFAR-10 models are inherently less adversarially robust than MNIST models; 2) Both the image distribution and task that a model is trained on can affect the adversarial robustness of the resultant model. 3) Pretraining with a different image distribution and task sometimes carries over the adversarial robustness induced by that image distribution and task in the resultant model; Collectively, our results imply non-trivial differences of the learned representation space of one perceptual system over another given its exposure to different image statistics or tasks (mainly objects vs digits). Moreover, these results hold even when model systems are equalized to have the same level of performance, or when exposed to approximately matched image statistics of fusion images but with different tasks.
Source-Free Domain Adaptation for Image Segmentation
Aug 06, 2021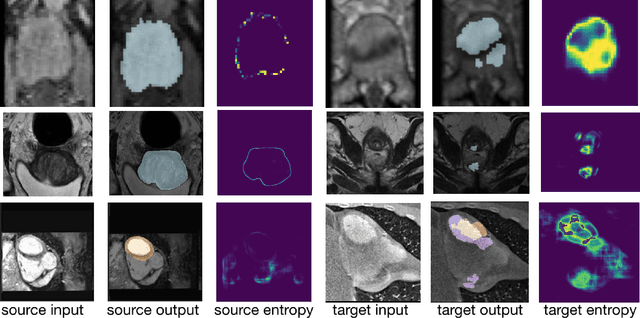
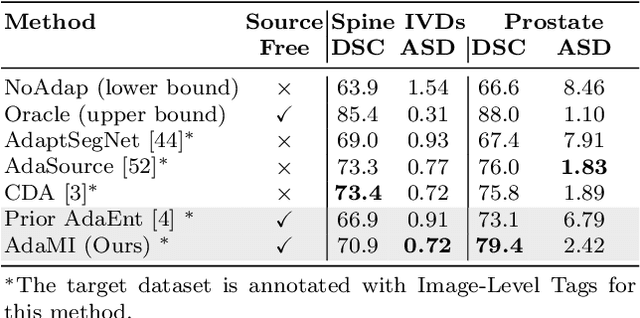
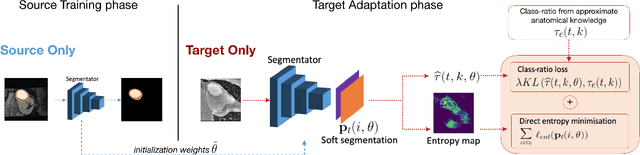
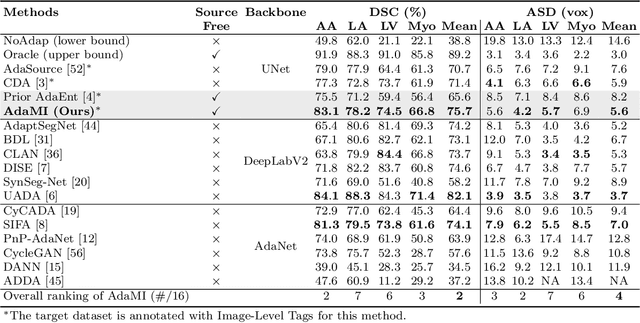
Domain adaptation (DA) has drawn high interest for its capacity to adapt a model trained on labeled source data to perform well on unlabeled or weakly labeled target data from a different domain. Most common DA techniques require concurrent access to the input images of both the source and target domains. However, in practice, privacy concerns often impede the availability of source images in the adaptation phase. This is a very frequent DA scenario in medical imaging, where, for instance, the source and target images could come from different clinical sites. We introduce a source-free domain adaptation for image segmentation. Our formulation is based on minimizing a label-free entropy loss defined over target-domain data, which we further guide with a domain-invariant prior on the segmentation regions. Many priors can be derived from anatomical information. Here, a class ratio prior is estimated from anatomical knowledge and integrated in the form of a Kullback Leibler (KL) divergence in our overall loss function. Furthermore, we motivate our overall loss with an interesting link to maximizing the mutual information between the target images and their label predictions. We show the effectiveness of our prior aware entropy minimization in a variety of domain-adaptation scenarios, with different modalities and applications, including spine, prostate, and cardiac segmentation. Our method yields comparable results to several state of the art adaptation techniques, despite having access to much less information, as the source images are entirely absent in our adaptation phase. Our straightforward adaptation strategy uses only one network, contrary to popular adversarial techniques, which are not applicable to a source-free DA setting. Our framework can be readily used in a breadth of segmentation problems, and our code is publicly available: https://github.com/mathilde-b/SFDA
Orthogonal Jacobian Regularization for Unsupervised Disentanglement in Image Generation
Aug 17, 2021


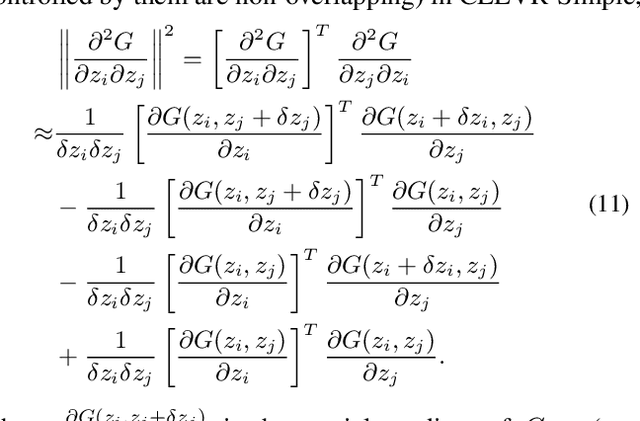
Unsupervised disentanglement learning is a crucial issue for understanding and exploiting deep generative models. Recently, SeFa tries to find latent disentangled directions by performing SVD on the first projection of a pre-trained GAN. However, it is only applied to the first layer and works in a post-processing way. Hessian Penalty minimizes the off-diagonal entries of the output's Hessian matrix to facilitate disentanglement, and can be applied to multi-layers.However, it constrains each entry of output independently, making it not sufficient in disentangling the latent directions (e.g., shape, size, rotation, etc.) of spatially correlated variations. In this paper, we propose a simple Orthogonal Jacobian Regularization (OroJaR) to encourage deep generative model to learn disentangled representations. It simply encourages the variation of output caused by perturbations on different latent dimensions to be orthogonal, and the Jacobian with respect to the input is calculated to represent this variation. We show that our OroJaR also encourages the output's Hessian matrix to be diagonal in an indirect manner. In contrast to the Hessian Penalty, our OroJaR constrains the output in a holistic way, making it very effective in disentangling latent dimensions corresponding to spatially correlated variations. Quantitative and qualitative experimental results show that our method is effective in disentangled and controllable image generation, and performs favorably against the state-of-the-art methods. Our code is available at https://github.com/csyxwei/OroJaR
Unified Pretraining Framework for Document Understanding
Apr 28, 2022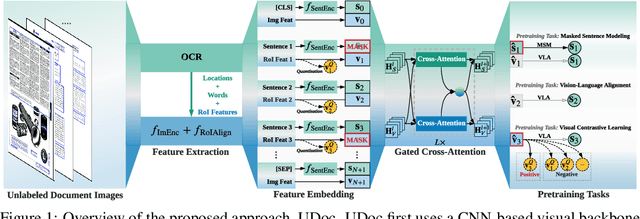
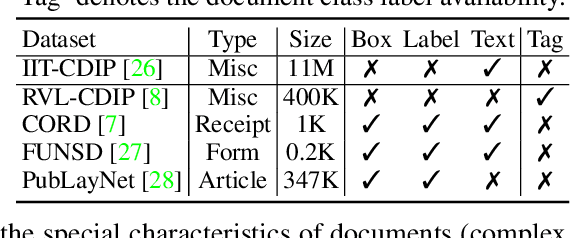
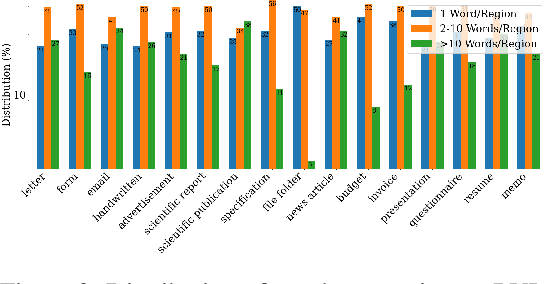
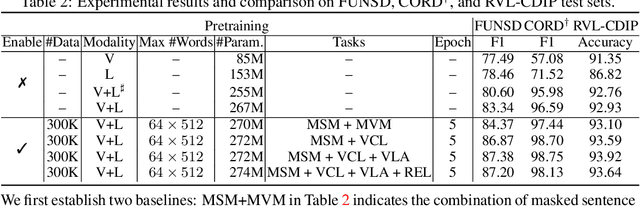
Document intelligence automates the extraction of information from documents and supports many business applications. Recent self-supervised learning methods on large-scale unlabeled document datasets have opened up promising directions towards reducing annotation efforts by training models with self-supervised objectives. However, most of the existing document pretraining methods are still language-dominated. We present UDoc, a new unified pretraining framework for document understanding. UDoc is designed to support most document understanding tasks, extending the Transformer to take multimodal embeddings as input. Each input element is composed of words and visual features from a semantic region of the input document image. An important feature of UDoc is that it learns a generic representation by making use of three self-supervised losses, encouraging the representation to model sentences, learn similarities, and align modalities. Extensive empirical analysis demonstrates that the pretraining procedure learns better joint representations and leads to improvements in downstream tasks.
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
Feb 08, 2021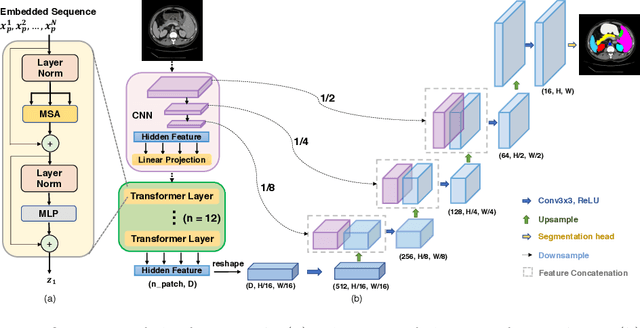
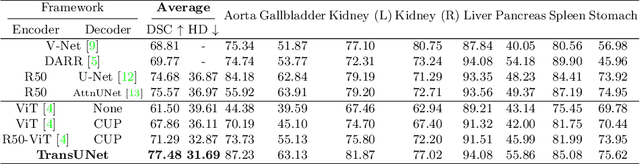
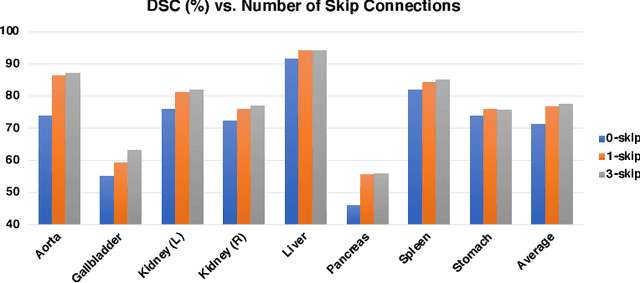

Medical image segmentation is an essential prerequisite for developing healthcare systems, especially for disease diagnosis and treatment planning. On various medical image segmentation tasks, the u-shaped architecture, also known as U-Net, has become the de-facto standard and achieved tremendous success. However, due to the intrinsic locality of convolution operations, U-Net generally demonstrates limitations in explicitly modeling long-range dependency. Transformers, designed for sequence-to-sequence prediction, have emerged as alternative architectures with innate global self-attention mechanisms, but can result in limited localization abilities due to insufficient low-level details. In this paper, we propose TransUNet, which merits both Transformers and U-Net, as a strong alternative for medical image segmentation. On one hand, the Transformer encodes tokenized image patches from a convolution neural network (CNN) feature map as the input sequence for extracting global contexts. On the other hand, the decoder upsamples the encoded features which are then combined with the high-resolution CNN feature maps to enable precise localization. We argue that Transformers can serve as strong encoders for medical image segmentation tasks, with the combination of U-Net to enhance finer details by recovering localized spatial information. TransUNet achieves superior performances to various competing methods on different medical applications including multi-organ segmentation and cardiac segmentation. Code and models are available at https://github.com/Beckschen/TransUNet.
Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation
Aug 03, 2020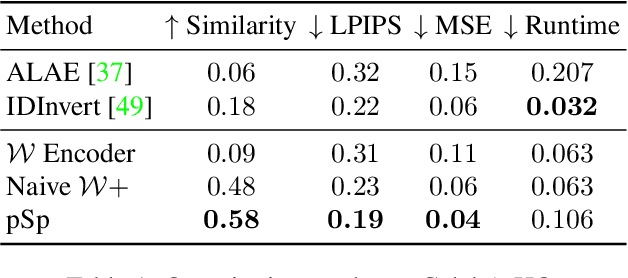
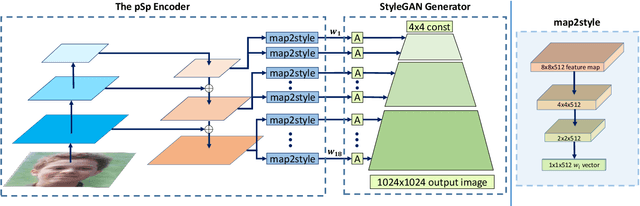
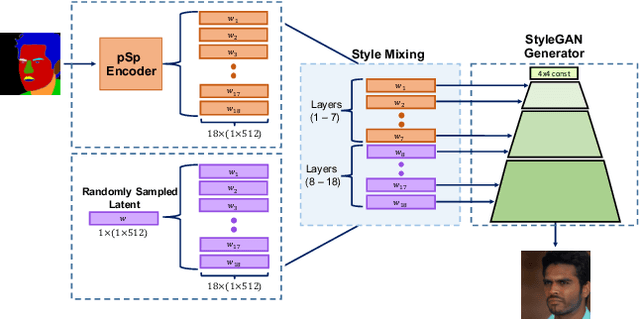

We present a generic image-to-image translation framework, Pixel2Style2Pixel (pSp). Our pSp framework is based on a novel encoder network that directly generates a series of style vectors which are fed into a pretrained StyleGAN generator, forming the extended W+ latent space. We first show that our encoder can directly embed real images into W+, with no additional optimization. We further introduce a dedicated identity loss which is shown to achieve improved performance in the reconstruction of an input image. We demonstrate pSp to be a simple architecture that, by leveraging a well-trained, fixed generator network, can be easily applied on a wide-range of image-to-image translation tasks. Solving these tasks through the style representation results in a global approach that does not rely on a local pixel-to-pixel correspondence and further supports multi-modal synthesis via the resampling of styles. Notably, we demonstrate that pSp can be trained to align a face image to a frontal pose without any labeled data, generate multi-modal results for ambiguous tasks such as conditional face generation from segmentation maps, and construct high-resolution images from corresponding low-resolution images.
Style Curriculum Learning for Robust Medical Image Segmentation
Aug 01, 2021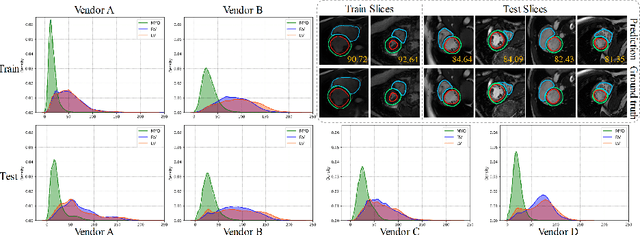
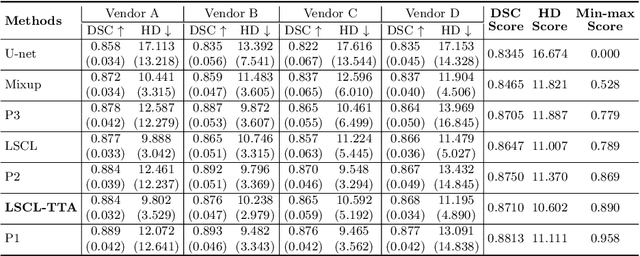
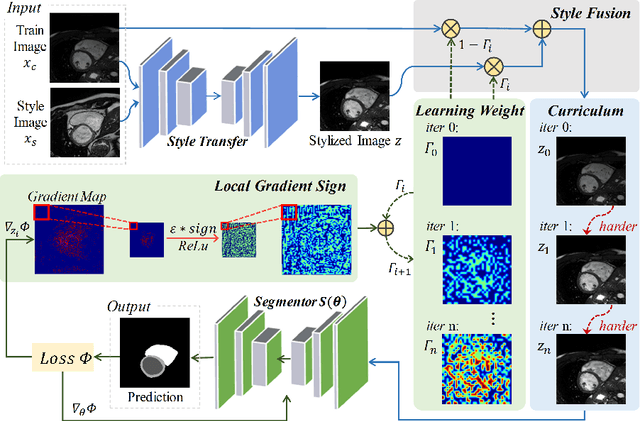

The performance of deep segmentation models often degrades due to distribution shifts in image intensities between the training and test data sets. This is particularly pronounced in multi-centre studies involving data acquired using multi-vendor scanners, with variations in acquisition protocols. It is challenging to address this degradation because the shift is often not known \textit{a priori} and hence difficult to model. We propose a novel framework to ensure robust segmentation in the presence of such distribution shifts. Our contribution is three-fold. First, inspired by the spirit of curriculum learning, we design a novel style curriculum to train the segmentation models using an easy-to-hard mode. A style transfer model with style fusion is employed to generate the curriculum samples. Gradually focusing on complex and adversarial style samples can significantly boost the robustness of the models. Second, instead of subjectively defining the curriculum complexity, we adopt an automated gradient manipulation method to control the hard and adversarial sample generation process. Third, we propose the Local Gradient Sign strategy to aggregate the gradient locally and stabilise training during gradient manipulation. The proposed framework can generalise to unknown distribution without using any target data. Extensive experiments on the public M\&Ms Challenge dataset demonstrate that our proposed framework can generalise deep models well to unknown distributions and achieve significant improvements in segmentation accuracy.
Spatio-Temporal Transformer for Dynamic Facial Expression Recognition in the Wild
May 10, 2022
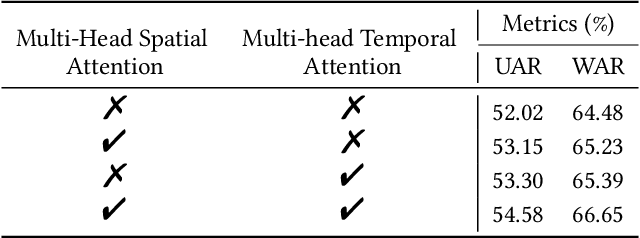
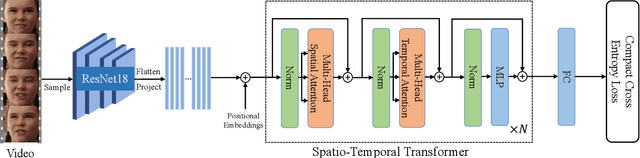
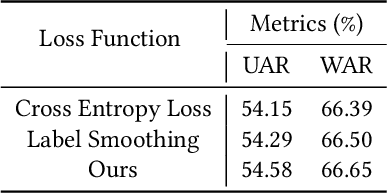
Previous methods for dynamic facial expression in the wild are mainly based on Convolutional Neural Networks (CNNs), whose local operations ignore the long-range dependencies in videos. To solve this problem, we propose the spatio-temporal Transformer (STT) to capture discriminative features within each frame and model contextual relationships among frames. Spatio-temporal dependencies are captured and integrated by our unified Transformer. Specifically, given an image sequence consisting of multiple frames as input, we utilize the CNN backbone to translate each frame into a visual feature sequence. Subsequently, the spatial attention and the temporal attention within each block are jointly applied for learning spatio-temporal representations at the sequence level. In addition, we propose the compact softmax cross entropy loss to further encourage the learned features have the minimum intra-class distance and the maximum inter-class distance. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and AFEW) indicate that our method provides an effective way to make use of the spatial and temporal dependencies for dynamic facial expression recognition. The source code and the training logs will be made publicly available.
GasHis-Transformer: A Multi-scale Visual Transformer Approach for Gastric Histopathology Image Classification
May 25, 2021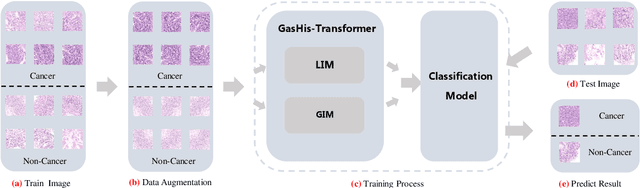

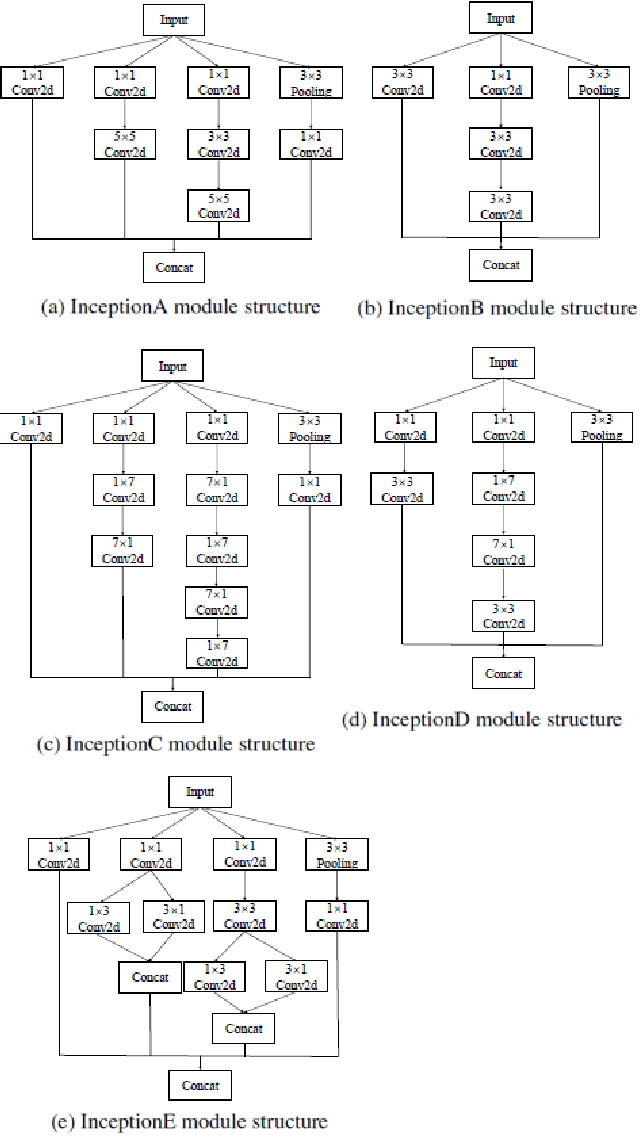
Existing deep learning methods for diagnosis of gastric cancer commonly use convolutional neural networks (CNN). Recently, the Visual Transformer (VT) has attracted a major attention because of its performance and efficiency, but its applications are mostly in the field of computer vision. In this paper, a multi-scale visual transformer model, referred to as GasHis-Transformer, is proposed for gastric histopathology image classification (GHIC), which enables the automatic classification of microscopic gastric images into abnormal and normal cases. The GasHis-Transformer model consists of two key modules: a global information module (GIM) and a local information module (LIM) to extract pathological features effectively. In our experiments, a public hematoxylin and eosin (H&E) stained gastric histopathology dataset with 280 abnormal or normal images using the GasHis-Transformer model is applied to estimate precision, recall, F1-score, and accuracy on the testing set as 98.0%, 100.0%, 96.0% and 98.0% respectively. Furthermore, a critical study is conducted to evaluate the robustness of GasHis-Transformer according to add ten different noises including adversarial attack and traditional image noise. In addition, a clinically meaningful study is executed to test the gastric cancer identification of GasHis-Transformerwith 420 abnormal images and achieves 96.2% accuracy. Finally, a comparative study is performed to test the generalizability with both H&E and Immunohistochemical (IHC) stained images on a lymphoma image dataset, a breast cancer dataset and a cervical cancer dataset, producing comparable F1-scores (85.6%, 82.8% and 65.7%, respectively) and accuracy (83.9%, 89.4% and 65.7%, respectively) respectively. In conclusion, GasHis-Transformerdemonstrates a high classification performance and shows its significant potential in histopathology image analysis.
QAIR: Practical Query-efficient Black-Box Attacks for Image Retrieval
Mar 23, 2021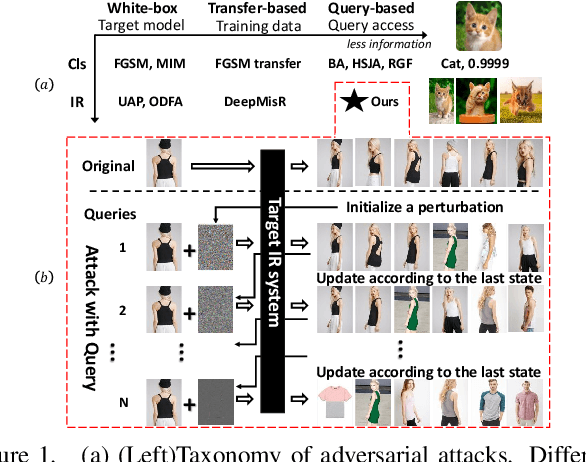
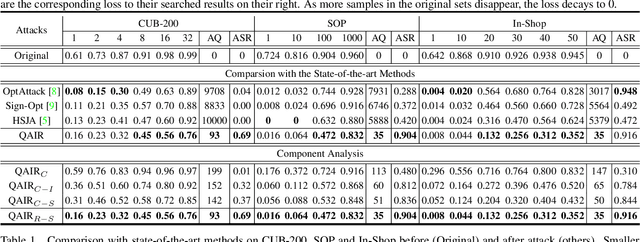
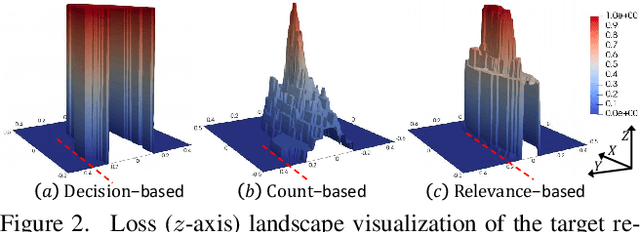
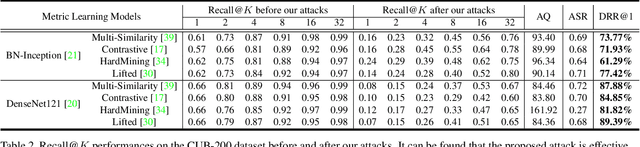
We study the query-based attack against image retrieval to evaluate its robustness against adversarial examples under the black-box setting, where the adversary only has query access to the top-k ranked unlabeled images from the database. Compared with query attacks in image classification, which produce adversaries according to the returned labels or confidence score, the challenge becomes even more prominent due to the difficulty in quantifying the attack effectiveness on the partial retrieved list. In this paper, we make the first attempt in Query-based Attack against Image Retrieval (QAIR), to completely subvert the top-k retrieval results. Specifically, a new relevance-based loss is designed to quantify the attack effects by measuring the set similarity on the top-k retrieval results before and after attacks and guide the gradient optimization. To further boost the attack efficiency, a recursive model stealing method is proposed to acquire transferable priors on the target model and generate the prior-guided gradients. Comprehensive experiments show that the proposed attack achieves a high attack success rate with few queries against the image retrieval systems under the black-box setting. The attack evaluations on the real-world visual search engine show that it successfully deceives a commercial system such as Bing Visual Search with 98% attack success rate by only 33 queries on average.