 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking FUN: Frequency-Domain Utilization Networks
Dec 06, 2020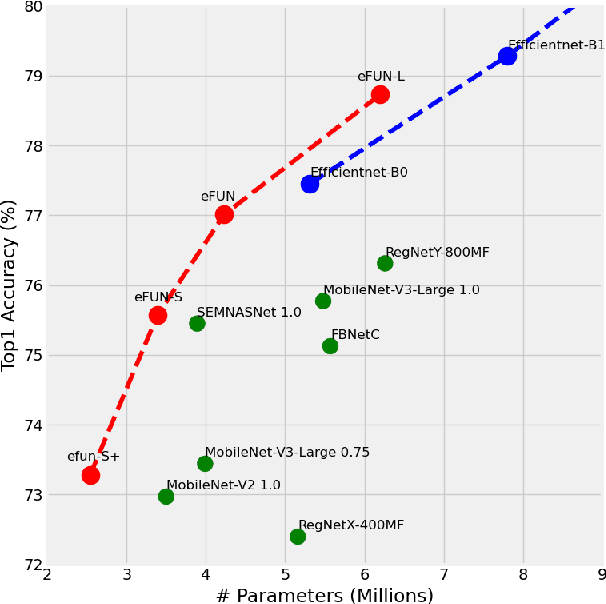
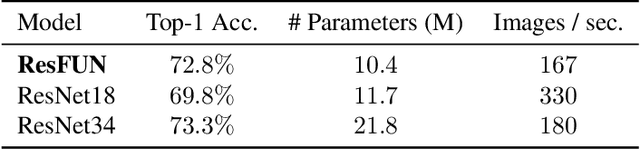
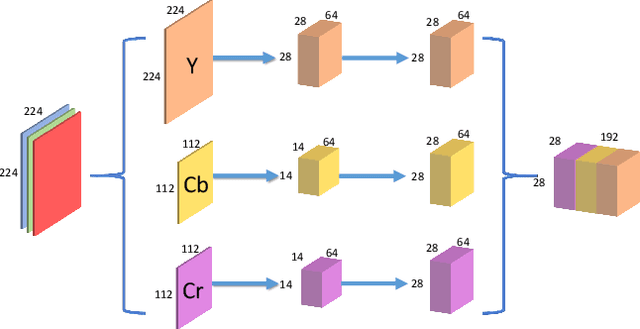
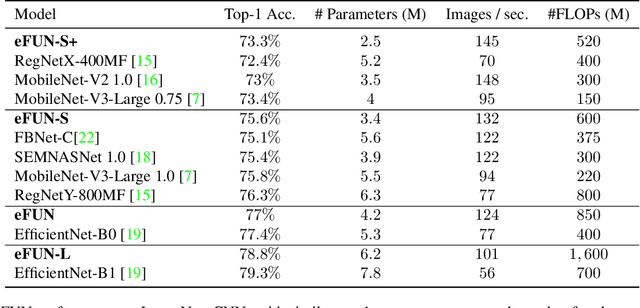
The search for efficient neural network architectures has gained much focus in recent years, where modern architectures focus not only on accuracy but also on inference time and model size. Here, we present FUN, a family of novel Frequency-domain Utilization Networks. These networks utilize the inherent efficiency of the frequency-domain by working directly in that domain, represented with the Discrete Cosine Transform. Using modern techniques and building blocks such as compound-scaling and inverted-residual layers we generate a set of such networks allowing one to balance between size, latency and accuracy while outperforming competing RGB-based models. Extensive evaluations verifies that our networks present strong alternatives to previous approaches. Moreover, we show that working in frequency domain allows for dynamic compression of the input at inference time without any explicit change to the architecture.
Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation
Aug 03, 2020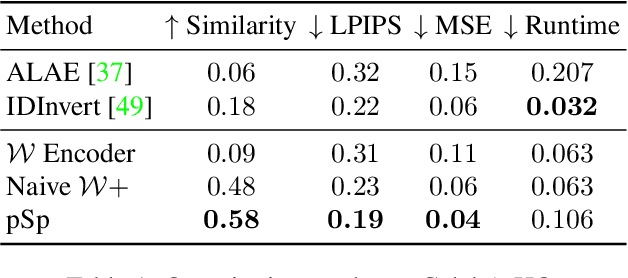
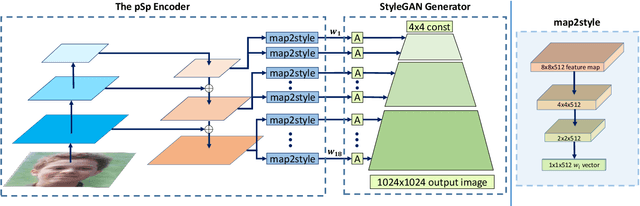
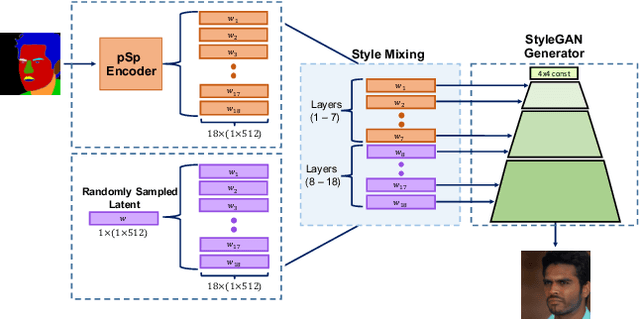

We present a generic image-to-image translation framework, Pixel2Style2Pixel (pSp). Our pSp framework is based on a novel encoder network that directly generates a series of style vectors which are fed into a pretrained StyleGAN generator, forming the extended W+ latent space. We first show that our encoder can directly embed real images into W+, with no additional optimization. We further introduce a dedicated identity loss which is shown to achieve improved performance in the reconstruction of an input image. We demonstrate pSp to be a simple architecture that, by leveraging a well-trained, fixed generator network, can be easily applied on a wide-range of image-to-image translation tasks. Solving these tasks through the style representation results in a global approach that does not rely on a local pixel-to-pixel correspondence and further supports multi-modal synthesis via the resampling of styles. Notably, we demonstrate that pSp can be trained to align a face image to a frontal pose without any labeled data, generate multi-modal results for ambiguous tasks such as conditional face generation from segmentation maps, and construct high-resolution images from corresponding low-resolution images.
It's All About The Scale -- Efficient Text Detection Using Adaptive Scaling
Jul 28, 2019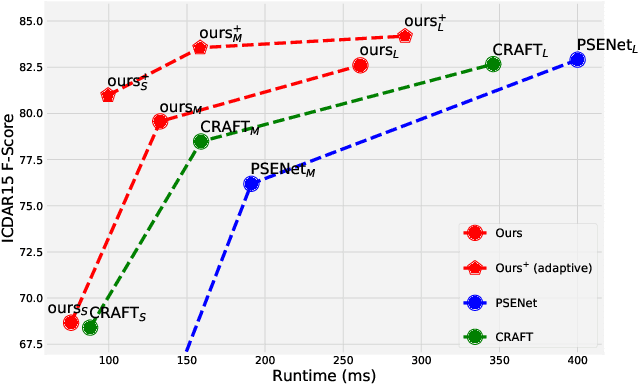
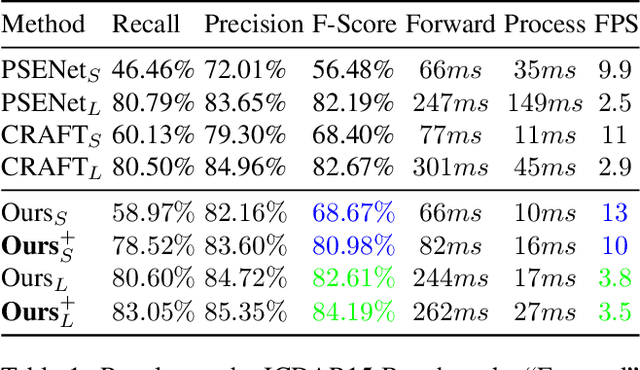

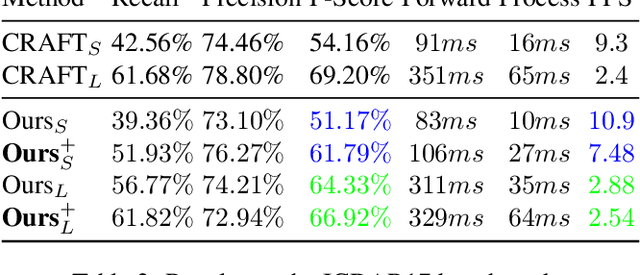
"Text can appear anywhere". This property requires us to carefully process all the pixels in an image in order to accurately localize all text instances. In particular, for the more difficult task of localizing small text regions, many methods use an enlarged image or even several rescaled ones as their input. This significantly increases the processing time of the entire image and needlessly enlarges background regions. If we were to have a prior telling us the coarse location of text instances in the image and their approximate scale, we could have adaptively chosen which regions to process and how to rescale them, thus significantly reducing the processing time. To estimate this prior we propose a segmentation-based network with an additional "scale predictor", an output channel that predicts the scale of each text segment. The network is applied on a scaled down image to efficiently approximate the desired prior, without processing all the pixels of the original image. The approximated prior is then used to create a compact image containing only text regions, resized to a canonical scale, which is fed again to the segmentation network for fine-grained detection. We show that our approach offers a powerful alternative to fixed scaling schemes, achieving an equivalent accuracy to larger input scales while processing far fewer pixels. Qualitative and quantitative results are presented on the ICDAR15 and ICDAR17 MLT benchmarks to validate our approach.