 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenExempt: A Diagnostic Benchmark for Legal Reasoning and a Framework for Creating Custom Benchmarks on Demand
Jan 19, 2026Reasoning benchmarks have played a crucial role in the progress of language models. Yet rigorous evaluation remains a significant challenge as static question-answer pairs provide only a snapshot of performance, compressing complex behavior into a single accuracy metric. This limitation is especially true in complex, rule-bound domains such as law, where existing benchmarks are costly to build and ill suited for isolating specific failure modes. To address this, we introduce OpenExempt, a framework and benchmark for diagnostic evaluation of legal reasoning. The OpenExempt Framework uses expert-crafted symbolic representations of U.S. Bankruptcy Code statutes to dynamically generate a large space of natural language reasoning tasks and their machine-computable solutions on demand. This gives users fine-grained control over task complexity and scope, allowing individual reasoning skills to be probed in isolation. Using this system, we construct the OpenExempt Benchmark, a diagnostic benchmark for legal reasoning with 9,765 samples across nine evaluation suites designed to carefully probe model capabilities. Experiments on 13 diverse language models reveal sharp performance cliffs that emerge only under longer reasoning paths and in the presence of obfuscating statements. We release the framework and benchmark publicly to support research aimed at understanding and improving the next generation of reasoning systems.
LegalCore: A Dataset for Legal Documents Event Coreference Resolution
Feb 18, 2025Recognizing events and their coreferential mentions in a document is essential for understanding semantic meanings of text. The existing research on event coreference resolution is mostly limited to news articles. In this paper, we present the first dataset for the legal domain, LegalCore, which has been annotated with comprehensive event and event coreference information. The legal contract documents we annotated in this dataset are several times longer than news articles, with an average length of around 25k tokens per document. The annotations show that legal documents have dense event mentions and feature both short-distance and super long-distance coreference links between event mentions. We further benchmark mainstream Large Language Models (LLMs) on this dataset for both event detection and event coreference resolution tasks, and find that this dataset poses significant challenges for state-of-the-art open-source and proprietary LLMs, which perform significantly worse than a supervised baseline. We will publish the dataset as well as the code.
DocEdit-v2: Document Structure Editing Via Multimodal LLM Grounding
Oct 21, 2024



Document structure editing involves manipulating localized textual, visual, and layout components in document images based on the user's requests. Past works have shown that multimodal grounding of user requests in the document image and identifying the accurate structural components and their associated attributes remain key challenges for this task. To address these, we introduce the DocEdit-v2, a novel framework that performs end-to-end document editing by leveraging Large Multimodal Models (LMMs). It consists of three novel components: (1) Doc2Command, which simultaneously localizes edit regions of interest (RoI) and disambiguates user edit requests into edit commands; (2) LLM-based Command Reformulation prompting to tailor edit commands originally intended for specialized software into edit instructions suitable for generalist LMMs. (3) Moreover, DocEdit-v2 processes these outputs via Large Multimodal Models like GPT-4V and Gemini, to parse the document layout, execute edits on grounded Region of Interest (RoI), and generate the edited document image. Extensive experiments on the DocEdit dataset show that DocEdit-v2 significantly outperforms strong baselines on edit command generation (2-33%), RoI bounding box detection (12-31%), and overall document editing (1-12\%) tasks.
DocSynthv2: A Practical Autoregressive Modeling for Document Generation
Jun 12, 2024



While the generation of document layouts has been extensively explored, comprehensive document generation encompassing both layout and content presents a more complex challenge. This paper delves into this advanced domain, proposing a novel approach called DocSynthv2 through the development of a simple yet effective autoregressive structured model. Our model, distinct in its integration of both layout and textual cues, marks a step beyond existing layout-generation approaches. By focusing on the relationship between the structural elements and the textual content within documents, we aim to generate cohesive and contextually relevant documents without any reliance on visual components. Through experimental studies on our curated benchmark for the new task, we demonstrate the ability of our model combining layout and textual information in enhancing the generation quality and relevance of documents, opening new pathways for research in document creation and automated design. Our findings emphasize the effectiveness of autoregressive models in handling complex document generation tasks.
Chain of Logic: Rule-Based Reasoning with Large Language Models
Feb 23, 2024



Rule-based reasoning, a fundamental type of legal reasoning, enables us to draw conclusions by accurately applying a rule to a set of facts. We explore causal language models as rule-based reasoners, specifically with respect to compositional rules - rules consisting of multiple elements which form a complex logical expression. Reasoning about compositional rules is challenging because it requires multiple reasoning steps, and attending to the logical relationships between elements. We introduce a new prompting method, Chain of Logic, which elicits rule-based reasoning through decomposition (solving elements as independent threads of logic), and recomposition (recombining these sub-answers to resolve the underlying logical expression). This method was inspired by the IRAC (Issue, Rule, Application, Conclusion) framework, a sequential reasoning approach used by lawyers. We evaluate chain of logic across eight rule-based reasoning tasks involving three distinct compositional rules from the LegalBench benchmark and demonstrate it consistently outperforms other prompting methods, including chain of thought and self-ask, using open-source and commercial language models.
Improving a Named Entity Recognizer Trained on Noisy Data with a Few Clean Instances
Oct 25, 2023



To achieve state-of-the-art performance, one still needs to train NER models on large-scale, high-quality annotated data, an asset that is both costly and time-intensive to accumulate. In contrast, real-world applications often resort to massive low-quality labeled data through non-expert annotators via crowdsourcing and external knowledge bases via distant supervision as a cost-effective alternative. However, these annotation methods result in noisy labels, which in turn lead to a notable decline in performance. Hence, we propose to denoise the noisy NER data with guidance from a small set of clean instances. Along with the main NER model we train a discriminator model and use its outputs to recalibrate the sample weights. The discriminator is capable of detecting both span and category errors with different discriminative prompts. Results on public crowdsourcing and distant supervision datasets show that the proposed method can consistently improve performance with a small guidance set.
User-Entity Differential Privacy in Learning Natural Language Models
Nov 09, 2022



In this paper, we introduce a novel concept of user-entity differential privacy (UeDP) to provide formal privacy protection simultaneously to both sensitive entities in textual data and data owners in learning natural language models (NLMs). To preserve UeDP, we developed a novel algorithm, called UeDP-Alg, optimizing the trade-off between privacy loss and model utility with a tight sensitivity bound derived from seamlessly combining user and sensitive entity sampling processes. An extensive theoretical analysis and evaluation show that our UeDP-Alg outperforms baseline approaches in model utility under the same privacy budget consumption on several NLM tasks, using benchmark datasets.
Certified Neural Network Watermarks with Randomized Smoothing
Jul 16, 2022

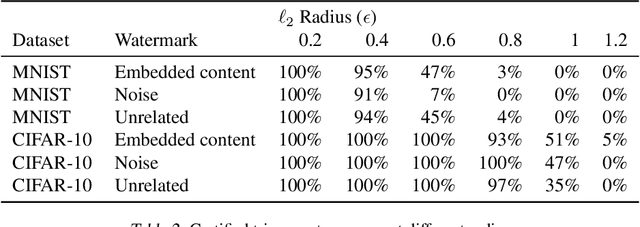

Watermarking is a commonly used strategy to protect creators' rights to digital images, videos and audio. Recently, watermarking methods have been extended to deep learning models -- in principle, the watermark should be preserved when an adversary tries to copy the model. However, in practice, watermarks can often be removed by an intelligent adversary. Several papers have proposed watermarking methods that claim to be empirically resistant to different types of removal attacks, but these new techniques often fail in the face of new or better-tuned adversaries. In this paper, we propose a certifiable watermarking method. Using the randomized smoothing technique proposed in Chiang et al., we show that our watermark is guaranteed to be unremovable unless the model parameters are changed by more than a certain l2 threshold. In addition to being certifiable, our watermark is also empirically more robust compared to previous watermarking methods. Our experiments can be reproduced with code at https://github.com/arpitbansal297/Certified_Watermarks
* ICML 2022
Unified Pretraining Framework for Document Understanding
Apr 28, 2022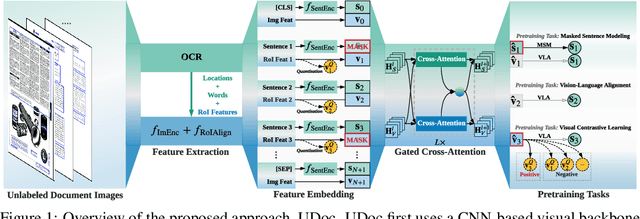
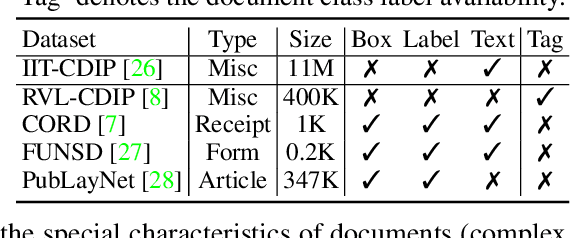
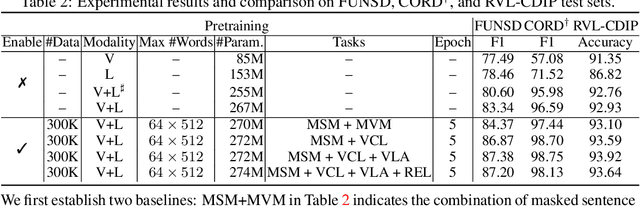
Document intelligence automates the extraction of information from documents and supports many business applications. Recent self-supervised learning methods on large-scale unlabeled document datasets have opened up promising directions towards reducing annotation efforts by training models with self-supervised objectives. However, most of the existing document pretraining methods are still language-dominated. We present UDoc, a new unified pretraining framework for document understanding. UDoc is designed to support most document understanding tasks, extending the Transformer to take multimodal embeddings as input. Each input element is composed of words and visual features from a semantic region of the input document image. An important feature of UDoc is that it learns a generic representation by making use of three self-supervised losses, encouraging the representation to model sentences, learn similarities, and align modalities. Extensive empirical analysis demonstrates that the pretraining procedure learns better joint representations and leads to improvements in downstream tasks.
MACRONYM: A Large-Scale Dataset for Multilingual and Multi-Domain Acronym Extraction
Feb 19, 2022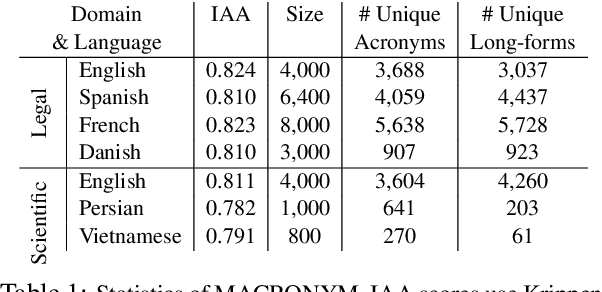
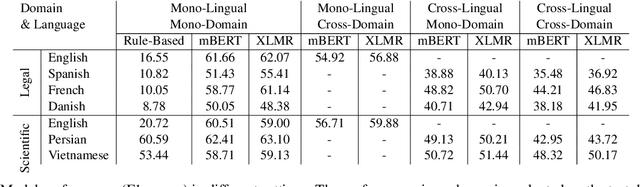
Acronym extraction is the task of identifying acronyms and their expanded forms in texts that is necessary for various NLP applications. Despite major progress for this task in recent years, one limitation of existing AE research is that they are limited to the English language and certain domains (i.e., scientific and biomedical). As such, challenges of AE in other languages and domains is mainly unexplored. Lacking annotated datasets in multiple languages and domains has been a major issue to hinder research in this area. To address this limitation, we propose a new dataset for multilingual multi-domain AE. Specifically, 27,200 sentences in 6 typologically different languages and 2 domains, i.e., Legal and Scientific, is manually annotated for AE. Our extensive experiments on the proposed dataset show that AE in different languages and different learning settings has unique challenges, emphasizing the necessity of further research on multilingual and multi-domain AE.