 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SSH: A Self-Supervised Framework for Image Harmonization
Aug 17, 2021
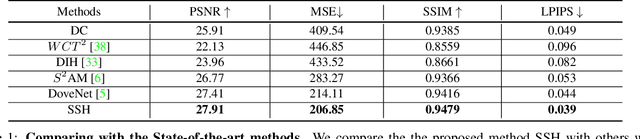
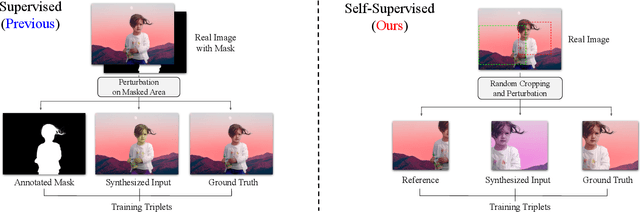
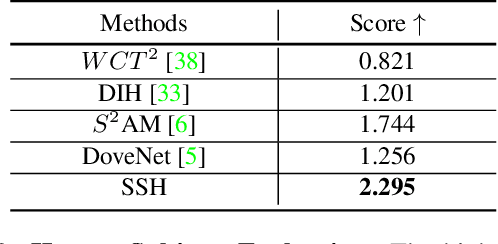
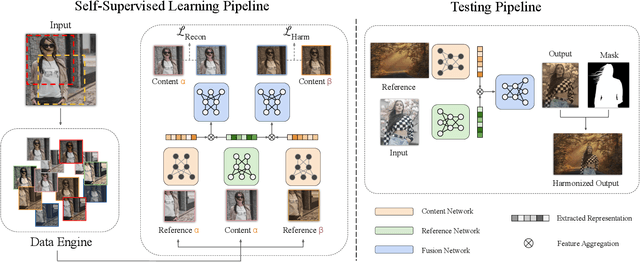
Image harmonization aims to improve the quality of image compositing by matching the "appearance" (\eg, color tone, brightness and contrast) between foreground and background images. However, collecting large-scale annotated datasets for this task requires complex professional retouching. Instead, we propose a novel Self-Supervised Harmonization framework (SSH) that can be trained using just "free" natural images without being edited. We reformulate the image harmonization problem from a representation fusion perspective, which separately processes the foreground and background examples, to address the background occlusion issue. This framework design allows for a dual data augmentation method, where diverse [foreground, background, pseudo GT] triplets can be generated by cropping an image with perturbations using 3D color lookup tables (LUTs). In addition, we build a real-world harmonization dataset as carefully created by expert users, for evaluation and benchmarking purposes. Our results show that the proposed self-supervised method outperforms previous state-of-the-art methods in terms of reference metrics, visual quality, and subject user study. Code and dataset are available at \url{https://github.com/VITA-Group/SSHarmonization}.
Simple Open-Vocabulary Object Detection with Vision Transformers
May 12, 2022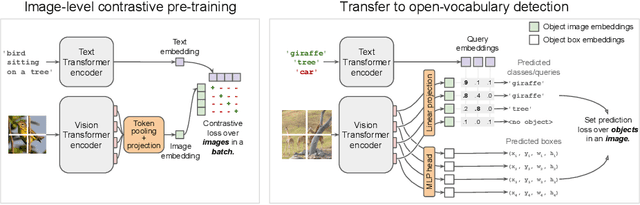
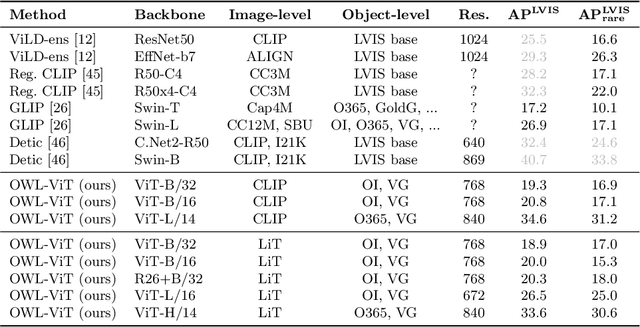
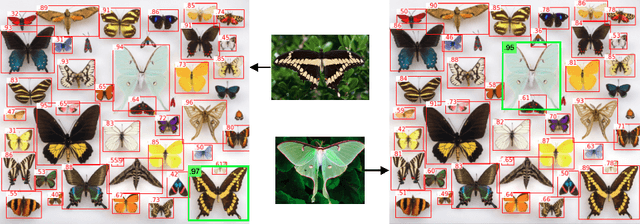
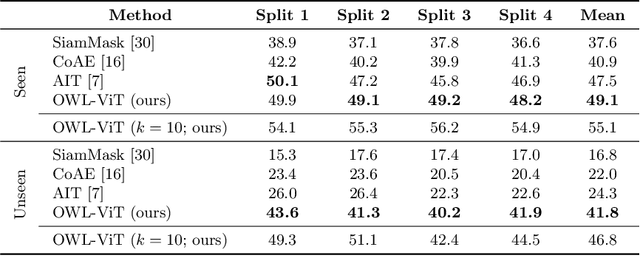
Combining simple architectures with large-scale pre-training has led to massive improvements in image classification. For object detection, pre-training and scaling approaches are less well established, especially in the long-tailed and open-vocabulary setting, where training data is relatively scarce. In this paper, we propose a strong recipe for transferring image-text models to open-vocabulary object detection. We use a standard Vision Transformer architecture with minimal modifications, contrastive image-text pre-training, and end-to-end detection fine-tuning. Our analysis of the scaling properties of this setup shows that increasing image-level pre-training and model size yield consistent improvements on the downstream detection task. We provide the adaptation strategies and regularizations needed to attain very strong performance on zero-shot text-conditioned and one-shot image-conditioned object detection. Code and models are available on GitHub.
Lung nodules segmentation from CT with DeepHealth toolkit
Aug 01, 2022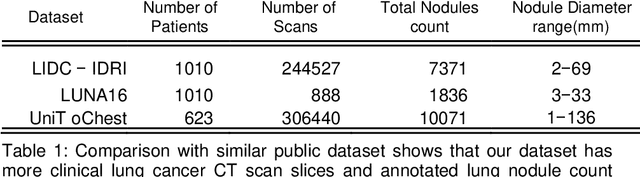
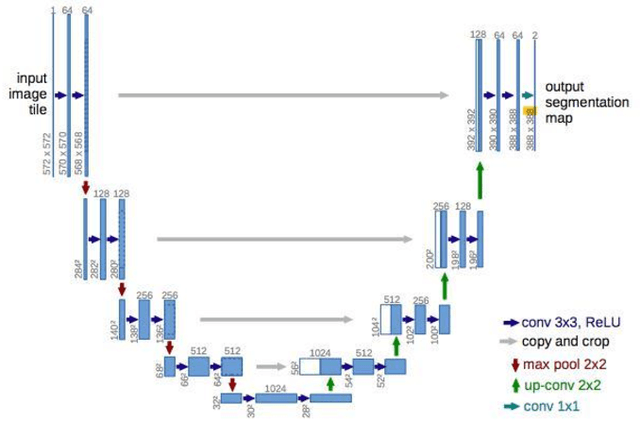

The accurate and consistent border segmentation plays an important role in the tumor volume estimation and its treatment in the field of Medical Image Segmentation. Globally, Lung cancer is one of the leading causes of death and the early detection of lung nodules is essential for the early cancer diagnosis and survival rate of patients. The goal of this study was to demonstrate the feasibility of Deephealth toolkit including PyECVL and PyEDDL libraries to precisely segment lung nodules. Experiments for lung nodules segmentation has been carried out on UniToChest using PyECVL and PyEDDL, for data pre-processing as well as neural network training. The results depict accurate segmentation of lung nodules across a wide diameter range and better accuracy over a traditional detection approach. The datasets and the code used in this paper are publicly available as a baseline reference.
A Streaming Volumetric Image Generation Framework for Development and Evaluation of Out-of-Core Methods
Dec 18, 2021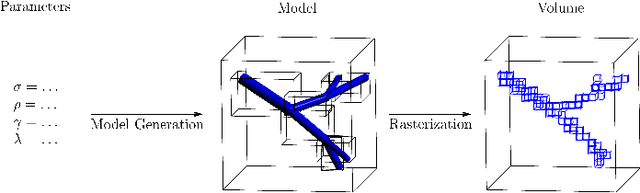
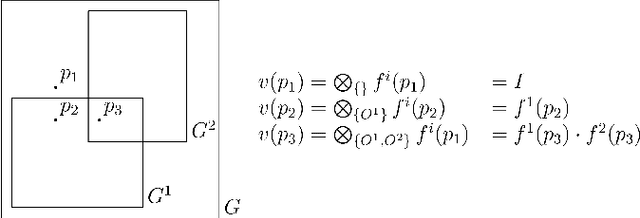
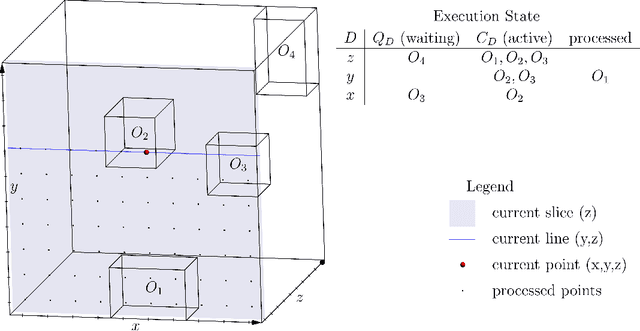
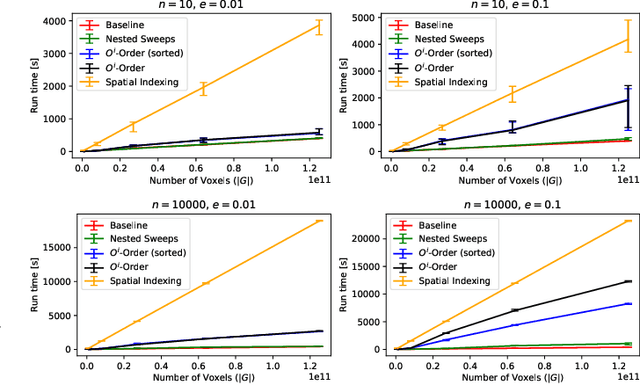
Advances in 3D imaging technology in recent years have allowed for increasingly high resolution volumetric images of large specimen. The resulting datasets of hundreds of Gigabytes in size call for new scalable and memory efficient approaches in the field of image processing, where some progress has been made already. At the same time, quantitative evaluation of these new methods is difficult both in terms of the availability of specific data sizes and in the generation of associated ground truth data. In this paper we present an algorithmic framework that can be used to efficiently generate test (and ground truth) volume data, optionally even in a streaming fashion. As the proposed nested sweeps algorithm is fast, it can be used to generate test data on demand. We analyze the asymptotic run time of the presented algorithm and compare it experimentally to alternative approaches as well as a hypothetical best-case baseline method. In a case study, the framework is applied to the popular VascuSynth software for vascular image generation, making it capable of efficiently producing larger-than-main memory volumes which is demonstrated by generating a trillion voxel (1TB) image. Implementations of the presented framework are available online in the form of the modified version of Vascusynth and the code used for the experimental evaluation. In addition, the test data generation procedure has been integrated into the popular volume rendering and processing framework Voreen.
Aesthetic Language Guidance Generation of Images Using Attribute Comparison
Aug 09, 2022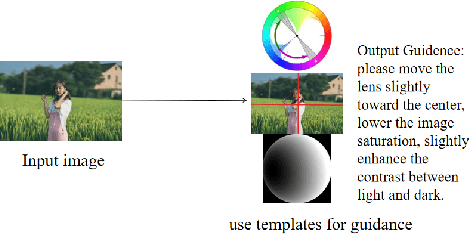

With the vigorous development of mobile photography technology, major mobile phone manufacturers are scrambling to improve the shooting ability of equipments and the photo beautification algorithm of software. However, the improvement of intelligent equipments and algorithms cannot replace human subjective photography technology. In this paper, we propose the aesthetic language guidance of image (ALG). We divide ALG into ALG-T and ALG-I according to whether the guiding rules are based on photography templates or guidance images. Whether it is ALG-T or ALG-I, we guide photography from three attributes of color, lighting and composition of the images. The differences of the three attributes between the input images and the photography templates or the guidance images are described in natural language, which is aesthetic natural language guidance (ALG). Also, because of the differences in lighting and composition between landscape images and portrait images, we divide the input images into landscape images and portrait images. Both ALG-T and ALG-I conduct aesthetic language guidance respectively for the two types of input images (landscape images and portrait images).
GenISP: Neural ISP for Low-Light Machine Cognition
May 07, 2022
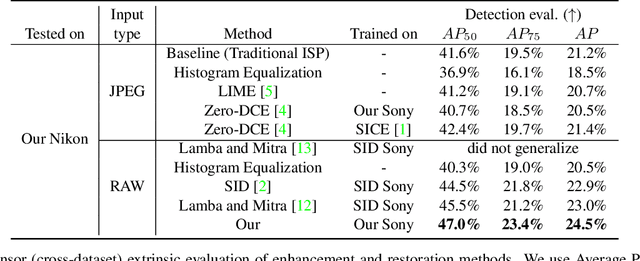


Object detection in low-light conditions remains a challenging but important problem with many practical implications. Some recent works show that, in low-light conditions, object detectors using raw image data are more robust than detectors using image data processed by a traditional ISP pipeline. To improve detection performance in low-light conditions, one can fine-tune the detector to use raw image data or use a dedicated low-light neural pipeline trained with paired low- and normal-light data to restore and enhance the image. However, different camera sensors have different spectral sensitivity and learning-based models using raw images process data in the sensor-specific color space. Thus, once trained, they do not guarantee generalization to other camera sensors. We propose to improve generalization to unseen camera sensors by implementing a minimal neural ISP pipeline for machine cognition, named GenISP, that explicitly incorporates Color Space Transformation to a device-independent color space. We also propose a two-stage color processing implemented by two image-to-parameter modules that take down-sized image as input and regress global color correction parameters. Moreover, we propose to train our proposed GenISP under the guidance of a pre-trained object detector and avoid making assumptions about perceptual quality of the image, but rather optimize the image representation for machine cognition. At the inference stage, GenISP can be paired with any object detector. We perform extensive experiments to compare our method to other low-light image restoration and enhancement methods in an extrinsic task-based evaluation and validate that GenISP can generalize to unseen sensors and object detectors. Finally, we contribute a low-light dataset of 7K raw images annotated with 46K bounding boxes for task-based benchmarking of future low-light image restoration and object detection.
Learning Low Bending and Low Distortion Manifold Embeddings: Theory and Applications
Aug 22, 2022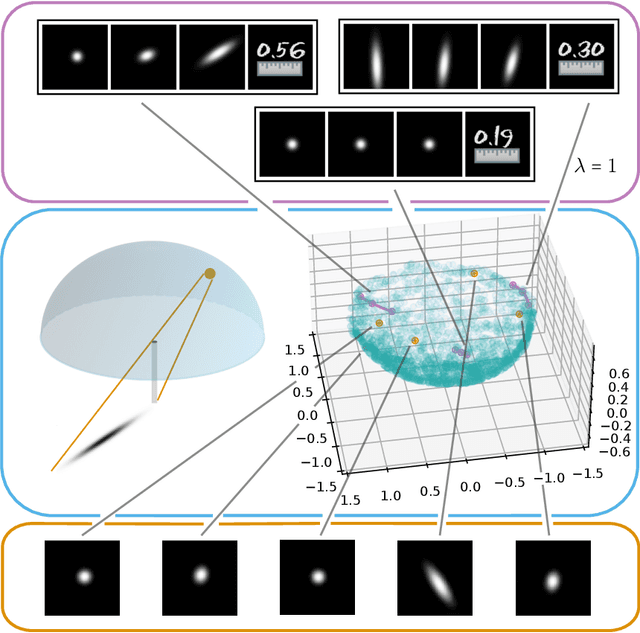
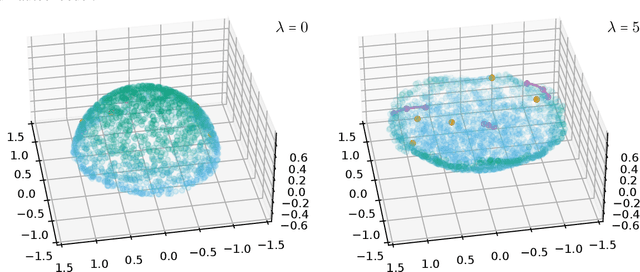
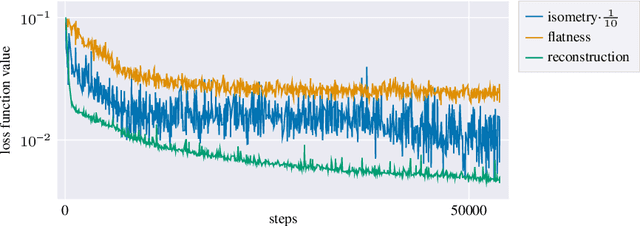
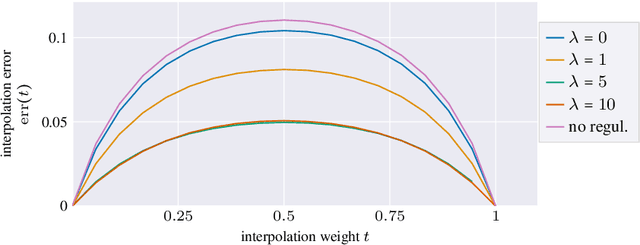
Autoencoders, which consist of an encoder and a decoder, are widely used in machine learning for dimension reduction of high-dimensional data. The encoder embeds the input data manifold into a lower-dimensional latent space, while the decoder represents the inverse map, providing a parametrization of the data manifold by the manifold in latent space. A good regularity and structure of the embedded manifold may substantially simplify further data processing tasks such as cluster analysis or data interpolation. We propose and analyze a novel regularization for learning the encoder component of an autoencoder: a loss functional that prefers isometric, extrinsically flat embeddings and allows to train the encoder on its own. To perform the training it is assumed that for pairs of nearby points on the input manifold their local Riemannian distance and their local Riemannian average can be evaluated. The loss functional is computed via Monte Carlo integration with different sampling strategies for pairs of points on the input manifold. Our main theorem identifies a geometric loss functional of the embedding map as the $\Gamma$-limit of the sampling-dependent loss functionals. Numerical tests, using image data that encodes different explicitly given data manifolds, show that smooth manifold embeddings into latent space are obtained. Due to the promotion of extrinsic flatness, these embeddings are regular enough such that interpolation between not too distant points on the manifold is well approximated by linear interpolation in latent space as one possible postprocessing.
Multi-Granularity Distillation Scheme Towards Lightweight Semi-Supervised Semantic Segmentation
Aug 22, 2022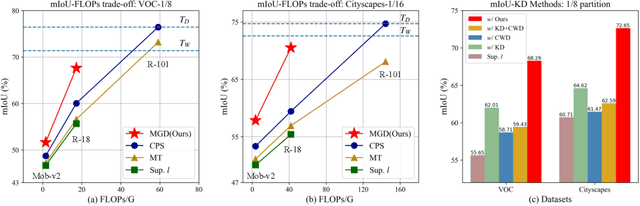
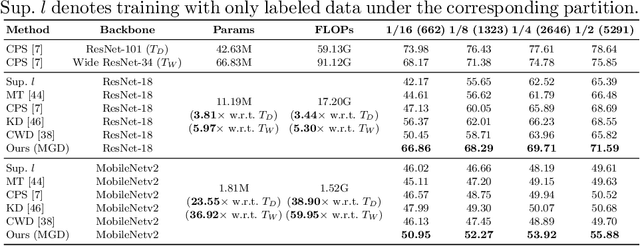
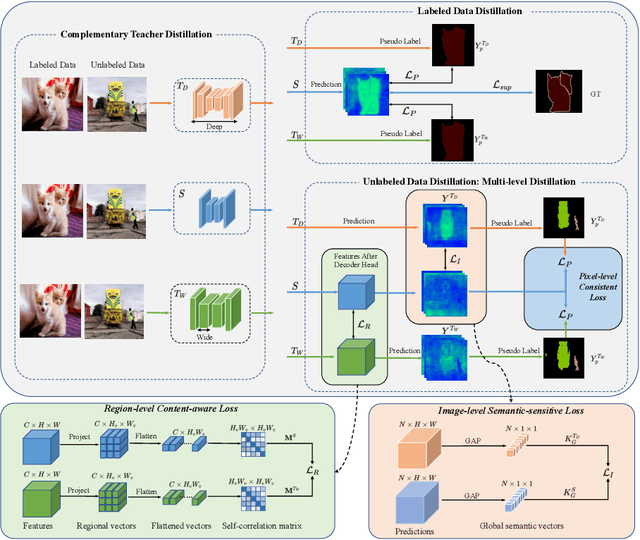
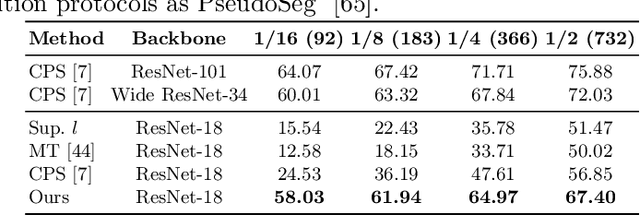
Albeit with varying degrees of progress in the field of Semi-Supervised Semantic Segmentation, most of its recent successes are involved in unwieldy models and the lightweight solution is still not yet explored. We find that existing knowledge distillation techniques pay more attention to pixel-level concepts from labeled data, which fails to take more informative cues within unlabeled data into account. Consequently, we offer the first attempt to provide lightweight SSSS models via a novel multi-granularity distillation (MGD) scheme, where multi-granularity is captured from three aspects: i) complementary teacher structure; ii) labeled-unlabeled data cooperative distillation; iii) hierarchical and multi-levels loss setting. Specifically, MGD is formulated as a labeled-unlabeled data cooperative distillation scheme, which helps to take full advantage of diverse data characteristics that are essential in the semi-supervised setting. Image-level semantic-sensitive loss, region-level content-aware loss, and pixel-level consistency loss are set up to enrich hierarchical distillation abstraction via structurally complementary teachers. Experimental results on PASCAL VOC2012 and Cityscapes reveal that MGD can outperform the competitive approaches by a large margin under diverse partition protocols. For example, the performance of ResNet-18 and MobileNet-v2 backbone is boosted by 11.5% and 4.6% respectively under 1/16 partition protocol on Cityscapes. Although the FLOPs of the model backbone is compressed by 3.4-5.3x (ResNet-18) and 38.7-59.6x (MobileNetv2), the model manages to achieve satisfactory segmentation results.
Prompt-Matched Semantic Segmentation
Aug 22, 2022
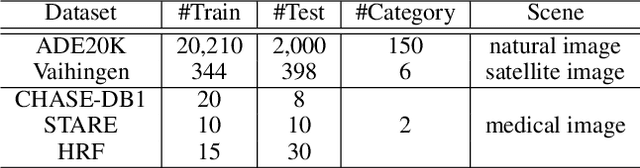
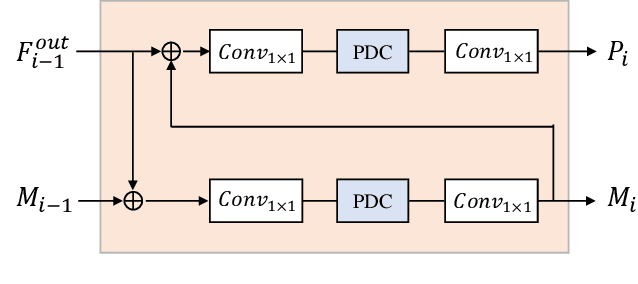

The objective of this work is to explore how to effectively and efficiently adapt pre-trained foundation models to various downstream tasks of image semantic segmentation. Conventional methods usually fine-tuned the whole networks for each specific dataset and it was burdensome to store the massive parameters of these networks. A few recent works attempted to insert some trainable parameters into the frozen network to learn visual prompts for efficient tuning. However, these works significantly modified the original structure of standard modules, making them inoperable on many existing high-speed inference devices, where standard modules and their parameters have been embedded. To facilitate prompt-based semantic segmentation, we propose a novel Inter-Stage Prompt-Matched Framework, which maintains the original structure of the foundation model while generating visual prompts adaptively for task-oriented tuning. Specifically, the pre-trained model is first divided into multiple stages, and their parameters are frozen and shared for all semantic segmentation tasks. A lightweight module termed Semantic-aware Prompt Matcher is then introduced to hierarchically interpolate between two stages to learn reasonable prompts for each specific task under the guidance of interim semantic maps. In this way, we can better stimulate the pre-trained knowledge of the frozen model to learn semantic concepts effectively on downstream datasets. Extensive experiments conducted on five benchmarks show that the proposed method can achieve a promising trade-off between parameter efficiency and performance effectiveness.
Fixed-Point Automatic Differentiation of Forward--Backward Splitting Algorithms for Partly Smooth Functions
Aug 05, 2022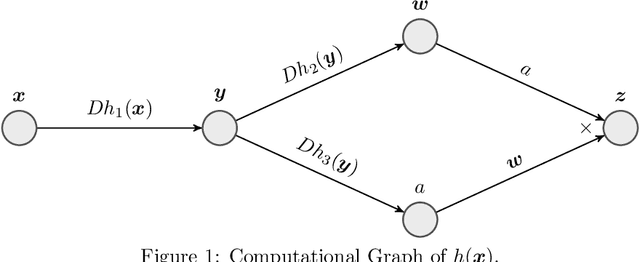
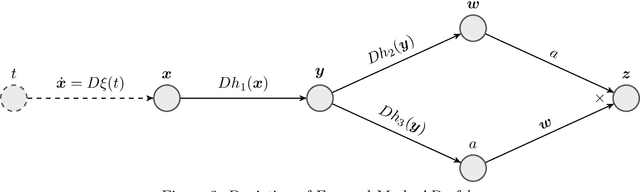
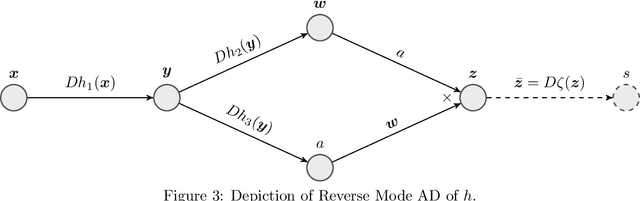
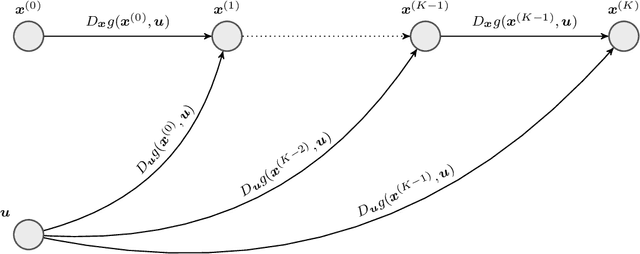
A large class of non-smooth practical optimization problems can be written as minimization of a sum of smooth and partly smooth functions. We consider such structured problems which also depend on a parameter vector and study the problem of differentiating its solution mapping with respect to the parameter which has far reaching applications in sensitivity analysis and parameter learning optmization problems. We show that under partial smoothness and other mild assumptions, Automatic Differentiation (AD) of the sequence generated by proximal splitting algorithms converges to the derivative of the solution mapping. For a variant of automatic differentiation, which we call Fixed-Point Automatic Differentiation (FPAD), we remedy the memory overhead problem of the Reverse Mode AD and moreover provide faster convergence theoretically. We numerically illustrate the convergence and convergence rates of AD and FPAD on Lasso and Group Lasso problems and demonstrate the working of FPAD on prototypical practical image denoising problem by learning the regularization term.