 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Curse of Unrolling
Feb 23, 2026Algorithm unrolling is ubiquitous in machine learning, particularly in hyperparameter optimization and meta-learning, where Jacobians of solution mappings are computed by differentiating through iterative algorithms. Although unrolling is known to yield asymptotically correct Jacobians under suitable conditions, recent work has shown that the derivative iterates may initially diverge from the true Jacobian, a phenomenon known as the curse of unrolling. In this work, we provide a non-asymptotic analysis that explains the origin of this behavior and identifies the algorithmic factors that govern it. We show that truncating early iterations of the derivative computation mitigates the curse while simultaneously reducing memory requirements. Finally, we demonstrate that warm-starting in bilevel optimization naturally induces an implicit form of truncation, providing a practical remedy. Our theoretical findings are supported by numerical experiments on representative examples.
Automatic Differentiation of Optimization Algorithms with Time-Varying Updates
Oct 21, 2024Numerous Optimization Algorithms have a time-varying update rule thanks to, for instance, a changing step size, momentum parameter or, Hessian approximation. In this paper, we apply unrolled or automatic differentiation to a time-varying iterative process and provide convergence (rate) guarantees for the resulting derivative iterates. We adapt these convergence results and apply them to proximal gradient descent with variable step size and FISTA when solving partly smooth problems. We confirm our findings numerically by solving $\ell_1$ and $\ell_2$-regularized linear and logisitc regression respectively. Our theoretical and numerical results show that the convergence rate of the algorithm is reflected in its derivative iterates.
A Generalization Result for Convergence in Learning-to-Optimize
Oct 10, 2024



Convergence in learning-to-optimize is hardly studied, because conventional convergence guarantees in optimization are based on geometric arguments, which cannot be applied easily to learned algorithms. Thus, we develop a probabilistic framework that resembles deterministic optimization and allows for transferring geometric arguments into learning-to-optimize. Our main theorem is a generalization result for parametric classes of potentially non-smooth, non-convex loss functions and establishes the convergence of learned optimization algorithms to stationary points with high probability. This can be seen as a statistical counterpart to the use of geometric safeguards to ensure convergence. To the best of our knowledge, we are the first to prove convergence of optimization algorithms in such a probabilistic framework.
A Markovian Model for Learning-to-Optimize
Aug 21, 2024



We present a probabilistic model for stochastic iterative algorithms with the use case of optimization algorithms in mind. Based on this model, we present PAC-Bayesian generalization bounds for functions that are defined on the trajectory of the learned algorithm, for example, the expected (non-asymptotic) convergence rate and the expected time to reach the stopping criterion. Thus, not only does this model allow for learning stochastic algorithms based on their empirical performance, it also yields results about their actual convergence rate and their actual convergence time. We stress that, since the model is valid in a more general setting than learning-to-optimize, it is of interest for other fields of application, too. Finally, we conduct five practically relevant experiments, showing the validity of our claims.
From Learning to Optimize to Learning Optimization Algorithms
May 28, 2024Towards designing learned optimization algorithms that are usable beyond their training setting, we identify key principles that classical algorithms obey, but have up to now, not been used for Learning to Optimize (L2O). Following these principles, we provide a general design pipeline, taking into account data, architecture and learning strategy, and thereby enabling a synergy between classical optimization and L2O, resulting in a philosophy of Learning Optimization Algorithms. As a consequence our learned algorithms perform well far beyond problems from the training distribution. We demonstrate the success of these novel principles by designing a new learning-enhanced BFGS algorithm and provide numerical experiments evidencing its adaptation to many settings at test time.
Learning-to-Optimize with PAC-Bayesian Guarantees: Theoretical Considerations and Practical Implementation
Apr 04, 2024



We use the PAC-Bayesian theory for the setting of learning-to-optimize. To the best of our knowledge, we present the first framework to learn optimization algorithms with provable generalization guarantees (PAC-Bayesian bounds) and explicit trade-off between convergence guarantees and convergence speed, which contrasts with the typical worst-case analysis. Our learned optimization algorithms provably outperform related ones derived from a (deterministic) worst-case analysis. The results rely on PAC-Bayesian bounds for general, possibly unbounded loss-functions based on exponential families. Then, we reformulate the learning procedure into a one-dimensional minimization problem and study the possibility to find a global minimum. Furthermore, we provide a concrete algorithmic realization of the framework and new methodologies for learning-to-optimize, and we conduct four practically relevant experiments to support our theory. With this, we showcase that the provided learning framework yields optimization algorithms that provably outperform the state-of-the-art by orders of magnitude.
Near-optimal Closed-loop Method via Lyapunov Damping for Convex Optimization
Nov 16, 2023We introduce an autonomous system with closed-loop damping for first-order convex optimization. While, to this day, optimal rates of convergence are only achieved by non-autonomous methods via open-loop damping (e.g., Nesterov's algorithm), we show that our system is the first one featuring a closed-loop damping while exhibiting a rate arbitrarily close to the optimal one. We do so by coupling the damping and the speed of convergence of the system via a well-chosen Lyapunov function. We then derive a practical first-order algorithm called LYDIA by discretizing our system, and present numerical experiments supporting our theoretical findings.
Fixed-Point Automatic Differentiation of Forward--Backward Splitting Algorithms for Partly Smooth Functions
Aug 05, 2022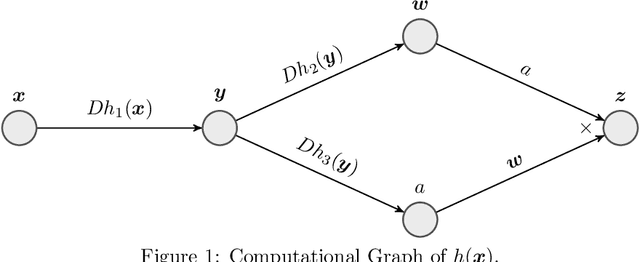
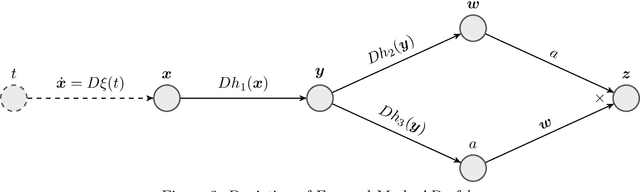
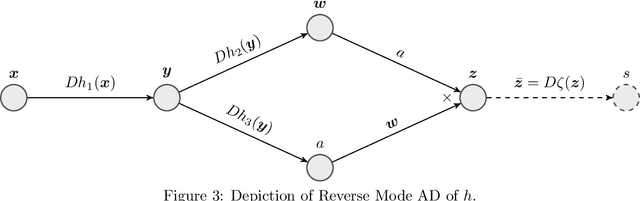
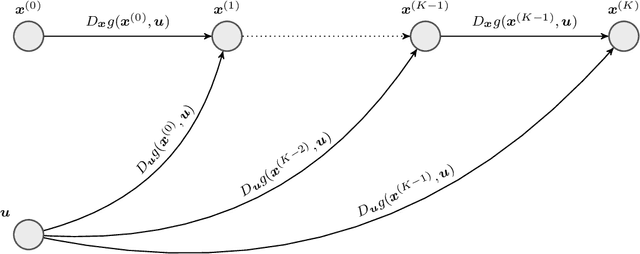
A large class of non-smooth practical optimization problems can be written as minimization of a sum of smooth and partly smooth functions. We consider such structured problems which also depend on a parameter vector and study the problem of differentiating its solution mapping with respect to the parameter which has far reaching applications in sensitivity analysis and parameter learning optmization problems. We show that under partial smoothness and other mild assumptions, Automatic Differentiation (AD) of the sequence generated by proximal splitting algorithms converges to the derivative of the solution mapping. For a variant of automatic differentiation, which we call Fixed-Point Automatic Differentiation (FPAD), we remedy the memory overhead problem of the Reverse Mode AD and moreover provide faster convergence theoretically. We numerically illustrate the convergence and convergence rates of AD and FPAD on Lasso and Group Lasso problems and demonstrate the working of FPAD on prototypical practical image denoising problem by learning the regularization term.
Global Convergence of Model Function Based Bregman Proximal Minimization Algorithms
Dec 24, 2020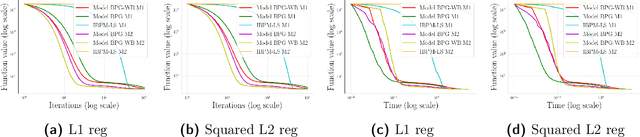
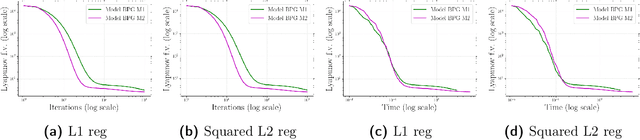
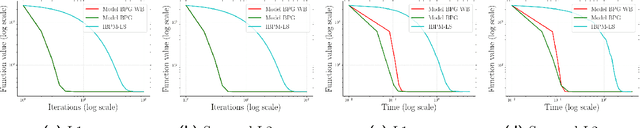
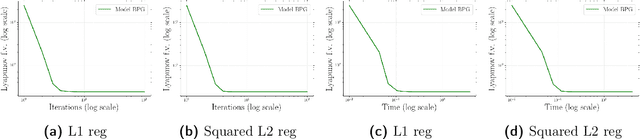
Lipschitz continuity of the gradient mapping of a continuously differentiable function plays a crucial role in designing various optimization algorithms. However, many functions arising in practical applications such as low rank matrix factorization or deep neural network problems do not have a Lipschitz continuous gradient. This led to the development of a generalized notion known as the $L$-smad property, which is based on generalized proximity measures called Bregman distances. However, the $L$-smad property cannot handle nonsmooth functions, for example, simple nonsmooth functions like $\abs{x^4-1}$ and also many practical composite problems are out of scope. We fix this issue by proposing the MAP property, which generalizes the $L$-smad property and is also valid for a large class of nonconvex nonsmooth composite problems. Based on the proposed MAP property, we propose a globally convergent algorithm called Model BPG, that unifies several existing algorithms. The convergence analysis is based on a new Lyapunov function. We also numerically illustrate the superior performance of Model BPG on standard phase retrieval problems, robust phase retrieval problems, and Poisson linear inverse problems, when compared to a state of the art optimization method that is valid for generic nonconvex nonsmooth optimization problems.
Self-supervised Sparse to Dense Motion Segmentation
Aug 18, 2020



Observable motion in videos can give rise to the definition of objects moving with respect to the scene. The task of segmenting such moving objects is referred to as motion segmentation and is usually tackled either by aggregating motion information in long, sparse point trajectories, or by directly producing per frame dense segmentations relying on large amounts of training data. In this paper, we propose a self supervised method to learn the densification of sparse motion segmentations from single video frames. While previous approaches towards motion segmentation build upon pre-training on large surrogate datasets and use dense motion information as an essential cue for the pixelwise segmentation, our model does not require pre-training and operates at test time on single frames. It can be trained in a sequence specific way to produce high quality dense segmentations from sparse and noisy input. We evaluate our method on the well-known motion segmentation datasets FBMS59 and DAVIS16.